







本文纯属为了练习drdb以及iscsi两种SAN存储方式结合pacemaker的使用方法,不考虑生产环境中方案的必要性,将采用drbd做为apache网页文件后端存储,iscsi做为mysql后端存储,同时为了保证mysql数据安全性,iscsi共享的block设备为20G未分区磁盘*2组成的raid1镜像盘(软raid),此次实验raid未做热备,所以本次实验的整体架构为DRBD+apache and RAID+ISCSI+MySQL
RAID+ISCSI+MySQL
基础环境配置
环境:
3台centos7主机(iscsi,node1,node2)
主机node1 及node2 设置互信
主机iscsi 包含2块未格式化磁盘(本实验 /dev/sdb /dev/sdc)
主机node1 及node2各包含1块未格式化磁盘(本实验node1:/dev/sdb node2:/dev/sdb)
本文不探讨防火墙相关配置,所以需要关闭三台机器防火墙及selinuxISCSI server端配置(iscsi)
[root@iscsi ~]# yum -y install mdadm #不解释
[root@iscsi ~]# mdadm -C /dev/md1 -l1 -n2 /dev/sd{b,c} #创建/dev/md1
[root@iscsi ~]# yum -y install targetcli #依然不解释
[root@iscsi ~]# targetcli #创建磁盘,目标,绑定,设置相关参数
/> /backstores/block create mysql /dev/md1
/> /iscsi create iqn.2018-01.com.rm958:mysql
/> /iscsi/iqn.2018-01.com.rm958:mysql/tpg1/luns create /backstores/block/mysql
/> /iscsi/iqn.2018-01.com.rm958:mysql/tpg1/ set attribute cache_dynamic_acls=1
/> /iscsi/iqn.2018-01.com.rm958:mysql/tpg1/ set attribute demo_mode_write_protect=0
/> /iscsi/iqn.2018-01.com.rm958:mysql/tpg1/ set attribute generate_node_acls=1
/> saveconfigISCSI initiator 端配置(node1,node2)
[root@node1 ~]# iscsiadm -m discovery -t st -p 10.8.8.62 #发现设备
[root@node1 ~]# iscsiadm -m node -T iqn.2018-01.com.rm958:mysql -p 10.8.8.62:3260 -l #登录
以下操作为任一节点
[root@node1 ~]# mkfs.xfs /dev/sdc
[root@node1 ~]# mount /dev/sdc /var/lib/mysql
[root@node1 ~]# chown mysql. /var/lib/mysql #因mysql需要有读写权限,需更改目录属主及属组
[root@node1 ~]# systemctl start mariadb #初始化mysql,将初始文件写入iscsi共享盘符
[root@node1 ~]# systemctl stop mariadb
[root@node1 ~]# umount /var/lib/mysql
Pacemaker 配置(node1,node2)--mysql
准备工作
[root@node1 ~]# yum -y install pcs pacemaker fence-agents-all corosync #安装pacemaker所需软件
[root@node1 ~]# systemctl start pcsd;systemctl enable pcsd #启动及开机自启
[root@node2 ~]# echo 123 | passwd --stdin hacluster #为hacluster添加密码
以下命令在任一节点运行
[root@node2 ~]# pcs cluster auth node1 node2 #确认node1,node2通信状态
Username: hacluster
Password:
node1: Authorized
node2: Authorized
[root@node1 ~]# pcs cluster enable –all #设置集群自启动
[root@node1 ~]# pcs property set stonith-enabled=false #如果没有Fence,建议禁用STONITH
[root@node1 ~]# pcs property set no-quorum-policy=ignore #正常集群Quorum(法定)需要半数以上的票数,如果是双节点的集群
[root@node1 ~]# pcs resource defaults migration-threshold=1 #集群故障时候服务迁移
[root@node1 ~]# pcs resource defaults resource-stickiness=100 #在node1恢复后,为防止node2资源迁回node1
创建资源
[root@node1 ~]# pcs resource create mysqlvip IPaddr2 ip=10.8.8.100 cidr_netmask=24 op monitor interval=30s #创建IP资源
[root@node1 ~]# pcs cluster cib mysql.cfg #从主程序拉取resource配置文件
[root@node1 ~]# pcs -f mysql.cfg resource create mysqlfs Filesystem devide="/dev/sdc" directory="/var/lib/mysql" fstype="xfs" #在上一步拉取的配置文件中创建文件系统资源,用于挂载,
[root@node1 ~]# pcs -f mysql.cfg resource create mariadb systemd:mariadb \
binary="/usr/libexec/mysqld" config="/etc/my.cnf" datadir="/var/lib/mysql/" \
pid="/var/run/mariadb/mariadb.pid" socket="/var/lib/mysql/mysql.sock" op start timeout=180s op stop timeout=180s op monitor interval=20s timeout=60s –force #创建mariadb启动资源
[root@node1 ~]# pcs -f mysql.cfg constraint colocation add mariadb with mysqlfs INFINITY #设置依赖关系,文件系统需和mariadb service 运行在同一node
[root@node1 ~]# pcs -f mysql.cfg constraint order mysqlfs then mariadb #设置启动顺序
[root@node1 ~]# pcs cluster cib-push mysql.cfg #将配置推入主程序
[root@node1 ~]# pcs constraint colocation add mysqlfs with mysqlvip INFINITY #上一命令将资源配置文件推入主程序后发现vip和mariadb不在同一node上运行,故将mysqlvip 和 mysqlfs 也设置在同一node运行
至此,mysql运行正常,后面配置apache
DRBD+apache
DRBD复制模式(了解)
协议A:
异步复制协议。一旦本地磁盘写入已经完成,数据包已在发送队列中,则写被认为是完成的。在一个节点发生故障时,可能发生数据丢失,因为被写入到远程节点上的数据可能仍在发送队列。尽管,在故障转移节点上的数据是一致的,但没有及时更新。这通常是用于地理上分开的节点。
协议B:
内存同步(半同步)复制协议。一旦本地磁盘写入已完成且复制数据包达到了对等节点则认为写在主节点上被认为是完成的。数据丢失可能发生在参加的两个节点同时故障的情况下,因为在传输中的数据可能不会被提交到磁盘。
协议C:
同步复制协议。只有在本地和远程节点的磁盘已经确认了写操作完成,写才被认为完成。没有任何数据丢失,所以这是一个群集节点的流行模式,但I/O吞吐量依赖于网络带宽 。
准备工作
安装软件包(node1,node2)
# rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org #drbd密钥
# rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm #drbd repo源
yum -y install pcs pacemaker corosync fence-agents-all drbd84-utils kmod-drbd84 httpd
创建lvm,以便于后期对存储容量进行调整(node1,node2)
[root@node1 ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sr0 11:0 1 1024M 0 rom
vda 252:0 0 128T 0 disk
├─vda1 252:1 0 1M 0 part
├─vda2 252:2 0 512M 0 part /boot
└─vda3 252:3 0 128T 0 part
├─cl-root 253:0 0 128T 0 lvm /
└─cl-swap 253:1 0 4G 0 lvm [SWAP]
vdb 252:16 0 20G 0 disk
[root@node1 ~]# pvcreate /dev/vdb
Physical volume "/dev/vdb" successfully created.
[root@node1 ~]# vgcreate vgweb /dev/vdb
Volume group "vgweb" successfully created
[root@node1 ~]# lvcreate -L 5G -n lvweb vgweb
Logical volume "lvweb" created.
DRBD配置(node1,node2)
配置drbd全局配置文件
[root@node1 ~]# vim /etc/drbd.d/global_common.conf
global {
usage-count no; #设置是否参加DRBD使用统计
}
common {
protocol C; #设置DRBD同步协议
disk {
on-io-error detach; #设置I/O错误处理策略为分享
}
}
on-io-error 策略可能为以下选项之一(了解)
detach分离: 这是默认和推荐的选项,如果在节点上发生底层的硬盘I/O错误,它会将设备运行在Diskless无盘模式下。
pass_on: DRBD会将I/O错误报告到上层,在主节点上,它会将其报告给挂载的文件系统,但是在此节点上就往往忽略(因此此节点上没有可以报告的上层)
-local-in-error: 调用本地磁盘I/O处理程序定义的命令;这需要有相应的local-io-error调用的资源处理程序处理错误的命令
创建drbd资源 (注意主机名与IP对应)
[root@node1 ~]# cat /etc/drbd.d/web.res
resource web{
protocol C;
meta-disk internal;
device /dev/drbd1;
syncer{
verify-alg sha1;
}
net{
allow-two-primaries;
}
on node1{
disk /dev/vgweb/lvweb;
address 10.8.8.64:7789;
}
on node2{
disk /dev/vgweb/lvweb;
address 10.8.8.63:7789;
}
}
启用drbd
Node1:
[root@node1 drbd.d]# drbdadm create-md web #加载上一步创建的资源
[root@node1 drbd.d]# modprobe drbd #加载drdb模块
[root@node1 drbd.d]# drbdadm up web #将其上线
[root@node1 drbd.d]# drbdadm -- --force primary web #强制此node为主
Node2:
[root@node1 drbd.d]# drbdadm create-md web
[root@node1 drbd.d]# modprobe drbd
[root@node1 drbd.d]# drbdadm up web[root@node2 drbd.d]# drbdadm cstate web #连接状态
Connected
[root@node2 drbd.d]# drbdadm dstate web #数据同步状态
UpToDate/UpToDate
[root@node2 drbd.d]# drbdadm role web #角色
Secondary/Primary
格式化分区并写入测试网页(在primary端)
[root@node1 drbd.d]# mkfs.xfs /dev/drbd1
[root@node1 drbd.d]# mount /dev/drbd1 /mnt
[root@node1 drbd.d]# echo "test..." >/mnt/index.html
[root@node1 drbd.d]# chown apache. /var/www/html
[root@node1 drbd.d]# umount /mnt
Apache 配置
[root@node1 ~]# vim /etc/httpd/conf/httpd.conf #在末行加入此段内容
<location /server-status>
sethandler server-status
order deny,allow
deny from all
allow from 127.0.0.1
</location>
Pacemaker配置
因配置mysql时已创建集群,所以这里就直接用之前的集群了
[root@node1 ~]# pcs -f web.cfg resource create webvip IPaddr2 ip=10.8.8.200 cidr_netmask=24 op monitor interval=30s #VIP
[root@node1 ~]# pcs -f web.cfg resource create webdata ocf:linbit:drbd drbd_resource=web op monitor interval=60s
[root@node1 ~]# pcs -f web.cfg resource master webdataclone webdata master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true #DRDB克隆
[root@node1 ~]# pcs -f web.cfg resource create webfs Filesystem \
device="/dev/drbd1" directory="/var/www/html" fstype="xfs" #文件系统,挂载相关
[root@node1 ~]# pcs -f web.cfg constraint colocation add webfs with webdataclone INFINITY with-rsc-role=Master #告诉集群DRDB需和Filesystem运行在同一个节点上,并且DRDB角色为Master
[root@node1 ~]# pcs -f web.cfg constraint order promote webdataclone then start webfs #指定运行顺序,先执行DRDB,确认master之后再执行filesystem挂载
[root@node1 ~]# pcs -f web.cfg resource create websit apache configfile="/etc/httpd/conf/httpd.conf" statusurl=http://127.0.0.1/server-status # apache启动程序
[root@node1 ~]# pcs -f web.cfg constraint colocation add websit with webfs INFINITY # apache程序与文件系统依赖
[root@node1 ~]# pcs -f web.cfg constraint order webfs then websit # apache程序与文件系统执行顺序
[root@node1 ~]# pcs -f web.cfg constraint colocation add webvip with websit INFINITY # Web VIP与apache程序依赖
[root@node1 ~]# pcs -f web.cfg constraint colocation add websit with webfs INFINITY #告诉集群apache服务要和filesystem运行在同一节点
[root@node1 ~]# pcs -f web.cfg constraint order promote webfs then websit #指定运行顺序,先执行filesystem挂载,再执行apache服务
[root@node1 ~]# pcs cluster cib-push web.cfg #将配置文件推入cluster
[root@node2 drbd.d]# pcs constraint
Location Constraints:
Ordering Constraints:
start mysqlfs then start mariadb (kind:Mandatory)
promote webdataclone then start webfs (kind:Mandatory)
start webfs then start websit (kind:Mandatory)
Colocation Constraints:
mariadb with mysqlfs (score:INFINITY)
mysqlfs with mysqlvip (score:INFINITY)
webfs with webdataclone (score:INFINITY) (with-rsc-role:Master)
webvip with webfs (score:INFINITY)
websit with webfs (score:INFINITY)
验证
资源运行状况
资源正常运行在node1上
[root@node2 drbd.d]# pcs resource show
mysqlvip (ocf::heartbeat:IPaddr2): Started node1
mysqlfs (ocf::heartbeat:Filesystem): Started node1
mariadb (systemd:mariadb): Started node1
webvip (ocf::heartbeat:IPaddr2): Started node1
Master/Slave Set: webdataclone [webdata]
Masters: [ node1 ]
Slaves: [ node2 ]
webfs (ocf::heartbeat:Filesystem): Started node1
websit (ocf::heartbeat:apache): Started node1
将node1 standby
[root@node2 drbd.d]# pcs cluster standby node1资源正常运行在node2上
[root@node2 drbd.d]# pcs resource show
mysqlvip (ocf::heartbeat:IPaddr2): Started node2
mysqlfs (ocf::heartbeat:Filesystem): Started node2
mariadb (systemd:mariadb): Started node2
webvip (ocf::heartbeat:IPaddr2): Started node2
Master/Slave Set: webdataclone [webdata]
Masters: [ node2 ]
Stopped: [ node1 ]
webfs (ocf::heartbeat:Filesystem): Started node2
websit (ocf::heartbeat:apache): Started node2
服务可用性
web
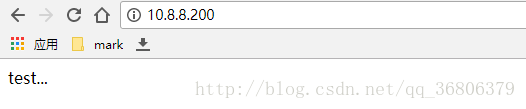
Mysql
在资源运行主机上
MariaDB [(none)]> grant all on *.* toroot@'%' identified by 'abc123';这里用iscsi server主机登录mysql测试















 126
126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









