









OCR:即Optical Character Recognition,光学字符识别,是指检查纸或者图片上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程;
Tesseract-OCR:一款由HP实验室(惠普布里斯托实验室)开发,由Google维护的开源OCR引擎,可以经过不断的训练,增强图像转换文本的能力,Tesseract-OCR 也经常被用于Python爬虫的验证码识别
1、下载安装Tesseract-OCR
官方GitHub地址:https://github.com/tesseract-ocr/
下载地址一:https://github.com/UB-Mannheim/tesseract/wiki (仅Windows操作系统,最新版本)
下载地址二:https://digi.bib.uni-mannheim.de/tesseract/ (仅Windows操作系统,历史版本)
下载地址三:https://github.com/tesseract-ocr/tesseract/wiki (其他操作系统)
以下以 V5.0.0 版本为例进行安装,双击 tesseract-ocr-w64-setup-v5.0.0-alpha.20190708.exe 安装程序,基本上一直next就OK了,注意要勾选 Additional language data(download) 安装OCR识别支持的语言包

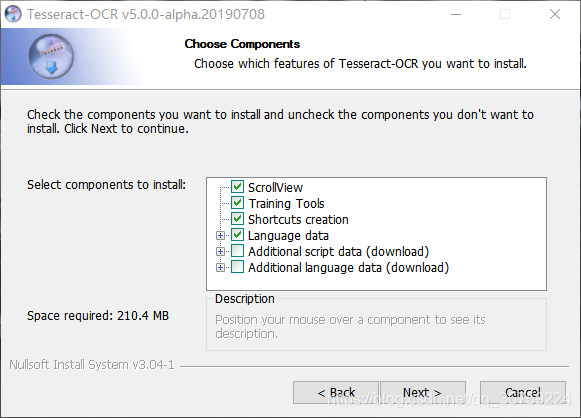
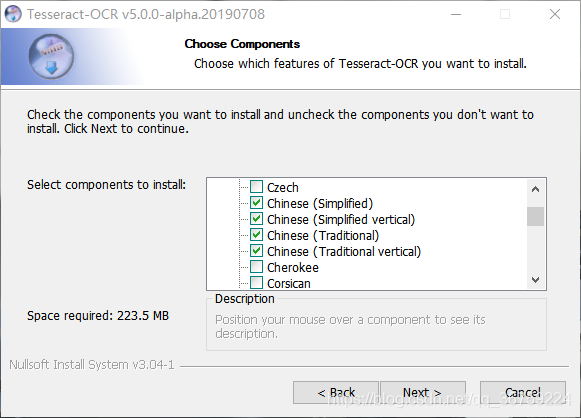
在这里勾选 Additional language data(download) ,安装OCR识别支持的语言包,在安装语言包时会比较慢,所以建议不要全选,根据需要选择即可,若后期需要增加语言包,可在官网下载后放到Tesseract-OCR\tessdata\tessconfigs目录下即可,不同版本的对应的语言包也不同,下载地址:https://github.com/tesseract-ocr/tesseract/wiki/Data-Files#data-files-for-version-302
2、配置环境变量
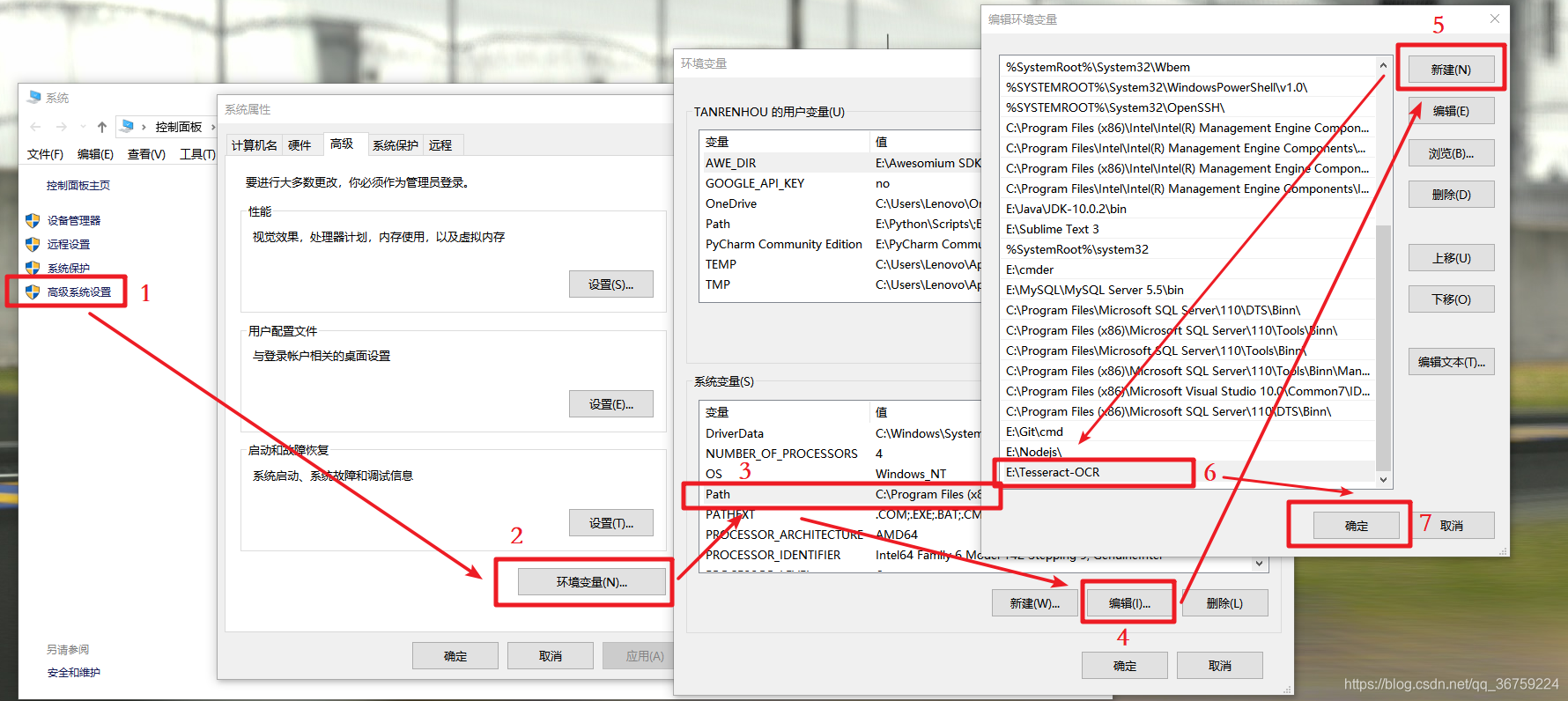
依次右键【此电脑】-【属性】-【高级系统设置】-【环境变量】,在【系统变量】里找到【Path】变量,选择【编辑】-【新建】,将你的Tesseract-OCR安装路径填写进去,比如我的是:E:\Tesseract-OCR,点击确定保存即可
3、测试是否成功安装
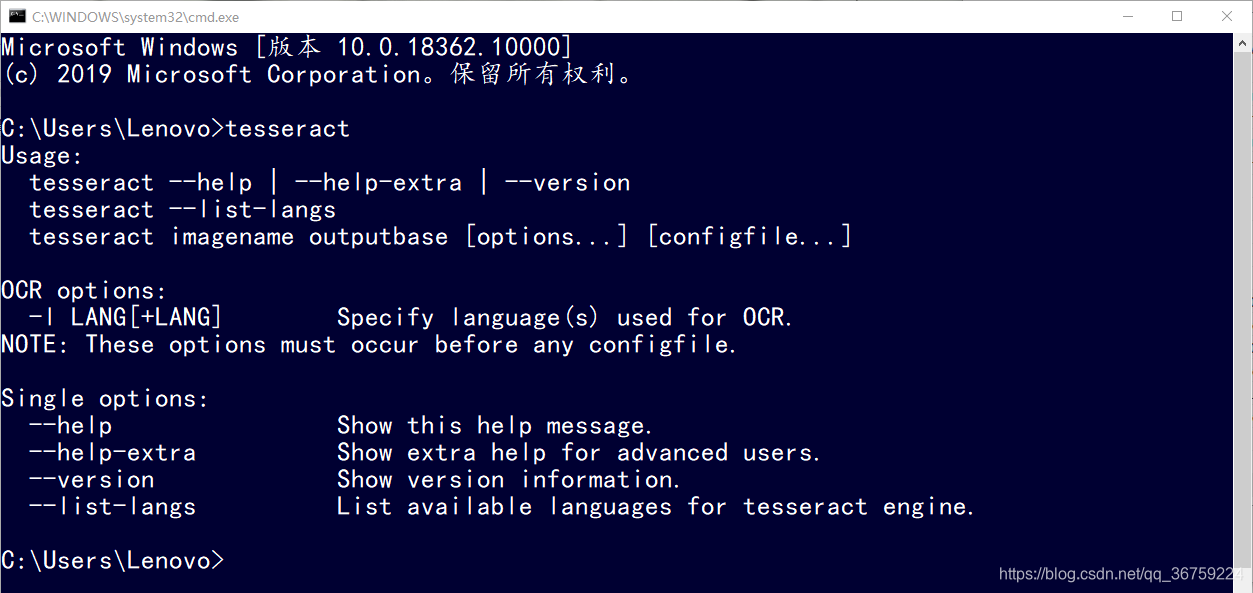
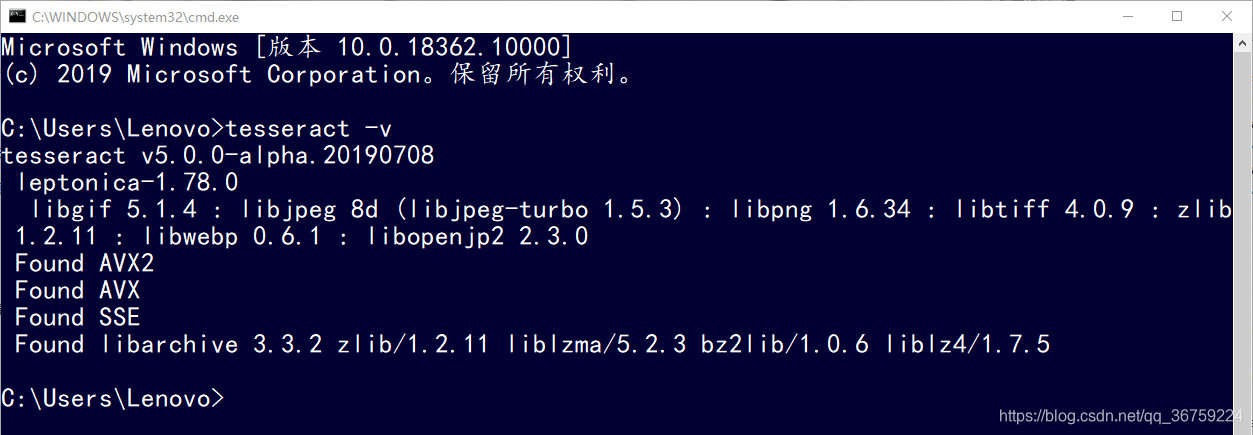
打开cmd,输入 tesseract 会显示一些 Tesseract-OCR 相关用法提示,输入 tesseract -v 可以查看到 Tesseract-OCR 的版本信息,说明此时安装成功
4、基本用法
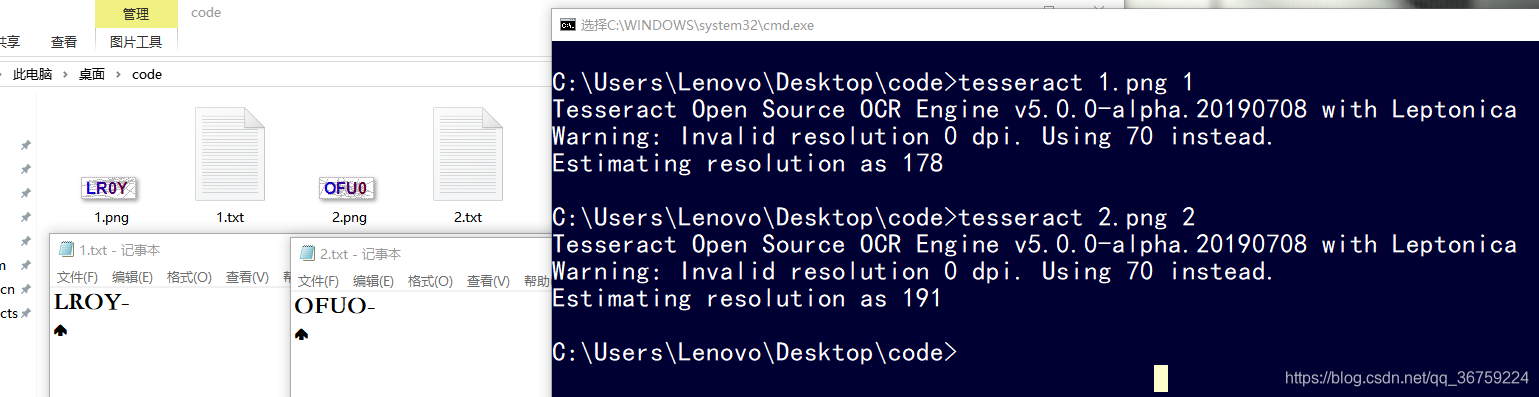
完整命令:tesseract 图片路径和图片名 结果路径和结果名 -l 语言
举例:tesseract F:\code\test.png F:\code\result -l eng
注意:
1、需要识别的图片要加后缀
2、结果文件名不需要加后缀,会自动加后缀,生成的是txt文件
3、-l 是英文字母l,不是数字1,language 语言的意思,不加默认英文
4、eng 表示英文,chi_sim 表示简体中文
5、将cmd切换到要识别图片的文件夹后,就不用加图片路径
在 Python 中使用:(需要安装 pytesseract 库)
import pytesseract
from PIL import Image
# 打开图片
img = Image.open('图片路径和图片名')
# 识别图片
print(pytesseract.image_to_string(img))















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











