










基本介绍
正则表达式是一种匹配字符串的工具。它提供了一系列的规则即用法,也就是给字符串定义一系列规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,该字符串就是不合法的。
正则表达式常见规则和用法如下;
- ‘\d ‘ 表示匹配一个数字,eg:’\d\d\d’可以表示三个任意数字
- ‘\w‘ 表示匹配一个字母或数字,eg:‘\w\w\d’可以匹配bs4
- ‘.‘ 表示匹配任意字符
- ‘\s’表示匹配一个空白字符,如<空格>\t\r\n\f\v等等
- ‘*’表示任意个字符(包括0个),eg:‘.*’可以匹配任意字符任意次
- '+'表示至少一个字符
- ‘?’表示出现0或1次
- '{x,y}'表示出现x~y次
- ‘{x}’表示出现x次
- ‘A|B’表示匹配A或者B
- .‘^’表示行的开头
- ‘$’表示行的结束
- ‘[]’用来限定范围,如[_0-9a-zA-Z]可以匹配一个数字、一个字母或者一个下划线
注意贪婪匹配的问题:
表达式‘.*’就是单个字符匹配任意次,即贪婪匹配。 表达式‘.*?’ 是满足条件的情况只匹配一次
有了以上正则表达式的基本知识,就可以了解一下python自带的re模块了:
re模块下的主要功能函数如下图所示:

而通过re.compile(strPattern[, flag])方法来得到pattern对象,结合上述函数可利用指定的正则表达式进行多次匹配。
而得到的match对象有如下属性:

具体可以参考这篇博客文章:pythonRE模块的使用
正如文章中所言:使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,再进行其他的操作。
确定目标数据页URL
首先,我们在淘宝网站搜索’python’:

而搜索栏URL为:
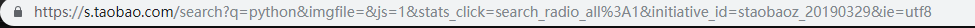
我们可以从中看到关键字’python’,而后面还有一系列参数,大致上描述了编码信息、搜索日期、搜索状态等等。我们把这些参数情清空,此时刷新后为:

可以发现内容没有差别,所以我们简化UR为https://s.taobao.com/search?q=python
接下来,我们向后翻页,继续观察URL:
第二页:

第三页:

可以简单观察到十分有规律,而bcoffset与ntoffset从名字简单推测就是一些偏移量,而最后的s,估计是顺序/序列sequence的缩写。
故而我们简化URL为:
‘https://s.taobao.com/search?q=‘+ str(“搜索关键字”) + ’ &s=’ + str(44 * n)
其中n表示第n页。
确定目标字段
假设我们要爬取商品的名称与价格。
首先,通过查看网页源代码,找到目标所在位置:
名称:

价格:

继而我们可以确定匹配名称与价格的正则表达式分别为:
r'"view_price":"[\d.]*"'#匹配价格
r'"raw_title":".*?"'#匹配名称
其中r表示非转义字符的原始字符串,即不含转义字符,反斜杠为普通字符
除此之外,我们还需要利用split()函数,将名称与价格从匹配的字符串中切出来:
最终我们可以写成如下函数:
#利用re来解析html文本
def parsePage(ilt,html):
try:
plt = re.findall(r'"view_price":"[\d.]*"',html)#匹配价格字段
tlt = re.findall(r'"raw_title":".*?"',html)#匹配名称字段
for i in range(len(plt)):#将匹配到的结果一一添加到列表中去
price = eval(plt[i].split(':')[1])#按照:分割,同时用eval函数去掉""
title = eval(tlt[i].split(':')[1])
ilt.append([price,title])
except:
print("error")
设置输出格式
假设我们已经获得了包含名称以及价格的列表,此时我们设置一个格式化输出的格式如下:
#输出商品的信息
def printGoodsList(ilt):
tplt = "{:4}\t{:8}\t{:16}"#设置标准化输出格式
print(tplt.format("序号","价格","商品名称"))#分别对应三个位置格式化输出
count = 0#计数,作为序号
for g in ilt:#按商品列表逐一输出
count = count + 1#序号加1
print(tplt.format(count,g[0],g[1]))#格式化输出
编写逻辑函数
接下来就是把整个逻辑写出来:
def main_logic(search_key,depth = 3):#搜索关键词与爬取页数
start_url = 'https://s.taobao.com/search?q=' + search_key#目标数据url格式
infoList = []#存储信息的列表
for i in range(depth):#逐页爬取
try:
url = start_url + '&s=' + str(44 * i)#确定该页的url
html = getHTMLText(url)#获取页面HTML
parsePage(infoList,html)#利用re解析页面HTML并将商品信息填入列表
except:
continue
printGoodsList(infoList)#输出信息
其中,getHTMLText(url)函数定义如下:
#获取网页html文本
def getHTMLText(url):
try:
r = requests.get(url,timeout = 30)#延迟时间为30s,get方法请求url
r.raise_for_status()#若失败则报错
r.encoding = r.apparent_encoding#转换成合适的编码
return r.text#返回得到的html文本
except:
return
尝试爬取
那么在以上函数的基础上,我们只需要调用main_logic()函数即可(需要import requests以及re模块):
main_logic('python')
但是我们会发现最终输出结果为空;
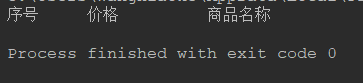
我们在main_logic()函数中尝试输出爬取到的html文本:
def main_logic(search_key,depth = 3):#搜索关键词与爬取页数
start_url = 'https://s.taobao.com/search?&ajax=true&q=' + search_key#目标数据url格式
#or start_url = 'https://s.taobao.com/search?q=' + search_key#目标数据url格式
infoList = []#存储信息的列表
for i in range(depth):#逐页爬取
try:
url = start_url + '&s=' + str(44 * i)#确定该页的url
html = getHTMLText(url)#获取页面HTML
print(html)#测试
parsePage(infoList,html)#利用re解析页面HTML并将商品信息填入列表
except:
continue
printGoodsList(infoList)#输出信息
再次运行,我们会发现我们在浏览器中查看的源代码中商品信息部分不见了,而给出了提醒:

这是因为我们缺少cookie信息,我们利用selenium不设置cookie访问的话,可以看到如下提示:
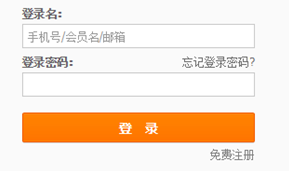
所以,我们需要在请求头中设置一下cookie:
首先在商品页面打开开发者工具,之后在netwok中查看cookie,复制即可:

然后修改获取html文件的代码如下:
#设置cookie与user-agent
cookie = 'miid=34809931572384275; cna=+F4NFAjGmwMCAXRdfFAJ4v7C; thw=cn; t=261f993926684f5aaa94682ac8ee0e83; tg=0; enc=ZhKcS4g02TvWrzzN5AurqRL943Qowjlaaiav9klspkgrGjcPR%2FZtjR7zQU4DBPDMco%2Bkt5hG2b9ku6P0uSU7lg%3D%3D; hng=CN%7Czh-CN%7CCNY%7C156; x=e%3D1%26p%3D*%26s%3D0%26c%3D0%26f%3D0%26g%3D0%26t%3D0%26__ll%3D-1%26_ato%3D0; cookie2=3376b841ff54287ff5dbcb6cd0d29e46; _tb_token_=e335e36b57716; swfstore=35377; _cc_=UIHiLt3xSw%3D%3D; alitrackid=login.taobao.com; lastalitrackid=login.taobao.com; x5sec=7b227365617263686170703b32223a2264383866316536383339326661613130636364336535386661313261383761374349712f382b5146454a616c372b323069637a3879414561444449314f444d334e5449324f4451374d513d3d227d; whl=-1%260%260%261553784745894; mt=ci=0_0; v=0; JSESSIONID=74AC0AF66DA1F4D02D912615328E9CBE; l=bBaqYQ8lvAPYNj4ABOfZNuI81G_94IRb8sPzw4sw6ICP_75HdTyAWZ6LJ1LMC3GVa6fpR3ouEw9UB48L9yUIh; isg=BDs7zHCy497Z0dgwFo5PGWjJyh9lOFCZE9SJ-y34wzoGjFlutWAW4vOKpmxnrKeK'
agent = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'
headers = {'cookie':cookie,'user-agent':agent}
#获取网页html文本
def getHTMLText(url):
try:
r = requests.get(url,headers = headers,timeout = 30)#延迟时间为30s,get方法请求url
r.raise_for_status()#若失败则报错
r.encoding = r.apparent_encoding#转换成合适的编码
return r.text#返回得到的html文本
except:
return
最后,我们可以发现爬取了相应的数据:

然而,如果不断进行爬取,例如一直爬的话,会发现最终得到的list为空,这是因为淘宝识别出了可能为机器人,我们在实际网页进行检验会发现如下提示:

故而我们要大规模进行数据爬取的话,至少有点儿时间间隔,还可能要考虑选取分布式爬取等方式。
附
其实直接以商品搜索页为目标可能会在一定程度上影响些许效率,因为商品搜索页可能解析的内容较多。
故而我们可以去找到数据存储页的URL来作为搜索目标。
方法前面的实战文章里有较为详细的内容。
大体上就是在开发者工具(F12或审查元素)开启的情况下点击翻页按钮,
在network的JS标签中观察出现的JS文件,在其中检索是否是数据存储页:

如图便是数据存储页,我们请求网页会得到下述界面:

可以看到即是原来源代码中script加载处理的内容。
然后根据之前的URL格式确定的方法,来找到其基本规律即可。这里不再赘述。
最终数据存储页基本的URL格式为:
‘https://s.taobao.com/search?q=’ + search_key + str(44 * i)
故而修改main_logic()函数如下即可:
def main_logic(search_key,depth = 3):#搜索关键词与爬取页数
#start_url = 'https://s.taobao.com/search?&ajax=true&q=' + search_key#目标数据url格式
start_url = 'https://s.taobao.com/search?q=' + search_key#目标数据url格式
infoList = []#存储信息的列表
for i in range(depth):#逐页爬取
try:
url = start_url + '&s=' + str(44 * i)#确定该页的url
html = getHTMLText(url)#获取页面HTML
parsePage(infoList,html)#利用re解析页面HTML并将商品信息填入列表
time.sleep(1)
except:
continue
printGoodsList(infoList)#输出信息















 505
505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









