







高可用架构由两个核心部分组成,一个是心跳检测,判断服务器是否正常运行;一个是资源转移,用来将公共资源在正常服务器和故障服务器之间搬动。
整个运行模式就是心跳检测不断的在网络中检测各个指定的设备是否能够正常响应,如果一旦发生设备故障,就由资源转移功能进行应用的切换,以继续提供服务。
| corosync,心跳信息传输层,它是运行在每一个主机上的一个进程 。 Pacemaker是一个集群管理器。它利用推荐集群基础设施(OpenAIS 或heartbeat)提供的消息和成员能力,由辅助节点和系统进行故障检测和回收,实现性群集服务(亦称资源)的高可用性。用于资源转移。 |
server1,server2:集群节点
server3,server4:后端服务器
一、配置Haproxy
HAProxy 是一款提供高可用性、负载均衡以及基于TCP(第四层)和HTTP(第七层)应用的代理软件。
server1
[root@server1 haproxy]# yum install haproxy -y[root@server1 ~]# vim /etc/haproxy/haproxy.cfg global
log 127.0.0.1 local2 #日志配置,所有的日志都记录本地,通过local2输出
chroot /var/lib/haproxy #改变haproxy的工作目录
pidfile /var/run/haproxy.pid
maxconn 65535
user haproxy
group haproxy
daemon
stats socket /var/lib/haproxy/stats
defaults
mode http #默认使用协议,可以为{http|tcp|health} http:是七层协议 tcp:是四层 health:只返回OK
log global
option httplog
option dontlognull #不记录空日志
option http-server-close
option forwardfor except 127.0.0.0/8 #来自这些信息的都不forwardfor
option redispatch
retries 3 #3次连接失败则认为服务不可用
timeout http-request 10s
timeout queue 1m
timeout connect 10s
timeout client 1m
timeout server 1m
timeout http-keep-alive 10s
timeout check 10s
maxconn 8000 #最大连接数
stats uri /admin/stats ##健康检查
monitor-uri /monitoruri ##监控管理
frontend main *:5000
# acl url_static path_beg -i /static /images /javascript /stylesheets
# acl url_static path_end -i .jpg .gif .png .css .js
# use_backend static if url_static #调用后端服务器并检查ACL规则是否被匹配
bind 172.25.18.100:80
default_backend static #客户端访问时默认调用后端服务器地址池
#---------------------------------------------------------------------
# static backend for serving up images, stylesheets and such
#---------------------------------------------------------------------
backend static
balance roundrobin
server static1 172.25.18.4:80 check #check:启动对后端server的健康状态检测
server static2 172.25.18.3:80 check为节点添加VIP便于集群管理。
[root@server1 haproxy]# ip add add 172.25.18.100/24 dev eth0
设置系统支持haproxy最大连接数。
[root@server1 haproxy]# vim /etc/security/limits.conf
haproxy - nofile 65535
[root@server1 ~]# /etc/init.d/haproxy start
Starting haproxy: [ OK ]server1上Haproxy测试:
##后端apache服务开启
[root@server3 ~]# /etc/init.d/httpd start
[root@server4 ~]# /etc/init.d/httpd start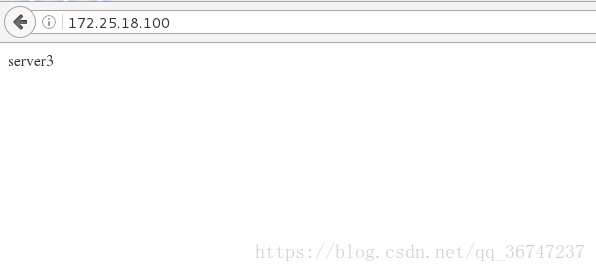
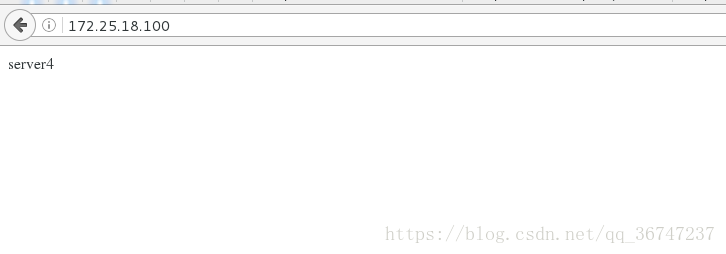
Haproxy自带健康检查(检查Haproxy服务是否正常):
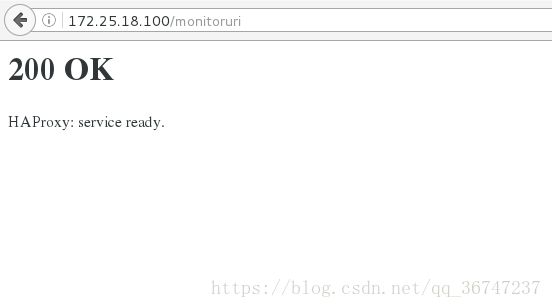
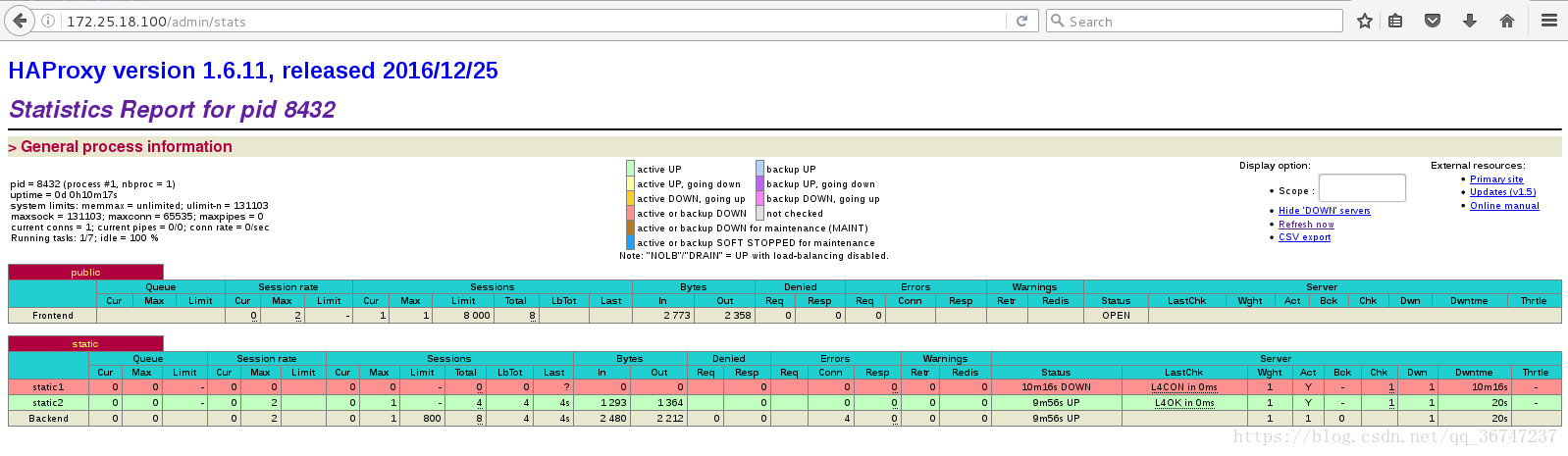
Haproxy监控页面:
颜色代表后端的状态(图中显示server3异常)
为了实现server1与server2的集群管理,将server2上与server1作相同的配置。当一个节点故障时,另一个节点会替代其进行工作。
[root@server2 ~]# yum install haproxy -y
[root@server1 haproxy]# scp /etc/haproxy/haproxy.cfg server2:/etc/haproxy/
[root@server2 ~]# ip addr add 172.25.18.100/24 dev eth0
[root@server2 ~]# /etc/init.d/haproxy start二、配置pacemaker
Pacemaker是一个集群资源管理器。它利用集群基础构件(OpenAIS 、heartbeat或corosync)提供的消息和成员管理能力来探测并从节点或资源级别的故障中恢复,以实现群集服务(亦称资源)的最大可用性。
[root@server1 ~]# yum install pacemaker corosync -y
[root@server1 ~]# cp /etc/corosync/corosync.conf.example /etc/corosync/corosync.conf
[root@server1 haproxy]# rpm -ivh crmsh-1.2.6-0.rc2.2.1.x86_64.rpm --nodeps
[root@server1 haproxy]# scp /etc/corosync/corosync.conf server2:/etc/corosync/
[root@server1 ~]# vim /etc/corosync/corosync.conf
compatibility: whitetank
totem {
version: 2
secauth: off
threads: 0
interface {
ringnumber: 0
bindnetaddr: 172.25.18.0
mcastaddr: 226.94.1.1
mcastport: 5405
ttl: 1
}
}
logging {
fileline: off
to_stderr: no
to_logfile: yes
to_syslog: yes
logfile: /var/log/cluster/corosync.log
debug: off
timestamp: on
logger_subsys {
subsys: AMF
debug: off
}
}
amf {
mode: disabled
}
service{
name:pacemaker
ver:0
}
aisexce {
user: root
group: root
}
quorum {
provider: corosync_votequorum
expected_votes: 2
two_node: 1
}server2:
[root@server2 ~]# yum install pacemaker corosync -y
[root@server2 ~]# rpm -ivh crmsh-1.2.6-0.rc2.2.1.x86_64.rpm --nodeps
warning: crmsh-1.2.6-0.rc2.2.1.x86_64.rpm: Header V3 DSA/SHA1 Signature, key ID 7b709911: NOKEY
Preparing... ########################################### [100%]
1:crmsh ########################################### [100%]
[root@server2 ~]# /etc/init.d/corosync start
[root@server1 haproxy]# /etc/init.d/pacemaker start
GFS2: no entries found in /etc/fstab
Starting Pacemaker Cluster Manager [ OK ]
[root@server1 haproxy]# crm status
Last updated: Fri Aug 3 11:10:53 2018
Last change: Fri Aug 3 11:10:06 2018 via crmd on server2
Stack: cman
Current DC: server2 - partition with quorum
Version: 1.1.10-14.el6-368c726
2 Nodes configured
0 Resources configured
Online: [ server1 server2 ][root@server2 ~]# /etc/init.d/pacemaker start
GFS2: no entries found in /etc/fstab
Starting Pacemaker Cluster Manager [ OK ]
[root@server2 ~]# crm status
Last updated: Fri Aug 3 11:09:58 2018
Last change: Fri Aug 3 11:09:45 2018 via crmd on server2
Current DC: NONE
2 Nodes configured
0 Resources configured
Node server1: UNCLEAN (offline)
Node server2: UNCLEAN (offline)测试:
##
[root@server1 haproxy]# crm node standby
[root@server1 haproxy]# crm status
Last updated: Fri Aug 3 11:11:52 2018
Last change: Fri Aug 3 11:11:47 2018 via crm_attribute on server2
Stack: cman
Current DC: server2 - partition with quorum
Version: 1.1.10-14.el6-368c726
2 Nodes configured
0 Resources configured
Node server1: standby
Online: [ server2 ][root@server1 haproxy]# crm node online
[root@server2 ~]# crm node standby
[root@server2 ~]# crm status
Last updated: Fri Aug 3 11:13:11 2018
Last change: Fri Aug 3 11:13:06 2018 via crm_attribute on server2
Stack: cman
Current DC: server2 - partition with quorum
Version: 1.1.10-14.el6-368c726
2 Nodes configured
0 Resources configured
Node server2: standby
Online: [ server1 ][root@server1 haproxy]# crm node standby
[root@server1 haproxy]# crm status
Last updated: Fri Aug 3 11:13:43 2018
Last change: Fri Aug 3 11:13:38 2018 via crm_attribute on server2
Stack: cman
Current DC: server2 - partition with quorum
Version: 1.1.10-14.el6-368c726
2 Nodes configured
0 Resources configured
Node server1: standby
Node server2: standby













 455
455











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









