







k8s_day03_05
service 于endpoint 关系
k8s 当中,service 是标准的资源类型,作用是为了动态的一组pod 提供一个固定的 访问入口,clusterip,访问入口就可以认为是一组应用的前端负载均衡器。
一个service 如何识别它背后有多少个pod ? 在每个pod 上 给他添加独立的标签,前端的service 将使用标签选择器来挑选中一组pod. 过滤名称空间下的pod ,满足标签选择条件的pod 都会被认为是service 的后端端点(一个服务的ip + port 构成的访问入口就把它称为端点endpoint ).
service 不仅能把标签选择器选中的pod 做为后端端点 , 它还能对后端端点做就绪状态检测。如果这个 pod/端点是就是的 ,service 就可以把它加入到 后端可用列表中来 , 否则就把它移除掉。 这个过程并不是service 自己直接做的,而是借助了 另一个 资源 Endpoint 也是标准的资源类型只不过service 会自动管理endpoint
再重复一遍:
pod 是数据资源的一个schema , endpoint 也是。 service 创建成功之后能发挥作用是因为 有一个 叫 service controller 的组件,endpoint 同理 它要发挥作用也是靠 Endpoint Controller 。很多资源都有它的专用控制器,以确保它所对应的意义能实现
再重复一遍:
创建一个pod 就是在apiserver 中添加一个数据项 ,一个pod 中包含 运行 容器的意义和价值,这时侯 就必须由控制器调用、或者 触发 apiserver /控制平面的调度器, 调度器会绑定某个节点对应的kubelet 来把这pod 中容器给运行起来 。所以控制器至关重要 ,它们都打包在 contpller manger 当中。
service 和 endponit 都有自己的service 确保自己能正常工作。 所以创建一个service , 必须指定的属性就是标签选择器。 而后 service 控制器 就会根据创建标签请求创建同名的ep 资源。 接着endpint 的控制器 就会介入,因为出现一个新的自己管理的资源,endpint 的控制器 会使用 endpoint 标签选择器(继承自service 的) 查找多个符合标签选择器的pod , 并且会检查pod 就绪状态。
ep 会把就绪状态的pod 告诉service , service 通通把它门加入后端端点,用clusterIp 来标识它们。所以说service 绑定pod 其实是由endpoint 做的
service只复责调度
简单来说 ,service 就是 为 一组具有相同功能的pod对象 ,使用标签过滤成为一组pod 对象。 并且把这一组对象作为能同一接受请求流量的后端进行管理 根据pod对象的就绪状态 决定是否把它加进来
kube-proxy代理模型 3种
在k8s 当中 ,真正负责service 工作的 是叫kube-proxy 组件
kube-proxy , 是service controller 位于 各个节点的agent
kube-proxy 的代理模型:
1、userspace 代理模型 已经弃用
(因为发请求的过程报文会再次进入用户空间)
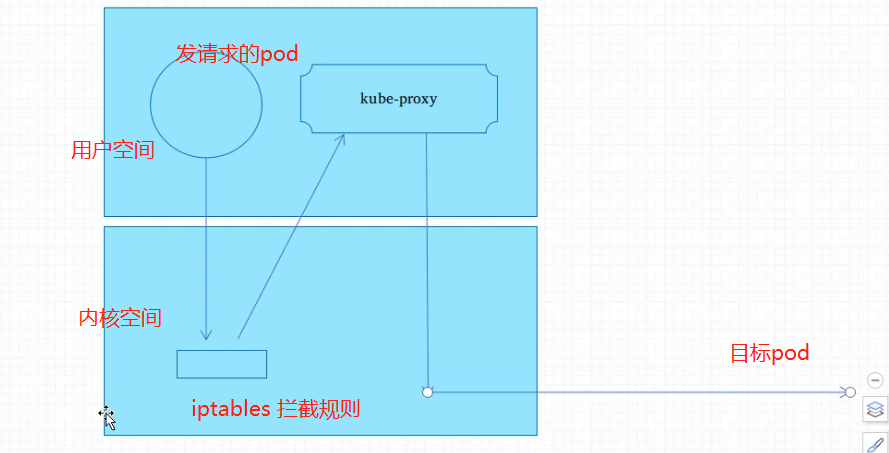
最早期的kube-proxy 是一个服务进程 , 和nginx一样,所有的调度都是由kube-proxy完成的。
pod 是运行在用户空间,pod 去访问其他节点的pod(或者service) , 它的请求会先到自己节点的内核空间 netfilter 上面来, 第一种方式是把service 实现为一种iptables拦截规则. 把请求拦截下来以后 但是自己不调度,会把拦截住的请求 重定向为同样运行在该节点用户空间 一个成为 kube-proxy 的进程。 kube-proxy 会 根据请求选定 后端调度地址后 再发回内核空间,最终调度给某一个pod。
因为请求报文会在内核于应用空间多次切换 ,所以效率低
2、iptables 模式
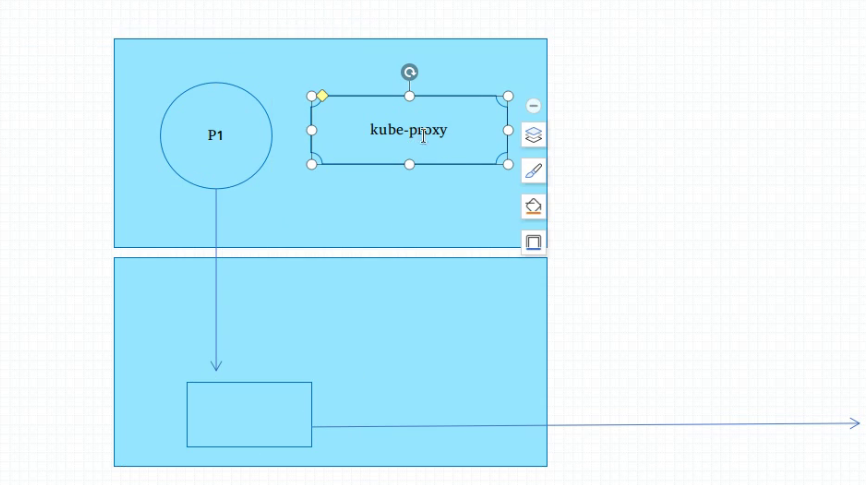
pod 发请求进入到内核空间之后,同样会被iptables 规则拦截 ,但是iptables 同时加了 调度规则,这个报文会直接发出去,不用再回kube-proxy
这里的kube-proxy 看起来没有用了? 错,它要监视着 apiserver 中 service 的定义 ,并且把它转化为本地的iptables 规则(userspace 模型也需要)。
因为纯内核级别 就能完成调度 ,所以比效率userspace 模型要好些,但是随着ep增多,会产生大量iptables规则
3、ipvs 模式。
对于ipvs 一个调度 ,只须一套规则。
- 定义集群
- 向集群添加 后端端点(rs ,real server).
所以区区2步骤ipvs规则就行 ,无论后端pod数量多少个 ,也不过是第二条规则的一个端点
使用kubeadm 部署时 ,会自动检测节点上的ipvs 相关模块是否被加载了,加载了就自动启用,否则就是iptables模式。当然也可以根据配置文件修改
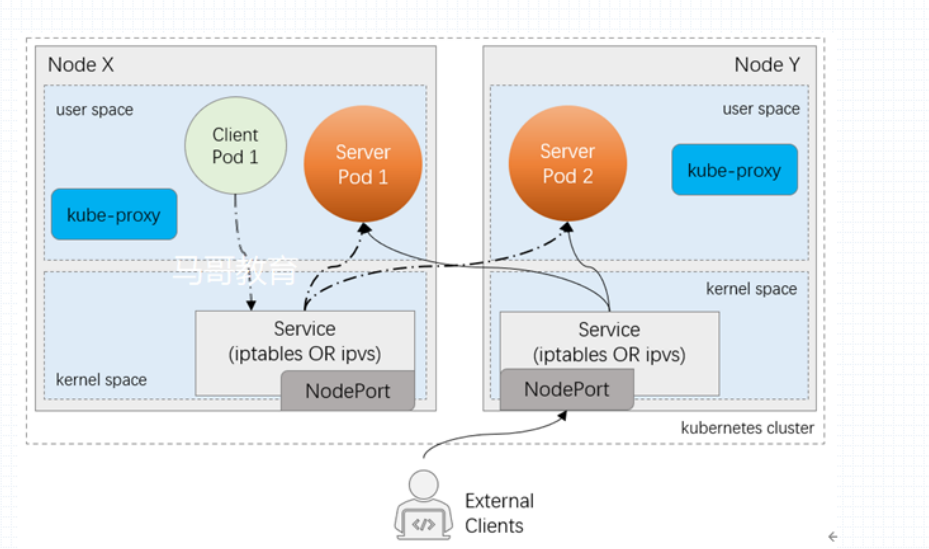
service 是定义在apiserver中的 , service controller 负责将其触发(其实主要是触发ep的)
kube-proxy 会注册监听着apiserver中的 所有service
任何一个serivce的添加 ,都会由每一个节点上的kube-proxy 把它加载到本地节点并且转换为内核中的iptables/ipvs 规则
任何一个一个节点上的iptables/ipvs 规则 通常 只负责本地节点上 pod 做为客户端发出请求时的过滤规则或者调度规则。 因此, client pod1 或者server pod1 去访问server pod2 时, 请求报文先到达本机内核空间,进而本iptables/ipvs 规则捕获 。iptables 规则一般在prerouting 链上,ipvs规则借助于prerouting 链上的iptables一两条(或几条)有限的规则 发送至INPUT 链上, 随后就被ipvs 所调度。
一旦创建了一个service , 为了让service 能接收请求且做为端点能被各种pod 所访问, service 会有一个不变的地址 clusterip( 前提不删除修改) ,从而能作为内部接入内部pod 请求的IP地址,因此把它称为cluserip
kube-proxy如何确保service能正常工作;
service 类型
ClusterIP:
通过集群内部IP地址暴露服务,但该地址仅在集群内部可见、可达,它无法被集群外部的客户端访问;默认类型;
一旦创建了一个service , 为了让service 能接收请求且做为端点能被各种pod 所访问, service 会有一个不变的地址 clusterip( 前提不删除修改) ,从而能作为内部接入内部pod 请求的IP地址,因此把它称为cluserip
NodePort:
NodePort是ClusterIP的增强类型,它会于ClusterIP的功能之外,在每个节点上使用一个相同的端口号将外部流量引入到该Service上来。然后service 转发到其他pod 上去
缺点就是 ,有可能 恰巧访问的那一台物理节点宕机了 ,就无法响应,所以需要创建一个外部的负载均衡器,LoadBlancer (external) ,把工作节点都加上去,负载均衡器是外部的,所以也要做高可用。
如果把k8s 部署在公有云上,公有云会有一种叫LBass的服务 ,叫软负载均衡器,可用调用云服务的api,它能自动帮你创建一个外部的 公有云本身提供的均衡器,有一定意义上的高可用性
LoadBalancer:
LB是NodePort的增强类型,要借助于底层IaaS云服务上的LBaaS产品来按需管理LoadBalancer。
ExternalName:
借助集群上KubeDNS来实现,服务的名称会被解析为一个CNAME记录,而CNAME名称会被DNS解析为集群外部的服务的IP地址; 这种Service既不会有ClusterIP,也不会有NodePort;















 5263
5263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









