










【自己做个笔记,大家有需要的可以看看,有问题欢迎指出】
文章目录
- 基础面试题
- 1.设计用例的方法、依据有哪些
- 2.软件的生命周期
- 3.测试流程
- 4.bug生命周期
- 5.你在测试中发现了一个bug,但是开发认为这不是一个bug,你应该怎样解决
- 6.如何测试一个纸杯?
- 7.我手上这支笔,请你根据这支笔设计测试用例
- 8.支付流程测试
- 9.请你说一说PC网络故障,以及如何排除障碍
- 10.请你说一下分布式和集群的概念。
- 11.请你说一说TCP的数据报结构以及三次握手和四次挥手?
- 12.请你说一下在浏览器中输入一个网址它的运行过程是怎样的?
- 13.请你说一说http请求报文以及http和https的区别
- 14.请你说一说get和 post区别
- 14.1 get请求缓存解决办法
- 15.请你说一下tcp和udp的区别
- 16.请你说一下为什么tcp可靠,哪些方法保证可靠
- 17.请你说说HTTP状态码
- 18.请你介绍下session
- 19.Session和cookie的区别:
- 20.请问你知道跨域吗,条件是什么,在header里需要加什么,有几种方案
- 21.请你说一下进程和线程的区别
- 22.请你说一下多进程、多线程,操作系统层面的差别和联系
- 23.请你说一下死锁的概念、原因、解决方法
- 24.各数据类型的长度(java)
- 25.七层模型
- 数据库相关面试题
- 1.说一下mysql删除语句
- 2.问count和sum的区别,以及count(*)和count(列名)的区别
- 3.讲一下where和having的区别
- 4.请你说一下数据库mysql中CHAR和VCHAR的区别
- 5.请问什么是数据库事务
- 6.说一下数据库事务的四个特性
- 7.请问什么是幻读
- 8.请你说一下事务的隔离级别,以及你一般使用的事务是哪种
- 9.索引相关
- 10.请问如何对数据库作优化
- 11.请问对缓存技术了解吗(请你说说redis)
- 12.mysql练习题
- 13.数据库熟吗?用过哪些数据库?索引会吗?事务了解吗?写一个 SQL 查询语句:给一个字段,对其进行从大到小排序,取前十行。
- 14.redis常用操作
- 15.关系型数据库和非关系型数据库简介
- 16.常见的非关系型数据库有哪些
- 17.关系型数据库和非关系型数据库的特性以及各自的优缺点
- 性能测试相关面试题
- 安全相关面试题
- linux相关面试题
- docker相关面试题
- Jenkins相关面试题
- UI自动化测试相关面试题
- 1.什么是自动化测试?
- 2.你会封装自动化测试框架吗?
- 3.你觉得自动化测试的价值在哪里?你们公司为什么要做自动化测试?
- 4.自动化测试有误报过bug吗?产生误报怎么办?
- 5.如果一个元素无法定位,你一般会考虑哪些方面的原因?
- 6.常见的元素定位方法有几种?分别是哪些?
- 7.遇到frame框架页面怎么处理?
- 8.遇到alert弹出窗如何处理?
- 9.如何处理多窗口?
- 10.怎么验证元素是enable/disabled/checked状态?
- 11.如何处理下拉菜单?
- 12.举例说明一下你遇到过哪些异常
- 13.关闭浏览器中quit和close的区别
- 14.在Selenium中如何实现截图,如何实现用例执行失败才截图
- 15.如何实现文件上传?
- 16.自动化中有哪三类等待?他们有什么特点?
- 17.你写的测试脚本能在不同浏览器上运行吗?
- 18.什么是PO模式,为什么要使用它?
- 接口自动化相关面试题
- Python相关面试题
- 1.模块和包
- 2.super 是干嘛用的?在 Python2 和 Python3 使用,有什么区别?为什么要使用 super?请举例说明。
- 3.L = [1, 2, 3, 11, 2, 5, 3, 2, 5, 3],用一行代码得出 [11, 1, 2, 3, 5]
- 4.python让列表倒序排列的三种方法
- 5.L = [1, 2, 3, 5, 6],如何得出 '12356'?
- 6.L = [1, 2, 3, 4, 5],L[10:]的结果是?
- 7.为什么python的切片不会索引越界?
- 8.1.什么是Python列表?
- 8.2.什么是Python元组?
- 8.2.1.元组的使用场景
- 8.3.什么是Python字典?
- 8.4.Python中列表和元组有什么区别?
- 8.5.Python中列表和字典有什么区别
- 8.6.Python中列表、元组、字典之间有什么区别呢?
- 9.写一段代码,ping 一个 ip 地址,并返回成功 失败的信息
- 10.生成器generator和迭代器iterator
- 11.参数传递机制
- 12.Python对象基本要素(3)
- 13.__new__和__init__的区别?
- 14.浅拷贝和深拷贝的区别
- 15.1.如何理解python装饰器
- 15.2.为什么要用装饰器?
- 15.3.常见的装饰器有哪些?
- 什么是ORM?为什么要用ORM?不用ORM会带来什么影响?
- python内置函数
- 问会什么语言?现场写两段代码,如下:
基础面试题
1.设计用例的方法、依据有哪些
参考文章:
https://blog.csdn.net/weixin_46658581/article/details/119678292
http://www.51testing.com/html/30/n-3719130.html
- 测试用例设计方法
白盒测试:逻辑覆盖、循环覆盖、基本路径覆盖
黑盒测试:边界值分析法、等价类划分、错误猜测法、因果图法、状态图法、测试大纲法、随机测试、场景法
1. 等价类划分法
顾名思义,等价类划分,就是将测试的范围划分成几个互不相交的子集,他们的并集是全集,从每个子集选出若干个有代表性的值作为测试用例。
例如,我们要测试一个用户名是否合法,用户名的定义为:8位数字组成的字符。
我们可以先划分子集:空用户名,1-7位数字,8位数字,9位或以上数字,非数字。
然后从每个子集选出若干个有代表性的值:
空用户名:“” (无效等价类实例,指对于软件规格说明而言,没有意义的、不合理的输入)
1-7位数字:"234" (无效等价类实例)
8位数字:"00000000" (有效等价类实例,能检验程序是否实现了规格说明中所规定的功能和性能)
9位或以上数字:"1234567890" (无效等价类实例)
非数字:"abc&!!!" (无效等价类实例)
他们5个,就是用等价类划分选出的测试用例。实际上,对于1-7位数字的子集来说,选“234”和“11111”没有本质的区别。
等价类的划分,最关键的是子集的划分。实际上,非数字还可以继续划分子集:字母,特殊字符。
究竟要划分到何种程度才合适呢?看你有多少资源和时间,还有,看是否值得。毕竟无论你怎么测试,总会有未发现的缺陷存在,所以,先解决容易被发现的问题再说。
2. 边界值法
长期的测试工作经验告诉我们,大量的错误是发生在输入或输出范围的边界上,而不是发生在输入输出范围的内部。因此针对各种边界情况设计测试用例,可以查出更多的错误。选出的测试用例,应选取正好等于、刚刚大于、刚刚小于边界的值,例如,对于在区间min,max的值,测试用例可以记为min,min+,max,max-。
例如,假定 X 为整数,10≤X≤100,那么 X 在测试中应该取的边界值为:10,11,99,100。
注:上面只是说边界值,如果是完整的测试,除了边界值外,还需要一个正常值,即12-98之间的任意值。
3. 因果图及判定表法
4. 正交表
用语言描述正交实验法会很抽象难懂,简单说,就是在各因素互相独立的情况下,设计出一种特殊的表格,找出能以少数替代全面的测试用例。
其中,上面所说的特殊表格就是正交表,是按照一定规则生成的表。
虽然说是特殊的表格,实际表现形式跟一般的表格没有什么区别,正交表的主要特征是,“均匀分布,整齐划一”,正是因为“均匀”的,所以才能以少数代替全部。
5. 测试大纲法
6. 场景法
7. 错误推断法
错误推测法是指:在测试程序时,人们可以根据经验或直觉推测程序中可能存在的各种错误,从而有针对性地编写检查这些错误的测试用例的方法。
这种方法没有固定的形式,依靠的是经验和直觉,很多时候,我们都会不知不觉的使用到。
8. 随机测试
2.软件的生命周期
计划阶段-〉需求分析-〉设计阶段-〉编码->测试->运行与维护
3.测试流程
- 测试需求分析阶段:阅读需求,理解需求,主要就是对业务的学习,分析需求点,参与需求评审会议。
- 测试计划阶段:主要任务就是编写测试计划,参考软件需求规格说明书,项目总体计划,内容包括测试范围(来自需求文档),进度安排,人力物力的分配,整体测试策略的制定。风险评估与规避措施有一个制定。
- 测试设计阶段:主要是编写测试用例,会参考需求文档(原型图),概要设计,详细设计等文档,用例编写完成之后会进行评审。
- 测试执行阶段:搭建环境,执行冒烟测试(预测试)-然后进入正式测试,bug管理直到测试结束。
- 测试评估阶段:出测试报告,确认是否可以上线。
4.bug生命周期
一般情况下:发现bug -》提交bug -》指派bug -》开发确认bug -》解决bug -》验证bug -》关闭bug
但是还会存在开发拒绝bug、验证不通过重新打开bug、挂起bug等
5.你在测试中发现了一个bug,但是开发认为这不是一个bug,你应该怎样解决
【自由发挥】
1、将问题提交到缺陷管理工具进行记录
2、给出你判断其为bug的依据和标准,看开发是否能够认同;
3、根据需求说明书、产品说明、设计文档等,确认实际结果是否与计划有不一致的地方,提供缺陷是否确认的直接依据;
4、如果没有文档依据,可以根据类似软件的一般特性来说明是否存在不一致的地方,来确认是否是缺陷;
5、与产品确认是否是缺陷
6.如何测试一个纸杯?
功能度:用水杯装水看漏不漏;水能不能被喝到
安全性:杯子有没有毒或细菌
可靠性:杯子从不同高度落下的损坏程度
可移植性:杯子在不同的地方、温度等环境下是否都可以正常使用
兼容性:杯子是否能够容纳果汁、白水、酒精、汽油等
易用性:杯子是否烫手、是否有防滑措施、是否方便饮用
用户文档:使用手册是否对杯子的用法、限制、使用条件等有详细描述
疲劳测试:将杯子盛上水(案例一)放 24 小时检查泄漏时间和情况;盛上汽油(案例二)放 24 小时检查泄漏时间和情况等
压力测试:用根针并在针上面不断加重量,看压强多大时会穿透
7.我手上这支笔,请你根据这支笔设计测试用例
首先我要测它的外观、颜色是否符合要求、所占的空间是多大、是否环保、
接下来测它的质量、这支笔是否能够写字流畅、写出的字的颜色是否符合要求、能使用多长时间等
8.支付流程测试
-
功能测试。
用等价类和边界值,判断支付的金额;
如果没有登陆能否支付,支付成功后是否可以正常跳转;
支付方式是否支持扫码支付,第三方平台支付(支付包,云网等),语音支付,指纹支付;
支付时是否需要身份验证,支付后有无手机短信提示,是否可以找他人代付;
用边界值法有无支付额度限制,余额不足时有无提示,支付时是否是动态加密支付;
待支付状态:订单是否可以正常支付;是否可以取消;有相同订单是否可以支付两次;
是否可以扫码支付,输入错误的密码会怎样显示,有无错误次数限制;
若支持扫码支付,二维码是否支持支付包和微信扫码,若两人同时扫描怎么处理;
有无最小支付金额限制,无意义的支付金额0,重复支付如何处理;
如果支付包含优惠金额,该怎么处理优惠额度; -
性能测试
弱网,无网时是否可以支付;
退款到账时间,耗电量的多少;
带负载情况下的响应时间和吞吐率,在某个时间段内同时访问系统的用户数量 ; -
压力测试
多人同时付款; -
界面测试;
支付界面有无错别字,排版是否合理,颜色搭配是否合理; -
兼容性测试
是否可以跨平台,不同电脑机型下显示有无区别; -
安全性测试;
若支付不成功是否原路退款,若支付成功,有无支付信息提示;
用fiddler抓包尝试修改价格,对订单金额有无校验;
直接输入需要权限的页面地址可用访问; -
接口测试
第三方平台支付
9.请你说一说PC网络故障,以及如何排除障碍
参考回答:
(1)首先是排除接触故障,即确保你的网线是可以正常使用的。然后禁用网卡后再启用,排除偶然故障。打开网络和共享中心窗口,单击窗口左上侧“更改适配器设置”右击其中的“本地连接“或”无线网络连接”,单击快捷菜单中的“禁用”命令,即可禁用所选网络。接下来重启网络,只需右击后单击启用即可。
(2)使用ipconfig查看计算机的上网参数
1、单击“开始|所有程序|附件|命令提示符“,打开命令提示符窗口
2、输入ipconfig,按Enter确认,可以看到机器的配置信息,输入ipconfig/all,可以看到IP地址和网卡物理地址等相关网络详细信息。
(3)使用ping命令测试网络的连通性,定位故障范围
在命令提示符窗口中输入”ping 127.0.0.1“,数据显示本机分别发送和接受了4个数据包,丢包率为零,可以判断本机网络协议工作正常,如显示”请求超时“,则表明本机网卡的安装或TCP/IP协议有问题,接下来就应该检查网卡和TCP/IP协议,卸载后重装即可。
(4)ping本机IP
在确认127.0.0.1地址能被ping通的情况下,继续使用ping命令测试本机的IP地址能否被ping通,如不能,说明本机的网卡驱动程序不正确,或者网卡与网线之间连接有故障,也有可能是本地的路由表面收到了破坏,此时应检查本机网卡的状态是否为已连接,网络参数是否设置正确,如果正确可是不能ping通,就应该重新安装网卡驱动程序。丢失率为零,可以判断网卡安装配置没有问题,工作正常。
(5)ping网关
网关地址能被ping通的话,表明本机网络连接以及正常,如果命令不成功,可能是网关设备自身存在问题,也可能是本机上网参数设置有误,检查网络参数。
10.请你说一下分布式和集群的概念。
分布式:是指将不同的业务分布在不同的地方
集群:是指将几台服务器集中在一起,实现同一业务
分布式中的每一个节点,都可以做集群,而集群并不一定就是分布式的。
集群有组织性,一台服务器垮了,其它的服务器可以顶上来,而分布式的每一个节点,都完成不同的业务,一个节点垮了,那这个业务就不可访问了。
11.请你说一说TCP的数据报结构以及三次握手和四次挥手?
- TCP数据报结构
参考文章:
https://blog.csdn.net/weixin_45393094/article/details/104965561
https://blog.csdn.net/qq_38950316/article/details/81087809
https://blog.csdn.net/weixin_45629285/article/details/121195202
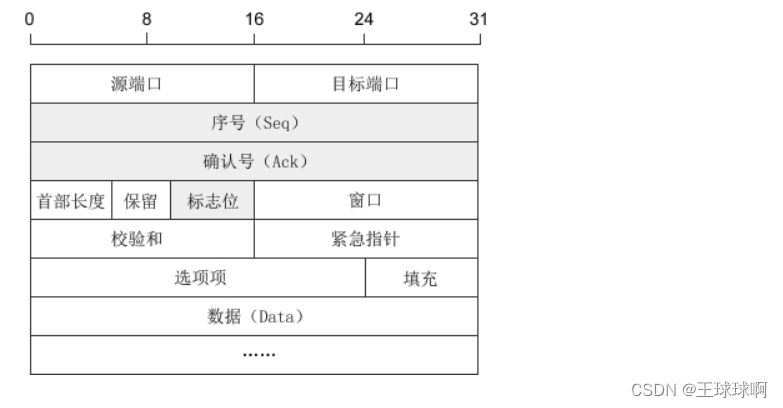
①序号:Seq(Sequence Number)序号占32位,用来标识从计算机A发送到计算机B的数据包的序号,计算机发送数据时对此进行标记。
②确认号:Ack(Acknowledge Number)确认号占32位,客户端和服务器端都可以发送,Ack = Seq + 1。
③标志位:每个标志位占用1Bit,共有6个,分别为 URG、ACK、PSH、RST、SYN、FIN,具体含义如下:
URG:紧急指针(urgent pointer)有效。 为1,表示某一位需要被优先处理
ACK:确认序号有效。
PSH:接收方应该尽快将这个报文交给应用层。
RST:重置连接。
SYN:建立一个新连接。
FIN:断开一个连接。
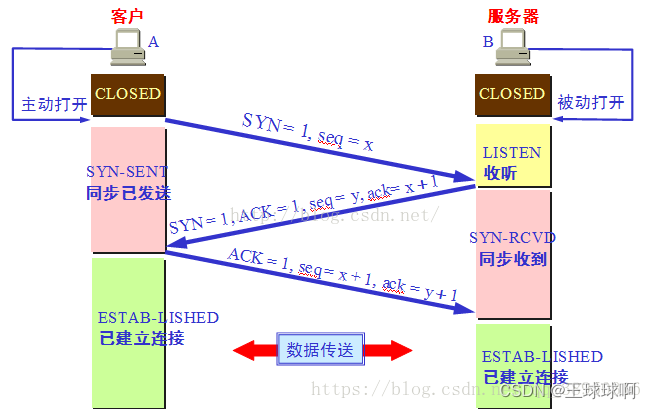
- 三次握手文字总结1
第一次握手:客户端将标志位SYN置为1,随机产生一个值序列号seq=x,并将该数据包发送给服务端,客户端进入syn_sent状态,等待服务端确认。
第二次握手:服务端收到数据包后由标志位SYN=1知道客户端请求建立连接,服务端将标志位SYN和 ACK都置为1,ack=x+1,随机产生一个值序列号seq=y,并将该数据包发送给客户端以确认连接请求,服务端进入syn_rcvd状态。
第三次握手:客户端收到服务端的确认连接请求后检查,如果正确则将标志位ACK置为1,ack=y+1,并将该数据包发送给服务端,服务端进行检查如果正确则连接建立成功,客户端和服务端进入established状态,完成三次握手,随后客户端和服务端之间可以开始传输数据了。
-
三次握手文字总结2
三次握手是 TCP 连接的建立过程。在握手之前,主动打开连接的客户端结束 CLOSE 阶段,被动打开的服务器也结束 CLOSE 阶段,并进入 LISTEN 阶段。随后进入三次握手阶段:① 首先客户端向服务器发送一个 SYN 包,并等待服务器确认,其中:
标志位为 SYN,表示请求建立连接;
序号为 Seq = x(x 一般取随机数);
随后客户端进入 SYN-SENT 阶段。② 服务器接收到客户端发来的 SYN 包后,对该包进行确认后结束 LISTEN 阶段,并返回一段 TCP 报文,其中:
标志位为 SYN 和 ACK,表示确认客户端的报文 Seq 序号有效,服务器能正常接收客户端发送的数据,并同意创建新连接;
序号为 Seq = y;
确认号为 Ack = x + 1,表示收到客户端的序号 Seq 并将其值加 1 作为自己确认号 Ack 的值,随后服务器端进入 SYN-RECV 阶段。③ 客户端接收到发送的 SYN + ACK 包后,明确了从客户端到服务器的数据传输是正常的,从而结束 SYN-SENT 阶段。并返回最后一段报文。其中:
标志位为 ACK,表示确认收到服务器端同意连接的信号;
序号为 Seq = x + 1,表示收到服务器端的确认号 Ack,并将其值作为自己的序号值;
确认号为 Ack= y + 1,表示收到服务器端序号 seq,并将其值加 1 作为自己的确认号 Ack 的值。
随后客户端进入 ESTABLISHED。
当服务器端收到来自客户端确认收到服务器数据的报文后,得知从服务器到客户端的数据传输是正常的,从而结束 SYN-RECV 阶段,进入 ESTABLISHED 阶段,从而完成三次握手。

- 为什么需要三次握手,两次不行吗?
参考文章:https://blog.csdn.net/hyg0811/article/details/102366854
弄清这个问题,我们需要先弄明白三次握手的目的是什么,能不能只用两次握手来达到同样的目的。
第一次握手:客户端发送网络包,服务端收到了。
这样服务端就能得出结论:客户端的发送能力、服务端的接收能力是正常的。
第二次握手:服务端发包,客户端收到了。
这样客户端就能得出结论:服务端的接收、发送能力,客户端的接收、发送能力是正常的。不过此时服务器并不能确认客户端的接收能力是否正常。
第三次握手:客户端发包,服务端收到了。
这样服务端就能得出结论:客户端的接收、发送能力正常,服务器自己的发送、接收能力也正常。
因此,需要三次握手才能确认双方的接收与发送能力是否正常。
试想如果是用两次握手,则会出现下面这种情况:
如客户端发出连接请求,但因连接请求报文丢失而未收到确认,于是客户端再重传一次连接请求。后来收到了确认,建立了连接。数据传输完毕后,就释放了连接,客户端共发出了两个连接请求报文段,其中第一个丢失,第二个到达了服务端,但是第一个丢失的报文段只是在某些网络结点长时间滞留了,延误到连接释放以后的某个时间才到达服务端,此时服务端误认为客户端又发出一次新的连接请求,于是就向客户端发出确认报文段,同意建立连接,不采用三次握手,只要服务端发出确认,就建立新的连接了,此时客户端忽略服务端发来的确认,也不发送数据,则服务端一致等待客户端发送数据,浪费资源。
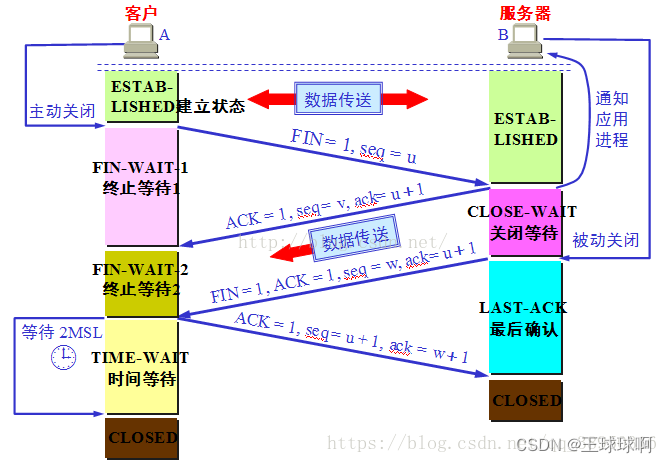
- 四次挥手
初始状态双方ESTABLISHED 。
1.客户端A发送一个FIN,用来关闭客户A到服务器B的数据传送。客户端FIN_WAIT_1。表示主动关闭连接,向对方发送了FIN,进入FIN_WAIT_1,等待对方的确认 。
2.服务器B收到这个FIN,它发回一个ACK,确认序号为收到的序号加1。客户端FIN_WAIT_2,表示半连接,而服务器可能还有数据要发,这边稍后关闭。服务器CLOSE_WAIT。
3.服务器B关闭与客户端A的连接,发送一个FIN给客户端A。服务器LAST_ACK,等待对面的ACK报文。
4.客户端A发回ACK报文确认,并将确认序号设置为收到序号加1。客户端进入TIME_WAIT,表示收到了对方的FIN报文,并发送出了ACK报文,就等2MSL(报文在网络中最大生存时间)后即可回到CLOSED可用状态了。
12.请你说一下在浏览器中输入一个网址它的运行过程是怎样的?
-
查询DNS,获取域名对应的IP。
(1)检查浏览器缓存、检查本地hosts文件是否有这个网址的映射,如果有,就调用这个IP地址映射,解析完成。 (2)如果没有,则查找本地DNS解析器缓存是否有这个网址的映射,如果有,返回映射,解析完成。 (3)如果没有,则查找填写或分配的首选DNS服务器,称为本地DNS服务器。服务器接收到查询时: 如果要查询的域名包含在本地配置区域资源中,返回解析结果,查询结束,此解析具有权威性。 如果要查询的域名不由本地DNS服务器区域解析,但服务器缓存了此网址的映射关系,返回解析结果,查询结束,此解析不具有权威性。 (4)如果本地DNS服务器也失效: 如果未采用转发模式(迭代),本地DNS就把请求发至13台根DNS,根DNS服务器收到请求后,会判断这个域名(如.com)是谁来授权管理,并返回一个负责该顶级域名服务器的IP,本地DNS服务器收到顶级域名服务器IP信息后,继续向该顶级域名服务器IP发送请求,该服务器如果无法解析,则会找到负责这个域名的下一级DNS服务器(如http://baidu.com)的IP给本地DNS服务器,循环往复直至查询到映射,将解析结果返回本地DNS服务器,再由本地DNS服务器返回解析结果,查询完成。 如果采用转发模式(递归),则此DNS服务器就会把请求转发至上一级DNS服务器,如果上一级DNS服务器不能解析,则继续向上请求。最终将解析结果依次返回本地DNS服务器,本地DNS服务器再返回给客户机,查询完成。 -
得到目标服务器的IP地址及端口号(http 80端口,https 443端口),会调用系统库函数socket,请求一个TCP流套接字。客户端向服务器发送HTTP请求报文:
(1)应用层:客户端发送HTTP请求报文。 (2)传输层:(加入源端口、目的端口)建立连接。实际发送数据之前,三次握手客户端和服务器建立起一个TCP连接。 (3)网络层:(加入IP头)路由寻址。 (4)数据链路层:(加入frame头)传输数据。 (5)物理层:物理传输bit。 -
服务器端经过物理层→数据链路层→网络层→传输层→应用层,解析请求报文,发送HTTP响应报文。
-
关闭连接,TCP四次挥手。
-
客户端解析HTTP响应报文,浏览器开始显示HTML
13.请你说一说http请求报文以及http和https的区别
- http请求报文
http请求报文主要包含以下几部分:
-
请求方法
GET:请求获取Request URL所标识的资源
POST:在Request URL所标识的资源后附加资源
HEAD:请求获取由Request URL所标识的资源的响应消息报头
PUT:请求服务器存储一个资源,由Request URL作为其标识
DELETE:请求服务器删除由Request URL所标识的资源
TRACE:请求服务器回送收到的请求信息(用于测试和诊断)
CONNECT:保留
OPTIONS:请求查询服务器性能 -
URL
URI全名为Uniform Resource Indentifier(统一资源标识),用来唯一的标识一个资源,是一个通用的概念,URI由两个主要的子集URL和URN组成。URL全名为Uniform Resource Locator(统一资源定位),通过描述资源的位置来标识资源。URN全名为Uniform Resource Name(统一资源命名),通过资源的名字来标识资源,与其所处的位置无关,这样即使资源的位置发生变动,其URN也不会变化。 -
协议版本
格式为HTTP/主版本号.次版本号,常用为:HTTP/1.1 HTTP/1.0 -
请求头部
Host:接受请求的服务器地址,可以是IP或者是域名
User-Agent:发送请求的应用名称
Connection:指定与连接相关的属性,例如(Keep_Alive,长连接)
Accept-Charset:通知服务器端可以发送的编码格式
Accept-Encoding:通知服务器端可以发送的数据压缩格式
Accept-Language:通知服务器端可以发送的语言
- http和https的区别
1、连接方式:HTTP 和 HTTPS 使用连接方式不同,默认端口也不一样,HTTP是80,HTTPS是443。Http连接是非常简单和无状态的;HttpS协议是基于HTTP使用SSL/TLS进行了加密的网络协议。
2、安全:HTTPS是HTTP协议的安全版本,HTTP协议的数据传输是明文的,是不安全的,HTTPS使用了SSL/TLS协议进行了加密处理,相对更安全
3、性能:HTTPS 由于需要涉及加密以及多次握手,性能方面不如 HTTP
4、成本:HTTPS需要SSL,SSL 证书需要钱,功能越强大的证书费用越高
http是超文本传输协议,信息是明文传输, https则具安全性的ssl/tls加密传输协议。
1.Http和https使用完全不同的连接方法和不同的端口。前者是80,后者是443。Http连接是非常简单和无状态的;HttpS协议是由SSL/TLS+HTTP协议构建的网络协议,可用于加密传输和身份认证。它比HTTP协议更安全。
2.超文本传输协议,缩写为HTTP,是分布式、协作式和超媒体信息系统的应用层协议,是万维网数据通信的基础,也是互联网上使用最广泛的网络传输协议。HTTP最初被设计为提供一种发布和接收HTML页面的方式。
3.HTTPS协议之所以安全,是因为HTTPS协议对传输的数据进行加密,而加密过程是由非对称加密实现的。然而,HTTPS在内容传输的加密过程中使用对称加密,而非对称加密只在证书验证阶段发挥作用。
14.请你说一说get和 post区别
GET:从指定的资源请求数据。
POST:向指定的资源提交要被处理的数据。
由于HTTP的规定和浏览器/服务器的限制,导致它们在应用过程中体现出一些不同。

14.1 get请求缓存解决办法
- 问题描述
vue脚手架创建的项目在ie浏览器中打开,发现所有的编辑操作完成后提示修改成功,代码中主动重新调用了新的列表,但是页面并没有刷新。
- 寻找原因
通过发送请求,查看控制台发现,接口已经调用,但是没有返回结果。由此可以推断,浏览器是取用了缓存,并没有真实的向服务器发送请求。(只有get请求是有缓存的,post请求默认cache-control:no-cache)
- 解决办法
方法一:加时间戳。在拦截器上判断当前请求只要是get请求,就添加一个时间戳,保证每次的请求都是不一样的,从而使得浏览器不得不去向服务器发送请求。
方法二:设置请求头清除缓存。但是这个方法可能需要后端的配合。后端需要在Access-Control-Allow-Header里面添加cache-control这个字段,
这样前端传递该字段才有效果,否则即使前端传递了该参数,后端也是不能接收的。
方法三:在header里添加标签
<meta http-equiv="Pragma" content="no-cache"/>
<meta http-equiv="Cache-Control" content="no-store"/>
<meta http-equiv="Pragma" content="no-cache"/>
<meta http-equiv="Expires" content="0"/>
缺点:部分ie浏览器可能不兼容
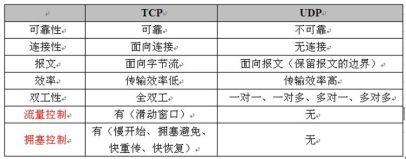
15.请你说一下tcp和udp的区别
参考回答:
1、TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
2、TCP提供可靠的服务。也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保 证可靠交付
3、TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的,应用层交给UDP多长的报文,UDP就照样发送,即一次发送一个报文。UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
4、每一条TCP连接只能是点到点的;UDP支持一对一,一对多,多对一和多对多的交互通信
5、TCP首部开销20字节;UDP的首部开销小,只有8个字节
6、TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道


16.请你说一下为什么tcp可靠,哪些方法保证可靠
-
确认和重传机制
建立连接时三次握手同步双方的“序列号 + 确认号 + 窗口大小信息”,是确认重传、流控的基础传输过程中,如果Checksum校验失败、丢包或延时,发送端重传。
-
数据排序
TCP有专门的序列号SN字段,可提供数据re-order
-
流量控制
滑动窗口和计时器的使用。TCP窗口中会指明双方能够发送接收的最大数据量,发送方通过维持一个发送滑动窗口来确保不会发生由于发送方报文发送太快接收方无法及时处理的问题。
-
拥塞控制
TCP的拥塞控制由4个核心算法组成:
“慢启动”(Slow Start)
“拥塞避免”(Congestion avoidance)
“快速重传 ”(Fast Retransmit)
“快速恢复”(Fast Recovery)
17.请你说说HTTP状态码
状态码,100~199表示请求已收到继续处理,200~299表示成功,300~399表示资源重定向,400~499表示客户端请求出错,500~599表示服务器端出错
200:响应成功
302:跳转,重定向
400:客户端有语法错误
403:服务器拒绝提供服务
404:请求资源不存在
500:服务器内部错误
1xx:请求正常,但是无响应,只有在实验状态下使用
2xx:2开头的表示发送成功
3xx:3开头的代表重定向,常见302
4xx:400代表客户端发送的语法有错误,401代表访问的页面没有授权,403 无权限访问该网页,404代表没有这个页面,415 格式错误
5xx:5开头的代表服务器异常,500代表服务器内部异常,504代表服务器超时
18.请你介绍下session
参考回答:
Session:在web开发中,服务器可以为每个用户创建一个会话对象(session对象),默认情况下一个浏览器独占一个session对象,因此在需要保存用户数据时,服务器程序可以把用户数据写到用户浏览器独占的session中,当用户使用浏览器访问其他程序时,其他程序可以从用户的session中取出该用户的数据,为用户服务,其实现原理是服务器创建session出来后,会把session的id号,以cookie的形式回写给客户机,这样只要客户机的浏览器不关,再去访问服务器时,都会带着session的id号去,服务器发现客户机浏览器带session id过来了,就会使用内存中与之对应的session服务。
19.Session和cookie的区别:
- 作用范围不同:cookie数据存放在客户的浏览器上,session数据放在服务器上,session会在一定时间内保存在服务器上,当访问增多,会比较占用服务器的性能,考虑到减轻服务器性能方面,应当使用cookie
- 隐私策略不同:cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗,考虑到安全应当使用session
- 存取方式不同:cookie只能保存ASCII,session可以保存任意类型的数据
- 有效期不同:cookie可设置为长时间保持,例如默认登陆,session一般失效时间较短,客户端关闭或者session超时都会失效
- 存储大小不同:单个cookie保存的数据不能超过4k,很多浏览器都限制一个站点最多保存20个cookie,session可存储的数据远高于cookie
20.请问你知道跨域吗,条件是什么,在header里需要加什么,有几种方案
参考回答:
什么是跨域?
浏览器从一个域名的网页去请求另一个域名的资源时,域名、端口、协议任一不同,都是跨域
跨域的几种方案:
1:基于script标签实现跨域
3: 基于jquery跨域
4: 通过iframe来跨子域
21.请你说一下进程和线程的区别
参考回答:
进程:是具有一定独立功能的程序、它是系统进行资源分配和调度的一个独立单位,重点在系统调度和单独的单位,也就是说进程是可以独立运行的一段程序。
线程:是进程的一个实体,是CPU调度和分派的基本单位,比进程更小的能独立运行的基本单位,线程自己基本上不拥有系统资源,在运行时,只是暂用一些计数器、寄存器和栈 。线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间。
一个程序至少有一个进程,一个进程至少有一个线程。
22.请你说一下多进程、多线程,操作系统层面的差别和联系
参考回答:
进程:进程是一个具有一定独立功能的程序在一个数据集上的一次动态执行的过程,是操作系统进行资源分配和调度的一个独立单位,是应用程序运行的载体。进程是一种抽象的概念,从来没有统一的标准定义。进程一般由程序、数据集合和进程控制块三部分组成。程序用于描述进程要完成的功能,是控制进程执行的指令集;数据集合是程序在执行时所需要的数据和工作区;程序控制块(Program Control Block,简称PCB),包含进程的描述信息和控制信息,是进程存在的唯一标志。
线程:在早期的操作系统中并没有线程的概念,进程是能拥有资源和独立运行的最小单位,也是程序执行的最小单位。任务调度采用的是时间片轮转的抢占式调度方式,而进程是任务调度的最小单位,每个进程有各自独立的一块内存,使得各个进程之间内存地址相互隔离。后来,随着计算机的发展,对CPU的要求越来越高,进程之间的切换开销较大,已经无法满足越来越复杂的程序的要求了。于是就发明了线程,线程是程序执行中一个单一的顺序控制流程,是程序执行流的最小单元,是处理器调度和分派的基本单位。一个进程可以有一个或多个线程,各个线程之间共享程序的内存空间(也就是所在进程的内存空间)。一个标准的线程由线程ID、当前指令指针(PC)、寄存器和堆栈组成。而进程由内存空间(代码、数据、进程空间、打开的文件)和一个或多个线程组成。
差别:1.线程是程序执行的最小单位,而进程是操作系统分配资源的最小单位;2.一个进程由一个或多个线程组成,线程是一个进程中代码的不同执行路线;3.进程之间相互独立,但同一进程下的各个线程之间共享程序的内存空间(包括代码段、数据集、堆等)及一些进程级的资源(如打开文件和信号),某进程内的线程在其它进程不可见;4.调度和切换:线程上下文切换比进程上下文切换要快得多。
联系:原则上一个CPU只能分配给一个进程,以便运行这个进程。通常使用的计算机中只有一个CPU,同时运行多个进程,就必须使用并发技术。通常采用时间片轮转进程调度算法,在操作系统的管理下,所有正在运行的进程轮流使用CPU,每个进程允许占用CPU的时间非常短(比如10毫秒),这样用户根本感觉不出来CPU是在轮流为多个进程服务,就好象所有的进程都在不间断地运行一样。但实际上在任何一个时间内有且仅有一个进程占有CPU。如果一台计算机有多个CPU,情况就不同了,如果进程数小于CPU数,则不同的进程可以分配给不同的CPU来运行,这样,多个进程就是真正同时运行的,这便是并行。但如果进程数大于CPU数,则仍然需要使用并发技术。在Windows中,进行CPU分配是以线程为单位的,一个进程可能由多个线程组成。操作系统将CPU的时间片分配给多个线程,每个线程在操作系统指定的时间片内完成(注意,这里的多个线程是分属于不同进程的).操作系统不断的从一个线程的执行切换到另一个线程的执行,如此往复,宏观上看来,就好像是多个线程在一起执行.由于这多个线程分属于不同的进程,就好像是多个进程在同时执行,这样就实现了多任务。总线程数<=CPU数量时并行运行,总线程数>CPU数量时并发运行。并行运行的效率显然高于并发运行,所以在多CPU的计算机中,多任务的效率比较高。但是,如果在多CPU计算机中只运行一个进程(线程),就不能发挥多CPU的优势。
23.请你说一下死锁的概念、原因、解决方法
参考回答:
1、死锁是指在一组进程中的各个进程均占有不会释放的资源,但因互相申请被其他进程所站用不会释放的资源而处于的一种永久等待状态。死锁的四个必要条件:
• 互斥条件(Mutual exclusion):资源不能被共享,只能由一个进程使用。
• 请求与保持条件(Hold and wait):已经得到资源的进程可以再次申请新的资源。
• 非剥夺条件(No pre-emption):已经分配的资源不能从相应的进程中被强制地剥夺。
• 循环等待条件(Circular wait):系统中若干进程组成环路,该环路中每个进程都在等待相邻进程正占用的资源。
java中产生死锁可能性的最根本原因是:1)是多个线程涉及到多个锁,这些锁存在着交叉,所以可能会导致了一个锁依赖的闭环;2)默认的锁申请操作是阻塞的。
如,线程在获得一个锁L1的情况下再去申请另外一个锁L2,也就是锁L1想要包含了锁L2,在获得了锁L1,并且没有释放锁L1的情况下,又去申请获得锁L2,这个是产生死锁的最根本原因。
2、避免死锁:
• 方案一:破坏死锁的循环等待条件。
• 方法二:破坏死锁的请求与保持条件,使用lock的特性,为获取锁操作设置超时时间。这样不会死锁(至少不会无尽的死锁)
• 方法三:设置一个条件遍历与一个锁关联。该方法只用一把锁,没有chopstick类,将竞争从对筷子的争夺转换成了对状态的判断。仅当左右邻座都没有进餐时才可以进餐。提升了并发度。
24.各数据类型的长度(java)
8种基本数据类型为:
4种整形:byte,short,int,long
2种浮点类型:float,double
1种Unicode编码的字符单元的字符型:char
1中Boolean类型:boolean
8中类型所占字节和位数和取值范围如下:
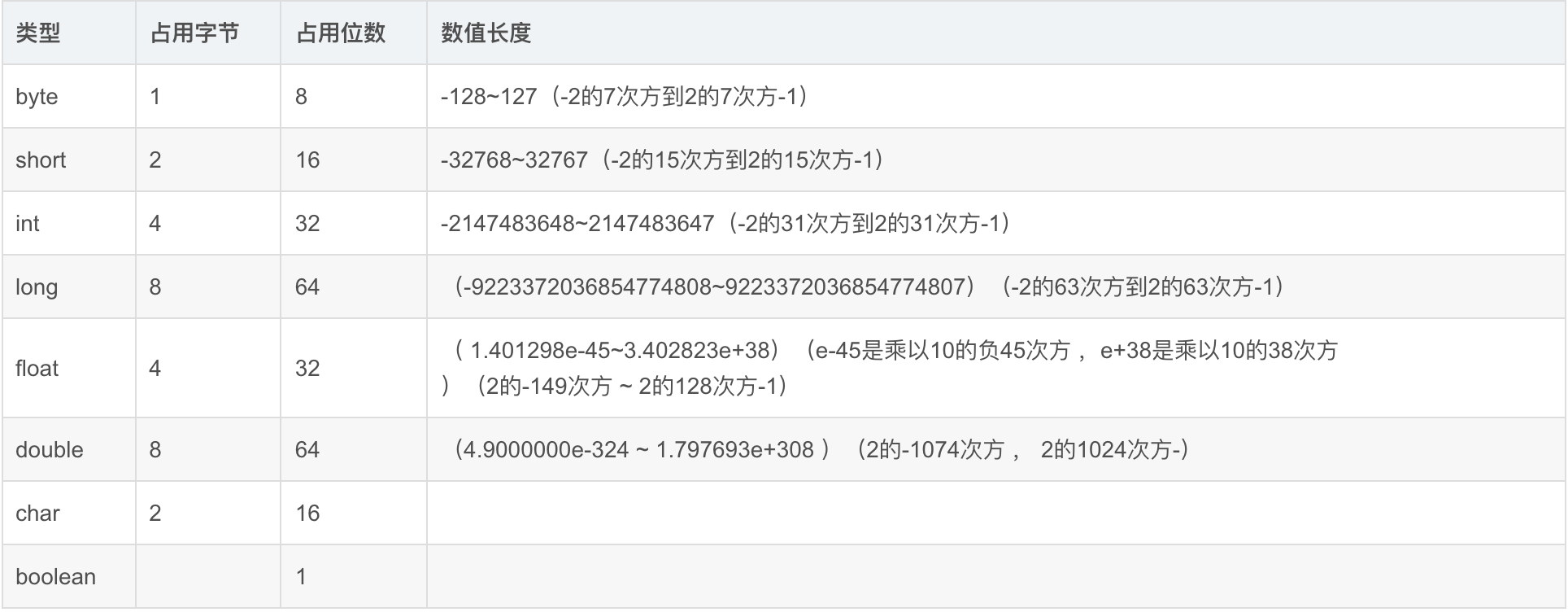
1 byte = 1字节 = 8bit
25.七层模型
应用层、表示层、会话层、传输层、网络层、数据链路层、物理层
数据库相关面试题
1.说一下mysql删除语句
-
drop语句。可以用来删除数据库和表。
用drop语句来删除数据库:drop database db;
用drop语句来删除表:drop table tb; -
delete语句。用来删除表中的字段。
delete from tb where id=1;
如果delete语句中没有加入where就会把表中的所有记录全部删除: -
用truncate来删除表中的所有字段.
truncate table tb;
2.问count和sum的区别,以及count(*)和count(列名)的区别
- count和sum区别
求和用累加sum(),求行的个数用累计count
- count(*)和count(列名)的区别
count(*)包括了所有的列,在统计结果的时候不会忽略列值为null
count(列名)只包括列名那一项,会忽略列值为空的计数
3.讲一下where和having的区别
1、WHERE是先分组再筛选记录,WHERE在聚合前先筛选记录.也就是说作用在GROUP BY 子句和HAVING子句前;而 HAVING子句在聚合后对组记录进行筛选。
2、在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与合计函数一起使用。而HAVING子句中可以。HAVING 子句是聚组函数唯一出现的地方。
3、在查询过程中聚合语句(SUM,MIN,MAX,AVG,COUNT)要比HAVING子句优先执行。而WHERE子句在查询过程中执行优先级高于聚合语句。
4、HAVING 子句中的每一个元素必须出现在SELECT列表中。
4.请你说一下数据库mysql中CHAR和VCHAR的区别
-
char(n)类型
char类型是定长的类型,即当定义的是char(10),输入的是"abc"这三个字符时,它们占的空间一样是10个字节,包括7个空字节。当输入的字符长度超过指定的数时,char会截取超出的字符。而且,当存储char值时,MySQL是自动删除输入字符串末尾的空格。 char是适合存储很短的、一般固定长度的字符串。例如,char非常适合存储密码的MD5值,因为这是一个定长的值。对于非常短的列,char比varchar在存储空间上也更有效率。取数据的时候,char类型的要用trim()去掉多余的空格,而varchar是不需要。 -
varchar(n)类型
varchar(n)类型用于存储可变长的,长度为n个字节的可变长度且非Unicode的字符数据。n必须是介于1和8000之间的数值,存储大小为输入数据的字节的实际长度+1/2. 比如varchar(10), 然后输入abc三个字符,那么实际存储大小为3个字节。除此之外,varchar还需要使用1或2个额外字节记录字符串的长度,如果列的最大长度小于等于255字节(是定义的最长长度,不是实际长度),则使用1个字节表示长度,否则使用2个字节来表示。取数据的时候,不需要去掉多余的空格。
5.请问什么是数据库事务
数据库事务是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。一个数据库事务通常包含了一个序列的对数据库的读/写操作。它的存在包含有以下两个目的:
- 为数据库操作序列提供了一个从失败中恢复到正常状态的方法,同时提供了数据库即使在异常状态下仍能保持一致性的方法。
- 当多个应用程序在并发访问数据库时,可以在这些应用程序之间提供一个隔离方法,以防止彼此的操作互相干扰。
当事务被提交给了DBMS(数据库管理系统),则DBMS(数据库管理系统)需要确保该事务中的所有操作都成功完成且其结果被永久保存在数据库中,如果事务中有的操作没有成功完成,则事务中的所有操作都需要被回滚,回到事务执行前的状态;同时,该事务对数据库或者其他事务的执行无影响,所有的事务都好像在独立的运行。
6.说一下数据库事务的四个特性
数据库事务拥有以下四个特性,被称之为ACID特性:
- 原子性(Atomicity):事务作为一个整体被执行,包含在其中的对数据库的操作要么全部被执行,要么都不执行。
- 一致性(Consistency):事务应确保数据库的状态从一个一致状态转变为另一个一致状态。一致状态的含义是数据库中的数据应满足完整性约束。
- 隔离性(Isolation):多个事务并发执行时,一个事务的执行不应影响其他事务的执行。
- 持久性(Durability):已被提交的事务对数据库的修改应该永久保存在数据库中。
7.请问什么是幻读
幻读就是指当一个事务正在访问数据,并且对数据进行了修改,但是还没有来得及提交到数据库中,这时,另一个事务也访问这个数据,然后使用了这个数据
8.请你说一下事务的隔离级别,以及你一般使用的事务是哪种
事务的隔离性及时同一时间只允许一个事务请求同一数据,不同事物之间彼此没有任何干扰,
事务隔离级别如下:

9.索引相关
版权声明:本文为CSDN博主「后端元宇宙」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/yudiandemingzi/article/details/122329773
- 什么是索引
索引其实是一种数据结构,能够帮助我们快速的检索数据库中的数据。
- 索引的优缺点
优点:
1.提高数据检索的效率,降低数据库IO成本。
2.通过索引对数据进行排序,降低数据的排序成本,降低CPU的消耗。
缺点:
1.建立索引需要占用物理空间
2.会降低表的增删改的效率,因为每次对表记录进行增删改,需要进行动态维护索引,导致增删改时间变长
- 什么情况下需要建索引?
- 主键自动创建唯一索引
- 较频繁的作为查询条件的字段
- 查询中排序的字段,查询中统计或者分组的字段
- 什么情况下不建索引?
- 表记录太少的字段
- 经常增删改的字段
- 唯一性太差的字段,不适合单独创建索引。比如性别,民族,政治面貌
- 索引主要有哪几种分类?
MySQL主要的几种索引类型:1.普通索引 2.唯一索引 3.主键索引 4.组合索引 5.全文索引。
- 普通索引: 是最基本的索引,它没有任何限制
- 唯一索引: 索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一
- 主键索引: 是一种特殊的唯一索引,一个表只能有一个主键,不允许有空值。
- 组合索引: 一个索引包含多个列,实际开发中推荐使用组合索引。
- 全文索引: 全文搜索的索引。FULLTEXT 用于搜索很长一篇文章的时候,效果最好。只能用于InnoDB或MyISAM表,只能为CHAR、VARCHAR、TEXT列创建。
- 主键索引和唯一索引的区别:
- 主键必唯一,但是唯一索引不一定是主键;
- 一张表上只能有一个主键,但是可以有一个或多个唯一索引。
- 索引失效场景有哪些?
理解了上面聚集索引相对于非聚集索引的树的结构,对于什么时候索引会失效,理解起来就不那么难了。
- 组合索引未使用最左前缀,例如组合索引(age,name),where name='张三’不会使用索引;
- or会使索引失效。如果查询字段相同,也可以使用索引。例如where age=20 or age=30(索引生效),where age=20 or name=‘张三’(这里就算你age和name都单独建索引,还是一样失效);
- 如果列类型是字符串,不使用引号。例如where name=张三(索引失效),改成where name=‘张三’(索引有效);
- like未使用最左前缀,where A like ‘%China’;
- 在索引列上做任何操作计算、函数,会导致索引失效而转向全表扫描;
- 如果mysql估计使用全表扫描要比使用索引快,则不使用索引;
- 索引的设计原则
- 索引列的区分度越高,索引的效果越好。比如使用性别这种区分度很低的列作为索引,效果就会很差。
- 尽量使用短索引,对于较长的字符串进行索引时应该指定一个较短的前缀长度,因为较小的索引涉及到的磁盘I/O较少,查询速度更快。
- 索引不是越多越好,每个索引都需要额外的物理空间,维护也需要花费时间。
- 利用最左前缀原则。
10.请问如何对数据库作优化
- 调整数据结构的设计,对于经常访问的数据库表建立索引;
- 调整SQL语句,ORACLE公司推荐使用ORACLE语句优化器(Oracle Optimizer)和行锁管理器(row-level manager)来调整优化SQL语句;
- 调整服务器内存分配。内存分配是在信息系统运行过程中优化配置的,数据库管理员可以根据数据库运行状况调整数据库系统全局区(SGA区)的数据缓冲区、日志缓冲区和共享池的大小;还可以调整程序全局区(PGA区)的大小;
- 调整硬盘I/O,DBA可以将组成同一个表空间的数据文件放在不同的硬盘上,做到硬盘之间I/O负载均衡。
11.请问对缓存技术了解吗(请你说说redis)
Redis可以实现缓存机制,
Redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、 list(链表)、set(集合)和zset(有序集合)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步,当前 Redis的应用已经非常广泛,国内像新浪、淘宝,国外像 Flickr、Github等均在使用Redis的缓存服务。
Redis 工作方式分析
Redis作为一个高性能的key-value数据库具有以下特征:
1、多样的数据模型
2、持久化
3、主从同步
Redis支持丰富的数据类型,最为常用的数据类型主要由五种:String、Hash、List、Set和Sorted Set。Redis通常将数据存储于内存中,或被配置为使用虚拟内存。Redis有一个很重要的特点就是它可以实现持久化数据,通过两种方式可以实现数据持久化:使用RDB快照的方式,将内存中的数据不断写入磁盘;或使用类似MySQL的AOF日志方式,记录每次更新的日志。前者性能较高,但是可能会引起一定程度的数据丢失;后者相反。 Redis支持将数据同步到多台从数据库上,这种特性对提高读取性能非常有益。
12.mysql练习题
参考文章:https://www.jianshu.com/p/d849b2b4a819
13.数据库熟吗?用过哪些数据库?索引会吗?事务了解吗?写一个 SQL 查询语句:给一个字段,对其进行从大到小排序,取前十行。
我平时的工作中会协助提高数据库的查询效率,会给数据 id 等创建索引; 事务开发那边用的比较多,然后我举了 ATM 机取款的例子。 SQL 语句如下 selectfieldfromtable orderbyfield desc limit10
14.redis常用操作
参考文章:
https://blog.csdn.net/yy12345_6_/article/details/124177795
https://blog.csdn.net/jsugs/article/details/124021447
-
启动Redis
#redis-server [--port 6379]如果命令参数过多,建议通过配置文件来启动Redis。
#redis-server [xx/xx/redis.conf]6379是Redis默认端口号。
-
连接Redis客户端
#./redis-cli [-h 127.0.0.1 -p 6379 <-a password>] -
停止Redis
#redis-cli shutdown #kill redis-pid以上两条停止Redis命令效果一样。
-
发送命令
给Redis发送命令有两种方式:
4.1.redis-cli带参数运行,如下,这样默认是发送到本地的6379端口。:#redis-cli shutdown not connected#4.2. redis-cli不带参数运行,如:
#./redis-cli 127.0.0.1:6379#shutdown not connected# -
测试连通性
127.0.0.1:6379#ping PONG
14.1.Redis的key的操作命令
-
语法:keys pattern
作用:查找所有符合模式pattern的key。pattern可以使用通配符。
通配符:*(匹配0到多个字符),?(匹配一个字符),[](匹配括号中的一个字符)

-
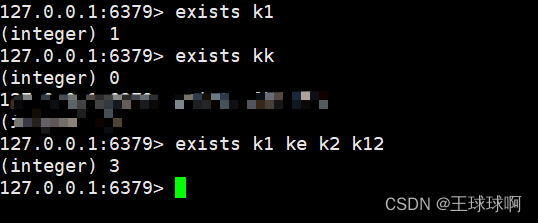
语法:exists key
作用:判断1个key是否存在,存在返回1,不存在返回0。
exists key [key key …];判断多个key是否存在,返回存在的个数。
-
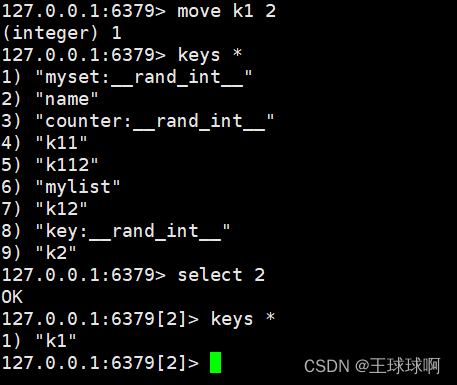
语法:move key index
作用:移动指定的key到指定的数据库实例(Redis默认有16个库),用户默认使用第0个库
-
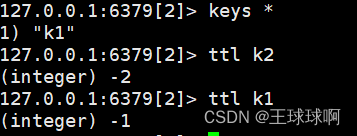
语法:ttl key
返回值:-1表示没有设置生存时间;-2表示该key不存在
作用:查看key的剩余生存时间
-
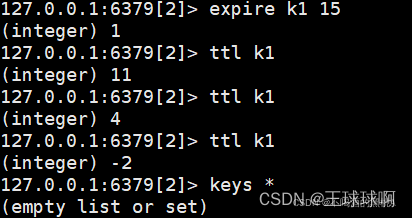
语法:expire key seconds
作用:设置key的最大生存时间
-
语法:type key
作用:查看指定key的数据类型

-
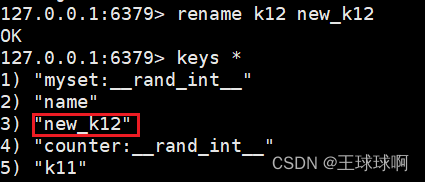
语法:rename key newkey
作用:重命名指定key
-
语法:del key:删除一个key;del key [key key …]:删除多个key
作用:删除指定key和value
返回值:删除实际删除数据条数

-
语法:decrby key num
作用:减去指定值 -
语法:incrby key num
作用:增加指定值
14.2.字符串类型:string(key-value)
- 添加数据:set key value;(如果key以存在,之前的value将会被覆盖)
- 获取指定key的值:get key;
- 追加字符串:append key value;返回字符串长度;(如果key不存在,则存储为新的key)
- 获取字符串长度:strlen key;
- 将value数值加一:incr key;返回计算后的值;(如果该值不是数值,将报错;如果key不存在,则自动存储新的key,并初始化为0,然后加一);
- 将value数值减一:decr key;用法同上;
- 将value数值加某一具体值:incrby key increment;
- 将value数值减某一具体值:decrby key increment;
- 闭区间截取字符串中的某一段:getrange key startIndex endIndex;(下标从0开始,最后一个字符的下标为-1或字符串长度减1)
- 用新的value覆盖从某一下标开始的字符串:setrange key offset value;
- 添加新的数据并同时设置生命周期:setex key seconds value;
- 当key值不存在时添加数据:setnx key value;key值不存在时添加,返回结果1;key值已存在不添加,返回结果0;
- 批量添加新的数据:mset key1 value1 key2 value2 key3 value3(中间使用空格隔开)
- 批量获取数据:mget key1 key2 key3 (中间使用空格隔开)
- 批量添加key不存在的数据:msetnx key1 value1 key2 value2…(所有key都不存在设置成功,只要有一个存在设置失败)
14.3.列表类型:list(key:value1 value2…)有序可重复列表
- 将一个或多个值依次插入列表的表头:lpush key value1 value2 …(若该key已存在,将新值追加在原来的列表中)(l:left)
- 获取列表中指定下标区间的元素:lrange key startIndex endIndex
- 将一个或多个值依次插入列表的表尾:rpush key value1 value2 …(若该key已存在,将新值追加在原来的列表中)(r:right)
- 删除指定列表的表头元素并返回:lpop key;
- 删除指定列表的表尾元素并返回:rpop key;
- 获取指定列表中指定下标的元素并返回:lindex key index
- 获取指定列表的长度:llen key
- 根据count的值移除列表中的指定的某一些元素:lrem key count value(count>0:从表头开始数前n个;count<0:从表尾开始数前n个;count=0:移除所有跟value相同的元素)【n=count】
14.4.集合类型:set(key:member1 member2…)value无序,并且不能重复
- 将一个或多个元素添加到指定的集合中:sadd key member1 member2…
- 获取指定集合中的所有元素:smembers key
- 判断指定元素在指定集合中是否存在:sismember key member; 存在返回1,不存在返回0;
- 获取指定集合的长度:scard key
- 移除指定集合中一个或者多个元素:srem key member1 member2…(不存的元素会忽略)
- 随机获取指定集合中的n个元素:srandmember key [count];(count不指定,默认为1;count>0:随机获取的数不重复,count<0:随机获取的数可能重复)
- 从指定集合中随机移除一个或者多个元素:spop key [count](count不指定,默认为1);
- 从指定集合中移动指定一个元素到另一个集合中:smove source destination member;
- 返回差集(一个集合中有,其他集合没有):sdiff key key…
- 返回交集(两个集合共同存在的值):sinter key1 key2…
- 返回并集(两个集合所有值):sunion key1 key2…
14.5. 双列集合:hash(单key:filed-value filed-value…)
- 将一个或多个键值对存储到指定集合中:hset key filed value …
- 获取hash表中指定的filed值:hget key filed;
- 批量获取hash表中指定的filed值:hmget key filed1 filed2…;
- 获取指定hash表中的所有filed和value:hgetall key;
- 删除指定hash表中的一个或者多个filed:hdel key filed1 filed2…
- 获取指定hash表中所有的filed的个数:hlen key
- 判断指定hash表中指定的filed是否存在:hexists key filed
- 获取指定hash表中所有filed的列表:hkeys key;
- 获取指定hash表中所有value的值:hvals key;
14.6.有序单列集合:zset()value会根据关联的分数进行排序,不能重复
- 将一个或者多个member及score加入有序集合:zadd key score1 member1 score2 member2 …
- 根据指定集合获取指定区间的元素:zrange key startindex endindex
- 根据指定分数区间获取元素:zrangebyscore key min max
- 删除指定集合中一个或多个指定元素:zrem key member1 member2…
- 获取集合中元素的个数:zcard key
- 获取指定元素的排名:zrank key member(排名从0开始) zrevrank(倒叙排名:从大到小)
- 获取指定集合中在指定分数区间的元素个数:zcount key min max
- 获取指定集合中的指定元素的分数:zscore key member
15.关系型数据库和非关系型数据库简介
参考文章:https://www.yisu.com/zixun/37712.html
关系型数据库是基于关系模型提出来的数据库。那么什么是关系模型呢?以行和列的方式二维表的方式存储数据的模型就是关系型数据库。例如:mysql、oracle、SQL server
非关系型数据库(NoSQL即Not-Only SQL)可以作为关系型数据库的良好补充。随着互联网web网站的兴起,关系型数据库暴露的缺点越来越多,比如对数据库高并发读写,对海量数据的高效率存储和访问。常见的非关系型数据库有redis、mongoDB
16.常见的非关系型数据库有哪些
参考文章:https://www.yisu.com/zixun/321198.html
1、MongoDB
MongoDB是最著名的NoSQL数据库。它是一个面向文档的开源数据库。MongoDB是一个可伸缩和可访问的数据库。它在c++中。MongoDB同样可以用作文件系统。在MongoDB中,JavaScript可以作为查询语言使用。通过使用sharding MongoDB水平伸缩。它在流行的JavaScript框架中非常有用。
人们真的很享受分片、高级文本搜索、gridFS和map-reduce功能。惊人的性能和新特性使这个NoSQL数据库在我们的列表中名列第一。
特点:提供高性能;自动分片;运行在多个服务器上;支持主从复制;数据以JSON样式文档的形式存储;索引文档中的任何字段;由于数据被放置在碎片中,所以它具有自动负载平衡配置;支持正则表达式搜索;在失败的情况下易于管理。
优点:易于安装MongoDB;MongoDB Inc.为客户提供专业支持;支持临时查询;高速数据库;无模式数据库;横向扩展数据库;性能非常高。
缺点:不支持连接;数据量大;嵌套文档是有限的;增加不必要的内存使用。
2、Cassandra
Cassandra是Facebook为收件箱搜索开发的。Cassandra是一个用于处理大量结构化数据的分布式数据存储系统。通常,这些数据分布在许多普通服务器上。您还可以添加数据存储容量,使您的服务保持在线,您可以轻松地完成这项任务。由于集群中的所有节点都是相同的,因此不需要处理复杂的配置。
Cassandra是用Java编写的。Cassandra查询语言(CQL)是查询Cassandra数据库的一种类似sql的语言。因此,Cassandra在最佳开源数据库中排名第二。Facebook、Twitter、思科(Cisco)、Rackspace、eBay、Twitter、Netflix等一些最大的公司都在使用Cassandra。
特点:线性可伸缩;;保持快速响应时间;支持原子性、一致性、隔离性和耐久性(ACID)等属性;使用Apache Hadoop支持MapReduce;分配数据的最大灵活性;高度可伸缩;点对点架构。
优点:高度可伸缩;无单点故障;Multi-DC复制;与其他基于JVM的应用程序紧密集成;更适合多数据中心部署、冗余、故障转移和灾难恢复。
缺点:对聚合的有限支持;不可预知的性能;不支持特别查询。
3、Redis
Redis是一个键值存储。此外,它是最著名的键值存储。Redis支持一些c++、PHP、Ruby、Python、Perl、Scala等等。Redis是用C语言编写的。此外,它是根据BSD授权的。
特点:自动故障转移;将其数据库完全保存在内存中;事务;Lua脚本;将数据复制到任意数量的从属服务器;钥匙的寿命有限;LRU驱逐钥匙;支持发布/订阅。
优点:支持多种数据类型;很容易安装;非常快(每秒执行约11万组,每秒执行约81000次);操作都是原子的;多用途工具(在许多用例中使用)。
缺点:不支持连接;存储过程所需的Lua知识;数据集必须很好地适应内存。
4、HBase
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。就像Bigtable利用了Google文件系统(File System)所提供的分布式数据存储一样,HBase在Hadoop之上提供了类似于Bigtable的能力。
HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。
5、neo4j
Neo4j被称为原生图数据库,因为它有效地实现了属性图模型,一直到存储层。这意味着数据完全按照白板的方式存储,数据库使用指针导航和遍历图。Neo4j有数据库的社区版和企业版。企业版包括Community Edition必须提供的所有功能,以及额外的企业需求,如备份、集群和故障转移功能。
特点:它支持唯一的约束;Neo4j支持完整的ACID(原子性、一致性、隔离性和持久性)规则;Java API: Cypher API和本机Java API;使用Apache Lucence索引;简单查询语言Neo4j CQL;包含用于执行CQL命令的UI: Neo4j Data Browser。
优点:容易检索其相邻节点或关系细节,无需连接或索引;易于学习Neo4j CQL查询语言命令;不需要复杂的连接来检索数据;非常容易地表示半结构化数据;大型企业实时应用程序的高可用性;简化的调优。
缺点:不支持分片。
17.关系型数据库和非关系型数据库的特性以及各自的优缺点
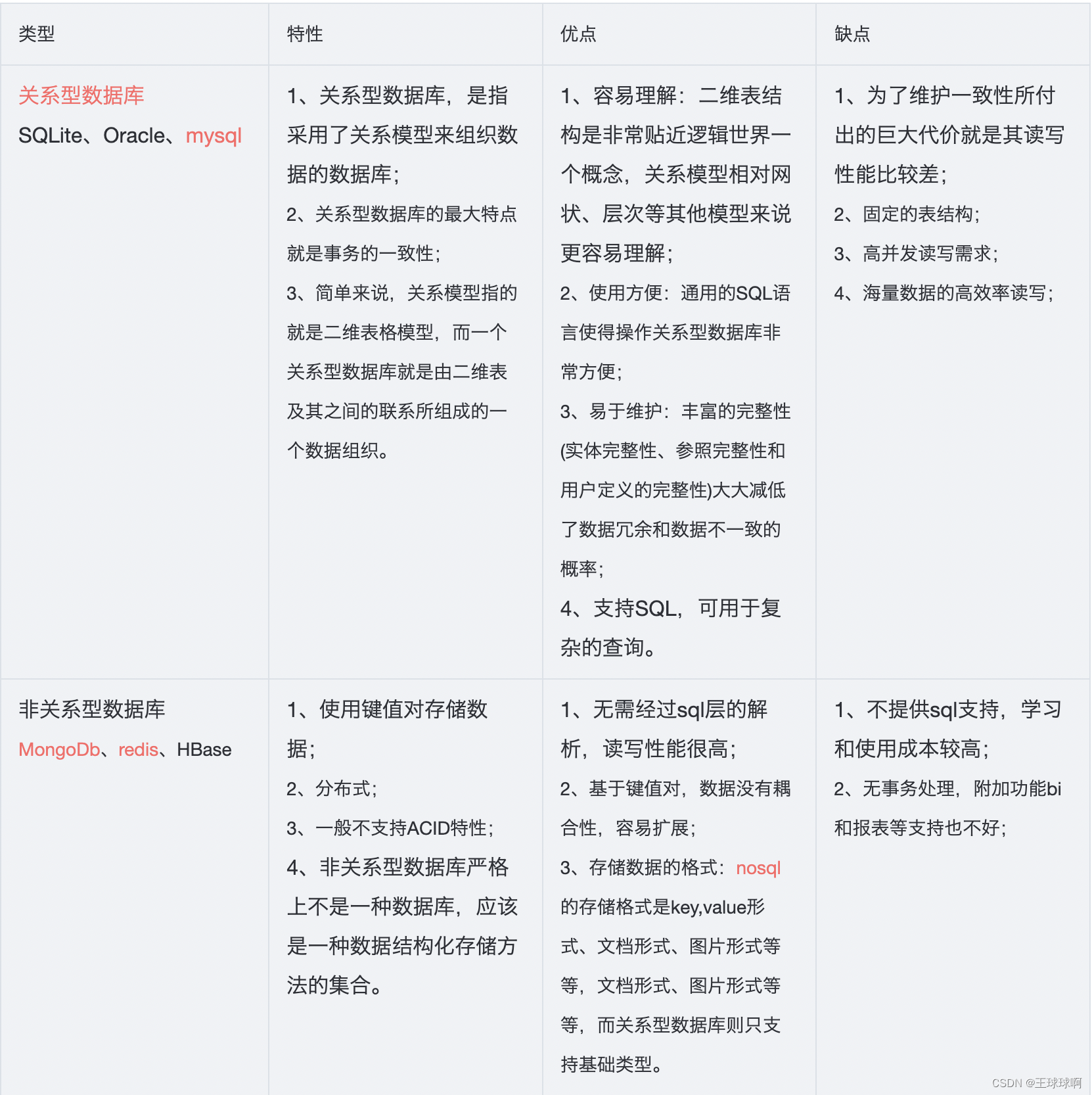
注1:数据库事务必须具备ACID特性,ACID是Atomic原子性,Consistency一致性,Isolation隔离性,Durability持久性。
注2:数据的持久存储,尤其是海量数据的持久存储,还是需要一种关系数据库。
性能测试相关面试题
1.简述负载测试与压力测试的区别
-
压力测试(Stress Testing)
压力测试的主要任务就是获取系统正确运行的极限,检查系统在瞬间峰值负荷下正确执行的能力。例如,对服务器做压力测试时就可以增加并发操作的用户数量;或者不停地向服务器发送请求;或一次性向服务器发送特别大的数据等。看看服务器保持正常运行所能达到的最大状态。人们通常使用测试工具来完成压力测试,如模拟上万个用户从终端同时登录,这是压力测试中常常使用的方法。 -
负载测试(Volume Testing)
用于检查系统在使用大量数据的时候正确工作的能力,即检验系统的能力最高能达到什么程度。例如,对于信息检索系统,让它使用频率达到最大;对于多个终端的分时系统,让它所有的终端都开动。在使整个系统的全部资源达到“满负荷”的情形下,测试系统的承受能力。
安全相关面试题
1.待补充
linux相关面试题
1.常用linux命令
- ifconfig 查看IP地址
- cat 用于显示指定文件的全部内容
- more 用分页的形式显示指定文件的内容
- mkdir 创建目录
- touch 创建新的文件
- grep 查找文件里符合条件的字符串
- find 查找指定的文件
- tail -f 用于自动刷新显示文件后N行数据内容
- kill -9 强制结束
- netstat -anp | grep 端口号 查看端口
- chmod -R 777 赋予777权限
常用操作命令
shutdown -h now 立刻关机
shutdown -h 5 5分钟后关
poweroff 立刻关机
shutdown -r now 立刻重启
shutdown -r 5 5分钟后重启
reboot 立刻重启
cd / 切换到根目录cd
/usr 切换到根目录下的usr目录
cd …/ 切换到上一级目录 或 cd … cd ~ 切换到home目录
cd - 切换到上次访问的目录
ls 查看当前目录下的所有目录和文件
ls -a查看当前目录下的所有目录和文件(包括隐藏的文件)
ls -l 列表查看当前目录下的所有目录和文件(列表查看,显示更多信息)
ls / 查看指定目录下的所有目录和文件
查找命令
grep 命令是一种强大的文本搜索工具
find 命令在目录结构中搜索文件,并对搜索结果执行指定的作。
locate 让使用者可以很快速的搜寻某个路径。
whereis 命令是定位可执行文件、源代码文件、帮助文件在文件系统中的位置。
which 命令的作用是在PATH变量指定的路径中,搜索某个系统命令的位置,并且返回第一个搜索结果。
命令格式
crontab [-u user] file
crontab [-u user] [ -e | -l | -r ]
参数说明:
-u user:用来设定某个用户的crontab服务
file:file是命令文件的名字,表示将file做为crontab的任务列表文件并载入crontab。
-e:编辑某个用户的crontab文件内容。如果不指定用户,则表示编辑当前用户的crontab文件。
-l:显示某个用户的crontab文件内容。如果不指定用户,则表示显示当前用户的crontab文件内容。
-r:删除定时任务配置,从/var/spool/cron目录中删除某个用的crontab
文件,如果不指定用户,则默认删除当前用户的crontab文件。
命令:pwd 查看当前目录路径
命令:ps -ef 查看所有正在运行的进程
命令:kill pid 或者 kill -9 pid(强制杀死进程) pid:进程号
ifconfig:查看网卡信息
命令:ifconfig 或 ifconfig | more
ping:查看与某台机器的连接情况
命令:ping ip
netstat -an:查看当前系统端口
命令:netstat -an
搜索指定端口
命令:netstat -an | grep 8080
目录操作【增,删,改,查】
【增】 mkdir
mkdir aaa 在当前目录下创建一个名为aaa的目录
mkdir /usr/aaa 在指定目录下创建一个名为aaa的目录
【删】rm
删除文件:
rm 文件 删除当前目录下的文件
rm -f 文件 删除当前目录的的文件(不询问)
删除目录:
rm -r aaa 递归删除当前目录下的aaa目录
rm -rf aaa 递归删除当前目录下的aaa目录(不询问)
全部删除:
rm -rf * 将当前目录下的所有目录和文件全部删除
rm -rf /* 【慎用!慎用!慎用!】将根目录下的所有文件全部删除
注意:rm不仅可以删除目录,也可以删除其他文件或压缩包,为了方便大家的记忆,无论删除任何目录或文件,都直接使用 rm -rf 目录/文件/压缩包
【改】mv 和 cp
重命名目录
命令:mv 当前目录 新目录
例如:mv aaa bbb 将目录aaa改为bbb
剪切目录
命令:mv 目录名称 目录的新位置(将/usr/tmp目录下的aaa目录剪切到/usr目录下面 mv/usr/tmp/aaa/usr)
拷贝目录
命令:cp -r 目录名称 目录拷贝的目标位置 -r代表递归
(将/usr/tmp目录下的aaa目录复制到 /usr目录下面 cp /usr/tmp/aaa /usr)
【查】find
命令:find 目录 参数 文件名称
示例:find /usr/tmp -name ‘a*’ 查找/usr/tmp目录下的所有以a开头的目录或文件
文件操作【增,删,改,查】
【增】touch
touch 文件名(示例:在当前目录创建一个名为aa.txt的文件 touch aa.txt)
【删】 rm
rm -rf 文件名
【改】 vi或vim
vi编辑器的3种模式
基本上vi可以分为三种状态,分别是命令模式(command mode)、插入模式(Insert mode)和底行模式(last line mode),各模式的功能区分如下:
1、command mode 命令行模式下的常用命令:
【1】控制光标移动: ↑,↓,j
【2】删除当前行: dd
【3】查找:/字符
【4】进入编辑模式: i o a
【5】进入底行模式: :
2、Insert mode编辑模式
编辑模式下常用命令:
【1】ESC 退出编辑模式到命令行模式;
3、last line mode底行模式下常用命令:
【1】退出编辑: :q
【2】强制退出: :q!
【3】保存并退出: :wq
【查】文件的查看命令:cat/more/less/tail
cat:看最后一屏 cat sudo.conf(使用cat查看/etc/sudo.conf文件,只能显示最后一屏内容)
more:百分比显示more sudo.conf(使用more查看/etc/sudo.conf文件,可以显示百分比,回车可以向下一行,空格可以向下一页,q可以退出查看)
less:翻页查看less sudo.conf(使用less查看/etc/sudo.conf文件,可以使用键盘上的PgUp和PgDn向上 和向下翻页,q结束查看)
tail:指定行数或者动态查看tail -10 sudo.conf(使用tail -10 查看/etc/sudo.conf文件的后10行,Ctrl+C结束)
打包和压缩
Windows的压缩文件的扩展名 .zip/.rar
linux中的打包文件:aa.tar
linux中的压缩文件:bb.gz
linux中打包并压缩的文件:.tar.gz
Linux中的打包文件一般是以.tar结尾的,压缩的命令一般是以.gz结尾的。
命令:tar -zcvf 打包压缩后的文件名 要打包的文件,其中:z:调用gzip压缩命令进行压缩
c:打包文件
v:显示运行过程
f:指定文件名
示例:打包并压缩/usr/tmp 下的所有文件 压缩后的压缩包指定名称为xxx.tar
tar -zcvf ab.tar aa.txt bb.txt
或:tar -zcvf ab.tar *
解压
命令:tar [-zxvf] 压缩文件
其中:x:代表解压
示例:将/usr/tmp 下的ab.tar解压到当前目录下
tar -zxvf ab.tar
示例:将/usr/tmp 下的ab.tar解压到根目录/usr下
tar -zxvf ab.tar -C /usr------C代表指定解压的位置
常用的mysql命令
【增】insert
insert into 表名 values(值1,值2,…);
insert into 表名(字段1,字段2…) values(值1,值2,…);(较常用)
insert into 表名(字段1,字段2…) values(值1,值2,…),(值1,值2,…),(值1,值2,…);
【删】delete
delete from 表名 where 条件
【改(更新)】update
update 表名 set字段1 = 值1, 字段2 = 值2 where 条件
重要*【查】select
select * from 表名 查询表中的所有数据
select 字段 from 表名 指定数据查询
select 字段 from 表名 where 条件 根据条件查询出来的数据
where 条件后面跟的条件
关系:>,<,>=,<=,!=
逻辑:or, and
区间:id between 4 and 6 ;闭区间,包含边界
【排序】
select 字段 from 表 order by 字段 排序关键词(desc | asc)
排序关键词 desc 降序 asc 升序(默认)
通过字段来排序 :select * from star orser by money desc, age asc;
多字段排序 :select 字段 from 表 order by 字段1 desc |asc,…字段n desc| asc;
【常用的统计函数】 sum,avg,count,max,min
多表联合查询
1.内连接
隐式内连接 select username,name from user,goods where user,gid=gods,gid;
显示内连接 select username,from user inner join goods on user.gid=goods.gid;
select * from user left join goods on user.gid=goods.gid;
2.外链接 左/右连接
select * from user where gid in(select gid from goods);
select * from user right jOin goods on user.gid=goods.gid;
3.数据联合查询
select * from user left join goods on user.gid=goods.gid union select * from user right join goods on user.gid=goods.gid;
4.两个表同时更新
update user u, goods g set u.gid=12,g.price=1 where u.id=2 and u.gid=g.gid;
monkey
命令:adb shell monkey +命令参数
所有的参数都需要放在monkey和设置的次数之间;参数的顺序可以调整,若带了-p ,-p必须放在monkey之后,参数必须在-p和次数之间
2.monkey基础命令
adb shell monkey -p 包名 -v -s seed值 压测次数
参数-p:
此命令用于指定要测试的包,若不指定则在整个系统中执行
a)指定一个包执行10次:adb shell monkey -p 包名 10
如下出现事件执行次数和所耗时间,则算是执行成功;
b)指定多个包执行10次:adb shell monkey -p 包名 –p 包名 10
参数 -v:
用于指定反馈日志的详细程度级别(共3个级别)
1.Level 0: adb shell monkey -p 包名 -v 10
默认级别,仅提供启动、测试完成和最终结果等少量信息
2.Level 1: adb shell monkey -p 包名 -v -v 10
提供较为详细的日志,包括每个发送到Activity的事件信息
3.Level 2: adb shell monkey -p 包名 -v -v -v 10
提供最详细的日志,包括了测试中选中/未选中的Activity信息
参数 -s:
用于指定伪随机数生成器的seed值
命令:adb shell monkey -p 包名 –s seed值 执行次数
作用:如果seed值相同,则两次Monkey测试所产生的事件序列也相同的。
示例:
测试1:adb shell monkey -p com.qq –s 15888 100
测试2:adb shell monkey -p com.qq –s 15888 100
说明:
两次测试的效果是相同的,因为模拟的用户操作序列(每次操作按照一定的先后顺序所组成的一系列操作,即一个序列)是一样的。(也就是说,重复执行上次的随机操作)
操作序列虽然是随机生成的,但是只要我们指定了相同的Seed值,就可以保证两次测试产生的随机操作序列是完全相同的,所以这个操作序列伪随机的;
运行:
>>不间断操作500次 adb shell monkey -p 包名 -v 500
>>每个操作间隔500ms,共执行100次 adb shell monkey -p 包名 -v-v --throttle 500 100
>>每个操作间隔100ms,共执行1000次 ,其中点击事件占比50%,轨迹50% adb shell monkey -p 包名 -v-v --pct-touch 50 --pct-trackball 50 --throttle 100 1000
>>日志重定向到桌面文件夹 adb shell monkey -p 包名 -v-v --pct-touch 50 --pct-trackball 50 --throttle 100 1000>C:\Users\xyp\Desktop\Android脚本\1.log
>>每个操作间隔500ms、崩溃、超时、许可错误继续执行 adb shell monkey -p 包名 --throttle 500 --ignore-crashes --ignore-timeouts --ignore-security-exceptions --ignore-native-crashes --monitor-native-crashes -v-v-v 1000000>C:\Users\xyp\Desktop\Android脚本\1.log
停止monkey测试
重新打开一个cmd窗口>>进入adb shell>>ps | grep monkey查找monkey进程>>kill 进程号结束monkey
日志分析
1. 查找出差步骤:
a)找到monkey里哪个地方出错
查看Monkey执行的是哪一个Activity,在switch后面找,两个swtich之间如果出现了崩溃或其他异常,可以在该Activity中查找问题的所在。
b)查看Monkey里面出错前的一些事件动作,手动执行该动作
>>Sleeping for XX milliseconds这是执行Monkey测试时,throttle设定的间隔时间,每出现一次,就代表一个事件
>>Sending XX 就是代表一个操作,如下图的两个操作 应该就是一个点击事件。
c)若以上步骤还不能找出,则可以使用之前一样的seed,再执行monkey命令一遍,便于复现
2.测试结果分析:
>>程序无响应,ANR问题:在日志中搜索“ANR”
>>崩溃问题:在日志中搜索“CRASH”
>>其他问题:在日志中搜索”Exception”
monkey说明
--throttle 时间间隔
--ignore-crashes 忽略崩溃
--ignore-timeouts 忽略超时
--ignore-security-exceptions 忽略许可错误
--ignore-native-crashes 忽略本地崩溃
--monitor-native-crashes 监控本地崩溃
--pct-touch 触摸、点击
--pct-motion 调整动作事件的百分比(动作事件由屏幕上某处的一个down事件、一系列的伪随机事件和一个up事件组成)
--pct-trackball 调整轨迹事件的百分比(轨迹事件由一个或几个随机的移动组成,有时还伴随有点击)
--pct-nav 调整“基本”导航事件的百分比(导航事件由来自方向输入设备的up/down/left/right组成)
--pct-majornav 调整“主要”导航事件的百分比(这些导航事件通常引发图形界面中的动作,如:5-way键盘的中间按键、回退按键、菜单按键)
--pct-syskeys 调整“系统”按键事件的百分比(这些按键通常被保留,由系统使用,如Home、Back、Start Call、End Call及音量控制键)
--pct-appswitch 调整启动Activity的百分比。在随机间隔里,Monkey将执行一个startActivity()调用,作为最大程度覆盖包中全部Activity的一种方法
--pct-flip 调整“键盘翻转”事件的百分比。
--pct-anyevent 调整其它类型事件的百分比。它包罗了所有其它类型的事件,如:按键、其它不常用的设备按钮、等等
注意:各事件类型的百分比总数不能超过100%
docker相关面试题
1.常用命令
1.1.帮助命令
- 显示docker的版本信息
docker version
- 显示docker的系统信息,包括镜像和容器的数量
docker info
- 帮助命令
docker --help
1.2.镜像命令
- 列出所有镜像
docker images -a
或者
docker images --all
- 只显示镜像id
docker images -q
或者
docker images --quiet
示例:
[root@hsStudy ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
hello-world latest d1165f221234 2 months ago 13.3kB
centos/mysql-57-centos7 latest f83a2938370c 19 months ago 452MB
解释:
REPOSITORY 镜像的仓库源
TAG 镜像的标签
IMAGE ID 镜像的创建时间
SIZE 镜像的大小
- 搜索镜像
docker search
- 通过收藏数过滤搜索过滤镜像
docker search --filter=STARS=3000
此处搜索出来的镜像都是STARS大于3000的
示例:
[root@hsStudy ~]# docker search mysql
NAME DESCRIPTION STARS OFFICIAL AUTOMATED
mysql MySQL is a widely used, open-source relation… 10881 [OK]
mariadb MariaDB Server is a high performing open sou… 4104 [OK]
- 下载镜像
docker pull 镜像名[:tag]
示例:
[root@hsStudy ~]# docker pull mysql
Using default tag: latest #如果不写tag,默认就是latest
latest: Pulling from library/mysql
69692152171a: Pull complete #分层下载,docker images核心 联合文件地址
1651b0be3df3: Pull complete
951da7386bc8: Pull complete
0f86c95aa242: Pull complete
37ba2d8bd4fe: Pull complete
6d278bb05e94: Pull complete
497efbd93a3e: Pull complete
f7fddf10c2c2: Pull complete
16415d159dfb: Pull complete
0e530ffc6b73: Pull complete
b0a4a1a77178: Pull complete
cd90f92aa9ef: Pull complete
Digest: sha256:d50098d7fcb25b1fcb24e2d3247cae3fc55815d64fec640dc395840f8fa80969
Status: Downloaded newer image for mysql:latest
docker.io/library/mysql:latest #真实地址
docker pull mysql等价于docker pull docker.io/library/mysql:latest
- 指定版本下载
docker pull mysql:5.7
示例:
[root@hsStudy ~]# docker pull mysql:5.7
5.7: Pulling from library/mysql
69692152171a: Already exists
1651b0be3df3: Already exists
951da7386bc8: Already exists
0f86c95aa242: Already exists
37ba2d8bd4fe: Already exists
6d278bb05e94: Already exists
497efbd93a3e: Already exists
a023ae82eef5: Pull complete
e76c35f20ee7: Pull complete
e887524d2ef9: Pull complete
ccb65627e1c3: Pull complete
Digest: sha256:a682e3c78fc5bd941e9db080b4796c75f69a28a8cad65677c23f7a9f18ba21fa
Status: Downloaded newer image for mysql:5.7
docker.io/library/mysql:5.7
- 删除指定的镜像
docker rmi -f 镜像id
- 删除多个指定的镜像
docker rmi -f 镜像id 镜像id 镜像id
- 删除全部镜像
docker rmi -f $(docker images -aq)
1.3.容器命令
说明:我们有了镜像才可以创建容器,我们下载一个CentOS镜像来测试学习
新建容器并启动
docker pull centos
docker run [可选参数] image
参数说明:
--name="Name":容器名字 tomcat01 tomcat02 用来区分容器
-d:以后台方式运行,ja nohub
-it:使用交互模式运行,进入容器查看内容
-p:指定容器的端口 -p 8080:8080
-p ip主机端:容器端口
-p 主机端:容器端口 主机端口映射到容器端口 (常用)
-p 容器端口
容器端口
-P:随机指定端口
测试,启动并进入容器
[root@hsStudy ~]# docker run -it centos /bin/bash
[root@9f8cb921299a /]#
[root@9f8cb921299a /]# ls #查看容器内的centos,基础命令很多都是不完善的
bin etc lib lost+found mnt proc run srv tmp var
dev home lib64 media opt root sbin sys usr
#从容器中退回主机
[root@9f8cb921299a /]# exit
exit
[root@hsStudy /]# ls
bin dev home lib64 media opt root sbin sys usr
boot etc lib lost+found mnt proc run srv tmp var
- 列出当前正在运行的容器
docker ps [可选参数]
参数说明:
-a #列出当前正在运行的容器+带出历史运行过的容器
-n=? #显示最近创建的容器
-q #只显示容器的编号
示例:
[root@hsStudy ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
[root@hsStudy ~]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9f8cb921299a centos "/bin/bash" 7 minutes ago Exited (0) 4 minutes ago eager_keldysh
da964ff44c74 d1165f221234 "/hello" 6 hours ago Exited (0) 6 hours ago affectionate_shtern
- 退出容器
exit #直接让容器停止并退出
Ctrl + P + Q #容器不停止退出
示例:
[root@hsStudy ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
[root@hsStudy ~]# docker run -it centos /bin/bash
[root@49bbf686f9a3 /]# [root@hsStudy ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
49bbf686f9a3 centos "/bin/bash" 14 seconds ago Up 12 seconds sharp_kilby
[root@hsStudy ~]#
- 删除容器
docker rm 容器id #删除指定的容器,不能删除正在运行的容器,如果要强制删除,rm -f
docker rm -f $(docker ps -aq) #删除所有的容器
docker ps -a -q|xargs docker rm #删除若有容器(使用linux管道命令)
- 启动和停止容器的操作
docker start 容器id #启动容器
- 重起容器
docker restart 容器id
- 停止当前正在运行的容器
docker stop 容器id
- 强制停止当前容器
docker kill 容器id
1.4.常用其他命令
- 后台启动容器
docker run -d 镜像名
示例:
[root@hsStudy ~]# docker run -d centos
docker ps , 发现centos停止了。
常见的坑,docker 容器使用后台运行,就必须要有一个前台进程,docker发现没有应用,就会自动停止
#nagix,容器启动后,发现自己没有提供服务,就会立即停止,没有程序了
- 查看日志命令
docker logs -f -t --tail 容器
参数说明:
-tf #显示日志
--tail number # 要显示的日志条数
docker logs -f -t --tail 10 4466628037e0
没有日志,自己编写一段shell脚本
[root@hsStudy /]# docker run -d centos /bin/sh -c "while true;do echo hansuo;sleep;done"
[root@hsStudy /]# docker ps
CONTAINER ID IMAGE
4466628037e0 centos
- 查看容器中的进程信息
docker top 容器id
示例:
[root@hsStudy /]# docker top 4466628037e0
UID PID PPID C STIME TTY
root 9218 9198 10 15:47 ?
- 查看镜像的元数据
docker inspect 容器id
- 进去当前正在运行的容器
我们通常容器都是是同后台方式进行的,修改一些配置
方式一:
docker exec -it 容器id bashShell
示例:
[root@hsStudy /]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
4466628037e0 centos "/bin/sh -c 'while t…" 16 minutes ago Up 16 minutes blissful_bhaskara
[root@hsStudy /]# docker exec -it 4466628037e0 /bin/bash
[root@4466628037e0 /]# ls
bin etc lib lost+found mnt proc run srv tmp var
dev home lib64 media opt root sbin sys usr
[root@4466628037e0 /]# ps -ef
UID PID PPID C STIME TTY TIME CMD
root 1 0 10 07:47 ? 00:02:01 /bin/sh -c while true;do echo hansuo;sleep;done
root 49735 0 0 08:05 pts/0 00:00:00 /bin/bash
root 51738 49735 5 08:05 pts/0 00:00:00 ps -ef
root 51745 1 0 08:05 ? 00:00:00 [sh]
方式二:
docker attach 容器id
示例:
[root@hsStudy /]# docker attach 4466628037e0
#decker exec #进入容器后开启一个新的终端,可以在里面操作(常用)
#docker attach #进入容器正在执行的终端,不会启动新的进程!
- 从容器内拷贝文件到主机上
docker cp 容器id:容器内路径 目的的主机
示例:
#查看当前主机目录下
[root@hsStudy home]# ls
depp hansuo.java
[root@hsStudy home]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
afb3e7611084 centos "/bin/bash" 3 minutes ago Up 3 minutes epic_galileo
#进入docker容器内部
[root@hsStudy home]# docker attach afb3e7611084
[root@afb3e7611084 /]# cd /home
[root@afb3e7611084 home]# ls
#在容器内新建一个文件
[root@afb3e7611084 home]# touch test.java
[root@afb3e7611084 home]# ls
test.java
[root@afb3e7611084 home]# exit
exit
[root@hsStudy home]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
[root@hsStudy home]# docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
afb3e7611084 centos "/bin/bash" 5 minutes ago Exited (0) 8 seconds ago epic_galileo
#将这个文件拷贝出来到我们的主机上
[root@hsStudy home]# docker cp afb3e7611084:/home/test.java /home
[root@hsStudy home]# ls
depp hansuo.java test.java
[root@hsStudy home]#
#拷贝是一个手动过程,未来我们使用 -v 卷的技术可以实现,自动同步 /home
Jenkins相关面试题
1.结合你的日常工作讲一下,如何使用jenkisn构建一个项目?
参考文章:https://www.jianshu.com/p/5f671aca2b5a
- 新建一个任务,命名要言简意赅能够体现出这个任务是做什么的,然后会进入构建任务配置界面。构建任务设置界面上可以看到上方的几个选项"General", “源码管理”, “构建触发器”,“构建环境”, “构建”, “构建后操作”
- 在“General”中的“描述”中对该任务进行进一步说明,并根据自己的需求配置“丢弃旧的构建”
- 根据自己项目情况在“源码管理”中配置好需要构建的项目、凭证以及构建分支
- 配置构建触发器(有多种方式,我这边常用的是使用crontab定时构建)
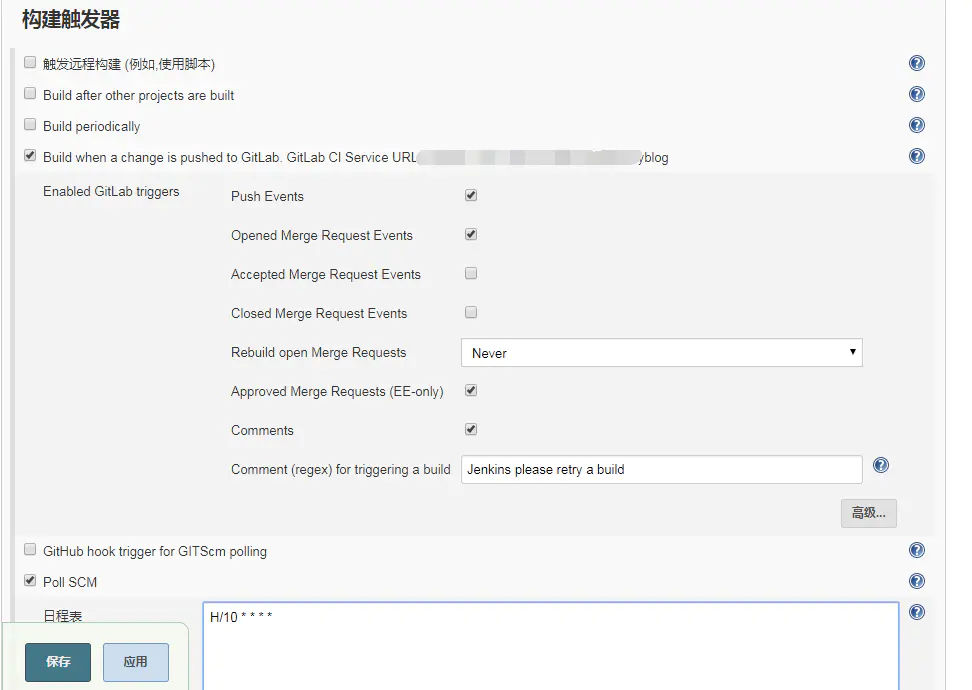
- 配置构建环境,我用的是“Build in docker”,因为比较方便,自己可以随时维护,需要什么可以随时自行安装下载
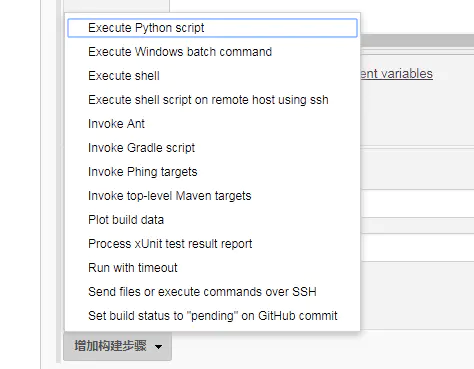
- 根据自己的需求在“构建”环节添加构建步骤,我常用的是“Execute shell”用来执行运行项目的命令
Eexcute shell: 执行shell命令,该工具是针对linux环境的,windows环境也有对应的工具"Execute Windows batch command"。 在构建之前,可能我们需要执行一些命令,比如压缩包的解压之类的。为了演示,我就简单的执行 “echo $RANDOM” 这样的linux shell下生产随机数命令。
- 根据自己的需要在“构建后操作”环节添加步骤,我这里主要是构建后的发送测试报告到邮箱
UI自动化测试相关面试题
1.什么是自动化测试?
自动测试就是把以人为驱动的测试转化为机器执行的一种过程,它是一种以程序测试程序的过程。
2.你会封装自动化测试框架吗?
既然问了这个问题,说明该公司期望求职者具备这个能力,不然可能达不到他们的要求。
拥有相关经验的按照自己的实战经验大概介绍一下即可。讲清楚封装的整个流程,以及每个环节的思考点。
⚠️自动化框架主要的核心框架就是分层+PO模式:分别为:基础封装层BasePage,PO页面对象层,TestCase测试用例层。然后再加上日志处理模块,ini配置文件读取模块,unittest+ddt数据驱动模块,jenkins持续集成模式组成。
3.你觉得自动化测试的价值在哪里?你们公司为什么要做自动化测试?
引用自动化测试之后,能代替大量繁琐的回归测试工作,把业务测试人员解放出来,既而让业务测试人员把精力集中在复杂的业务功能模块上,自动化测试一般是对稳定下来的功能进行自动化,保证不会因为产品的更新导致之前稳定下来的功能出现BUG。
4.自动化测试有误报过bug吗?产生误报怎么办?
有误报过,有时候自动化测试报告中显示发现了bug,实际去通过手工测试去确认又不存在该bug。
误报原因一般是:
1.元素定位不稳定,需要尽量提高脚本的稳定性;
2.开发更新了相关代码但是测试没有及时更新维护。
5.如果一个元素无法定位,你一般会考虑哪些方面的原因?
1.页面加载元素过慢,加等待时间;
2.页面有frame框架页,需要先跳转入frame框架再定位;
3.可能该元素是动态元素,定位方式要优化,可以使用部分元素定位或通过父节点或兄弟节点定位;
4.可能识别了元素,但是不能操作,比如元素不可用,不可写等,需要使用js先把前置的操作完成。
6.常见的元素定位方法有几种?分别是哪些?
常见的有8种,分别如下:
- id:通过id属性进行定位。
- name:通过name属性进行定位。
- classname:通过class属性进行定位。
- tag name:通过元素的标签名称来查找元素。这个方法搜索到的元素通常不止一个,所以一般建议结合使用findElements方法来使用。
- xpath:Xpath是XML Path的简称,由于HTML文档本身就是一个标准的XML页面。这个方法是非常强大的元素查找方式,使用这种方法几乎可以定位到页面上的任意元素。xpath也分几种不同类型的定位方法。一种是绝对路径定位。这种定位方式是利用html标签名的层级关系来定位元素的绝对路径,一般从标签开始依次往下进行查找。还有一种是相对路径定位,利用元素属性来进行xpath定位,搜索框还可以利用id和name属性去定位。
- css selector:cssSelector元素定位方式跟xpath比较类似,但执行速度较快,而且各种浏览器对它的支持很到位。
- link text:这个方法是通过超文本链接上的文字信息来定位元素,这种方式一般专门用于定位页面上的超文本链接。
- partial link text:这个方法是By Link Text的扩展。当不能确定超链接的文本信息或者只通过一些关键字进行匹配时,可以使用这个方法进行匹配。
⚠️注意⚠️ XPath的定位方式,webdriver会将整个页面的所有元素进行扫描以定位我们所需要的元素,所以这是一个非常费时的操作,如果你的脚本中大量使用xpath做元素定位的话,将导致你的脚本执行速度大大降低,所以请慎用。
find_element(By.ID,“kw”)
find_element(By.NAME,“wd”)
find_element(By.CLASS_NAME,“s_ipt”)
find_element(By.TAG_NAME,“input”)
find_element(By.LINK_TEXT,u" 新闻 “)
find_element(By.PARTIAL_LINK_TEXT,u” 新 “)
find_element(By.XPATH,”//*[@class=‘bg s_btn’]")
find_element(By.CSS_SELECTOR,“span.bg s_btn_wr>input#su”)
7.遇到frame框架页面怎么处理?
- 先用driver.switch_to.frame()跳转进去frame;
- 然后再操作页面元素;
- 操作完后使用driver.swith_to.default_content()跳转出来。
8.遇到alert弹出窗如何处理?
- 使用driver.switch_to.alert方法先跳转到alert弹出窗口;
- 然后再通过accept点击确定按钮,通过dismiss点击取消弹窗,通过text()获得弹出窗口的文本。
9.如何处理多窗口?
当你点击一个链接,这个链接会在一个新的tab打开,然后你接下来要在新tab打开的页面查找元素,
1.我们在点击链接前使用driver.current_window_handle获得当前窗口句柄;
2.再点击链接。点击后通过driver.window_handles获得所有窗口的句柄;
3.然后再循环找到新窗口的句柄,然后再通过driver.switch_to.window()方法跳转到新的窗口。
10.怎么验证元素是enable/disabled/checked状态?
定位元素后:分别通过isEnabled(),isSelected(),isDisplayed()三个方法进行判断。
11.如何处理下拉菜单?
在Selenium中有一个叫Select的类,这个类支持对下拉菜单进行操作。使用方法如下:
- 定位元素
- 把定位的元素转化成Select对象。
sel = Select(定位的元素对象) - 通过下标或者值或者文本选中下拉框。
sel.select_by_index(index);
sel.select_by_value(value);
sel.select_by_visible_text(text);
12.举例说明一下你遇到过哪些异常
常见的selenium异常有这些:
- NoSuchElementException:没有该元素异常
- TimeoutException : 超时异常
- ElementNotVisibleException :元素不可见异常
- NoSuchAttributeException:没有这样属性异常
- NoSuchFrameException :没有该frame异常
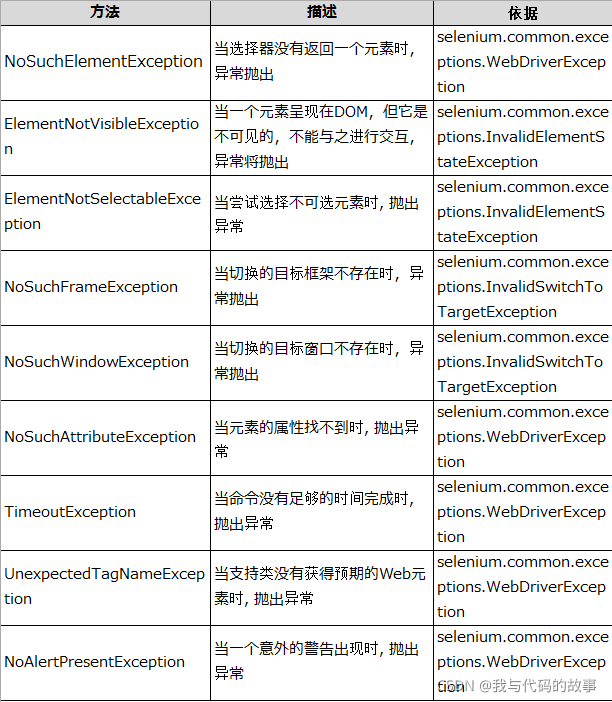
13.关闭浏览器中quit和close的区别
简单来说,两个都可以实现退出浏览器session功能。
close是关闭你当前聚焦的tab页面,而quit是关闭全部浏览器tab页面,并退出浏览器session。
知道这两个区别,我们就知道quit一般用在结束测试之前的操作,close用在执行用例过程中关闭某一个页面的操作。
14.在Selenium中如何实现截图,如何实现用例执行失败才截图
【1】在Selenium中提供了4种方法来截图,分别为:
-
driver.get_screenshot_as_base64():
用途:获取截屏的base64编码数据,在HTML界面输出截图时使用。 -
driver.get_screenshot_as_png():
用途:获取获取二进制数据流 -
driver.save_screenshot(filename/full_path):
用途:获取截屏png图片,参数是文件名称,截屏必须是.png图片, 如果只给文件名,截图会保存在项目的根目录下面。 -
driver.get_screenshot_as_file(filename/full_path)
用途:获取截屏png图片,参数是文件的绝对路径,截屏必须是.png图片。如果只给文件名,截屏会存在项目的根目录下。
【2】一般结合try/except捕获异常时使用,进行错误截图。但是在自动化测试项目中可以结合测试报告类中的addFailure()、addError()方法进行截图,但该操作要将unittest/case.py中webdriver.teardown()【盲打可能有误】的操作后置,避免还未截图浏览器就被关闭。
15.如何实现文件上传?
定位元素后,直接使用send_keys()方法设置就行,参数为需要上传的文件的路径。
16.自动化中有哪三类等待?他们有什么特点?
1.线程等待(强制等待):如time.sleep(2),线程强制休眠2秒钟,2秒过后,再执行后续的代码。建议少用。
2.imlicitlyWait(隐式等待):会在指定的时间范围内不断的查找元素,直到找到元素或超时,特点是必须等待整个页面加载完成。
3.WebDriverWait(显式等待):通常是我们自定义的一个函数代码,这段代码用来等待某个元素加载完成,再继续执行后续的代码
17.你写的测试脚本能在不同浏览器上运行吗?
当然可以,我写的用例可以在在IE,火狐和谷歌这三种浏览器上运行。
实现的思路是封装一个方法,分别传入一个浏览器的字符串,如果传入IE就使用IE,如果传入FireFox就使用FireFox,如果传入Chrome就使用Chrome浏览器,并且使用什么浏览器可以动态选择,也可以在配置文件中进行配置。需要注意的是每个浏览器使用的驱动不一样。
18.什么是PO模式,为什么要使用它?
PO是Page Object 模式的简称,它是一种设计思想,意思是,把一个页面当做一个对象,页面的元素和元素之间操作方法就是页面对象的属性和行为,PO模式一般使用三层架构,分别为:基础封装层BasePage,PO页面对象层,TestCase测试用例层。
接口自动化相关面试题
1.说说接口测试的流程,介绍一下request有哪些内容
(1)流程:
- 获取接口文档
- 依据文档设计接口参数
- 获取响应
- 解析响应
- 校验结果
- 判断测试是否通过
(2)request 内容:
- 封装了各种请求类型,get、post 等;
- 以关键字参数的方式,封装了各种请求参数,params、data、headers、token等;;
- 封装了响应内容,status code、json()、cookies、url等;
- session 会话对象,可以跨请求
Python相关面试题
1.模块和包
模块:python中包含并有组织的代码片段,xxx.py的xxx就是模块名 。
包:模块之上的有层次的目录结构,定义了由很多模块或很多子包组成的应用程序执行环境。包是一个包含init.py文件和若干模块文件的文件夹。
库:具有相关功能模块的集合,python有很多标准库、第三方库…
2.super 是干嘛用的?在 Python2 和 Python3 使用,有什么区别?为什么要使用 super?请举例说明。
- super 用于继承父类的方法、属性。
- super 是新式类中才有的,所以 Python2 中使用时,要在类名的参数中写Object。Python3 默认是新式类,不用写,直接可用。
- 使用super 可以提高代码的复用性、可维护性。修改代码时,只需修改一处。
代码举例:
class baseClass:
def test1(self, num):
print(num)
class sonClass(baseClass):
def test2(self):
super().test1(num)
son = sonClass()
son.test1(11)
3.L = [1, 2, 3, 11, 2, 5, 3, 2, 5, 3],用一行代码得出 [11, 1, 2, 3, 5]
list(set(L))
4.python让列表倒序排列的三种方法
参考文章:https://blog.csdn.net/weixin_44255592/article/details/90903392
- 第一种方式 list.reverse()
Python 的 list.reverse() 方法,会直接在原来的列表里面将元素进行逆序排列,不需要创建新的副本用于存储结果。

这种方式,有好处也有坏处。好处是节省内存使用,因为我们不需要重新申请空间来保存最后的结果。坏处是,我们修改了原来的数据,如果我们后面要使用原数据的话不方便。(虽说再倒序一次就行,但毕竟使用了多余的操作)。
- 第二种方式 使用切片 [::-1]
Python 的列表有一个特性叫做切片,你可以将它看作是方括号( [ ] )使用的扩展。
简单的说下切片的使用,mylist[start : end : step]
上面的操作表示取 mylist 的第 start 个(列表索引从 0 开始)到第 end 个元素(不包括第 end 个),其中每隔 step 个(默认 1 )取一个。
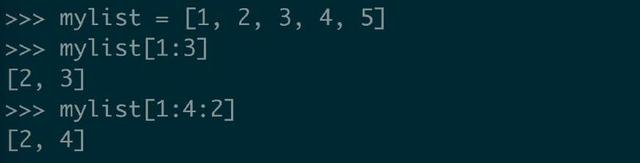
当然,start 、end 和 step 都是可选的,mylist[:] 会返回 mylist 的副本。

而当 start 、end 和 step 为负时,表示从反方向遍历
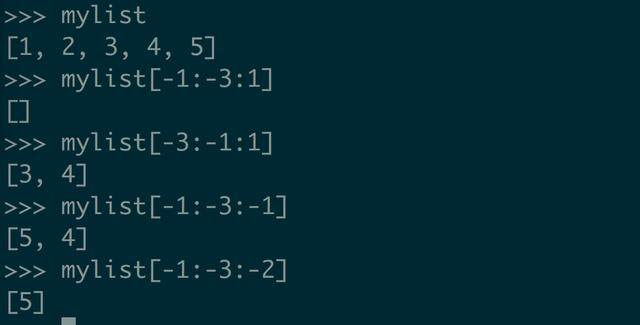
所以 mylist[::-1] 就能达到逆序的目的。

相比于第一种方式,这种方式会另外创建副本来保存列表的所有元素,所以需要更多的内存空间。并且,由于使用了切片的特性,导致在可读性上也不如之前的方式。但是这种方式没有改变原来的列表,在某些情况下算是一种优势。
- 第三种方式 使用 reversed() 方法
reversed 方法会将列表逆序的结果存储到迭代器里面,这种方式不会改变原来的列表,也不会创建原来列表的完整副本,只会多出迭代器对象所占的空间,相对来说也比较高效。
如果要访问所有的元素,循环就好,就像这样:
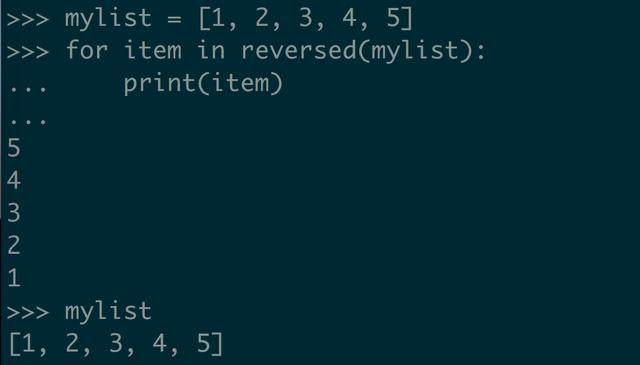
看了例子后,我们发现,这个的可读性也好,毕竟 reversed 字面意思已经体现出来了。
但是,如果我们想要一个列表呢,也简单
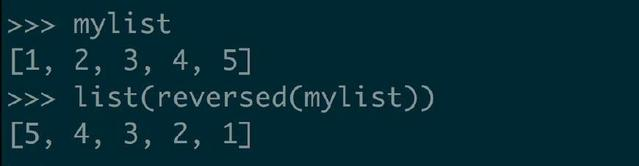
虽然这能达到目的,但是如果我们最终想要得到列表的话,这里使用 reversed 方法就没有意义了,因为这里我们又创建了 mylist 的副本。针对这种情况,用第一种或第二种方式更合适。
那么选择哪一种呢?
1、显然,第一种是首选。毕竟高效、易读。如果不要保留原列表的数据,使用这种方式显然更有优势,否则选择后两种。
2、如果最后需要得到列表类型的结果,那么选第二种方式比较合理。否则,第三种方式更高效。
5.L = [1, 2, 3, 5, 6],如何得出 ‘12356’?
此处列表中的元素不是字符串类型,所以不能 ‘’.join(L)
L = [1, 2, 3, 5, 6]
s=''
for i in L:
s = s+str(i)
print(s)
6.L = [1, 2, 3, 4, 5],L[10:]的结果是?
[],即空列表(不会超出索引)
7.为什么python的切片不会索引越界?
对于一个非空的序列对象,假设其长度为 length,则它有效的索引值是从 0 到(length - 1)。如果把负数索引也考虑进去,则单个索引值的有效区间是 [-length, length - 1] 闭区间。
但是,当 Python 切片中的索引超出这个范围时,程序并不会报错。
>>> li = [1, 2]
>>> li[1:5] # 右索引超出
[2]
>>> li[5:6] # 左右索引都超出
[]
其实,对于这种现象,官方文档中有所介绍:
The slice of s from i to j is defined as the sequence of items with index k such that i <= k < j. If i or j is greater than len(s), use len(s). If i is omitted or None, use 0. If j is omitted or None, use len(s). If i is greater than or equal to j, the slice is empty.
也就是说:
- 当左或右索引值大于序列的长度值时,就用长度值作为该索引值;
- 当左索引值缺省或者为 None 时,就用 0 作为左索引值;
- 当右索引值缺省或者为 None 时,就用序列长度值作为右索引值;
- 当左索引值大于等于右索引值时,切片结果为空对象。
8.1.什么是Python列表?
列表是由一系列按特定顺序排列的元组组成的。在Python中,用[]来表示列表,并用逗号来分隔其中的元素。
8.2.什么是Python元组?
你可以把它看作是只读的列表,因为元组是不可以改变的,但是要注意,元组中含有列表元素,则该列表元素是可变的。用于元组不可变,所以对于增删改查这四种标准操作来讲只有查能实现,元组查询操作非常简单。
8.2.1.元组的使用场景
- 函数的参数和返回值。一个函数可以接收多个参数也可以一次返回多个数据。
- 格式化字符串。
- 让列表不可以被修改,保护数据。
8.3.什么是Python字典?
字典就是一个数据容器,用大括号来括起来,说明里面的数据是无序的,不能重复的。
8.4.Python中列表和元组有什么区别?
参考文章:https://blog.csdn.net/qq_33362684/article/details/119416425
-
相同点:
列表和元组是Python中最常用的两种数据结构,字典是第三种。- 都是序列
- 都可以存储任何数据类型
- 可以通过索引访问
- list和tuple都支持负索引
- list和tuple都支持切片操作
- list和tuple都可以随意嵌套
-
写法上不同
列表使用[],例如list1=[“1”,“2”],;
元组使用() ,t=(“https://china-testing.github.io/”, “https://www.oscobo.com/”) -
是否可变
列表是可变的,而元组是不可变的,这标志着两者之间的关键差异。
我们可以修改列表的值,但是不修改元组的值。
列表是动态的,长度大小不固定,可以随意的增加、删除、修改元素
元组是静态的,长度在初始化的时候就已经确定不能更改,更无法增加、删除、修改元素
由于列表是可变的,我们不能将列表用作字典中的key。 但可以使用元组作为字典key
list1=[1,2,“ceshi”]
list1[0]=“change list value1”
print(list1)
t1=(“1”,“ceshi”)
t1[0]=“change tuple value”
‘’’ TypeError: ‘tuple’ object does not support item assignment’‘’
- 大小差异
Python将低开销的较大的块分配给元组,因为它们是不可变的。
对于列表则分配小内存块。
与列表相比,元组的内存更小。
当你拥有大量元素时,元组比列表快。
列表的长度是可变的。
l = [“https://china-testing.github.io/”, “https://www.oscobo.com/”]
t = (“https://china-testing.github.io/”, “https://www.oscobo.com/”)
print(l.sizeof())
56
print(t.sizeof())
40
8.5.Python中列表和字典有什么区别
(1)获取元素的方式不同。列表通过索引值获取,字典通过键获取
(2)数据结构和算法不同。字典是 hash 算法,搜索的速度特别快
(3)占用的内存不同。
8.6.Python中列表、元组、字典之间有什么区别呢?
1、元组是不可变的,而列表、字典是可以改变的
元组是不可变对象,对象一旦生成,它的值将不能更改;列表是可变对象,对象生成之后,可以对其元素进行更改、添加、删除、清空、排序等操作;
2、元组通常由不同数据组成,而列表通常是相同的数据队列(可以不同但通常相同)
元组表示的是结构,列表表示的是顺序,列表权限大于元组;
3、列表不能作为字典的key值,而元组可以,字典的键是唯一的。
9.写一段代码,ping 一个 ip 地址,并返回成功 失败的信息
使用 subProcess 模块的 Popen 方法(使用简单,具体用法,这里不展开)
10.生成器generator和迭代器iterator
- 生成器
生成器是一种特殊迭代器。生成一系列的值用于迭代,在for循环的过程中不断计算出下一个元素并在恰当的条件结束循环。
使用了yield的函数,返回迭代器。
- 迭代器
迭代器是访问集合元素的一种方式,他的对象从集合的第一个元素开始访问,直到所有元素被访问完结束,用iter()创建迭代器,调用next()函数获取对象(迭代只能往前不能后退)。
- 两者区别:
- 创建/生成。生成器创建一个函数,用关键字yield生成/返回对象;迭代器用内置函数iter()和next()。
- 生成器中yield语句的数目可以自己在使用时定义,迭代器不能超过对象数目。
- 生成器yield暂停循环时,生成器会保存本地变量的状态;迭代器不会使用局部变量,更节省内存。
- 生成器和函数的区别
生成器和函数的主要区别在于函数 return a value,生成器 yield a value同时标记或记忆 point of the yield 以便于在下次调用时从标记点恢复执行。 yield 使函数转换成生成器,而生成器反过来又返回迭代器。
11.参数传递机制
如果实际参数的数据类型是可变对象,比如列表、字典,则函数参数的传递方式将采用引用传递方式。
如果是不可变的,比如字符串、数值、元组,他们就是按值传递。
12.Python对象基本要素(3)
id,type和value。
id,身份:对象的唯一性身份标志,是该对象的内存地址(可用内建函数id()获得)。
type,类型:对象的类型决定了该对象可以保存什么类型的值,可进行什么样的操作(可用内建函数type()获得)。
value,值:对象代表的数据(value)。
13.__new__和__init__的区别?
__new__:创建对象时调用,会返回当前对象的一个实例 。
__init__:创建完对象后调用,对当前对象的一些实例初始化,无返回值 。
调用顺序:先调用__new__生成一个实例再调用__init__方法对实例进行初始化,比如添加属性。
14.浅拷贝和深拷贝的区别
1、浅拷贝
浅拷贝只复制某个对象的引用,而不复制对象本身,新旧对象还是共享同一块内存,原对象被释放,后来拷贝的对象也会被释放
2、深拷贝
深拷贝会创造一个一模一样的对象放在一个新开辟的内存空间,新对象和原对象不共享内存,修改新对象不会改变原对象。
15.1.如何理解python装饰器
参考链接:https://baijiahao.baidu.com/s?id=1718409527818049816&wfr=spider&for=pc
装饰器(decorator)是一种高级Python语法。可以对一个函数、方法或者类进行加工。在Python中,我们有多种方法对函数和类进行加工,相对于其它方式,装饰器语法简单,代码可读性高。因此,装饰器在Python项目中有广泛的应用。修饰器经常被用于有切面需求的场景,较为经典的有插入日志、性能测试、事务处理、Web权限校验、Cache等。
装饰器的优点是能够抽离出大量函数中与函数功能本身无关的雷同代码并继续重用。即,可以将函数“修饰”为完全不同的行为,可以有效的将业务逻辑正交分解。概括的讲,装饰器的作用就是为已经存在的对象添加额外的功能。例如记录日志,需要对某些函数进行记录。笨的办法,每个函数加入代码,如果代码变了,就悲催了。装饰器的办法,定义一个专门日志记录的装饰器,对需要的函数进行装饰。
15.2.为什么要用装饰器?
答:开放封闭原则
开放:指的是对拓展功能是开放的。
封闭:指的是对修改源代码是封闭的。
装饰器就是在不修改被装饰器对象源代码以及调用方式的前提下为被装饰对象添加新功能。
15.3.常见的装饰器有哪些?
- 内置装饰器
Python中有三种我们经常会用到的装饰器, property、 staticmethod、 classmethod,他们有个共同点,都是作用于类方法之上。
- property 装饰器
property 装饰器用于类中的函数,使得我们可以像访问属性一样来获取一个函数的返回值。
class XiaoMing:
first_name = '明'
last_name = '小'
@property
def full_name(self):
return self.last_name + self.first_namexiaoming = XiaoMing()
print(xiaoming.full_name)
例子中我们像获取属性一样获取 full_name 方法的返回值,这就是用 property 装饰器的意义,既能像属性一样获取值,又可以在获取值的时候做一些操作。
- staticmethod 装饰器
staticmethod 装饰器同样是用于类中的方法,这表示这个方法将会是一个静态方法,意味着该方法可以直接被调用无需实例化,但同样意味着它没有 self 参数,也无法访问实例化后的对象。
class XiaoMing:
@staticmethod
def say_hello():
print('同学你好')
XiaoMing.say_hello()
# 实例化调用也是同样的效果,但是有点多此一举
xiaoming = XiaoMing()
xiaoming.say_hello()
- classmethod 装饰器
classmethod 依旧是用于类中的方法,这表示这个方法将会是一个类方法,意味着该方法可以直接被调用无需实例化,但同样意味着它没有 self 参数,也无法访问实例化后的对象。相对于 staticmethod 的区别在于它会接收一个指向类本身的 cls 参数。
class XiaoMing:
name = '小明'
@classmethod
def say_hello(cls):
print('同学你好, 我是' +cls.name)
print(cls)
XiaoMing.say_hello()
- wraps 装饰器
等等等还有很多不一一赘述
什么是ORM?为什么要用ORM?不用ORM会带来什么影响?
- ORM 框架可以将类和数据表进行对应,只需要通过类和对象就可以对数据表进行操作。
- 通过类和对象操作对应的数据表,类的静态属性名和数据表的字段名一一对应,不需要写 SQL 语句。
- ORM 另外一个作用,是根据设计的类生成数据库中的表。
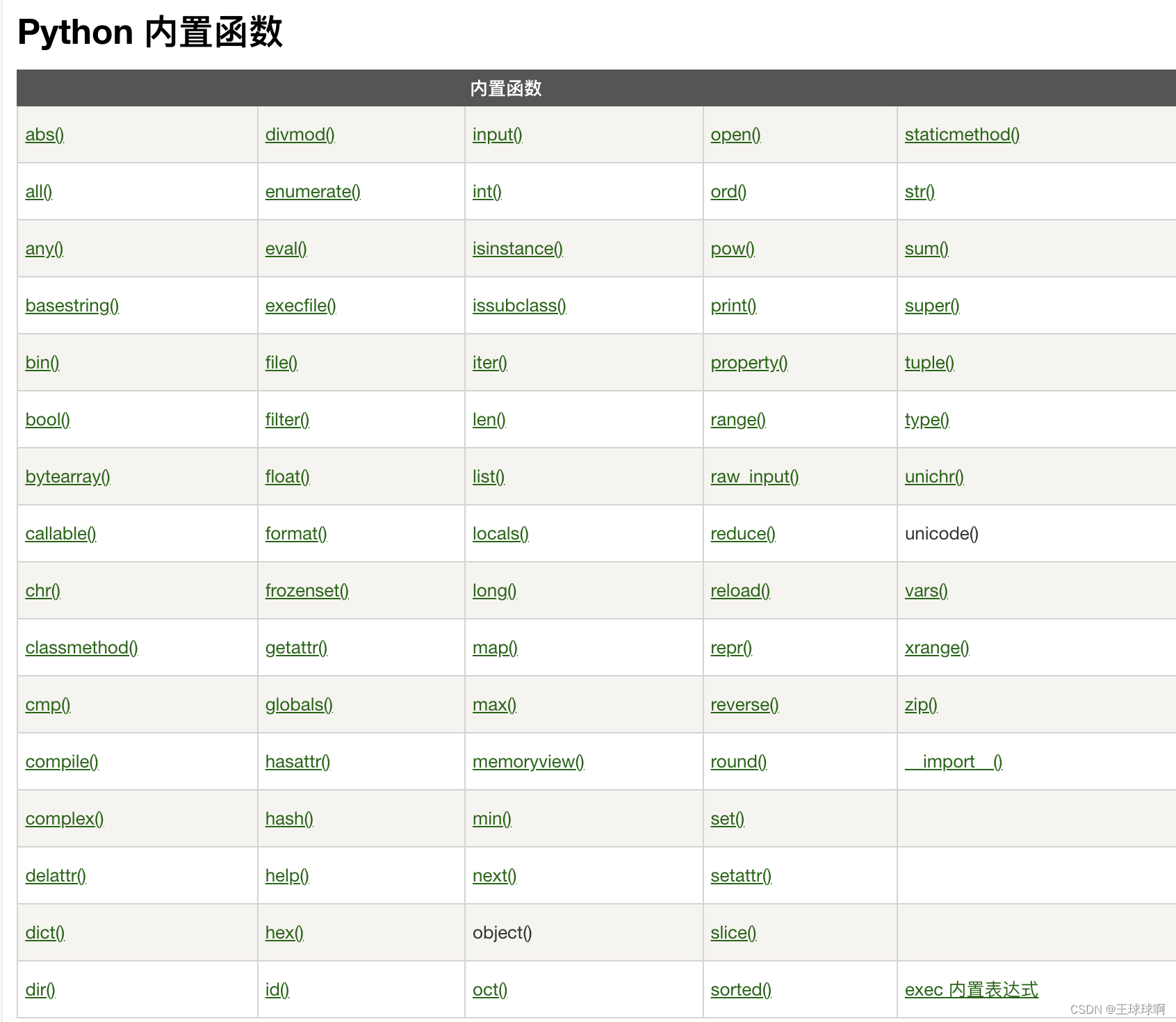
python内置函数
参考链接:https://www.runoob.com/python/python-built-in-functions.html
问会什么语言?现场写两段代码,如下:
A、有两个有序链表,将他们组成一个有序链表。
一开始面试官是让我写 A 代码的,此处我很虚,因为很久很久没用过链表。。。我问可以用数组来代替吗?她说这两个很像,数组取值是通过 index,链表是通过指针…,然后我很坦白跟她说,链表平时用的少,不知道怎么写…她说好吧,那我们换一题…然后出了B题
B、给一个字符串,字符串里有 (){}[]“”这几个符号,设计一个算法,判断这些符号是否成对匹配,即要检验这些括号是否都是成对出现的。
思路如下: 对原始字符创 str1 进行遍历,获取到这些符号,将它们构成一个新的字符串 str1(stringbuilder 类型),然后进行倒序操作(reverse方法),判断 str1 是不是回文字符即可。
接着让我根据这个算法写测试用例,注意还有要考虑没有这些符号但有其他字符的情况,以及字符串为空的情况。最好用等价类法,因为细分的话可以写的测试用例太多了,
class Solution:
def addTwoNumbers(self, l1: ListNode, l2: ListNode) -> ListNode:
def creat_data(lk): # 生成每个链表所代表的数字
sum = 0
it = 0
while lk:
x = lk.val
sum += x*10**it
it += 1
lk = lk.next
return sum
data = creat_data(l1) + creat_data(l2) # 两个链表相加后所得的数字
head = ListNode(0) # 生成头节点
tail = head # 生成尾节点,也当指针用
n = len(str(data)) # data是几位数
for i in range(n):
data_1 = data % 10 # 取出当前循环下data的个位数
tail.next = ListNode(data_1)
tail = tail.next # 更新尾节点
data //= 10 # 更新data,以便取出下一位数
return head.next
其他学习文献:
【1】https://www.csdn.net/tags/NtzaIgysNjcxMDMtYmxvZwO0O0OO0O0O.html














 325
325











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









