







大家好,我是36度道,人生苦短,我用python !
今日目标:批量下载wallhere网站上的壁纸
目标网址:https://wallhere.com/zh/wallpapers
首页图:

按 F12 查看网页源代码,搜索img标签,可以看到现在有120张图片

如果想要更多的图片,需要往下拉,网页会自动往下加载新的图片

为了截这张图,拉了老长了…现在加载到了240张图片

也就是说 只有执行了“下拉”这个操作,才会加载出新的图片。这时,就不能单纯地从网页源代码中采集了,因为它是通过ajax动态加载的数据。
所以要先找到这些加载的新图片是通过什么请求而加载到网页上的
打开“开发者工具”,边往下拉,边看 network 的 Fetch/XHR 里发送了什么请求。
结果发现,新的图片的源代码保存在https://wallhere.com/zh/wallpapers?page=2&format=json这个请求下,该请求返回的是一个json数据,可以通过json()方法获取。其中源代码保存在data 这个key下

找到了图片的存储路径就好办了
现在看下这个请求的请求方式和参数信息
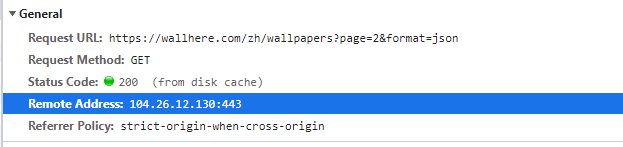
发现是get请求,并且可传入两个参数,分别是page和format
page表示页数,每下拉加载新数据时,page就会加1。所以我们可以通过翻页来实现“下拉”的动作
format在这应该表示返回的格式是json吧, 照着写上去就完事,不写可能也行,自行尝试
ok,准备工作已完成,接下来直接上代码
import requests
import time
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36'}
# 用来计数并作为图片名称
count = 0
# 获取前5页的图片
for page in range(1, 6):
url = "https://wallhere.com/zh/wallpapers?page=%s&format=json" % page
# 使用json()将字符串转化为json格式,并获取源代码
json_data = requests.get(url, headers=headers).json()['data']
# 创建一个BeautifulSoup对象,用来解析源代码
document = BeautifulSoup(json_data, 'html.parser')
# 获取源代码中所有的img标签
img = document.select('img')
for i in img:
# 获取图片的链接
img_url = i['src']
# 下载图片,图片需要用content属性获取二进制数据
content = requests.get(img_url, headers=headers).content
# 将图片保存到本地
with open(r'D:\桌面整理\8-壁纸\%s.png' % count, 'wb') as f:
f.write(content)
count += 1
# 记住访问速度不要过快,对对方服务器造成压力
time.sleep(1)
time.sleep(1.5)
效果图如下:

现在 我又有了很多新的壁纸可以用了~O Ye
客官,来了就点个赞呗?















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









