







目录
一、Jmeter优化tips
- 使用命令行操作
- 尽量避免使用监听器/断言等
- 增加JVM的堆空间(压力越来越大时,需要的堆空间越大,这个值不要太小也不要太大,适中最好)
- 尽可能使用最新的Jmeter版本(这样性能会更好,也可以获取最新的功能点)
- 尽可能使用正则表达式的方式提取响应数据(但是这样也会消耗cpu性能,待商榷)
- 每台机器配置合理数量的线程数 (建议小于1000个线程数)
- 分布式压测:将负载平均分配到每台机器。与其用一台16核128g的机器,不如用4台4核16g的机器替代,因为jvm无法在超过16g的内存里工作的很好
- 执行完压测后再生成报告(因为这个比较耗cpu和内存)
- 在大多数情况下网络是个瓶颈
- 避免使用beanshell脚本 :因为要用更多的cpu,推荐用JSR223采样器中嵌入的groovy脚本,或者JSR223的post或者pre中完成
- 不要在分布式模式下执行压测:分布式模式单台的master,slave承载的限度是有限的,推荐分布式最好在20-30台的slave之间,只能在网络环境非常好才能达到40-50台的并发,单台限制2w-5w左右的并发,单台能承载1000左右的并发
- 监控测试发压机和压力机:推荐使用Prometheus监控手段完成监控
- 先在内网进行压力测试:发压机和压力机尽量在一个网络,比如在内网,因为内网网络传递速度比较快,尤其是有好的路由或交换器的时候
二、Jmeter的使用建议-参数配置
1. XX:MaxMataspaceSize(jdk8的参数)
这个参数用于限制Mataspace(堆外内存:Metaspace 区域位于堆外,所以它的最大内存大小取决于系统内存,而不是堆大小,我们可以指定 MaxMetaspaceSize 参数来限定它的最大内存)增长的上限,防止因为某些情况导致Mataspace无限的使用本地内存,如果超过设置的值就会触发Full GC,此值默认没有限制,应取决于系统内存的大小,jvm会动态的改变此值。例如:
// 如果是一台4g的机器,直接设置成4096m即可
-XX:MaxMataspaceSize=4096M
2. -Xmx2048m
设置堆内存最大值为512m,这个值推荐设置成2048m
3. -Xms1g
设置堆内存的最小值为1g(ps:-Xms和-Xmx实际上是 -Xx:InitialHeapSize和 -XX: MaxHeapSize的缩写。例如:-XX: InitialHeapSize=123m -XX: MaxHeapSize=2g)
三、Jmeter插件
1. 介绍及安装
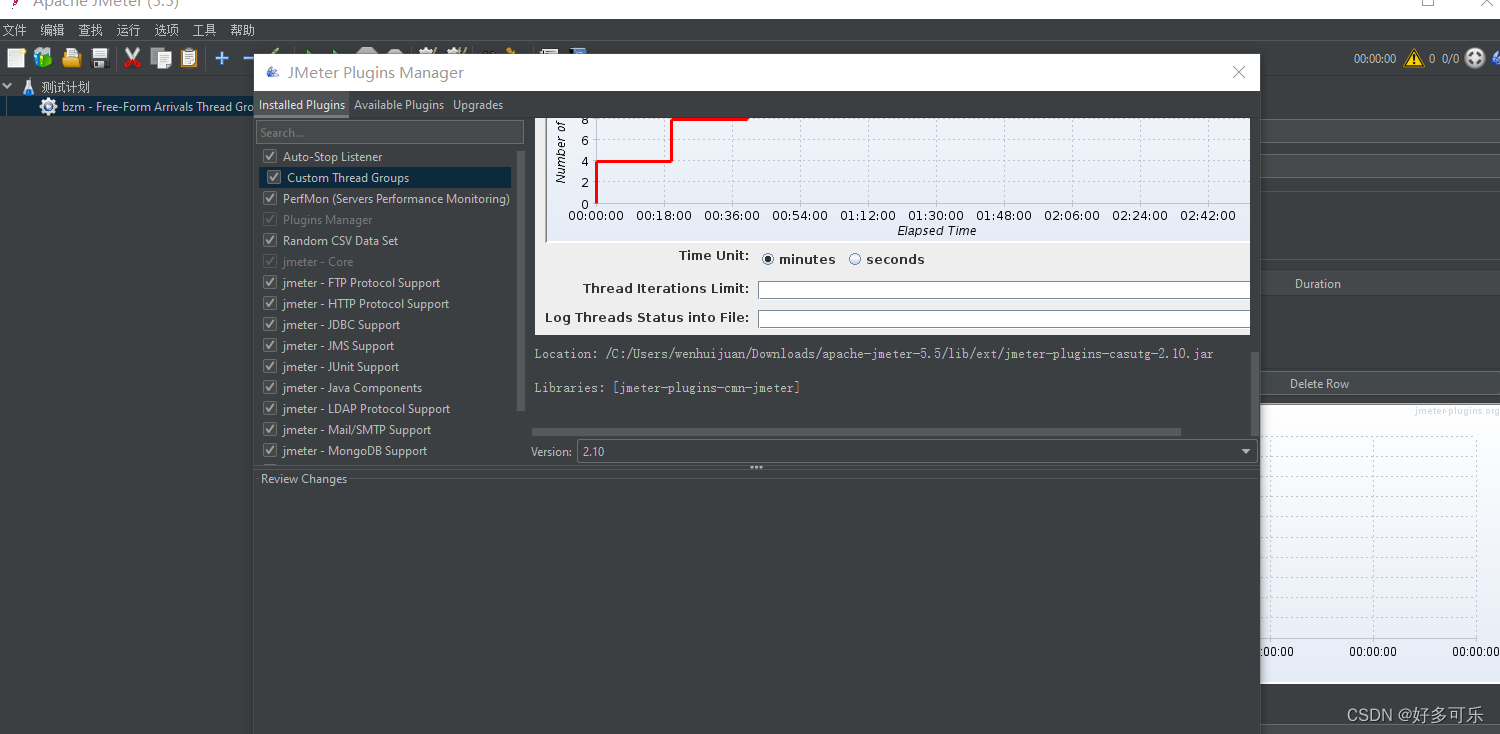
- Plugins Manager:
https://jmeter-plugins.org/install/Install/ - 优势:这里安装插件可以自动添加所需依赖
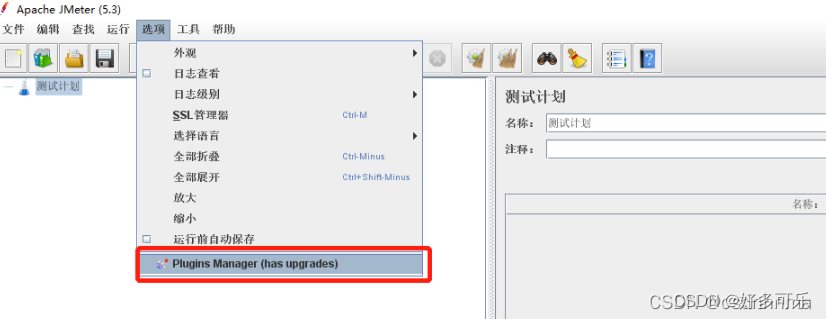
- 使用方式:
下载管理插件,plugins-manager.jar,将plugins-manager.jar拷贝到Jmeter的lib/ext目录下,重新打开Jmeter在options菜单可以看到如下界面
2. 常用插件
- Auto-Stop Listener :错误率达到设置的值就自动停止
- HTTP/2 Sampler:http2协议用的采样器
- PerfMon:同时监控发压机和被测机性能(不太建议使用)
- Random CSV Data Set:之前的csv data set config都是从头读到尾,如果是多台slave,所以slave同一时间可能都会去读第一个,会导致缓存出现问题。用这个可以随机读取,就不用给磁表文件分片
- Redis Data Set:从redis获取压测磁表
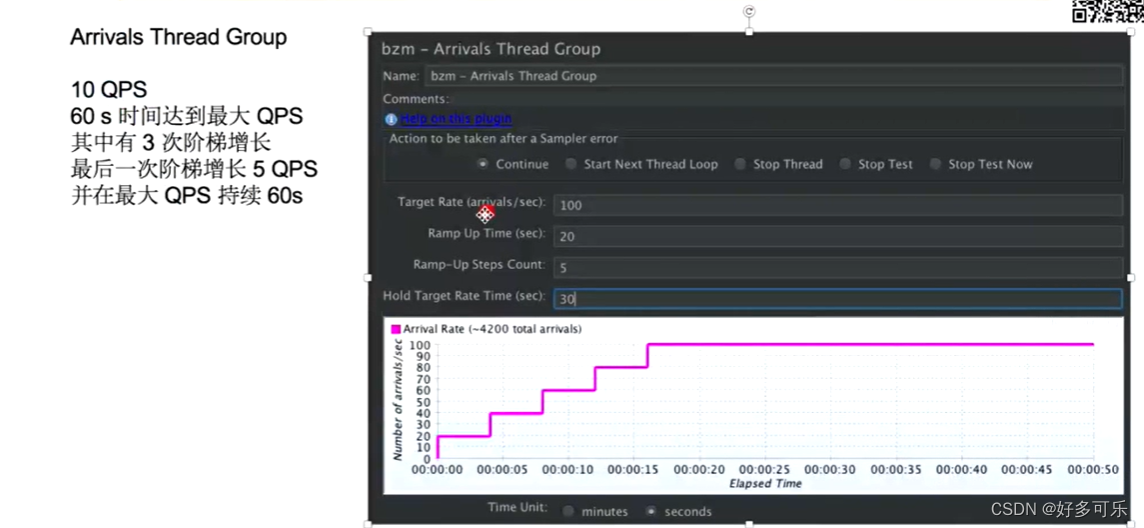
- Custom Thread Groups:定制的thread group,它有2种模式,第一种是Utimate Thread Group,就是并发线程组的方式。第二种是Free-Form Arrivals Thread Group:自带的Thread Group是按照自定义的线程数去控制并发,得到qps。这个是按QPS去控制并发,不用指定并发用户数,如果需要限制qps可以用这个去做

例子:
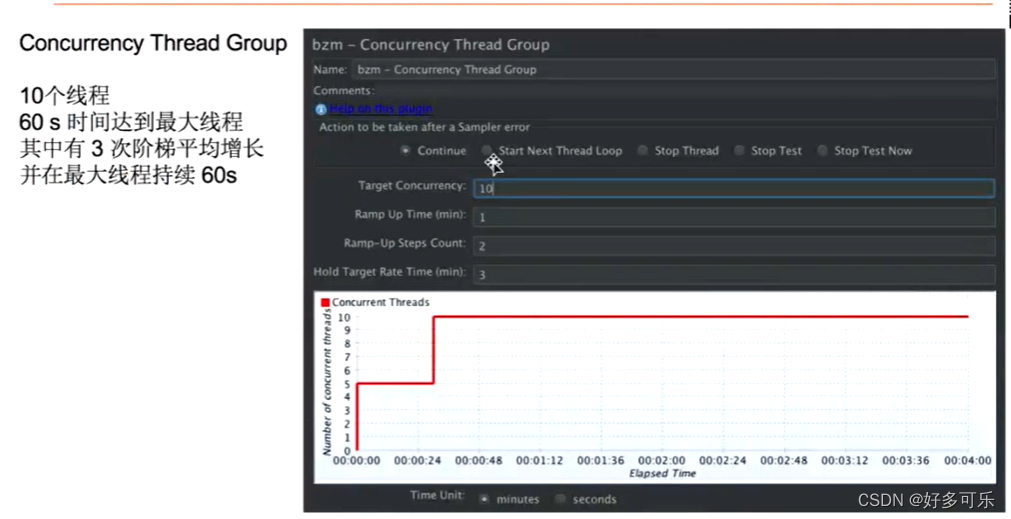
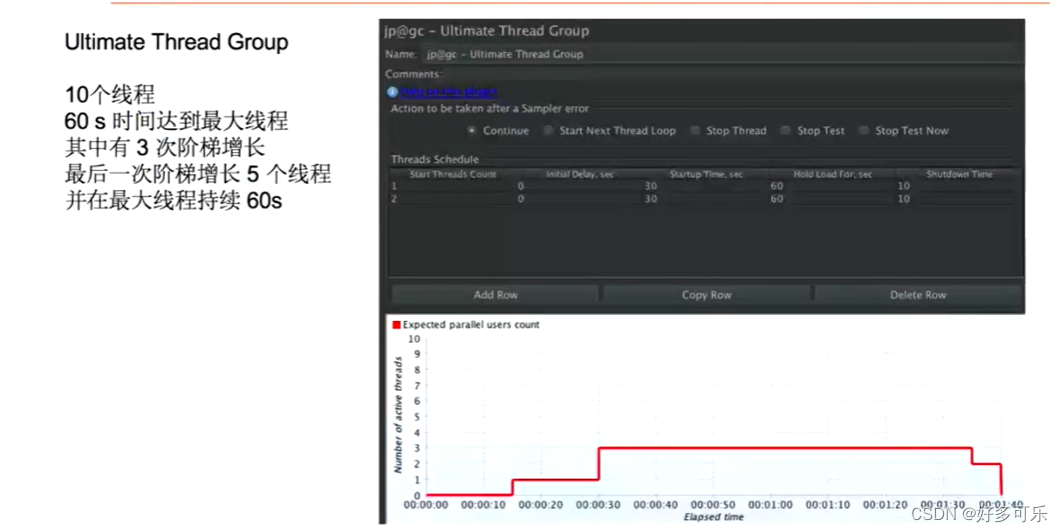
前面都是按照线程数,这里按照qps的概念来做了
四、Jmeter日志收集
1. 概览
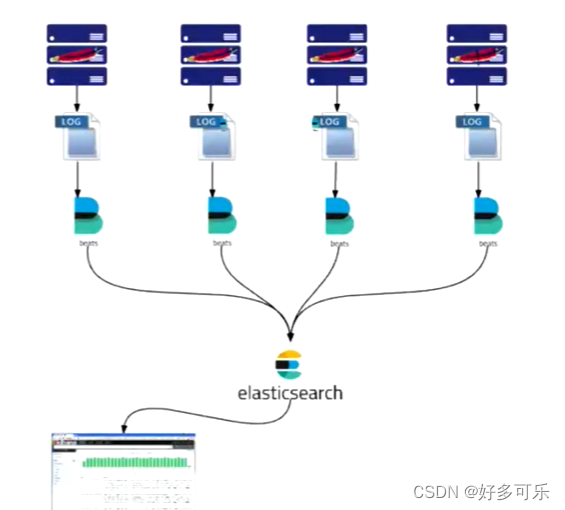
压测过程中如果我们想要看报错,就需要看日志。因为压测执行人可能会有多个,可能所有人都在看这个错误,但是不能每个人都在一台机器看,这个时候就需要用到分布式日志收集方式,本次我们用的是ElasticSearch+FileBeats+Kibana的架构
- ES:日志存储
- FileBeats:日志收集
- Kibana:日志展示
收集前我们需要安装并编辑对应的配置文件:
2. elk,kibana和es的安装和配置
// 下载并解压到本地,然后编辑配置文件
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-oss-7.5.1-darwin-x86_64.tar.gz --no-check-certificate
tar -xzf filebeat-oss-7.5.1-darwin-x86_64.tar.gz
Vi filebeat.yaml
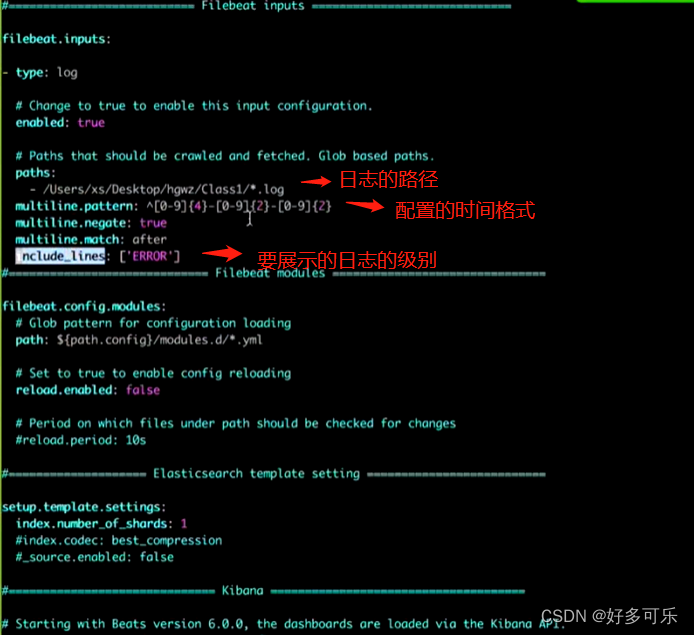
编辑配置文件时,我们重点关注这些:
- 是否开启input config
- 日志需要从哪里获取
- 有哪些行是想要的/不太想要的(3个都在截图里)
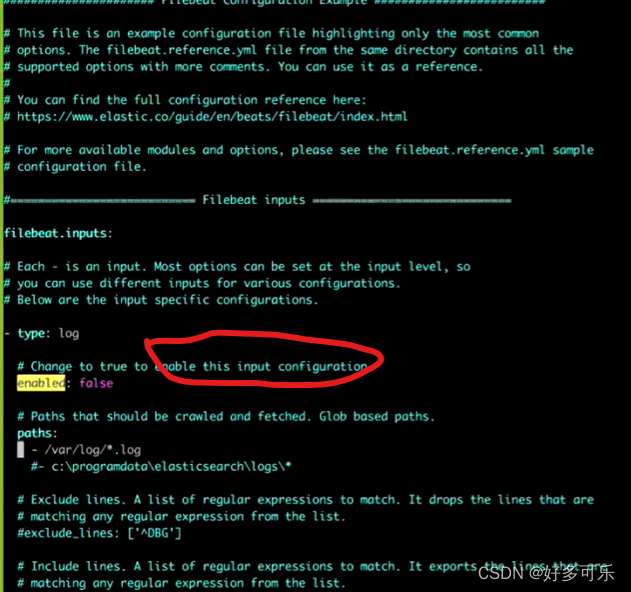
日志输出路径:因为这个给的是elk,这里会修改成对应的端口号
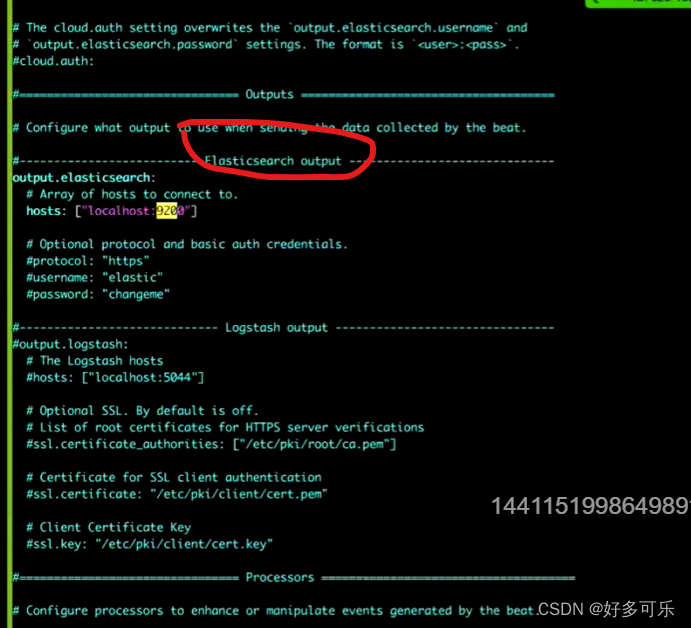
下载elk
// 启动kibana (这里限制jvm参数,因为该机器性能一般)
docker run -e ES_JAVA_OPTS="-Xms256m =Mmx256m" -idt -p 9202:9200 -p 5602:5601 nshou/elasticsearch-kibana
浏览器验证es是否启动了
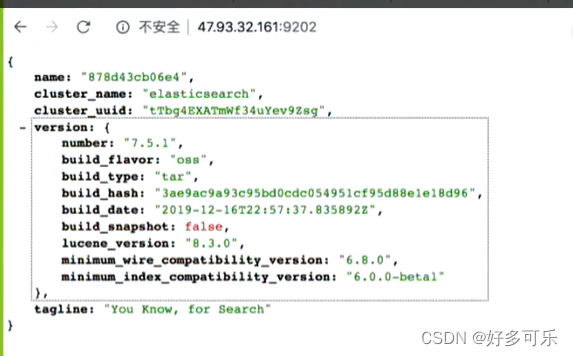
验证kibana是否启动了
配置filebeats:这些是常见的要修改的地方
vi filebeat.yml
纠正下,第二个是配置分隔符,按照什么进行分行
jmeter会生成2类日志,一个是jmeter.log,另一个是error.log,如果我们只想要打印错误日志,目前有2种方式

jmeter常用的存储变量的工具
1,ctx:
2,vars:存在jmeter变量后,可以通过vars去get/set
3,props:可以在运行时去改动jmeter原生的属性,比如说去修改开始结束时间的格式
4,prev:可以通过这个拿到上一个请求的result结果,并基于这个去做下一步的动作
- 第一种:查看结果树里(不推荐,会消耗性能)
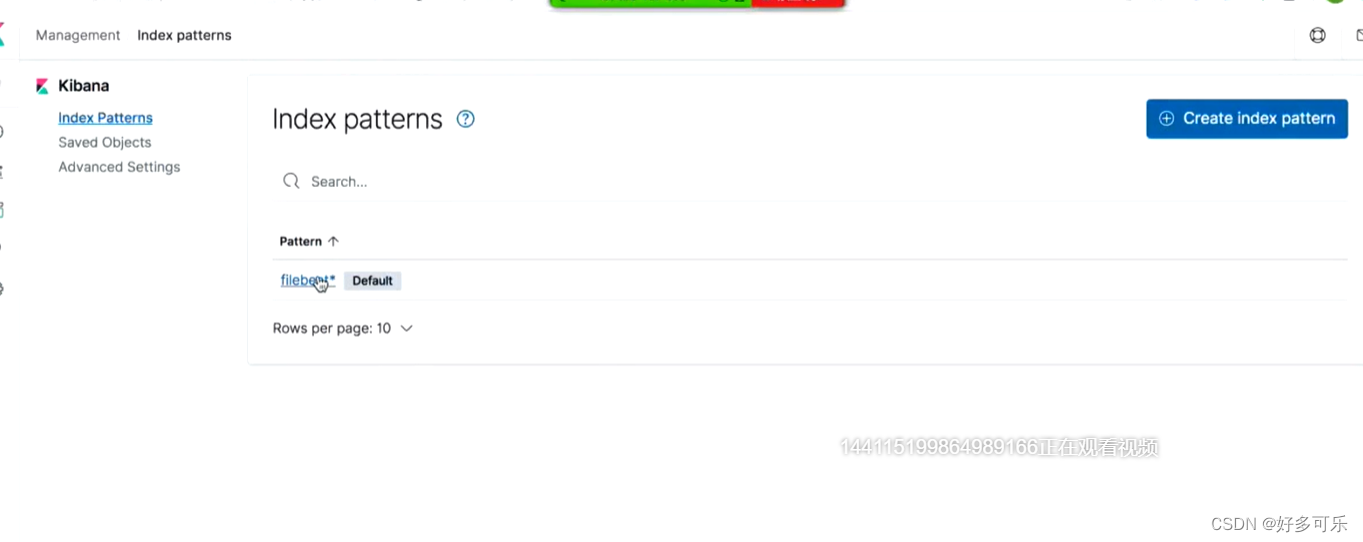
这个时候在kibana就可以收到
这里记得加一个pattern
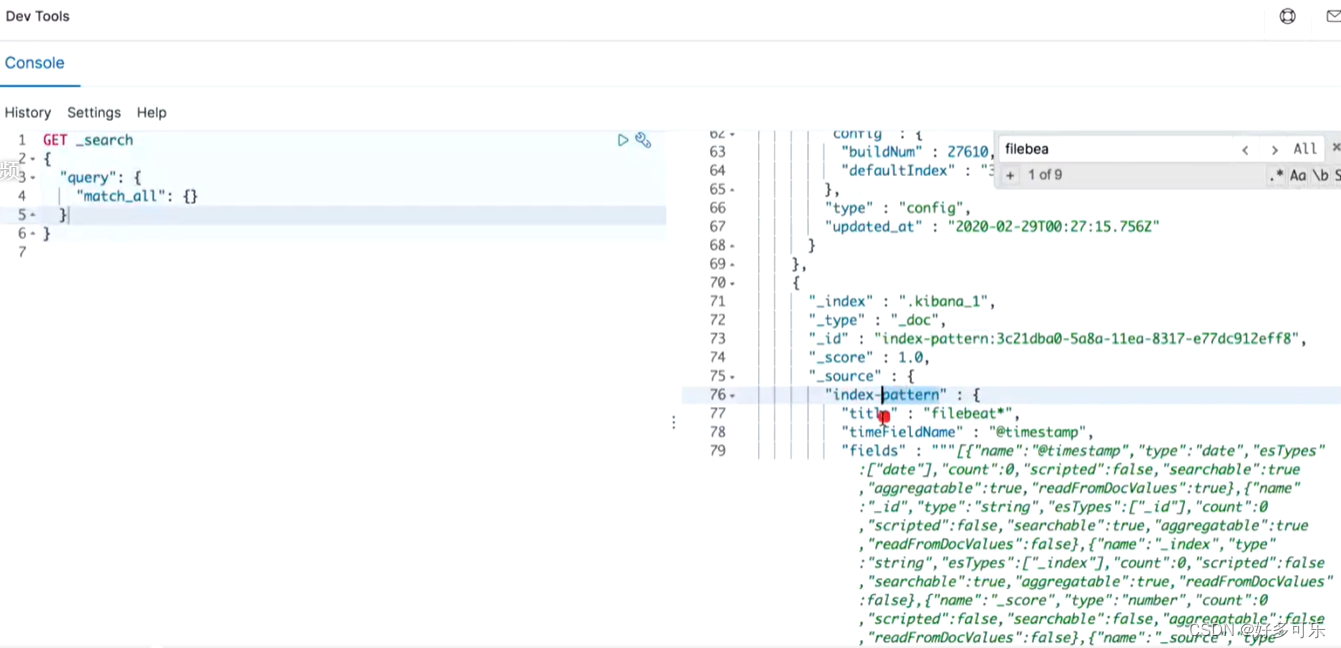
如果不确定index是啥,可以通过dev tools进行确认
我们如何对日志进行过滤,只展示error级别的呢
我们可以选择添加这个
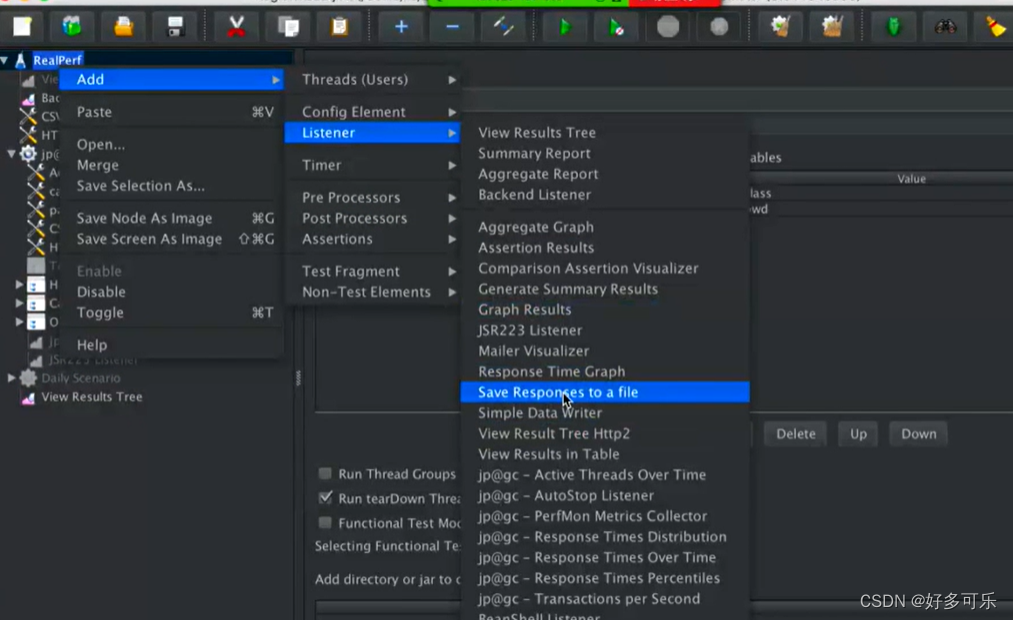
当然我们更倾向添加JSR223 listener
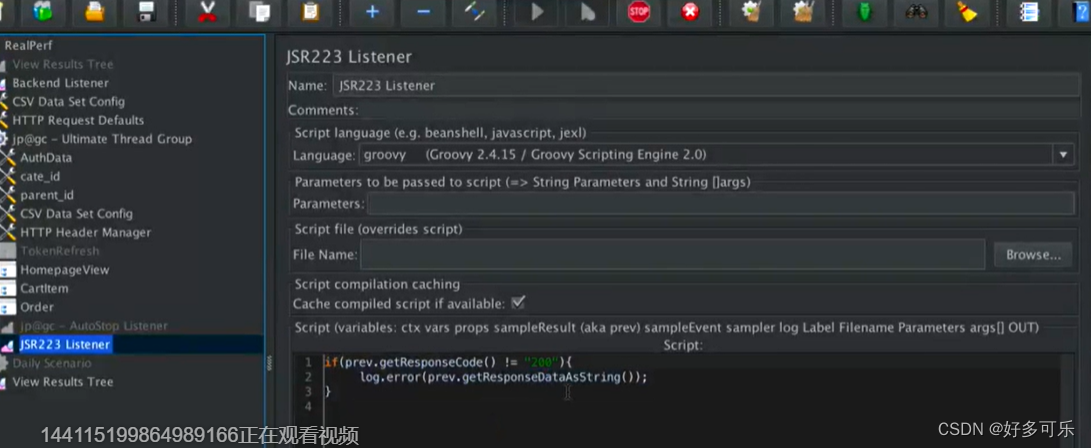
这里写了一段脚本,意思是如果code!=200,则打印出error
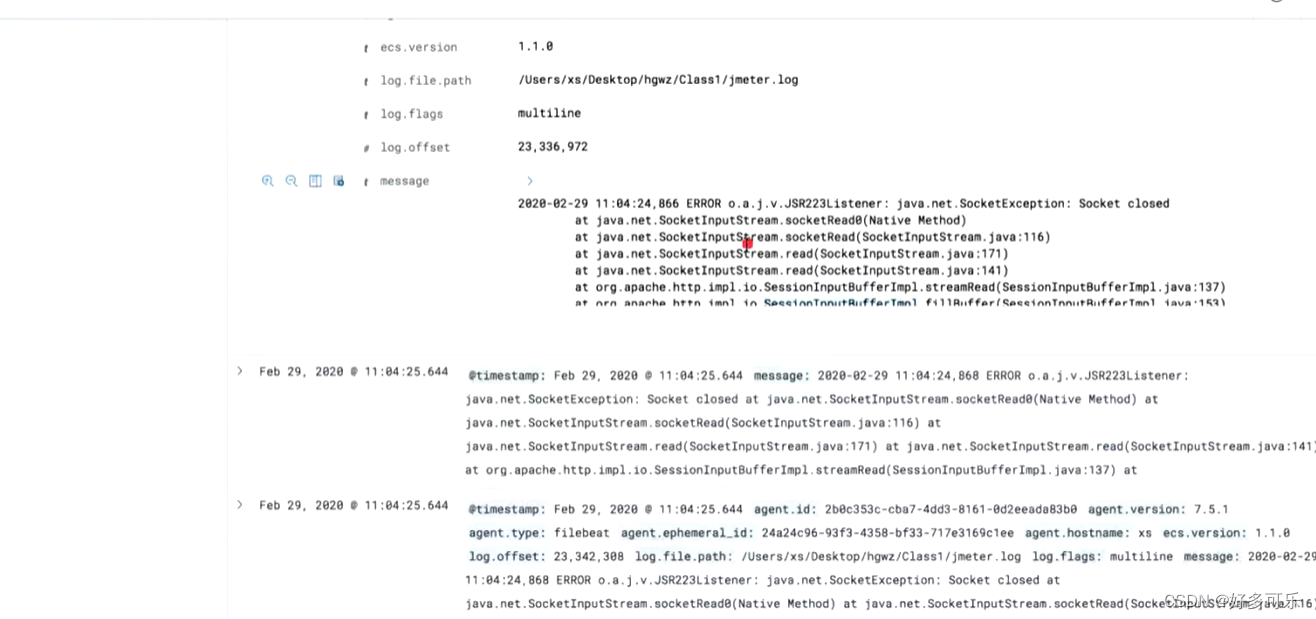
我们可以在kibana查看到对应日志
这样我们就基本能拿到客户端的比较全的监控了
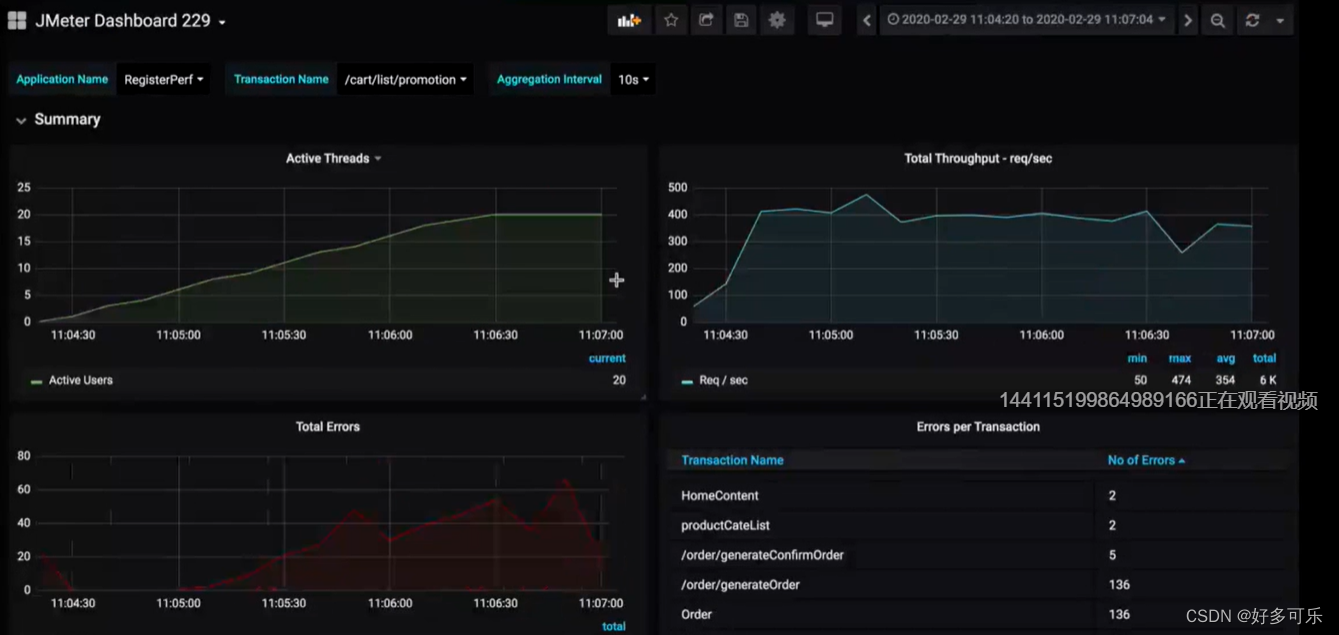
3. Prometheus和Node Exporter,grafana的安装及配置
-
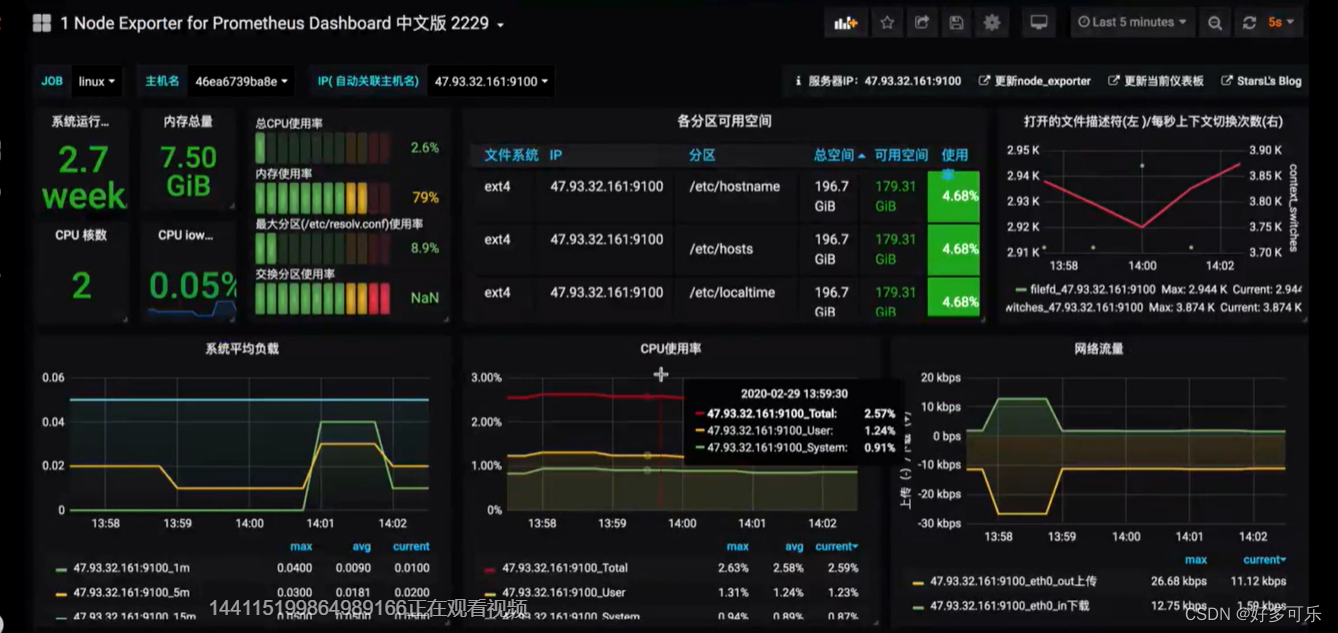
Prometheus架构:
- 分为三层,第一层是数据发送方node exporter;第二层是数据存储方prometheus server;第三层是数据展示方:如grafana或者prometheus web ui。
- 具体:prometheus的target:通过各种各样的jobs或者exporters,把指标打到prometheus上,prometheus把它存到数据库,并且通过sql的查询方式通过如grafana来访问调用存储的数据,并且prometheus配合alert manager采集数据,通过email,企业微信等方式发送报警。
配置完成以后我们查看报表,可以看到jmeter达到瓶颈的同时,机器性能总体是比较优,并没有什么异常表现,还在可接受范围,这个时候我们可以从其他角度拿到服务端压测数据,并对其进行分析
五、Spring JVM,Mysql,Redis,MongoDB调优
如果被测应用是springboot应用,想对其jvm或者springboot进行监控可以用micrometer插件
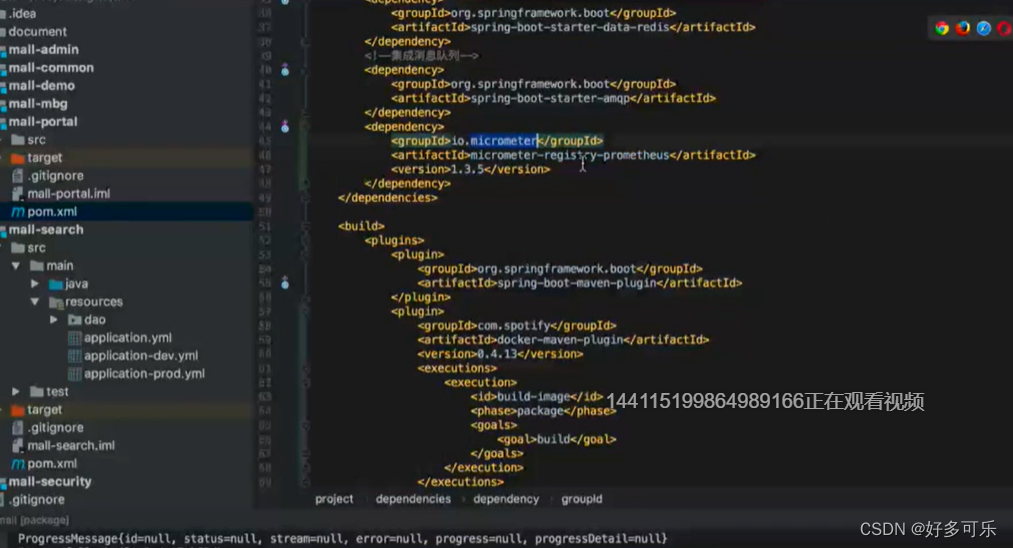
操作步骤:
- 添加依赖
<dependence>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
<version>1.3.5</version>
</dependence>
-
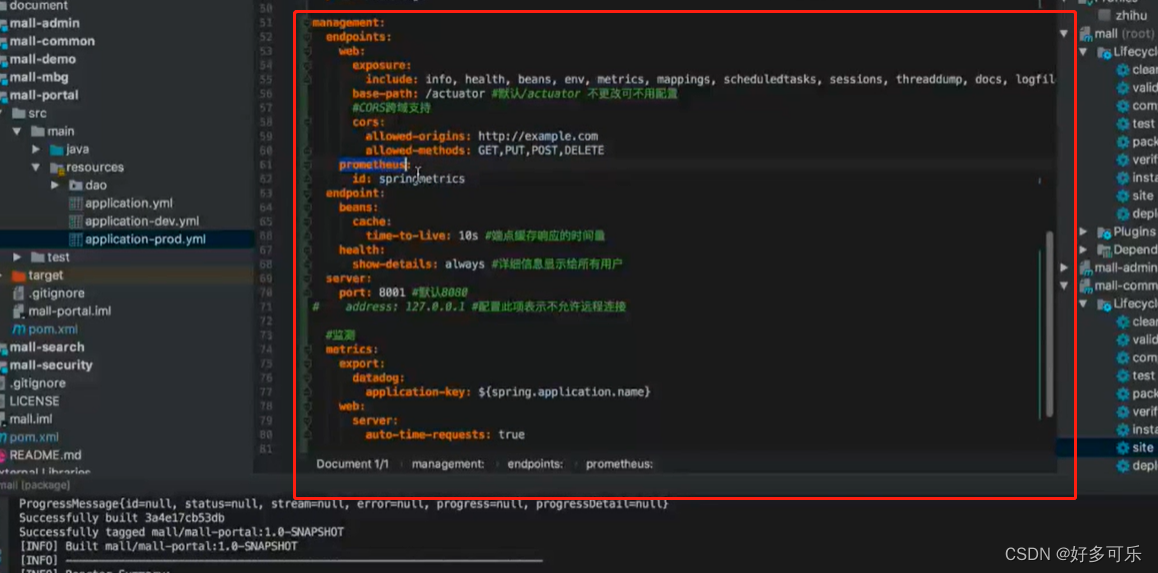
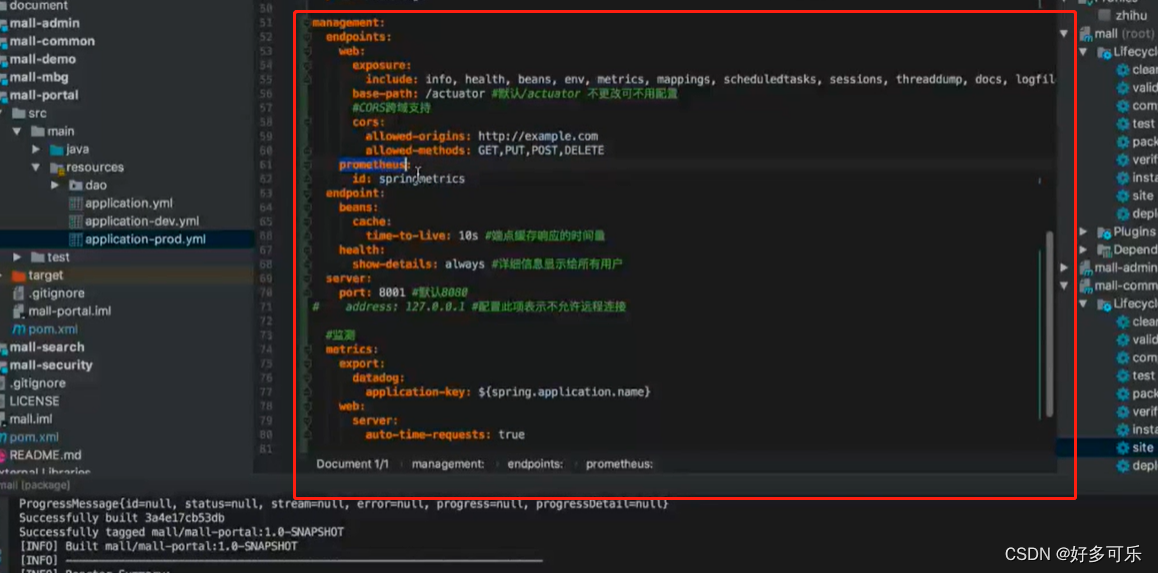
配置文件
在这个yml文件进行配置
-
push image到远程仓库
配置完记得点击右边的package进行打包,这边配置了docker插件,会自动push到远程
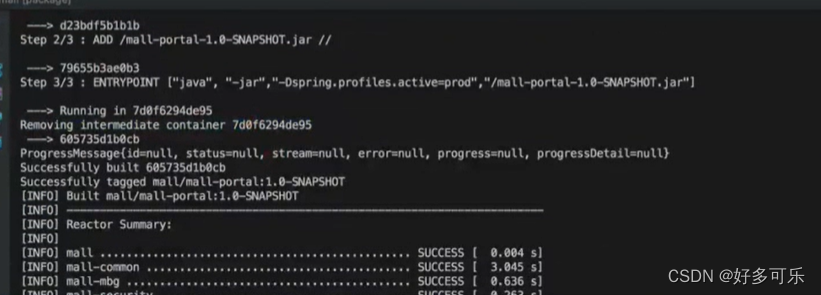
-
docker Image暴露对外接口:
docker run -p9100:9100 -p 8001:8001 -p 8085:8085 --name mall-portal --link mall-mysql:db --link mall-redis:redis --link mongo:mongo --link rabbitmq:rabbit -v /etc/localtime:/etc/localtime -v /mydata/app/portal/logs:/var/logs -d mall/mall-portal:1.0-SNAPSHOT
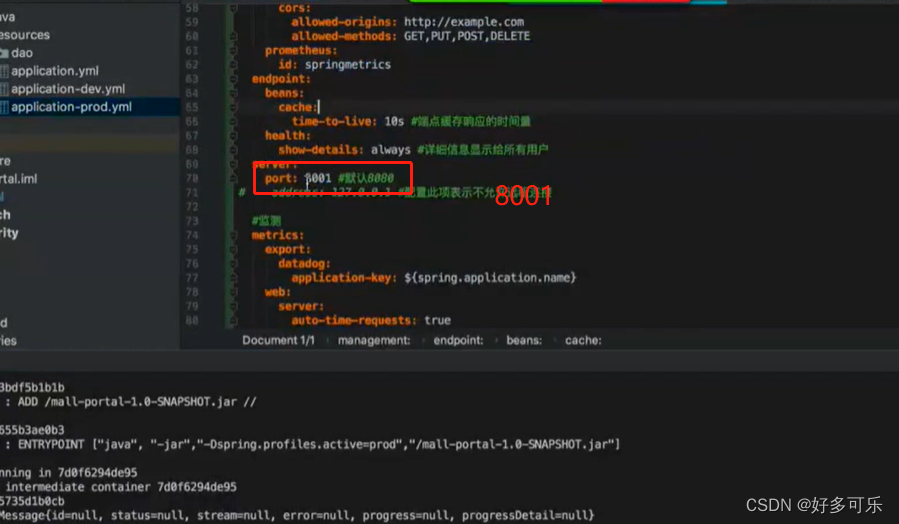
配置完之后访问这个,如果可以正常访问就表示配置成功了
为啥要在这个目录去找呢?因为我们在配置文件就是这么配置的
base-path
8001
- 编辑prometheus.yml文件
编辑这个文件,加上这部分,然后保存
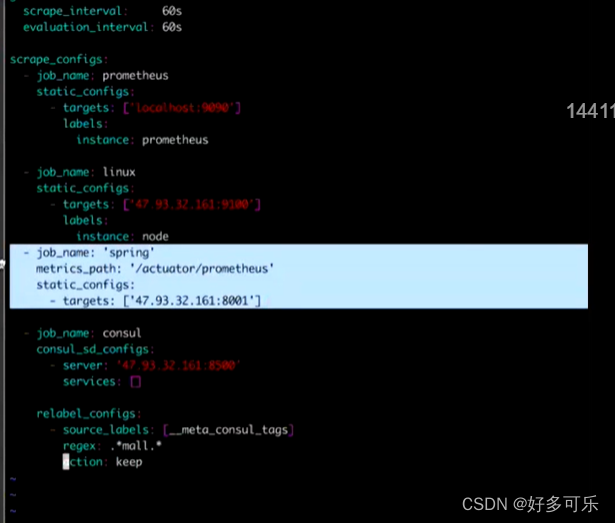
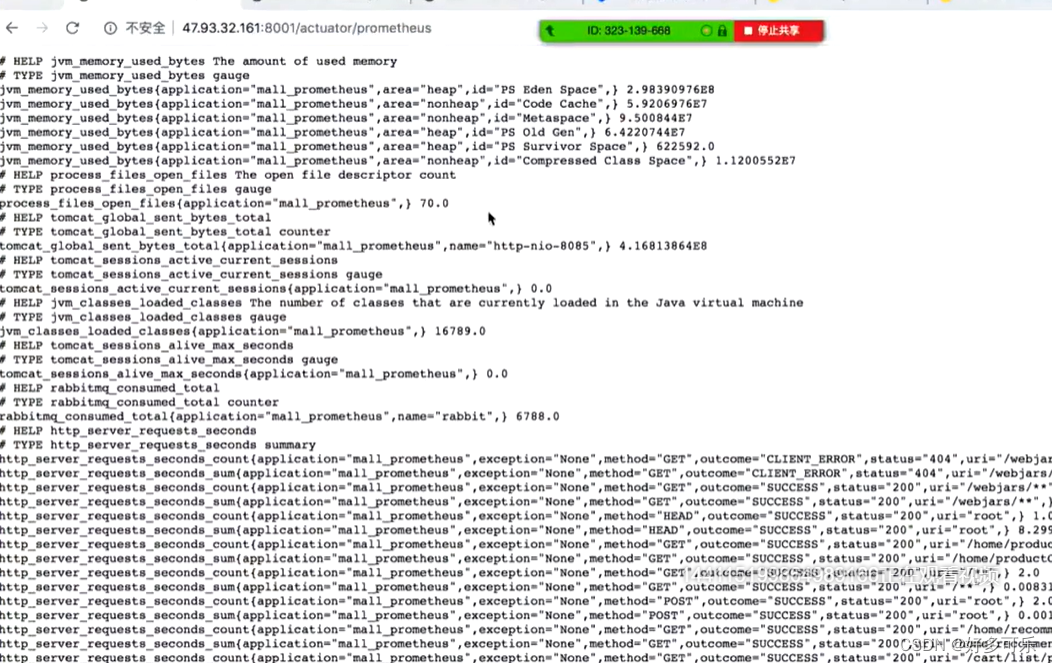
- 查看Prometheus里是否能够拿到9090端口
如果在这里能看到spring,看到状态和值,
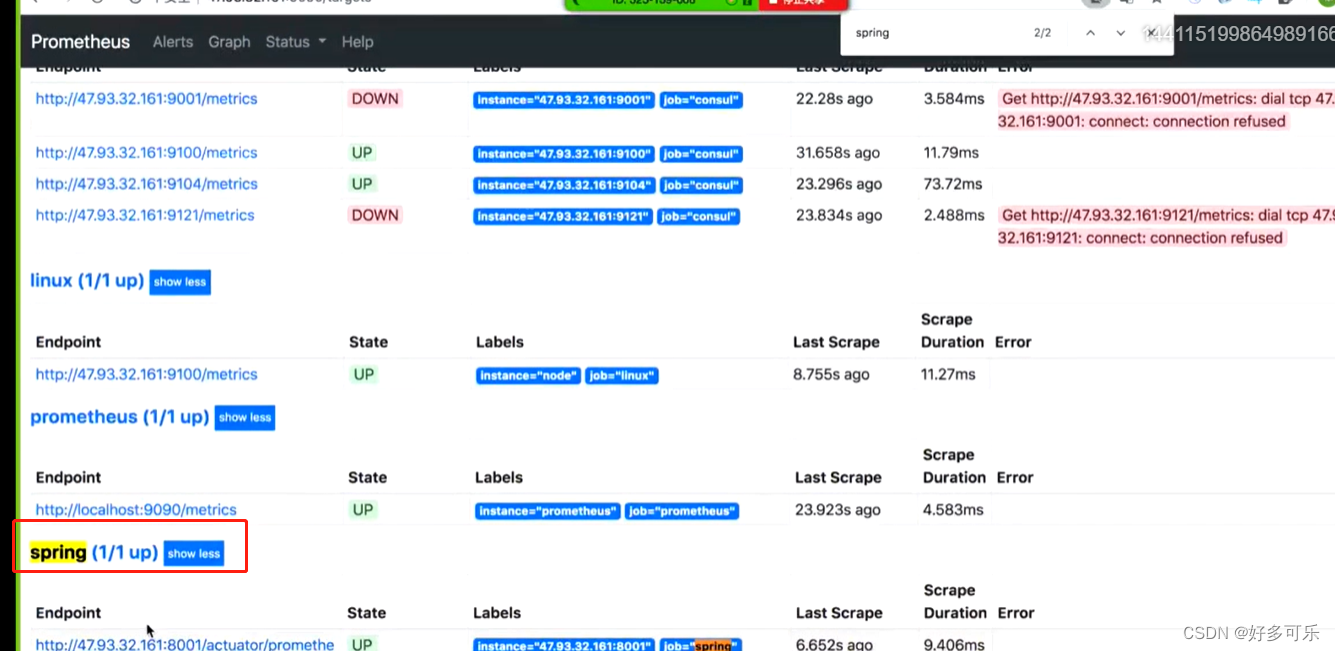
介绍一下里面的指标值
| 指标名称 | 含义 |
|---|---|
| jvm_memory_used_bytes | jvm内存的使用,包括堆内存/非堆内存,新生代/老生代,具体的值 |
| jvm_threads_live_threads | jvm活跃线程数,主要指当前活跃线程数 |
| jvm_threads_peak_threads | jvm峰值线程数是多少 |
| jvm_classes_loaded_classes | 加载了多少class线程数以及待加载的class数 |
| jvm_gc_xxx | 重点关注如主gc和副gc的发生的时间,发生的次数,gc的耗时,gc的最大内存 |
| tomcat_sessions_xxx | tomcat的连接相关数据,比如创建/活跃session数 |
| system_cpu_usage/count | jvm使用的cpu核数,使用率信息等 |
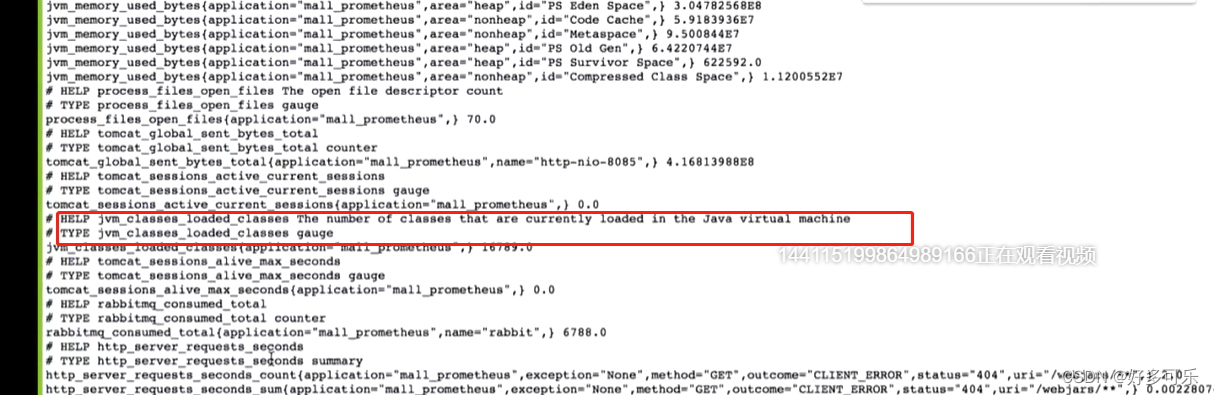
- jvm_classes_loaded_classes

- jvm_threads_peak_threads

- jvm_gc_xxx
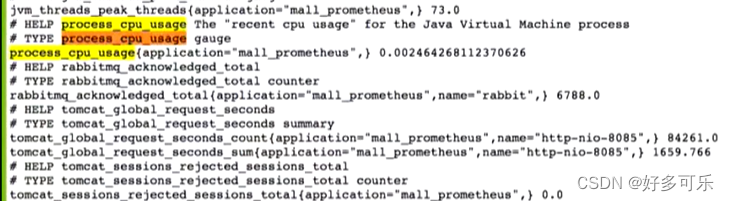
- system_cpu_xxx
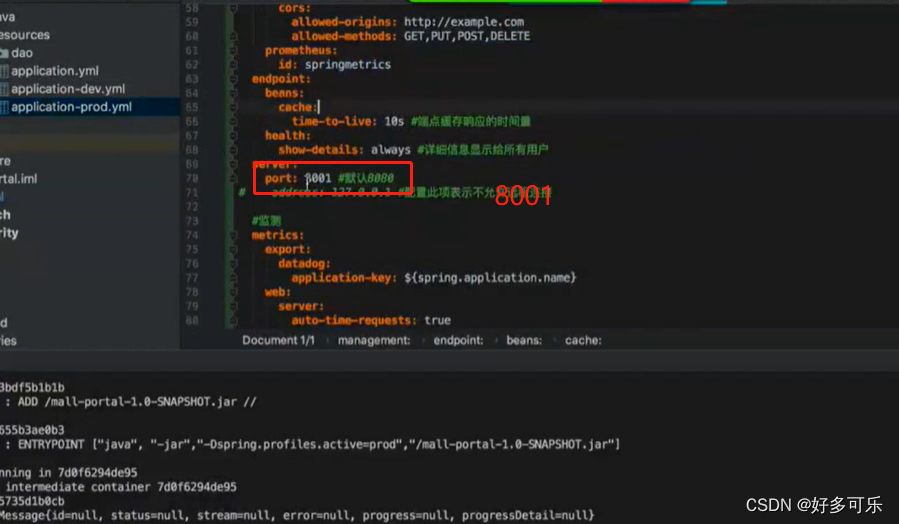
- 当yml配置文件的
auto-time-requests:true时,会把接收到的请求,请求的状态,响应耗时打印出来

总结一下,我们可以通过这个micrometer获取jvm所有信息和tomcat的session信息和服务请求的详情信息,还有当前进程和系统的cpu情况。
因为这样显示不太直观,我们直接来用报表展示
- 添加报表
首先我们需要搜索插件:
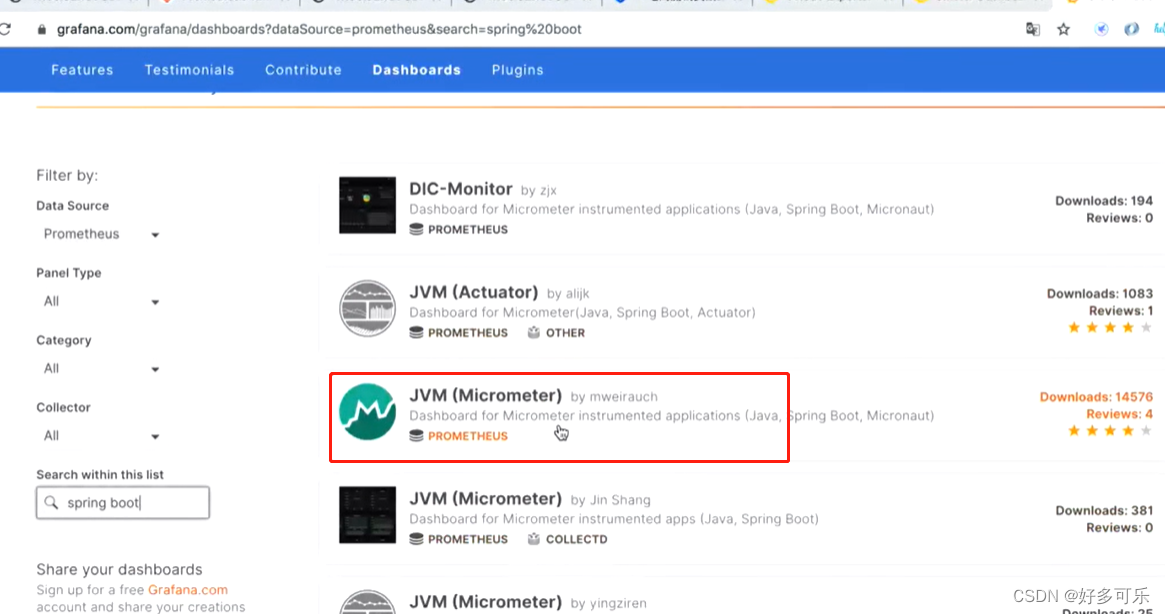
添加插件:
查看报表:
我们可以看到启动时间,首次启动时间,堆内存使用占比,非堆内存的使用占比等参数
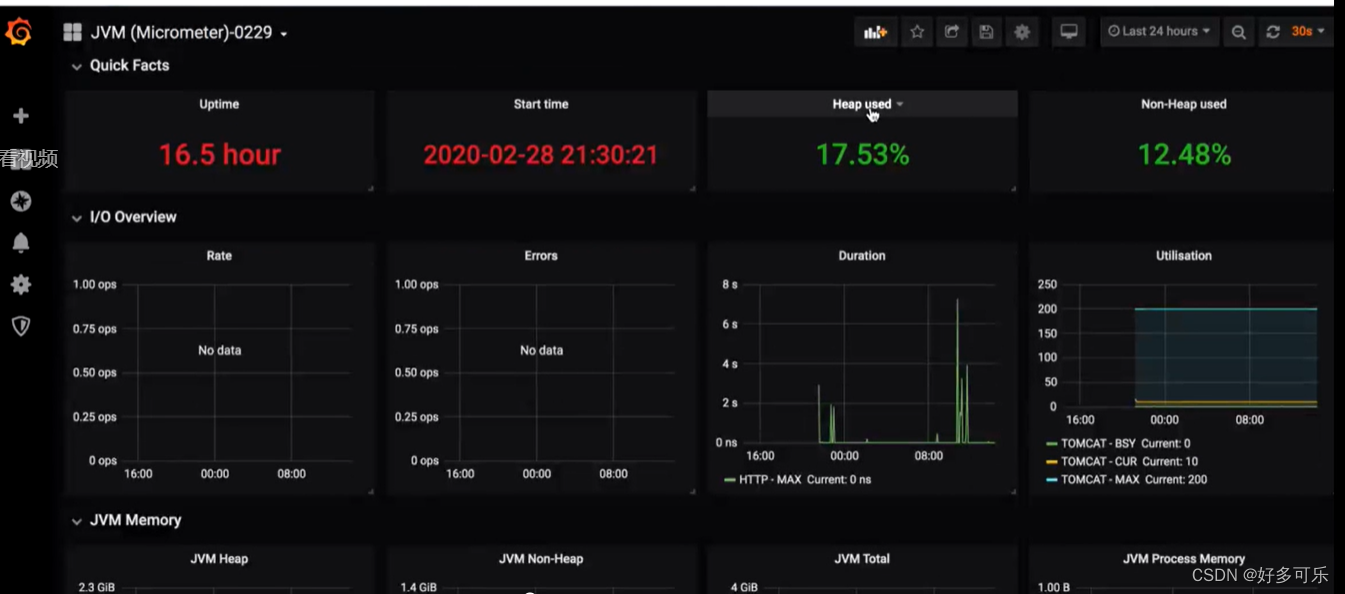
- rate:请求的qps占比
- errors:错误数
- duration:不等于5xx的响应请求数
- utilsation:tomcat的使用情况
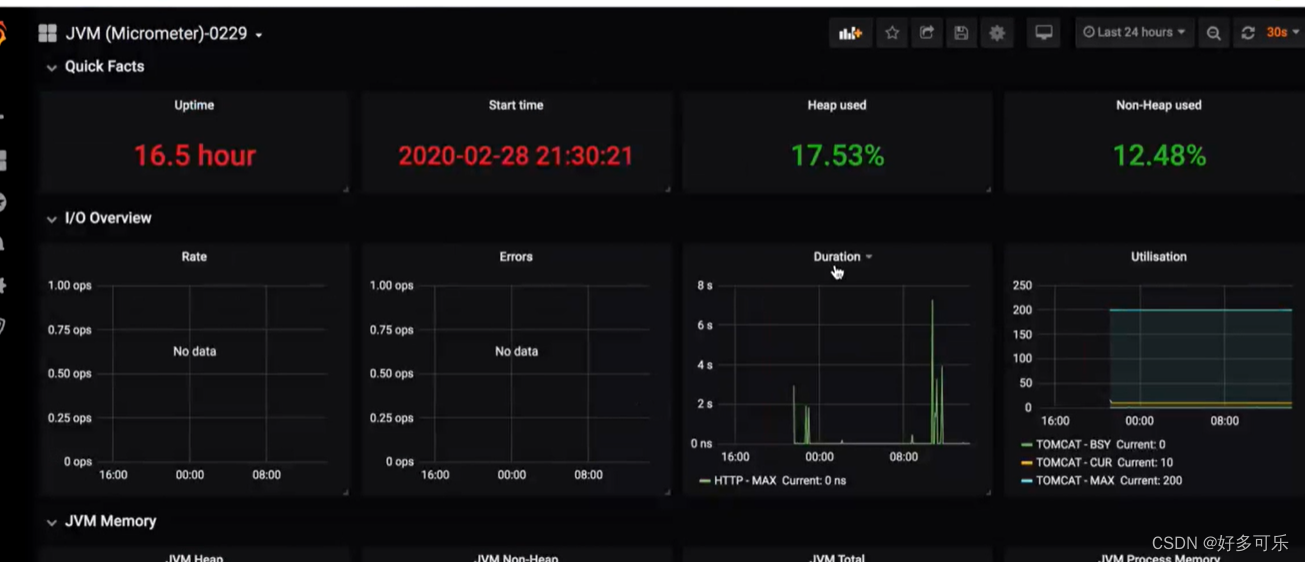
- jvm heap:jvm堆内存具体使用情况
- jvm non-heap:jvm非堆内存使用情况
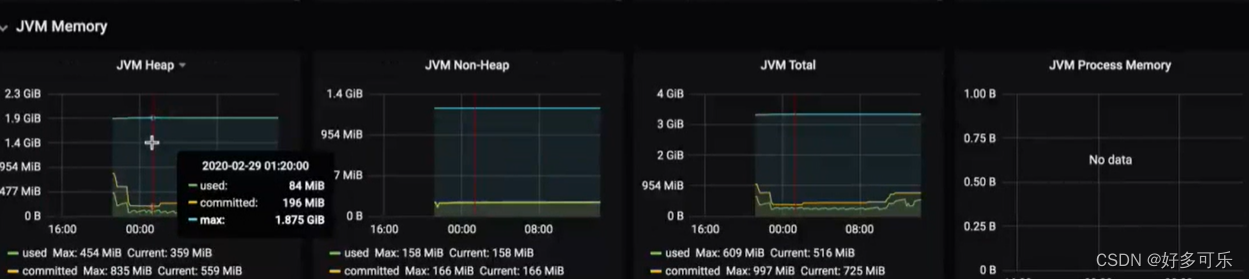
jvm的cpu,活跃线程数等属性
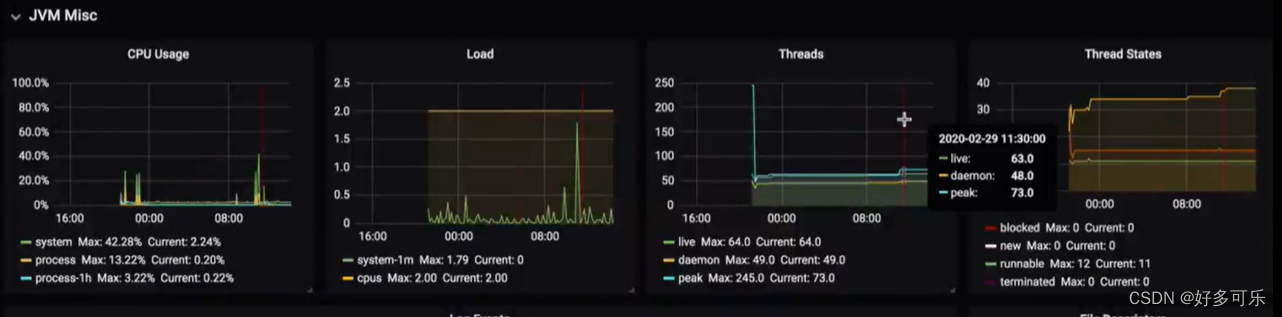
gc的一些属性,比如耗时啥的















 1036
1036











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









