






本文旨在介绍简单的脉脉爬虫,用作学习交流,侵删~
1. 基本知识
1.1Python基本语法
链接自寻 ?Python3 中文手册
1.2爬虫基本原理
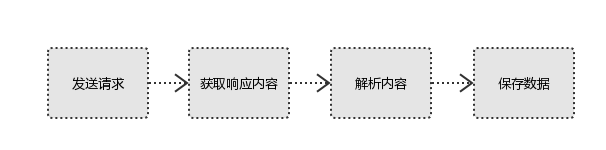
1.3爬虫基本模块
1.3.1Requests模块
pip安装方法:
pip install requests导入requests模块:
import requestsRequests主要用post或get的方法请求数据,根据需要添加一些headers和cookies
import requests
header = {
"user-agent": 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US;rv:1.9.1.5)Gecko/20091102 Firefox/3.5.5 (.NET CLR 3.5.30729)'
}
url = 'www.baidu.com'
r = requests.get(url, headers=header)链接走你?Requests中文文档
1.3.2BeautifulSoup模块
pip安装方法:
pip install beautifulsoup4导入BeautifulSoup模块:
from bs4 import BeautifulSoup安装第三方解析器,搭配BeuatifulSoup使用简直美滋滋~
pip install lxmlBeautifulSoup将复杂HTML文档转换成一个复杂的树形结构,方便之后对网页标签的提取。
简单使用方法:
import requests
from bs4 import BeautifulSoup
header = {
"user-agent": 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US;rv:1.9.1.5)Gecko/20091102 Firefox/3.5.5 (.NET CLR 3.5.30729)'
}
url = 'www.baidu.com'
r = requests.get(url, headers=header)
soup = BeautifulSoup(r.text, 'lxml')1.3.3Json模块
有的网页获取到的是json形式的数据,那就用不到BeautifulSoup了,需要对json数据进行转换成Python的字典形式,之后的工作就是根据字典的键值进行提取数据。
json模块安装:
pip install json导入使用:
import requests
import json
header = {
"user-agent": 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US;rv:1.9.1.5)Gecko/20091102 Firefox/3.5.5 (.NET CLR 3.5.30729)'
}
url = 'www.baidu.com'
r = requests.get(url, headers=header)
data = json.loads(r.text)1.3.4urllib模块
urllib是一个强大的模块,可以用来请求数据等,由于本文使用的是requests模块,因此这里主要用做简单的url编码和解码。
安装:
pip install urllib导入使用:
import requests
import json
import urllib.parse
header = {
"user-agent": 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US;rv:1.9.1.5)Gecko/20091102 Firefox/3.5.5 (.NET CLR 3.5.30729)'
}
url = 'www.baidu.com'
url = urllib.parse.quote(url)
r = requests.get(url, headers=header)
data = json.loads(r.text)2.基本内容爬取
脉脉网页版url:https://maimai.cn/web/feed_explore
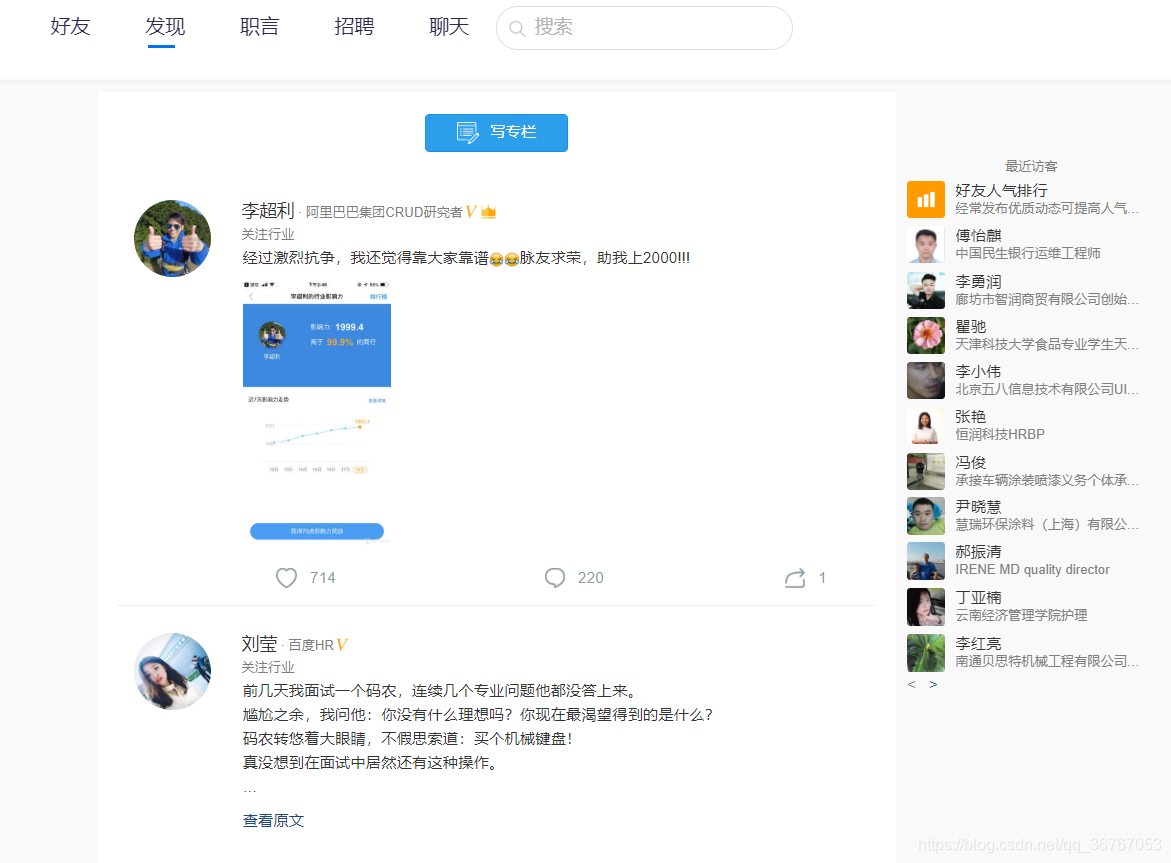
登陆之后可以看到好友的发布的动态消息,如图:
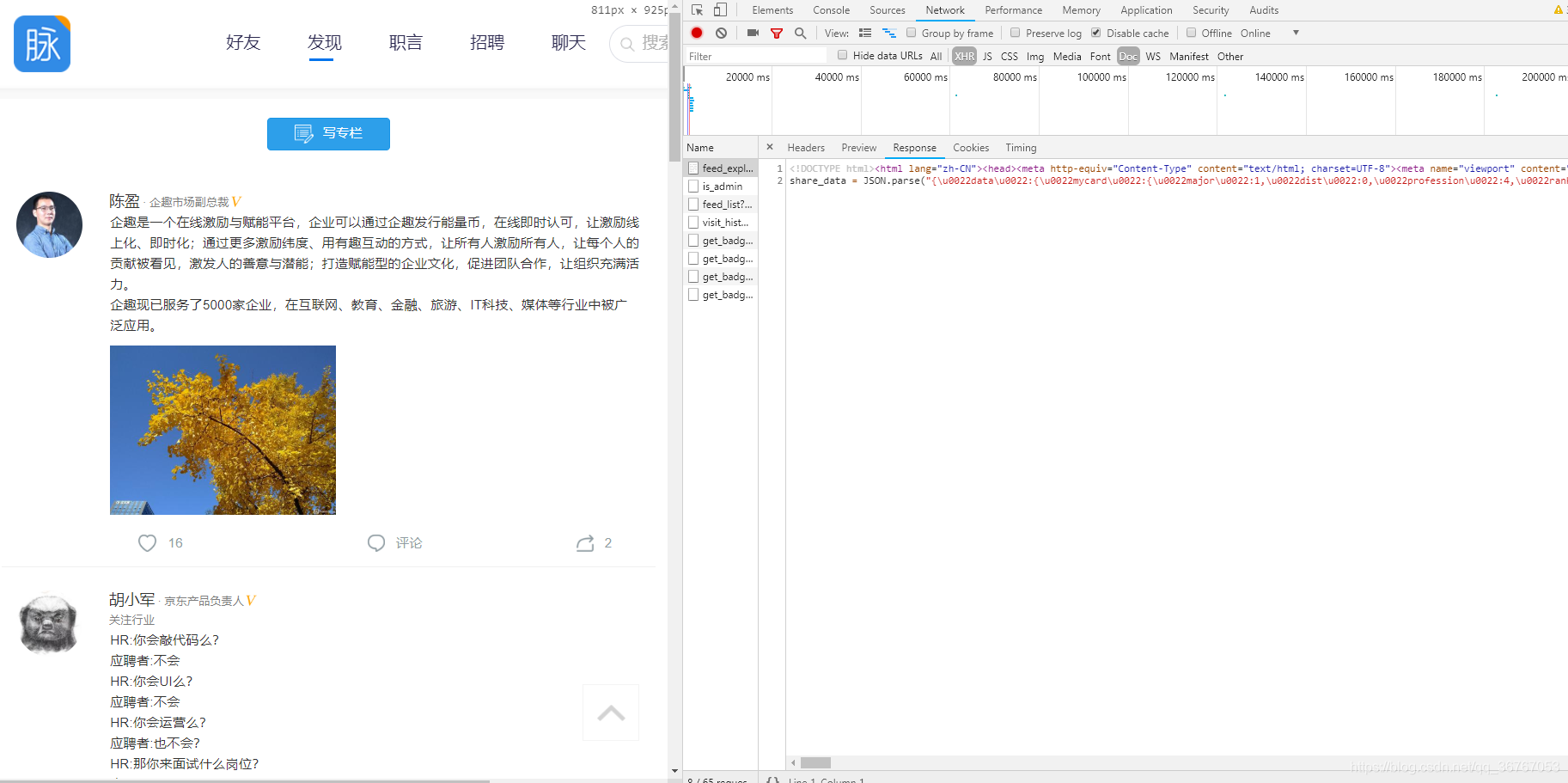
通过F12开发者工具抓包,可以看到主页显示的信息都在这里面啦!
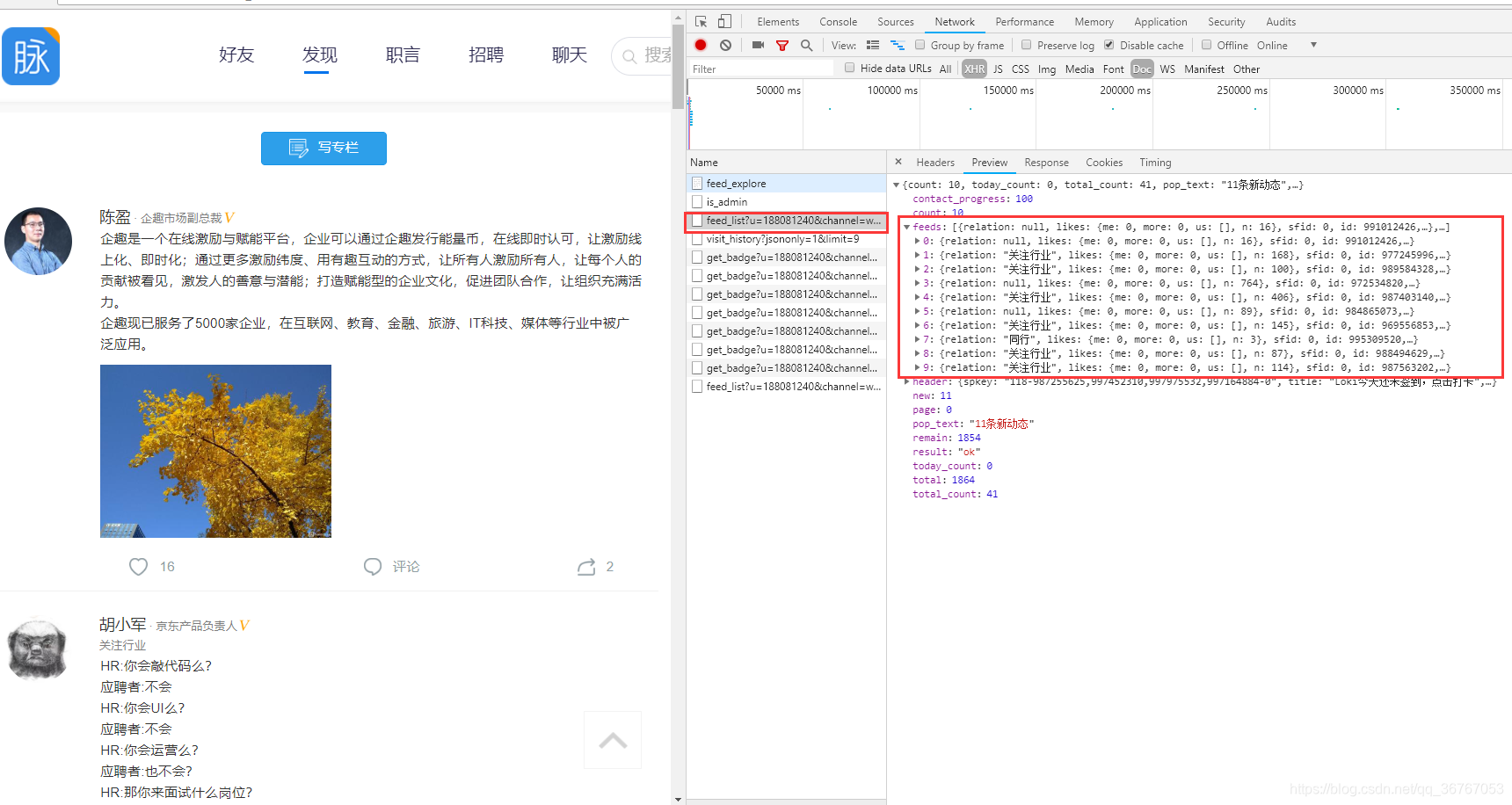
通过寻找,发现主页这些人的信息都在一个文件里面,同时往下拉动态加载的数据也在另一个类似的文件里。
接下来我们就可以构造需要的url啦!
我们来比较一下两个不同的url:
https://maimai.cn/sdk/web/feed_list?u=188081240&channel=www&version=4.0.0&_csrf=NnNNs0Mk-QJrkSl7PjtQ_gVqeYLKd8XQa54w&access_token=1.8996b04cb72224ca89393ecffbd3e1fb&uid=%22RZ01hOKhNgSH%2Bk1Ntgdo9fAirs3A3wL6ApgZu%2Fo1crA%3D%22&token=%22TAKi5qw%2Bx6ZNfy%2BZUX4f37Au1iR97LH4vHVZytesdes1Ad3Gp1o%2BHETzdIsEU%2FOF8CKuzcDfAvoCmBm7%2BjVysA%3D%3D%22&page=0&hash=feed_explore&jsononly=1
https://maimai.cn/sdk/web/feed_list?u=188081240&channel=www&version=4.0.0&_csrf=NnNNs0Mk-QJrkSl7PjtQ_gVqeYLKd8XQa54w&access_token=1.8996b04cb72224ca89393ecffbd3e1fb&uid=%22RZ01hOKhNgSH%2Bk1Ntgdo9fAirs3A3wL6ApgZu%2Fo1crA%3D%22&token=%22TAKi5qw%2Bx6ZNfy%2BZUX4f37Au1iR97LH4vHVZytesdes1Ad3Gp1o%2BHETzdIsEU%2FOF8CKuzcDfAvoCmBm7%2BjVysA%3D%3D%22&page=1&hash=feed_explore&jsononly=1发现只是page=0改成了page=1,因此我们可以通过让page的值增加的方式获取到更多的数据,是不是很赞( •̀ ω •́ )y
构造如下url,通过for循环增加page的值,requests的时候不要忘了构造header和cookie哦,要不然是获取不到数据的:
import requests
import json
cookie = {'Cookie': ''} #把复制的cookies放在这里
header = {
"user-agent": 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US;rv:1.9.1.5)Gecko/20091102 Firefox/3.5.5 (.NET CLR 3.5.30729)'
}
for page in range(0, 5):
url = 'https://maimai.cn/sdk/web/feed_list?u=188081240&channel=www&version=4.0.0&_csrf=NnNNs0Mk-QJrkSl7PjtQ_gVqeYLKd8XQa54w&access_token=1.8996b04cb72224ca89393ecffbd3e1fb&uid=%22RZ01hOKhNgSH%2Bk1Ntgdo9fAirs3A3wL6ApgZu%2Fo1crA%3D%22&token=%22TAKi5qw%2Bx6ZNfy%2BZUX4f37Au1iR97LH4vHVZytesdes1Ad3Gp1o%2BHETzdIsEU%2FOF8CKuzcDfAvoCmBm7%2BjVysA%3D%3D%22&page={}&hash=feed_explore&jsononly=1'.formate(page)
r = requests.get(url, headers=header, cookies=cookie)
data = json.loads(r.text)剩下的只需要对需要的信息进行字典的键值操作提取就可以啦~
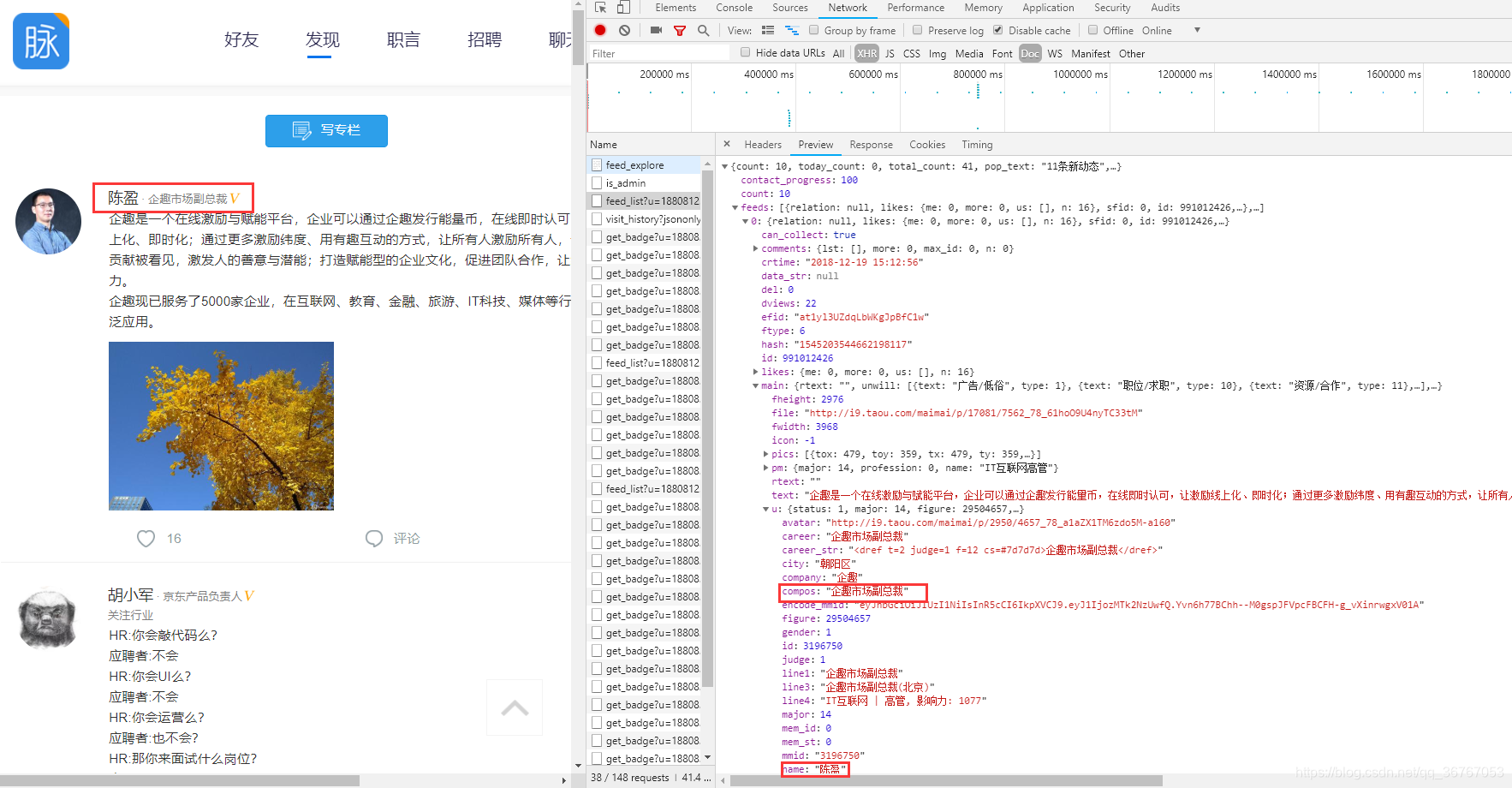
比如我们要提取姓名这一属性,发现姓名标签存在的位置依次为:feeds→0→main→u→name,按照这个顺序我们可以成功提取到姓名的这一属性的数据啦!其他的属性同理可得 o(* ̄▽ ̄*)ブ
import requests
import json
cookie = {'Cookie': ''} #把复制的cookies放在这里
header = {
"user-agent": 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US;rv:1.9.1.5)Gecko/20091102 Firefox/3.5.5 (.NET CLR 3.5.30729)'
}
for page in range(0, 5):
url = 'https://maimai.cn/sdk/web/feed_list?u=188081240&channel=www&version=4.0.0&_csrf=NnNNs0Mk-QJrkSl7PjtQ_gVqeYLKd8XQa54w&access_token=1.8996b04cb72224ca89393ecffbd3e1fb&uid=%22RZ01hOKhNgSH%2Bk1Ntgdo9fAirs3A3wL6ApgZu%2Fo1crA%3D%22&token=%22TAKi5qw%2Bx6ZNfy%2BZUX4f37Au1iR97LH4vHVZytesdes1Ad3Gp1o%2BHETzdIsEU%2FOF8CKuzcDfAvoCmBm7%2BjVysA%3D%3D%22&page={}&hash=feed_explore&jsononly=1'.formate(page)
r = requests.get(url, headers=header, cookies=cookie)
data = json.loads(r.text)
name_list = data.get('feeds')
for li in list:
name = li.get('main').get('u').get('name')3.总结
脉脉的数据还是很丰富的,例如每个人的好友列表,好友动态等信息,本文介绍了一些基本的爬取方法,供初学者参考使用,时间匆促,如有错误之处,还请各路大侠批评指正(●'◡'●)!
注:转载请注明地址https://blog.csdn.net/qq_36767053/article/details/85222871


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









