







正则表达式
正则表达式:{Regualr (有规律的)Expression(表现)正则表达式}
简写为REGEXP–>RE
正则表达式就是能用某种模式去匹配一类字符串公式,它是由一串字符和元字符构成的字符串
元字符就是用以阐述字符表达式的内容,转换和描述各种操作信息的字符
正则表达式针对的是文本内容,而通配符针对的是文件名称
正则表达式分为:基本正则表达式:BRE / 扩展正则表达式:ERE
grep
grep:G lobal search R egular E xpression and P rint out the line
- 作用:文本搜索工具,根据用户指定的过滤条件对目标文本逐行进行匹配检查,并打印匹配到的行
- 模式:由正则表达式的元字符及文本字符所编写出的过滤条件
- 字符匹配
.:匹配单个字符;
[]:匹配范围内的任意单个字符; - 匹配次数
\?:匹配前面的字符0次或者一次,意味着可有可无;
*:匹配前面的字符0次或者任意次;
+:匹配前面字符1次或者任意次,意味着至少一次;
{n}:匹配其前面的字符n次;
{n,m}:匹配其前面的字符至少n次,至多m次;
{0,n}:匹配前面的字符至多n次;
{m,}:至少m次;
.和(星号):匹配任意长度的任意字符; - 位置限定
^:行首锚定,用于模式最左侧;
$ :行尾锚定,用于模式最右侧;
^PATTERN$ :用于PATTERN来匹配整行;
^$:空白行;
< 或 \b:词首锚定,用于单词模式的最左侧;
> 或 \b:词尾锚定,用于单词模式的最右侧;
<PATTERN>:匹配完整的单词; - 其他及特殊的POSIX字符
\w:匹配字母,数字和下划线等于[A-Z a-z 0-9]
\W:匹配非字母,非数字和非下划线[ ^A-Z a-z 0-9 ]
\n:匹配一个换行字符
\r:匹配一个回车符
\t:匹配一个制表符
\s:匹配任何空白字符
\S:匹配任何非空白字符
\f:匹配一个换页符
[[:alnum:]]:文字数字字符(除去符号之外,数字,字母,都可以包括中文)
[[:alpha:]]:文字字符(字母,包括中文)
[[:digit:]]:数字字符(阿拉伯数字)
[[:graph:]]:非空字符(排除空格和tab键)
[[:print:]]:非空字符(包括空格,空格认为非空,tab键不适应)
[[:lower:]]:小写字符
[[:upper:]]:大写字符
[[:cntrl:]]:控制字符
[[:punct:]]:标点,符号(包括常用符号)
[[:space:]]:所有空白字符(新行,空格,制表符)
[[:xdigit:]]:十六进制数(0-9,a-f,A-F)
练习
[root@localhost ~]# vim lianxi.txt
good good study day day up
10086
10086+1
I remember that day she got married
三个空格
三个tab建
Good afternoon everyone
you are a good man
Study hard for your future
How are you?
yuwenkedaibiao
I’m fine,thanks
go TO bed
are you ok?
It’s been a long day without you my friend
You jump ,I jump!
one day ,'your girl will go '. Just because you have noting.
“you cried to me,‘fairy tales are deceptive’”
\\
//
()()()()()
“how do you do”
根据以上文本练习使用grep查找文件内容:
- 搜索含有thanks的行
[root@localhost ~]# grep "thanks" lianxi.txt - 搜索以Good开头的行
[root@localhost ~]# grep "^Good" lianxi.txt - 搜索一个包含od的行,d字母可有可无,不限次数
[root@localhost ~]# grep "od*" lianxi.txt - 搜索一个词,该词以y或Y开头
[root@localhost ~]# grep "^[Yy].*" lianxi.txt - 搜索含有单引号的行
[root@localhost ~]# grep ".*'.*'.*" lianxi.txt - 搜索一些行,该行包括某个单词并满足以下条件
1)第一个字符可以是Y或者y
2)第二个字符可以是o或者没有
3)第三个字符可以是任意字符
4)第四个字符匹配前一个字符,0次或任意次
[root@localhost ~]# grep "^[Yy]o\?.*" lianxi.txt - 匹配以大写字母开头的行
[root@localhost ~]# grep ^[[:upper:]] lianxi.txt - 匹配包含数字的行
[root@localhost ~]# grep [[:digit:]] lianxi.txt - 搜索精确匹配到含有day的单词的行
[root@localhost ~]# grep "\<day\>" lianxi.txt - 搜索包含are you ok这一行
[root@localhost ~]# grep "are you ok" lianxi.txt - 搜索以字母g开头包含两个o以上的单词
[root@localhost ~]# grep "\b^go\{2,\}" lianxi.txt - 使用扩展正则表达式,搜索g和d之间至少有一个o的行
[root@localhost ~]# grep "go\+d" lianxi.txt - 搜索++++++++的行
[root@localhost ~]# fgrep "++++" lianxi.txt - 搜索\或者的行
[root@localhost ~]# grep"[\/]" lianxi.txt - 搜索带有单引号的行
[root@localhost ~]# grep ".*'.*'.*" lianxi.txt - 搜索带有双引号的行
[root@localhost ~]# grep ".*\".*\".*" lianxi.txt - 搜索双引号里带有单引号的行
[root@localhost ~]# grep "\".*'.*'.*\"" lianxi.txt - 搜索空白字符行and搜索非空白字符行,并分别统计有多少行
//空白
[root@localhost ~]# grep [[:space:]] lianxi.txt
//非空(有空格也认为是空)
[root@localhost ~]# grep -c [[:graph:]] lianxi.txt
//非空(有空格不算空,有tab键算)
[root@localhost ~]# grep -c [[:print:]] lianxi.txt - 搜索带有标点符号的行
[root@localhost ~]# grep [[:punct:]] lianxi.txt - 搜索以y开头中间肯定有字符末尾是o的行,并显示出上下各两行的内容
[root@localhost]# grep -c 2 "^y.*o$" lianxi.txt
sed
sed:流编辑器,awk报告文本生成器(这三兄弟里最难的)
sed基本用法:stream EDitor 对文本进行逐行处理的编辑器,还有全屏编辑器比如vim
-
sed:模式空间
默认不直接处理源文件,仅对模式空间中的数据进行处理,处理结束后,将模式空间打印到屏幕
它并不是处理文件的文本本身,它要将要处理的数据加载到内存中,然后在内存中进行处理,这个内存空间就叫做模式空间 -
sed常用参数
-e:多条件编辑
-r:支持扩展正则表达式
-n:只显示匹配出的行
-f:指定sed脚本
-i:直接修改源文件
=:显示文件行号 -
打印行
//打印文件中的第二行,默认会全部输出,加上-n选项就只会打印匹配的行
命令示例:

//取反
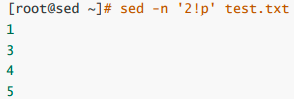
//打印1到3行

删除命令
使用d选项可以删除指定的行
命令示例:
- 将文件的第一行删除后输出到屏幕
[root@sed ~]# sed '1d' sed.txt - 删除sed.txt文件的第三到第五行
[root@sed ~]# sed '3,5d' sed.txt - 删除第三行到最后一行
[root@sed ~]# sed '3,$d' sed.txt - 删除最后一行
[root@sed ~]# sed '$d' sed.txt - 跨奇数删除
[root@sed ~]# sed '1~2d' sed.txt - 跨偶数删除
[root@sed ~]# sed '2~2d' sed.txt - 删除所有包含‘Empty’的行
[root@sed ~]# sed '/Empty/d' sed.txt - 删除所包含’Empty’ 到最后的行
[root@sed ~]# sed '/Empty/,$d' sed.txt - 删除所包含‘Empty’到下两行的行
[root@sed ~]# sed '/Empty/,+2d' sed.txt - 删除空行
[root@sed ~]# sed '/^$/d' sed.txt - 这个和含有空是有区别的
[root@sed ~]# sed '/[[:space:]]/d' sed.txt - 删除从‘You jump!’到‘I jump’的行,关键在于查找关键字
[root@sed ~]# sed '/^Y/,/^I/d' sed.txt - 删除指定行到下2行之间的内容,比如删除第三行到下两行的内容
[root@sed ~]# sed '3,+2d' sed.txt
查找替换
命令示例:
- 使用s选项可将查找到的匹配文本替换为新文本,默认情况值替换第一次匹配到的内容
[root@sed ~]# sed 's/line/LINE/' sed.txt - 如果想只替换第二个匹配到的line为LINE
[root@sed ~]# sed 's/line/LINE/2' sed.txt - 使用g选项,可以完成所有匹配值的替换
[root@sed ~]# sed 's/line/LINE/g' sed.txt - 将以this开头的this替换为that
[root@sed ~]# sed 's/^this/that/' sed.txt - 将符合"," 换成"-"
[root@sed ~]# sed -n 's/,/-/gp' sed.txt - 思考如果删除每一行的第一个字符应该怎么做?
[root@sed ~]# sed 's/^.//g' sed.txt - 在匹配到Empty的行,行首的单词前添加you can see
[root@sed ~]# sed '/Empty/s/^/you can see/' sed.txt - 在匹配到Empty的行,将行首第一个字母替换为*
[root@sed ~]# sed '/Empty/s/^./*/' sed.txt
字符转换
使用y命令可以进行字符转换其作用为将一系列字符逐个地变换为另外一系列字符,基本用法如下 注意转换字符和被转换字符长度要相等,否则sed无法执行
- 命令示例:
[root@sed ~]# sed 'y/OLD/NEW/' file
插入文本
使用或者a命令插入文本,其中i代表匹配杭之前插入,而a代表在匹配行之后插入
命令示例:
- 使用i选项在第二行前插入文本
[root@sed ~]# sed '2 i Insert' sed.txt - 使用a选项在第二行后插入文本
[root@sed ~]# sed '2 a append' sed.txt - 在匹配行的上一行插入文本
[root@sed ~]# sed '/Second/i\Insert' sed.txt - 同时新增多行的话每行之间要用\n来进行新添加
[root@sed ~]# sed '2 a\append1\nappend2\nappend3' sed.txt
取代行
c选项,c选项的后面可以接字符串,这些字符串可以取代n1,n2之间的行
- 命令示例:
[root@sed ~]# sed '2,4c this is 2-4 line' sed.txt
读入文本
使用r命令可以从其他文件中读取文本,并插入匹配行之后
- 命令示例:
[root@sed ~]# sed '/^$/r /etc/passwd' sed.txt
打印
使用p选项可以进行打印,一般来说使用sed命令时都加-n选项,表示不打印无关的行
不加-n选项的话会输出文件所有行,而且匹配到的行会重复显示,感觉很乱
命令示例:
- 打印含有the的行
[root@sed ~]# sed -n '/the/p' sed.txt - 打印前5行
[root@sed ~]# sed '5q' sed.txt - 打印出匹配first的行到第4行
[root@sed ~]# sed -n '/First/,4p' sed.txt - 打印出不包含line的行
[root@sed ~]# sed -n '/line/!p' sed.txt
sed脚本
使用sed脚本可以加快工作效率,调用sed命令并使用-f参数指定文件
如下脚本,作用是将全文的this改成THAT,并删除所有空行

//执行脚本

思考如何将上述脚本改写为一条sed语句
- 第一种方法
[root@base ~]# sed -e 's/this/THAT/g' -e '/^$/'d' sed01.txt - 第二种方法
[root@base ~]# sed 's/this/THAT/g; /^$/g' sed.txt
sed总结
sed默认不对源文件执行操作,如果想生效于源文件则要加上-i,而且默认打印文件的所有行,用p加-n可以只打印匹配到的行
- 取代行:选择几行到几行之后用c选项就可以一句话替代
- 查找替换:s///,s@@@,s###,s&&&,等等符号,都可以使用
- 字符转换:y/// (注意一点:要替换的新旧字符长度必须向同,否则会命令出错)
- 插入文本:i insert:匹配行前插入 | aappend:匹配行后插入(添加多行要使用\n换行符)
- 删除:d,定点删除,从哪到哪删除,删除开头,删除结尾,删除奇数行,删除偶数行,删除包括单词的行等
awk
相较于sed常常对整行进行处理,awk则比较倾向于将一行分成好几个字段来处理
因此,awk相当适合处理小型数据
awk命令格式:awk options(选项) program(命令) file(文件)
awk可以后面接两个单引号并加上大括号 {} 来设置想要对数据进行的处理动作,awk 可以处理后续接的文件,也可以读取来自前个指令的 standard output 。但如前面说的,awk 主要是处理每一行的字段内的数据,而默认的“字段的分隔符号为 空格 或 tab键
- 举例:

- 若我想取出账号与登录者的ip,且账号与ip之间用tab键隔开,则会变成这样:
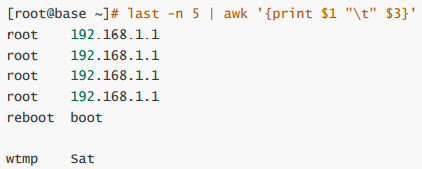
整个 awk 的处理流程
1)读入第一行,并将第一行的数据填入 $0, $1, $2… 等变量当中
2)依据条件类型的限制,判断是否需要进行后面的动作
3)做完所有的动作与条件类型
4)若还有后续的行的数据,则重复上面 1~3 的步骤,直到所有的数据都读完为止
awk内置变量

我们继续以上面 last -n 5 的例子来做说明,如果我想要:
列出每一行的帐号(就是 $1)
列出目前处理的行数(就是 awk 内的 NR 变量)
并且说明,该行有多少字段(就是 awk 内的 NF 变量)
awk 后续的所有动作是以单引号括住的,由于单引号与双引号都必须是成对的, 所以awk 的格式内容要以print 打印
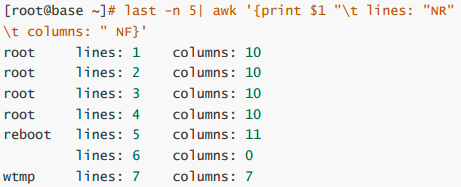
awk逻辑运算字符

举例来说,在 /etc/passwd 当中是以冒号 “:” 来作为字段的分隔,该文件中第一字段为帐号,第三字段则是 UID。如果我要查阅第三栏小于 10 以下的数据,并且仅列出帐号与第三栏,那么可以这样做

















 283
283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











