







k8s_day_06_01
k8s 是一个应用编排系统,什么是编排?
因为非紧密关系中的应用关系各种各样,可能存在一定的依赖性,而且有先后关系,应用编排借助service 实现这种跨应用关系的管理。但是接下来关注的应用编排 集中应用管理本身
k8s 中有大量的应用 ,分为紧密关系和非紧密关系的应用,紧密关系的应用通过把它们放在一个pod 中管理 ,非紧密的应用关系通过service管理 让它们可以彼此互相调用。调用的时候需要提供服务总线 用于实现服务注册服务发现。注册的总线 是coredns 中的dns 服务,其他客户端借助coredns 发现别的service 就行了。
应用编排当中有一些核心任务, 比如:
- 部署: 在k8s 上所有的部署是 资源描述清单 部署的
- 扩展: 有2种扩展方式 。 向上扩和向外扩。 向上扩 scale-up 垂直扩展 是用更强性能、容量的服务器 承载,在pod就是改最大资源限制。而向外扩 ,在ks 上,指的是增加pod 数量
- 更新:
- 回滚
裸pod运行的方式 是没有扩展 更新 回滚 功能的
在k8s 上 ,有一种非常重要却不是核心群组的资源 控制器。控制器有很多种。几乎每种资源都有控制器,比如节点控制器, ns 有ns 控制器等等;专门用于编排以pod形式运行的应用,统称为pod 控制器
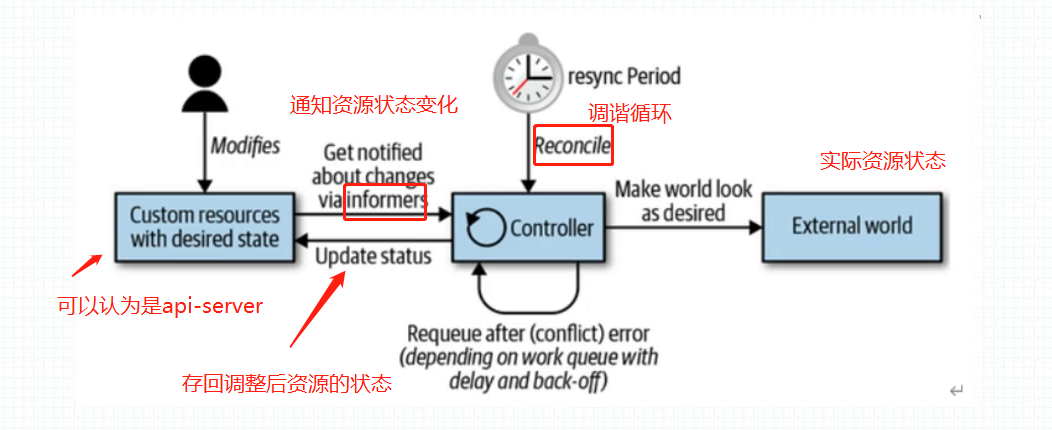
每一种控制器 只会监听和自己类型相关的资源变动,比如service 控制器只会监听service,pod 控制器只会监听pod. 一旦发生变动,控制器中会有一段代码, 定义在api 数据是用户的期望状态(spec 中定义的应该有的样子),用户定义完了数据之后,控制器会执行一段代码 使得在节点上创建出实体来 ,但是这个创建出的实体未必符合期望状态,比如可能因为某种原因没有运行起来等等, 实体的状态我们叫实际状态:status, 控制器 就是负责 实际状态和期望状态 相一致: controller 在创建完pod 后,pod 会把自己的status 状态字段存回apiserver ,status 字段是k8s内部维护的,不用自己定义。 controller 再读取status 内容与spec 相比较,如果不相同那么controller就会执行相应代码调整现在的pod 以趋同于spec 这是一个循环,调谐循环。 kubelet 也有对应的控制器,监视着节点上的所有pod , 一旦pod 状态发生改变 ,kubelet也会把pod 状态再存回apiserver 。所以,实际上来说,controller 和 kubelet是协同工作的 当然 ,service 控制器是 和kube-proxy 协同工作的。
调谐循环,也有人叫和解循环,就是让2个不一样的 变成一样的 control loop 也叫reconcile loop . ,默认5分钟一次,但是k8s 有着大量的资源,控制循环 会带来大量的请求 涌向 api-server ,所以 可以用主动通知的方式 告诉controller
pod 控制器 并不是 直接控制pod. 而是控制自己所创建的实体 间接控制。
假如握手rs 控制器 , 我会控制器所有rs 类型资源。
cm 中 有一段代码叫 rs的控制器代码, 就叫controller loop , controller loop 要想真正工作起来,得创建rs object, rs object 会向api server 请求管理符合 标签选择器matchLabels的pod 对象。 如何管理呢? 就是想apisever 查询 是否有指定数量 符合标签选择器的pod, 如果有就ok ,没有的话 就根据自己的模板向apiserver请求创建一个pod数据项, 而请求之后,期望创建的pod是否运行是由kubelet 负责的.
[由Scheduler调度并绑定至某节点 --> 由相应节点kubelet负责运行。]
控制循环/控制器 工作流程:
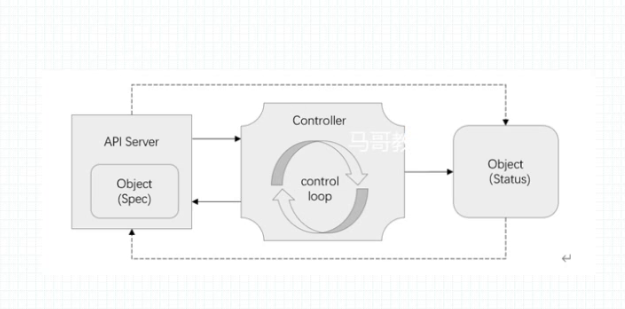
apiserver 在某种意义上说是一种特殊的db, 支持资源的监视和通知功能 watch 和notify(其实etcd 也支持)。apiserver 同时又把底层的存储模式schema做了 定义和限制 。 之前在etcd 上可以支持存放各种结构类型的kv 数据,类似redis 但是它比redis 支持更多类型的数据,比如json。 api 将etcd 的存储功能做了方案(schema),提供了固定的数据规范,这样只能存特定类型的数据了 ,k8s 中的各种资源类型就像是一种表,apiserver 支持客户都向里面存数据。
创建pod 时, 像是向pod 表插入了一行数据,但是它所对应的现实意义并不会立即发生,就是说并不会凭空产生一个一个处于期待运行状态的pod。是靠pod控制器调用kubelet , kubelet在节点生成对应的pod。
kubelet 选择在哪个节点是靠调度器。 但是 kubelet 只能维护单个pod的运行 ,如果想实现更高层级的容器编排,就得靠pod控制器建立在基础资源之上的更高级资源。
contoller 的作用是 客户都向api里面存数据所对应的实体 entity(现实意义)能发生: 把存放在api中的数据真真在在创建一个实体来。这个实体就叫做对象
在k8s中,对象有2种存在形式,一种是概念定义【api中的数据项】, 另一种是实体。 比如service的表现形式为service的资源规范定义 , 还有就是在节点表现出的ipvs/iptables规则. 哪个让k8s 的意义得以实现呢? 就是service 控制器 和kube-proxy 来负责。
k8s 上资源分成2类,一种是核心资源,处于core群组v1 版本的那个 ,还有一种就是基于核心资源之上的抽象出的更加高级类型扩展资源资源 也叫高级资源。
pod控制器类型
负责应用编排的控制器有如下几种:
- ReplicationController:最早期的Pod控制器;
- RelicaSet:副本集,负责管理一个应用(Pod)的多个副本;
- Deployment:部署,它不直接管理Pod,而是借助于ReplicaSet来管理Pod;最常用的无状态应用控制器;
- DaemonSet:守护进程集,用于确保在每个节点仅运行某个应用的一个Pod副本;
- StatefulSet:功能类似于Deployment,但StatefulSet专用于编排有状态应用;
- Job:有终止期限的一次性作业式任务,而非一直处于运行状态的服务进程;
- CronJob:有终止期限的周期性作业式任务;
控制器定义规范
pod控制器通用定义要素:
- 标签选择器;
- 期望的副本数;
- Pod模板;
1、Replicaset
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: …
namespace: …
spec:
minReadySeconds <integer> # Pod就绪后多少秒内,Pod任一容器无crash方可视为“就绪”, 因为pod内的就绪探针检测完成后仍然可能因为内部逻辑错误发生crash, 所以作用是多加了一层保护。如果不定义,则就绪探针检查是就绪那么就是就绪了
replicas <integer> # 期望的Pod副本数,默认为1
selector: # 标签选择器,必须匹配template字段中Pod模板中的标签;
matchExpressions <[]Object> # 标签选择器表达式列表,多个列表项之间为“与”关系
matchLabels <map[string]string> # map格式的标签选择器
template: # Pod模板对象
metadata: # Pod对象元数据
labels: # 由模板创建出的Pod对象所拥有的标签,必须要能够匹配前面定义的标签选择器
spec: # Pod规范,格式同自主式Pod
pod控制器使用的标签选择器 支持2种 matchExpressions 和 matchLabels。多个标签的关系表示有等值关系 和集合关系。 等值关系就用 matchLabels ,集合用matchExpressions 用于表示 in 和not in.
service 只支持等值关系标签选择器, matchLabels 作用类似
Service spec: selector: label1: value1 label2: value2
- pod控制器模板中就不用定义pod的 kind、vserion, 因为隐含的意义就包括在pod模板
[root@node01 chapter8]# cat replicaset-demo.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: replicaset-demo
spec:
minReadySeconds: 3
replicas: 2
selector:
matchLabels:
app: demoapp
release: stable
version: v1.0
template:
metadata:
labels:
app: demoapp
release: stable
version: v1.0
spec:
containers:
- name: demoapp
image: ikubernetes/demoapp:v1.0
ports:
- name: http
containerPort: 80
livenessProbe:
httpGet:
path: '/livez'
port: 80
initialDelaySeconds: 5
readinessProbe:
httpGet:
path: '/readyz'
port: 80
initialDelaySeconds: 15
注意 pod模板的 labels 一定大于控制器的matchlabels 否则将无限循环创建下去
模板中 只有 name 和 image 是必选字段,其他都是可选的
查看rs
[root@node01 chapter8]# kubectl get rs
NAME DESIRED CURRENT READY AGE
replicaset-demo 2 2 2 50m
DESIRED 表示期望的副本数
CURRENT 表示当前的副本数
READY 就绪的pod
-owide 可以 查看rs 内的容器
NAME DESIRED CURRENT READY AGE CONTAINERS IMAGES SELECTOR
replicaset-demo 2 2 1 95m demoapp ikubernetes/demoapp:v1.0 app=demoapp,release=stable,version=v1.0
[root@node01 chapter8]# kubectl describe rs/replicaset-demo
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 11m replicaset-controller Created pod: replicaset-demo-26d2v
Normal SuccessfulCreate 11m replicaset-controller Created pod: replicaset-demo-p82f9
[root@node01 chapter8]#
pod控制器创建的pod 与裸pod 的区别
控制器创建的pod 在metadata.ownerReferences 会有 pod 被哪个控制器 创建控制的信息
裸pod 没有
[root@node01 chapter7]# kubectl get po/replicaset-demo-lwf88 -o jsonpath={.metadata.ownerReferences}
[{"apiVersion":"apps/v1","blockOwnerDeletion":true,"controller":true,"kind":"ReplicaSet","name":"replicaset-demo","uid":"ef532fa3-e3cb-4a08-a00a-cbe932a59fa8"}]
[root@node01 chapter7]# kubectl get po/replicaset-demo-26d2v -o yaml
metadata:
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: replicaset-demo
uid: ef532fa3-e3cb-4a08-a00a-cbe932a59fa8
jsonpath 的使用
因为是该字段是列表可以用【*】 表示 ,默认不写就是这个
【0】.name 表示的是 第一项的name 字段
root@node01 chapter7]# kubectl get po/replicaset-demo-lwf88 -o jsonpath={.metadata.ownerReferences}
[{"apiVersion":"apps/v1","blockOwnerDeletion":true,"controller":true,"kind":"ReplicaSet","name":"replicaset-demo","uid":"ef532fa3-e3cb-4a08-a00a-cbe932a59fa8"}]
[root@node01 chapter7]# kubectl get po/replicaset-demo-lwf88 -o jsonpath={.metadata.ownerReferences[0]}
{"apiVersion":"apps/v1","blockOwnerDeletion":true,"controller":true,"kind":"ReplicaSet","name":"replicaset-demo","uid":"ef532fa3-e3cb-4a08-a00a-cbe932a59fa8"}[root@node01 chapter7]#
[root@node01 chapter7]# kubectl get po/replicaset-demo-lwf88 -o jsonpath={.metadata.ownerReferences[0].name}
replicaset-demo[root@node01 chapter7]#
ReplicaSet的更新机制
更新资源镜像
set image:更新应用版本,但对于replicaset来说,仅能更新API Server中的定义;
[root@node01 chapter8]# kubectl set image --help Possible resources include (case insensitive): pod (po), replicationcontroller (rc), deployment (deploy), daemonset (ds), statefulset (sts), cronjob (cj), replicaset (rs)
ReplicaSet的更新机制:
删除式更新:rs更新后,仅能更新API Server中的定义,不会立即更新当前的rs所管理的pod ,只有在创建删除老版本(现有的)Pod ,才会完成更新,删除多少旧的,才会创建多少新的
1、根据标签,单批次删除所有Pod,一次完成所有更新;服务会中断一段时间;
[root@node01 chapter8]# kubectl set image rs/replicaset-demo demoapp=ikubernetes/demoapp:v1.1
replicaset.apps/replicaset-demo image updated
[root@node01 chapter8]#
[root@node01 chapter7]# kubectl delete po -l app=demoapp,release=stable
pod "replicaset-demo-26d2v" deleted
pod "replicaset-demo-p82f9" deleted
2、分批次删除,待一批次就绪之后,才删除下一批;滚动更新;也就是灰度发布。
以上功能用deployment 控制器 更简单实现















 2269
2269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









