







概述
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的软件。
Flume的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume在删除自己缓存的数据。
Flume支持定制各类数据发送方,用于收集各类型数据;同时,Flume支持定制各种数据接受方,用于最终存储数据。一般的采集需求,通过对flume的简单配置即可实现。针对特殊场景也具备良好的自定义扩展能力。因此,flume可以适用于大部分的日常数据采集场景。
当前Flume有两个版本。Flume 0.9X版本的统称Flume OG(original generation),Flume1.X版本的统称Flume NG(next generation)。由于Flume NG经过核心组件、核心配置以及代码架构重构,与Flume OG有很大不同,使用时请注意区分。改动的另一原因是将Flume纳入 apache 旗下,Cloudera Flume 改名为 Apache Flume。
运行机制
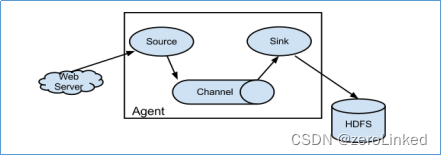
Flume系统中核心的角色是agent,agent本身是一个Java进程,一般运行在日志收集节点。
agent内部有三个组件:
- Source:采集源,用于跟数据源对接,以获取数据
- Sink:下沉地,采集数据的传送目的,用于往下一级agent传递数据或者往最终存储系统传递数据
- Channel:agent内部的数据传输通道,用于从source将数据传递到sink
简单测试
netcat-log.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sinks.k1.type = logger
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
启动agent
bin/flume-ng agent -c conf -f conf/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
测试
输入以下命令,然后往其中输入内容并回车,再观察agent的情况
telnet localhost 44444
采集数据到kafka
demo
a1.sources = r1
a1.sinks = k1
a1.channels = c1
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /var/data/flume/taildir_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /var/data/mock_data/MOCK_DATA.dat
a1.sources.r1.maxBatchCount = 10
a1.channels.c1.type = memory
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = MOCK_MSG
a1.sinks.k1.kafka.bootstrap.servers = node1:9092,node2:9092,node3:9092
a1.sinks.k1.kafka.flumeBatchSize = 10
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 1
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1















 1222
1222











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









