







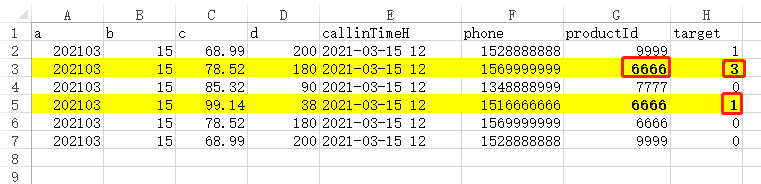
如上表csv数据,将productId=6666并且target=1和3的数据提取出来另存文件。
代码如下:
# -*- coding:utf-8 -*-
# 功能:将target=1和3并且productId=6666的数据取出来
import pandas as pd
import datetime
product_6666 = [6666]
def result(data):
data_6666_1 = data[(data['target'] == 1) & (data['productId'].isin(product_6666))]
data_6666_3 = data[(data['target'] == 3) & (data['productId'].isin(product_6666))]
# 2021-03-15 12
day = datetime.datetime.strptime(data['callinTimeH'][0], '%Y-%m-%d %H').strftime('%m%d') #0315
data_6666_1.to_csv('6666/' + 'data' + day + '_6666.csv', sep=',', index=False) # 写入csv,文件名为data0315_6666.csv
data_6666_3.to_csv('6666/' + 'data' + day + '_6666.csv', sep=',', mode='a', index=False, header=None) # mode='a'追加写入,header=None不写入表头
print('Finish!')
dataFile = pd.read_csv('data.csv', sep=',') # 读取数据
result(dataFile) # 调用函数
结果如下:
















 2727
2727











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









