






最近面试,发现sql题老是出问题这里复习一下sql集成,以mysql为例
mysql的连接方式
MySQL提供了多种连接数据库服务器的方式。 一旦我们安装了MySQL服务器,我们可以使用下面列出的任何客户端程序来连接它 :
- 命令行客户端
MySQL命令行客户端程序提供了交互和非交互模式下与数据库服务器进行交互的功能。我们可以在MySQL安装文件夹的 bin目录中看到这个程序 。我们可以通过导航到MySQL安装文件夹的bin目录并键入以下命令来打开MySQL命令提示符
#可以通过
#执行mysql 可以对本机或远程主机进行连接
#-u use身份
#-p password
#-h hostname 连接数据库的host地址 默认127.0.0.1
#-P port 连接端口 默认 3306
mysql -u root -p 123456 -h 127.0.0.1 -P 33062.MySQL Workbench或其他第三方连接客户端(Nativecat)
以Workbench为例
步骤 1 : 启动MySQL Workbench。我们应该看到以下屏幕:
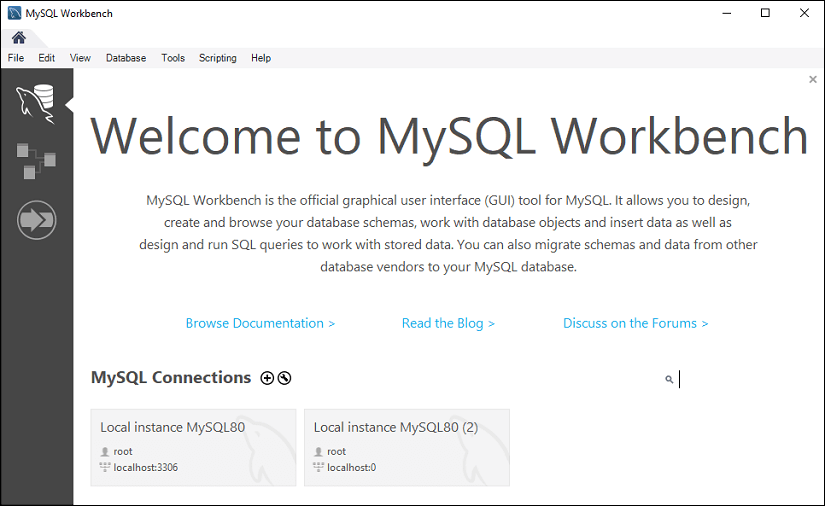
步骤2 :导航到菜单栏,点击 ‘数据库’ 并选择 连接到数据库 选项,或按下 CTRL+U 命令。我们还可以通过单击位于MySQL连接旁边的 加号 (+) 按钮 来连接数据库服务器。请参考下面的图像:
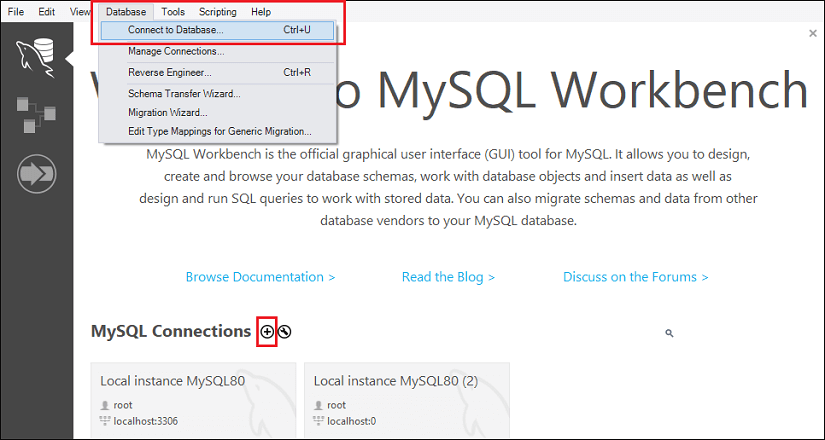
步骤3 :选择任何选项后,我们将获得以下屏幕:
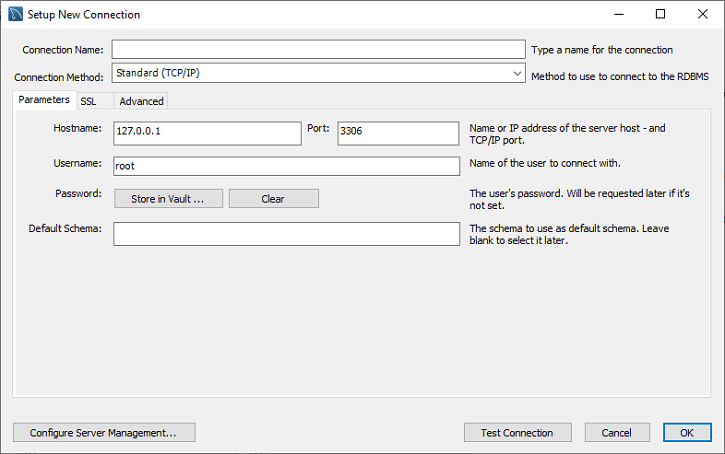
步骤 4: :填写框以创建连接,比如 连接名称 和 用户名 ,任意填写。默认情况下,用户名为 root ,但我们也可以在“用户名”文本框中使用不同的用户名进行更改。填写完所有框后,点击 Store in Vault …按钮 将密码写入给定用户账户中。
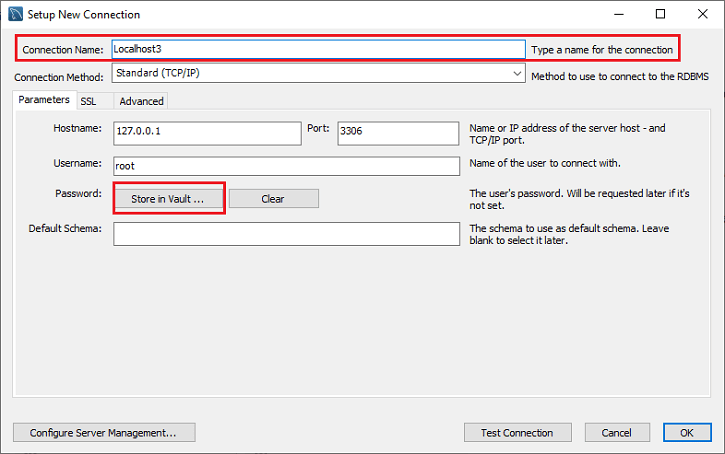
步骤5 : 我们将会得到一个新窗口用来输入密码,然后点击 确定 按钮。
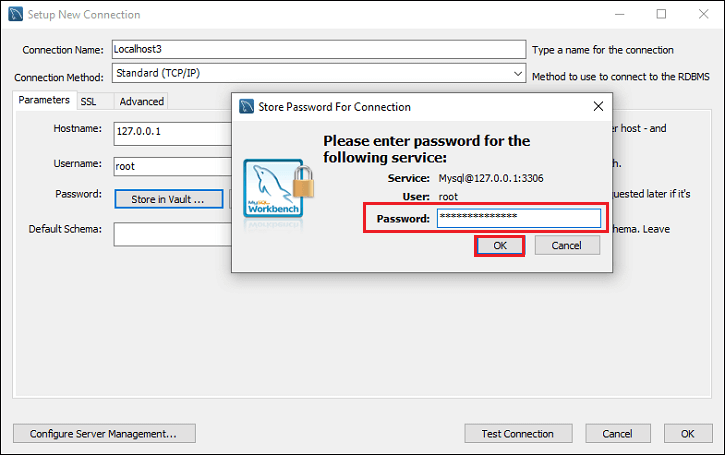
步骤6 :在输入完所有细节后,点击 测试连接 来测试数据库连接是否成功。如果连接成功,点击 确定 按钮。
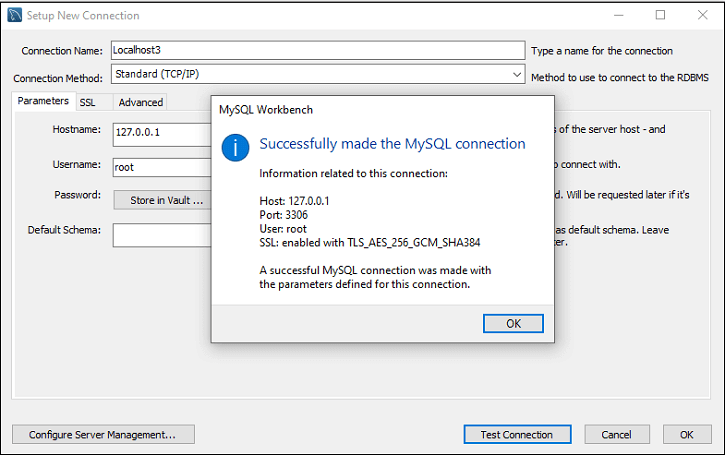
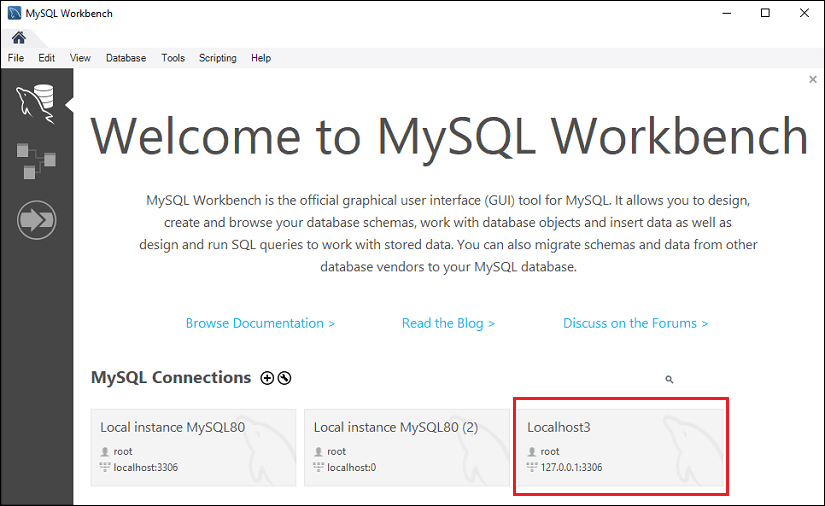
步骤 7 : 再次,点击 OK 按钮以保存连接设置。完成所有设置后,我们可以在 MySQL 连接 下看到此连接,以连接到 MySQL 数据库服务器。请查看下面的输出,其中我们有 Localhost3 连接名称:
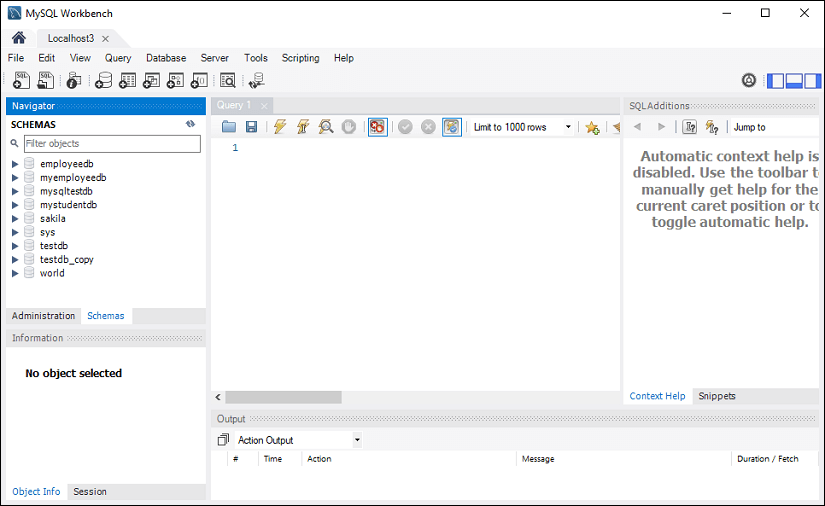
步骤 8 :现在,我们可以点击这个新创建的连接,显示当前的schemas以及一个输入查询的画板:
3. PHP脚本或其他编程语言
使用PHP脚本连接到MySQL数据库服务器的最简单方法是使用 mysql_connect()函数 。此函数需要 五个参数 ,并在连接成功时返回MySQL链接标识符。如果连接失败,则返回 FALSE 。
语法
使用PHP脚本进行MySQL连接的语法如下:
connection mysql_connect(server, user, passwordd, new_link, client_flag);SQL
Copy
让我们来解释一下mysql_connect()函数的参数:
服务器 :它是运行数据库服务器的主机名。默认情况下,其值将为lcalhost:3306。
用户 :它是访问数据库的用户的名称。如果我们不指定该字段,则默认值将是拥有服务器进程的用户的名称。
密码 :它是要访问其数据库的用户的密码。如果我们不指定该字段,则默认值将为空密码。
New_link :如果我们在mysql_connect()函数中进行第二次调用,并且参数相同,则MySQL不会建立新连接。相反,我们将获得已经打开的数据库连接的标识符。
Client_flags :该参数包含以下常量的组合:
- MYSQL_CLIENT_SSL:它使用SSL加密。
- MYSQL_CLIENT_COMPRESS:它使用压缩协议。
- MYSQL_CLIENT_IGNORE_SPACE:它在函数名后提供空格。
- MYSQL_CLIENT_INTERACTIVE:在关闭连接之前提供超时。
如果我们想要 断开与MySQL数据库服务器的连接 ,我们可以使用另一个名为 mysql_close() 的PHP函数。它只接受一个参数,该参数将是由mysql_connect()函数返回的连接。其语法如下:
bool mysql_close ( resource $link_identifier );SQL
Copy
如果我们没有指定任何资源,MySQL将关闭最后打开的数据库。当连接成功关闭时,该函数返回true。否则返回FALSE值。
示例
以下示例说明如何使用PHP脚本连接到MySQL服务器:
<html>
<head>
<title>MySQL Server Connection</title>
</head>
<body>
<?php
servername = 'localhost:3306';username = 'javatpoint';
dbpass = 'jtp123';conn = mysql_connect(servername,username, password); if(!conn ) {
die('Connection failed: ' . mysql_error());
}
echo 'Connection is successful';
mysql_close($conn);
?>
</body>
</html> sql数据类型
数值数据类型
MySQL具有所有必要的SQL数值数据类型。这些数据类型可以包括精确数值数据类型(例如整数、小数、数值等),以及近似数值数据类型(例如浮点数、实数和双精度)。它还支持BIT数据类型来存储位值。在MySQL中,数值数据类型分为两种类型,即有符号和无符号,除了位数据类型。
下表包含了所有在MySQL中支持的数值数据类型:
| 数据类型语法 | 描述 |
|---|---|
| TINYINT | 这是一个非常小的整数,可以有符号或无符号。如果是有符号的,允许的范围是-128到127。如果是无符号的,允许的范围是0到255。我们可以指定最多4位数的宽度。它需要1个字节来存储。 |
| SMALLINT | 这是一个小型整数,可以有符号或无符号。如果是有符号的,允许的范围是-32768到32767。如果是无符号的,允许的范围是0到65535。我们可以指定最多5位数的宽度。它需要2个字节来存储。 |
| MEDIUMINT | 这是一个中等大小的整数,可以有符号或无符号。如果是有符号的,允许的范围是-8388608到8388607。如果是无符号的,允许的范围是0到16777215。我们可以指定最多9位数的宽度。它需要3个字节来存储。 |
| INT | 这是一个正常大小的整数,可以有符号或无符号。如果是有符号的,允许的范围是-2147483648到2147483647。如果是无符号的,允许的范围是0到4294967295。我们可以指定最多11位数的宽度。它需要4个字节来存储。 |
| BIGINT | 这是一个大整数,可以有符号或无符号。如果是有符号的,允许的范围是-9223372036854775808到9223372036854775807。如果是无符号的,允许的范围是0到18446744073709551615。我们可以指定最多20位数的宽度。它需要8个字节来存储。 |
| FLOAT(m,d) | 这是一个浮点数,不能是无符号的。您可以定义显示长度(m)和小数位数(d)。这不是必需的,默认值为10,2,其中2是小数位数,10是总位数(包括小数位数)。浮点数的小数精度可以达到24位。它需要2个字节来存储。 |
| DOUBLE(m,d) | 这是双精度浮点数,不能是无符号的。您可以定义显示长度(m)和小数位数(d)。这不是必需的,默认值为16,4,其中4是小数位数。双精度浮点数的小数精度可以达到53位。Real是double的同义词。它需要8个字节来存储。 |
| DECIMAL(m,d) | 这是一个未打包的浮点数,不能是无符号的。在未打包的十进制数中,每个十进制数对应一个字节。定义显示长度(m)和小数位数(d)是必需的。Numeric是decimal的同义词。 |
| BIT(m) | 它用于将位值存储到表列中。这里,M确定每个值的位数,范围为1到64。 |
| BOOL | 它仅用于true和false条件。它将数值1视为true,将数值0视为false。 |
| BOOLEAN | 它类似于BOOL。 |
日期和时间数据类型:
这个数据类型用于表示日期、时间、日期时间、时间戳和年份等时间值。每种时间类型都包含值,包括零值。当我们插入无效的值时,MySQL无法表示它,然后使用零值。
下表列出了MySQL支持的所有日期和时间数据类型:
| 数据类型语法 | 最大大小 | 解释 |
|---|---|---|
| YEAR[(2|4)] | 年份可以是2位或4位数字。 | 默认为4位数字。需要占用1个字节的存储空间。 |
| DATE | 值范围从’1000-01-01’到’9999-12-31’。 | 显示格式为’yyyy-mm-dd’。需要占用3个字节的存储空间。 |
| TIME | 值范围从’-838:59:59’到’838:59:59’。 | 显示格式为’HH:MM:SS’。需要占用3个字节加上小数秒的存储空间。 |
| DATETIME | 值范围从’1000-01-01 00:00:00’到’9999-12-31 23:59:59’。 | 显示格式为’yyyy-mm-dd hh:mm:ss’。需要占用5个字节加上小数秒的存储空间。 |
| TIMESTAMP(m) | 值范围从’1970-01-01 00:00:01′ UTC到’2038-01-19 03:14:07′ TC。 | 显示格式为’YYYY-MM-DD HH:MM:SS’。需要占用4个字节加上小数秒的存储空间。 |
字符串数据类型:
字符串数据类型用于保存纯文本和二进制数据,例如文件、图片等。MySQL可以根据模式匹配(如LIKE操作符、正则表达式等)执行字符串值的搜索和比较。
下表列出了MySQL支持的所有字符串数据类型:
| 数据类型语法 | 最大大小 | 解释 |
|---|---|---|
| CHAR(size) | 最大长度为255个字符。 | 此处的size是要存储的字符数。定长字符串。右侧填充空格以使其等于大小字符。 |
| VARCHAR(size) | 最大长度为255个字符。 | 此处的size是要存储的字符数。可变长度字符串。 |
| TINYTEXT(size) | 最大长度为255个字符。 | 此处的size是要存储的字符数。 |
| TEXT(size) | 最大长度为65,535个字符。 | 此处的size是要存储的字符数。 |
| MEDIUMTEXT(size) | 最大长度为16,777,215个字符。 | 此处的size是要存储的字符数。 |
| LONGTEXT(size) | 最大长度为4GB或4,294,967,295个字符。 | 此处的size是要存储的字符数。 |
| BINARY(size) | 最大长度为255个字符。 | 此处的size是要存储的二进制字符数。定长字符串。右侧填充空格以使其等于大小字符。 (在MySQL 4.1.2中引入) |
| VARBINARY(size) | 最大长度为255个字符。 | 此处的size是要存储的字符数。可变长度字符串。 (在MySQL 4.1.2中引入) |
| ENUM | 占用1或2个字节,取决于枚举值的数量。ENUM最多可以有65,535个值。 | 它是枚举的缩写,意味着每列可以有指定的可能值之一。它使用数字索引(1, 2, 3……)来表示字符串值。 |
| SET | 占用1、2、3、4或8个字节,取决于集合成员的数量。最多可以存储64个成员。 | 它可以保存零个或多个,或任意数量的字符串值。它们必须从在创建表时指定的预定义值列表中选择。 |
二进制大对象数据类型(BLOB):
BLOB在MySQL中是一种可以容纳可变数量数据的数据类型。根据其可以容纳的值的最大长度,它们被分为四种不同类型。
下表显示了在MySQL中支持的所有二进制大对象数据类型:
| 数据类型语法 | 最大大小 |
|---|---|
| TINYBLOB | 可容纳最大255字节的数据。 |
| BLOB(size) | 可容纳最大65,535字节的数据。 |
| MEDIUMBLOB | 可容纳最大16,777,215字节的数据。 |
| LONGBLOB | 可容纳最大4gb或4,294,967,295字节的数据。 |
间数据类型是一种特殊的数据类型,用于存储各种几何和地理值。它对应于OpenGIS类。下表列出了在MySQL中支持的所有空间类型:
| 数据类型 | 描述 |
|---|---|
| GEOMETRY | 它是一个可以保存具有位置的任何类型的空间值的点或点的集合。 |
| POINT | 几何中的点表示一个单一位置。它存储了X、Y坐标的值。 |
| POLYGON | 它是表示多边几何形状的平面表面。它可以由零个或多个内部边界和仅有一个外部边界来定义。 |
| LINESTRING | 它是具有一个或多个点值的曲线。如果它只包含两个点,它总是表示一条线。 |
| GEOMETRYCOLLECTION | 它是一种具有零个或多个几何值的几何形状集合。 |
| MULTILINESTRING | 它是具有一组linestring值的多曲线几何。 |
| MULTIPOINT | 它是多个点元素的集合。在此,点不能以任何方式连接或排序。 |
| MULTIPLYGON | 它是表示多个多边形元素集合的多面对象。它是二维几何的一种类型。 |
sql变量
变量用于在程序执行期间存储数据或信息。它是一种使用适当名称标记数据的方式,有助于读者更清楚地理解程序。变量的主要目的是将数据存储在内存中,并可以在整个程序中使用。
MySQL可以以 三种不同的方式 使用变量,如下所示:
用户定义的变量
有时,我们希望从一个语句传递值到另一个语句。用户定义的变量使我们能够在一个语句中存储一个值,并在另一个语句中引用它。 MySQL提供了 SET 和 SELECT 语句来声明和初始化变量。用户定义的变量名以 @符号 开头。
用户定义的变量是不区分大小写的,例如@name和@NAME是相同的。一个人声明的用户定义变量对另一个人是不可见的。我们可以将用户定义的变量分配给整数、浮点数、小数、字符串或NULL等有限的数据类型。用户定义的变量的最大长度为 64个字符 。
语法
以下语法用于声明用户定义的变量。
#使用set
#注意:我们可以在SET语句中使用“=”或“:=”赋值运算符。
SET @var_name = value;
#使用select
SELECT @var_name := value;局部变量
它是一种不以@符号为前缀的变量类型。局部变量是强类型变量。局部变量的作用域在声明它的存储过程块中。MySQL使用DECLARE关键字指定局部变量。DECLARE语句还可以结合DEFAULT子句为变量提供默认值。如果不提供DEFAULT子句,变量将被赋予初始值NULL。它主要用于存储过程程序。
语法
DECLARE使用局部变量如下
DECLARE variable_name datatype(size) [DEFAULT default_value];
#eg
DECLARE total_price Oct(8,2) DEFAULT 0.0;
#我们还可以使用单个DECLARE语句定义两个或更多具有相同数据类型的变量。
DECLARE a,b,c INT DEFAULT 0;
#eg
DELIMITER //
Create Procedure Test()
BEGIN
DECLARE A INT DEFAULT 100;
DECLARE B INT;
DECLARE C INT;
DECLARE D INT;
SET B = 90;
SET C = 45;
SET D = A + B - C;
SELECT A, B, C, D;
END //
DELIMITER ;
#这里我们可以通过CALL查看你当前执行结果
mysql> CALL Test();
A B C D
100 90 45 145系统变量
系统变量是所有程序单元的特殊类,其中包含预定义的变量。MySQL包含各种配置其操作的系统变量,每个系统变量都有一个默认值。我们可以通过在运行时使用SET语句动态地更改某些系统变量,这使得我们能够在不停止和重新启动服务器的情况下修改其操作。系统变量也可以用于表达式中。
MySQL服务器提供了许多系统变量,如GLOBAL、SESSION或MIX类型。全局变量在服务器的整个生命周期中可见,而会话变量仅在特定会话中保持活动状态。
我们可以通过以下方式查看系统变量的名称和值:
要查看正在运行的服务器使用的当前值,请执行以下命令。
SHOW VARIABLES;
#OR
SELECT @@var_name;
SQL
#当我们想要查看基于其编译默认值的值时,请使用以下命令。
mysqld --verbose --help
#SQL
#示例1
SHOW VARIABLES LIKE '%wait_timeout%';
#示例2
SELECT @@key_buffer_size;MySQL 数据库数据库操作
MySQL 数据库创建
MySQL 将数据库实现为以表格形式存储的目录。主要有以下两种方式可以创建数据库:
- MySQL命令行客户端
CREATE DATABASE [IF NOT EXISTS] database_name
[CHARACTER SET charset_name]
[COLLATE collation_name];| 参数 | 描述 |
|---|---|
| database_name | 它是MySQL服务器实例中应该是唯一的新数据库的名称。当创建一个已经存在的数据库时, IF NOT EXIST 子句避免了错误。 |
| charset_name | 这是可选的。它是用于存储字符串中的每个字符的字符集的名称。MySQL数据库服务器支持许多字符集。如果在语句中未提供此项,则MySQL采用默认字符集。 |
| collation_name | 这是可选的,用于比较特定字符集中的字符。 |
介绍几个常用的有关于数据库的指令
#让我们通过一个例子来了解如何在MySQL中创建数据库。打开MySQL控制台,并写下安装过程中设置的密码。现在#我们准备好创建一个数据库了。在这里,我们将使用以下语句创建一个名为 “employeedb” 的数据库:
CREATE DATABASE employeesdb;
#我们将使用以下语句创建一个名为 “employeedb” 的数据库
CREATE DATABASE employeesdb;
#使用以下查询来查看新创建的数据库,该查询返回数据库的名称、字符集和排序规则:
SHOW CREATE DATABASE employeedb;
#查询来检查创建的数据库
SHOW DATABASES;
#选择数据库
USE customers;
MySQL 数据库删除
我们可以使用以下语法通过 DROP DATABASE 语句删除一个已存在的数据库:
在MySQL中,我们还可以使用以下语法来删除数据库。这是因为 模式 是数据库的同义词,所以我们可以互换使用它们。
DROP SCHEMA [IF EXISTS] database_name; | 参数 | 描述 |
|---|---|
| database_name | 这是我们想要从服务器删除的现有数据库的名称。在MySQL服务器实例中,它应该是唯一的。 |
| IF EXISTS | 这是可选的。它用于在删除不存在的数据库时防止出现错误。 |
MySQL 数据库复制
我们需要按照以下步骤将数据库复制到另一个数据库:
- 首先,使用 CREATE DATABASE 语句创建一个新数据库。
- 其次,将数据存储到一个 SQL文件 中。我们可以为此文件指定任何名称,但它的扩展名必须为 .sql 。
- 第三,使用 mysqldump 工具导出所有数据库对象以及其数据进行复制,然后将此文件导入新数据库
sql表操作
sql表的创建
表用于以行和列的形式组织数据,用于存储和显示结构格式中的记录,类似于电子表格应用程序中的工作表。创建表的命令需要 三个要素 :
- 表名
- 字段名
- 每个字段的定义
这里我们以ySQL命令行客户端为例介绍如何进行表的创建
#这里是一般创建表的语句
#[tempority] 是否为临时表,只存在于当前会话
#[IF NOT EXISTS] 查看表当前是否存,若存在执行创建操作
CREATE [tempority] TABLE [IF NOT EXISTS] table_name(
column_definition1,
column_definition2,
........,
table_constraints
);
#eg 这里我们创建了一个 名为employee_table的表
#其中 id 是INT类型 为主键并自增
#name 是varchar类型
#
CREATE TABLE employee_table(
id int NOT NULL AUTO_INCREMENT,
name varchar(45) NOT NULL,
occupation varchar(35) NOT NULL,
age int NOT NULL,
PRIMARY KEY (id)
);参数说明
上述语法的参数说明如下:
| 参数 | 描述 |
|---|---|
| database_name | 这是一个新表的名称。在所选的MySQL数据库中应该是唯一的。 如果不存在 子句避免在创建一个已存在的表时出现错误。 |
| column_definition | 它指定了每个列的列名和数据类型。表定义中的列使用逗号运算符分隔。列定义的语法如下: 列名1 数据类型(大小) [NULL | NOT NULL] |
| table_constraints | 它指定表的约束条件,如主键、唯一键、外键、检查等。 |
唯一键
在MySQL中,唯一键是一个字段或多个字段的组合,确保所有要存储到该列中的值都是唯一的。这意味着该列不能存储 重复值 。例如,在”student_info”表中的学生的电子邮件地址和学号,或在”Employee”表中的员工联系电话应该是唯一的。
MySQL允许我们在一个表中使用多个带有唯一约束的列。它可以接受一个 空值 ,但MySQL只允许每个列中有一个空值。它确保了列或一组列的 完整性 ,以便将不同的值存储到表中。
唯一键的需求
- 它有助于防止将相同的值存储到列中的两条记录。
- 它只存储不重复的值,以保持数据库的完整性和可靠性,以便以有组织的方式访问信息。
- 它还可以与外键一起工作,以保持表的唯一性。
- 它可以在表中包含空值。
创建方式
#单列创建
CREATE TABLE table_name(
col1 datatype,
col2 datatype UNIQUE,
...
);
#多列创建
CREATE TABLE table_name(
col1 col_definition,
col2 col_definition,
...
[CONSTRAINT constraint_name]
UNIQUE(column_name(s))
);
#table_name 这是我们要创建的表的名称。
#col1, col2 这是表中包含的列名。
#constraint_name 这是唯一键的名称。
#column_name(s) 这是将成为唯一键的列名
#创建唯一键
ALTER TABLE table_name ADD CONSTRAINT constraint_name UNIQUE(column_list);
#删除唯一键
ALTER TABLE table_name DROP INDEX constraint_name;
主键
MySQL主键是一个用于标识表中每条记录的单个或组合字段。 唯一地 。如果列包含主键约束,则不能为 null或空 。一个表可以有重复的列,但只能包含一个主键。它始终包含一个唯一值。
当您向表中插入新行时,主键列也可以使用 AUTO_INCREMENT 属性为该行自动生成连续的编号。 MySQL 在为表定义主键后自动创建一个名为“ Primary ”的索引。由于它有一个关联的索引,我们可以说主键使查询性能快。
主键规则
主键的规则如下:
- 主键列的值必须是唯一的。
- 每个表只能包含一个主键。
- 主键列不能为null或空。
- MySQL不允许我们使用现有的主键插入新行。
- 建议为主键列使用INT或BIGINT数据类型
我们可以通过两种方式创建主键:
- CREATE TABLE语句
CREATE TABLE table_name(
col1 datatype PRIMARY KEY,
col2 datatype,
...
);- ALTER TABLE语句
语法
以下是在MySQL中使用ALTER TABLE语句创建主键的语法:
#创建主键
ALTER TABLE table_name ADD PRIMARY KEY(column_list);、
#删除主键
ALTER TABLE table_name DROP PRIMARY KEY;
| 序号 | 主键 | 唯一键 |
|---|---|---|
| 1. | 它是一个字段或字段的组合,用于唯一标识表中的每条记录。 | 在没有主键的情况下,它也可以唯一地确定表中的每一行。 |
| 2. | 它不允许将NULL值存储到主键列中。 | 它只能接受一个NULL值到唯一键列中。 |
| 3. | 一个表只能有一个主键。 | 一个表可以有多个唯一键。 |
| 4. | 它创建一个聚集索引。 | 它创建一个非聚集索引。 |
外键
外键用于将一个或多个表链接在一起。它也被称为参考键。外键与另一个表的主键字段匹配。这意味着一个表中的外键字段指向另一个表的主键字段。它唯一地标识了另一个表的每一行,从而在MySQL中保持了引用完整性。
外键使得在表之间创建父子关系成为可能。在这种关系中,父表保存初始列值,子表的列值引用父表的列值。MySQL允许我们在子表上定义外键约束
MySQL 以两种方式定义外键:
- 使用CREATE TABLE语句
语法
以下是在MySQL中使用CREATE TABLE或ALTER TABLE语句定义外键的基本语法:
[CONSTRAINT constraint_name]
FOREIGN KEY [foreign_key_name] (col_name, ...)
REFERENCES parent_tbl_name (col_name,...)
ON DELETE referenceOption
ON UPDATE referenceOption
#eg
#主表
CREATE TABLE customer (
ID INT NOT NULL AUTO_INCREMENT,
Name varchar(50) NOT NULL,
City varchar(50) NOT NULL,
PRIMARY KEY (ID)
);
#关联表
CREATE TABLE contact (
ID INT,
Customer_Id INT,
Customer_Info varchar(50) NOT NULL,
Type varchar(50) NOT NULL,
INDEX par_ind (Customer_Id),
CONSTRAINT fk_customer FOREIGN KEY (Customer_Id)
REFERENCES customer(ID)
ON DELETE CASCADE
ON UPDATE CASCADE
);
在上面的语法中,我们可以看到以下参数:
constraint_name: 它指定了外键约束的名称。如果我们没有提供约束名,则MySQL会自动生成名称。
col_name: 它是我们要创建外键的列的名称。
parent_tbl_name: 它指定了父表的名称,后面跟着引用外键列的列名。
Refrence_option: 它用于确保外键在父表和子表之间使用ON DELETE和ON UPDATE子句维护引用完整性。
MySQL包含了 五个 不同的引用选项,如下所示:
CASCADE: 当我们从父表中删除或更新任何行时,子表中匹配行的值将自动删除或更新。
SET NULL: 当我们从父表中删除或更新任何行时,子表中外键列的值将设置为NULL。
RESTRICT: 当我们从父表中删除或更新任何具有匹配行的行时,MySQL不允许删除或更新父表中的行。
NO ACTION: 它类似于RESTRICT。但是它有一个区别,即在尝试修改表后会检查引用完整性。
SET DEFAULT: MySQL解析器识别此操作。但是,InnoDB和NDB表都不接受此操作
注意:MySQL主要对CASCADE、RESTRICT和SET NULL操作提供完全支持。如果我们没有指定ON DELETE和ON UPDATE子句,MySQL会采取默认的RESTRICT操作。
2.使用ALTER TABLE语句
#添加外键
ALTER TABLE table_name
ADD [CONSTRAINT [symbol]] FOREIGN KEY
[index_name] (column_name, ...)
REFERENCES table_name (column_name,...)
ON DELETE referenceOption
ON UPDATE referenceOption
#删除外键
ALTER TABLE table_name DROP FOREIGN KEY fk_constraint_name;
#主表
CREATE TABLE Person (
ID INT NOT NULL AUTO_INCREMENT,
Name varchar(50) NOT NULL,
City varchar(50) NOT NULL,
PRIMARY KEY (ID)
);
#外表
CREATE TABLE Contact (
ID INT,
Person_Id INT,
Info varchar(50) NOT NULL,
Type varchar(50) NOT NULL
);
#创建
ALTER TABLE Contact ADD INDEX par_ind ( Person_Id );
ALTER TABLE Contact ADD CONSTRAINT fk_person
FOREIGN KEY ( Person_Id ) REFERENCES Person ( ID ) ON DELETE CASCADE ON UPDATE RESTRICT;外键检查
MySQL有一个特殊的变量 foreign_key_cheks 用于控制对表中的外键进行检查。默认情况下,在对表进行常规操作期间,它会启用以确保引用完整性。这个变量是动态的,因此支持全局和会话范围。
有时需要禁用外键检查,这在以下情况下非常有用:
- 我们删除被外键引用的表。
- 我们从CSV文件导入数据到表中。这加快了导入操作的速度。
- 我们在具有外键的表上使用ALTER TABLE语句。
- 我们可以以任何顺序执行将数据加载到表中的操作,以避免外键检查。
以下语句允许我们 禁用 外键检查:
SET foreign_key_checks = 0;
SQL
Copy
以下语句允许我们 启用 外键检查:
SET foreign_key_checks = 1;查看表是否创建可以在当前数据库执行
#查看当前数据库下所有的表
SHOW TABLES;查看当前表结构可以使用
#查看当前表的结构信息
DESCRIBE employee_table;SQL编辑表
增加列
#table_name 对应表名
#new_column_name 新列名
#column_definition 列定义
# FIRST | AFTER column_name: 这是可选的。它告诉MySQL在表中的哪个位置创建该列。如果未指定此参数,新列将添加到表的末尾。
ALTER TABLE table_name
ADD new_column_name column_definition
[ FIRST | AFTER column_name ];
#通过这种方式可以增加多个列
ALTER TABLE 表名
ADD 新列名 列定义
[ FIRST | AFTER 列名 ],
ADD 新列名 列定义
[ FIRST | AFTER 列名 ],
...
;
#修改对应列的属性
ALTER TABLE cus_tbl
MODIFY cus_surname varchar(50) NULL;
#删除对应列
ALTER TABLE 表名
DROP COLUMN 列名;
#列重命名
ALTER TABLE 表名
CHANGE COLUMN 旧列名 新列名
列定义
[ FIRST | AFTER 列名 ]
#重命名表
ALTER TABLE 表名
RENAME TO 新表名;SQL表插入信息
MySQL插入语句用于在数据库中的MySQL表中存储或添加数据。我们可以使用单个查询以两种方式插入记录:
- 在单个行中插入记录
#注意:字段名是可选的。如果我们想指定部分值,则字段名是必需的。它还确保列名和值应该是相同的。此外,列和对应的值的位置必须相同。
INSERT INTO table_name ( field1, field2,...fieldN )
VALUES
( value1, value2,...valueN );
#eg
CREATE TABLE People(
id int NOT NULL AUTO_INCREMENT,
name varchar(45) NOT NULL,
occupation varchar(35) NOT NULL,
age int,
PRIMARY KEY (id)
);
#插入数据
INSERT INTO People (id, name, occupation, age)
VALUES (101, 'Peter', 'Engineer', 32);2.在多个行中插入记录
INSERT INTO table_name VALUES
( value1, value2,...valueN )
( value1, value2,...valueN )
...........
( value1, value2,...valueN );
#eg
CREATE TABLE People(
id int NOT NULL AUTO_INCREMENT,
name varchar(45) NOT NULL,
occupation varchar(35) NOT NULL,
age int,
PRIMARY KEY (id)
);
#插入多条信息
INSERT INTO People VALUES
(102, 'Joseph', 'Developer', 30),
(103, 'Mike', 'Leader', 28),
(104, 'Stephen', 'Scientist', 45);如果插入的值是时间类型
我们也可以使用INSERT STATEMENT将日期添加到MySQL表中。MySQL提供了多种数据类型以存储日期,如DATE、TIMESTAMP、DATETIME和YEAR。MySQL中日期的默认格式为YYYY-MM-DD。
此格式具有以下描述:
- YYYY: 表示四位数年份,如2020年。
- MM: 表示两位数月份,如01、02、03和12。
- DD: 表示两位数日期,如01、02、03和31。
以下是在MySQL表中插入日期的基本语法:
INSERT INTO table_name (column_name, column_date) VALUES ('DATE: Manual Date', '2008-7-04'); 如果我们想要在mm/dd/yyyy格式中插入日期,则需要使用下面的语句:
INSERT INTO table_name VALUES (STR_TO_DATE(date_value, format_specifier));SQL表查询信息
MySQL 中的 SELECT 语句用于从一个或多个表中获取数据。 我们可以使用这个语句检索所有字段或指定的字段,并匹配指定的条件。
#
SELECT field_name1, field_name 2,... field_nameN
FROM table_name1, table_name2...
[WHERE condition]
[GROUP BY field_name(s)]
[HAVING condition]
[ORDER BY field_name(s)]
[OFFSET M ][LIMIT N];| 参数名称 | 描述 |
|---|---|
| field_name(s) 或 * | 用于指定要在结果集中返回的一个或多个列。* 返回表的所有字段。 |
| table_name(s) | 我们希望提取数据的表的名称。 |
| WHERE | 可选语句。它指定了在结果集中返回匹配记录的条件。 |
| GROUP BY | 可选语句。它从多个记录中收集数据,并按一个或多个列进行分组。 |
| HAVING | 可选语句。它与 GROUP BY 子句配合使用,仅返回满足条件的行。 |
| ORDER BY | 可选语句。用于对结果集中的记录进行排序。 |
| OFFSET | 可选语句。指定从哪一行开始返回。默认情况下,从零开始。 |
| LIMIT | 可选语句。用于限制返回的记录数。 |
MySQL DISTINCT 子句用于从表中删除重复的记录,并仅获取唯一的记录。DISTINCT 子句仅与 SELECT 语句一起使用。
SELECT DISTINCT expressions
FROM tables
[WHERE conditions];
#eg 单条件
SELECT DISTINCT address
FROM officers;
#eg 多条件
SELECT DISTINCT officer_name, address
FROM officers;参数
expressions: 指定要检索的列或计算。
tables: 指定从中检索记录的表的名称。在FROM子句中必须至少列出一个表。
WHERE条件: 这是可选的。它指定必须满足的记录选择条件。
注意:
- 如果您在DISTINCT子句中只放置一个表达式,则查询将返回该表达式的唯一值。
- 如果您在DISTINCT子句中放置多个表达式,则查询将检索列出的表达式的唯一组合。
- 在MySQL中,DISTINCT子句不会忽略NULL值。因此,如果您在SQL语句中使用DISTINCT子句,则结果集将包括NULL作为一个不同的值。
MYSQL ORDER BY 子句用于按升序或降序对记录进行排序。
语法:
SELECT expressions
FROM tables
[WHERE conditions]
ORDER BY expression [ ASC | DESC ];
参数
表达式: 它指定您想要检索的列。
表: 它指定您想要检索记录的表。FROM子句中必须至少列出一个表。
WHERE条件: 这是可选项。它指定必须满足的条件,以选择记录。
ASC: 这是可选项。它按表达式的升序对结果集进行排序(如果没有提供修饰符,则为默认值)。
DESC: 这也是可选项。它按表达式的降序对结果集进行排序。
注意:您可以在SELECT语句、SELECT LIMIT语句和DELETE LIMIT语句中使用MySQL的ORDER BY子句。
这里我们对后三种子句单独介绍下
MySQL WHERE子句
MySQL WHERE子句用于SELECT、INSERT、UPDATE和DELETE语句中对结果进行过滤。它指定了您必须执行操作的特定位
where可以跟AND和OR对筛选调整需要查询的范围
#单where
#AND配合where
SELECT *
FROM officers
WHERE address = 'Lucknow'
AND officer_id < 5;
#OR配合where
SELECT *
FROM officers
WHERE address = 'Lucknow'
OR address = 'Mau';
#AND 和OR 配合where
SELECT *
FROM officers
WHERE (address = 'Mau' AND officer_name = 'Ajeet')
OR (officer_id < 5);MySQL FROM 子句
MySQL FROM 子句用于从表中选择一些记录。它也可以使用 JOIN 条件从多个表中检索记录。
语法:
#from在多表联合时需要与使用INNER JOIN 、LEFT [OUTER] JOIN等子句
FROM table1
[ { INNER JOIN | LEFT [OUTER] JOIN| RIGHT [OUTER] JOIN } table2
ON table1.column1 = table2.column1 ]
#eg从单表中获取信息
SELECT *
FROM officers
WHERE officer_id <= 3;
#eg多表前置
#students scores 外键为id ,
#students 表中,id 4 不在 scores 中
#students 表中,id 6 不在 scores 中
CREATE TABLE students (
id INT,
name VARCHAR(50)
);
INSERT INTO students (id,name) VALUES (1,"Tom");
INSERT INTO students (id,name) VALUES (2,"Alice");
INSERT INTO students (id,name) VALUES (3,"Sam");
INSERT INTO students (id,name) VALUES (4,"Sam");
CREATE TABLE scores (
id INT,
math INT,
chinese INT,
english INT
);
INSERT INTO scores (id,math,chinese,english) VALUES (1, 60,80,70);
INSERT INTO scores (id,math,chinese,english) VALUES (2, 90 ,60 ,100);
INSERT INTO scores (id,math,chinese,english) VALUES (3, 70 ,60 ,75);
INSERT INTO scores (id,math,chinese,english) VALUES (5, 70 ,60 ,75);
#通过内联获取信息INNER JOIN 只会显示符合on 后条件的列信息
select s.name, sc.math, sc.chinese, sc.english from students s inner join scores sc on s.id = sc.id;
#得到
#name math chinese english
#Tom 60 80 70
#Alice 90 60 100
#Sam 70 60 75
#通过外联获取信息right/left FULL JOIN 只会显示符合on 后条件的列信息
select s.name, sc.math, sc.chinese, sc.english from students s left join scores sc on s.id = sc.id;
#得到,左联,显示左表(from后的表)的所有数据,若此数据不存在与右表(join后的表)中对应列为null
#name math chinese english
#Tom 60 80 70
#Alice 90 60 100
#Sam 70 60 75
#Sam null null null
select s.name, sc.math, sc.chinese, sc.english from students s right join scores sc on s.id = sc.id;
#得到,右联,显示右表(from后的表)的所有数据,若此数据不存在与左表(join后的表)中对应列为null
#name math chinese english
#Tom 60 80 70
#Alice 90 60 100
#Sam 70 60 75
#Sam null null null
MySQL GROUP BY子句
MYSQL GROUP BY子句用于从多条记录中收集数据,并通过一个或多个列对结果进行分组。它通常用于SELECT语句中。
您还可以在分组列上使用一些聚合函数,如COUNT,SUM,MIN,MAX,AVG等。
语法:
SELECT expression1, expression2, ... expression_n,
aggregate_function (expression)
FROM tables
[WHERE conditions]
GROUP BY expression1, expression2, ... expression_n
HAVING condition;
#获取address项的出现次数
SELECT address, COUNT(*)
FROM officers
GROUP BY address;
#获取每个员工的工作总时间
SELECT emp_name, SUM(working_hours) AS "Total working hours"
FROM employees
GROUP BY emp_name;
#获取每个员工的最少工作时间
SELECT emp_name, MIN(working_hours) AS "Minimum working hour"
FROM employees
GROUP BY emp_name;
#获取每个员工的最多工作时间
SELECT emp_name, MAX (working_hours) AS "Minimum working hour"
FROM employees
GROUP BY emp_name;
#获取每个员工的平均工作时间
SELECT emp_name, MAX (working_hours) AS "Minimum working hour"
FROM employees
GROUP BY emp_name;参数
aggregate_function: 它指定了SUM、COUNT、MIN、MAX或AVG中的任何一个聚合函数。
expression1, expression2, … expression_n: 它指定了不包含在聚合函数内的表达式,并且必须包含在GROUP BY子句中。
WHERE conditions: 这是可选的。它指定了选择记录的条件。
HAVING condition: 它用于限制返回的行组。它只显示那些条件为TRUE的组在结果集中。
MySQL HAVING子句与GROUP BY子句一起使用。它总是返回条件为TRUE的行。
SELECT expression1, expression2, ... expression_n,
aggregate_function (expression)
FROM tables
[WHERE conditions]
GROUP BY expression1, expression2, ... expression_n
HAVING condition;MySQL LIKE条件
在MySQL中,LIKE条件用于执行模式匹配以找到正确的结果。它与WHERE子句的组合一起在SELECT、INSERT、UPDATE和DELETE语句中使用。
语法:
expression LIKE pattern [ ESCAPE 'escape_character' ]
#officer_id officer_name address
# 1 Ajeet Mau
# 2 Deepika Lucknow
# 3 Rahul Lucknow
# 使用%(百分比)通配符
SELECT officer_name
FROM officers
WHERE address LIKE 'Luck%';
# officer_name
# Deepika
# Rahul
# 使用_(下划线)通配符
SELECT officer_name
FROM officers
WHERE address LIKE 'Luc_now';
# officer_name
# Deepika
# Rahul
#使用NOT运算符:
SELECT officer_name
FROM officers
WHERE address NOT LIKE 'Luck%';
# officer_name
# Ajeet
参数
表达式: 它指定一个列或字段。
模式: 它是一个包含模式匹配的字符表达式。
转义字符: 它是可选的。它允许您测试通配符字符(如%或_)的字面实例。如果您不提供转义字符, MySQL 假设”\”是转义字符
MySQL 更新查询
MySQL UPDATE查询是一种数据操作语言语句,用于修改数据库中的MySQL表的数据。在现实生活中,记录会随着时间的推移而发生变化。因此,我们需要对表格的值进行更改。为此,需要使用UPDATE查询。
UPDATE语句与SET和WHERE子句一起使用。SET子句用于更改指定列的值。我们可以同时更新单个或多个列。
语法
以下是用于将数据修改为MySQL表的UPDATE命令的通用语法:
UPDATE table_name
SET column_name1 = new-value1,
column_name2=new-value2, ...
[WHERE Clause]
参数解释
下面给出了UPDATE语句语法中使用的参数的描述:
| 参数 | 描述 |
|---|---|
| table_name | 要执行更新操作的表的名称。 |
| column_name | 要使用SET子句将新值更新到的列的名称。如果需要更新多列,请使用逗号分隔符将列指定为每列的值。 |
| WHERE子句 | 可选的。用于指定要执行更新操作的行的名称。如果省略此子句,MySQL将更新所有行。 |
注意:
- 此语句一次只能更新一个表中的值。
- 使用此语句可以同时更新单个或多个列。
- 可以使用WHERE子句来指定任何条件。
- WHERE子句非常重要,因为有时我们只想更新一行,如果省略此子句,它会意外地更新表中的所有行。
UPDATE命令在MySQL中支持以下修饰符:
LOW_PRIORITY: 此修饰符指示语句延迟执行UPDATE命令,直到没有其他从表中读取数据的客户端。它仅对使用表级锁定的存储引擎有效。
IGNORE: 此修饰符允许语句在发生错误时不中止执行。如果发现重复键冲突,则不会更新行。
SQL删除信息
MySQL DELETE语句用于从MySQL表中删除不再需要的记录。 这个MySQL查询从表中删除一整行,并生成删除行数的计数。 它还允许我们在单个查询中删除表中的多条记录,这在删除大量记录时非常有用。通过使用delete语句,我们还可以根据条件删除数据。
使用这个查询删除记录后,我们将无法恢复它。 因此,在从表中删除任何记录之前,建议您 创建数据库的备份。 数据库备份允许我们在将来需要时恢复数据
语法:
#limit限制删除行,利用order by子句进行排序
DELETE FROM table_name
WHERE condition
ORDER BY colm1, colm2, ...
LIMIT row_count;ps:完全删除一个表的数据
#https://deepinout.com/mysql/mysql-top-articles/3_j_delete-all-data-from-table-mysql.html
TRUNCATE TABLE table_name;
#
delete TABLE table_name;
#
drop TABLE table_name;索引
索引是一种允许我们在现有表中添加索引的数据结构。它能够提高对数据库表上记录的快速检索。它为索引列的每个值创建一个 条目 。我们使用它在访问表时快速找到记录,而不是搜索数据库表中的每一行。我们可以通过使用表的一个或多个 列 来创建索引,以便有效地访问记录。
当创建带有主键或唯一键的表时,它会自动创建一个名为 PRIMARY 的特殊索引。我们将这个索引称为聚集索引。除主键索引之外的所有索引都被称为非聚集索引或二级索引
创建索引
#可以在创建表时,增加索引
CREATE TABLE t_index(
col1 INT PRIMARY KEY,
col2 INT NOT NULL,
col3 INT NOT NULL,
col4 VARCHAR(20),
INDEX (col2,col3)
);
#如果我们想在表中添加索引,我们将使用以下的CREATE INDEX语句:
CREATE INDEX [index_name] ON [table_name] (column names)
在这个语句中, index_name 是索引的名称, table_name 是索引所属表的名称,而 column_names 是列的列表。
默认情况下,如果我们没有指定索引的类型,MySQL 允许使用 BTREE 作为索引类型。下表展示了基于表的存储引擎的不同类型的索引。
| SN | Storage Engine | Index Type |
|---|---|---|
| 1. | InnoDB | BTREE |
| 2. | Memory/Heap | HASH, BTREE |
| 3. | MYISAM | BTREE |
删除索引
MySQL允许使用DROP INDEX语句从表中删除现有的索引。要从表中删除索引,我们可以使用以下查询:
DROP INDEX index_name ON table_name [algorithm_option | lock_option];
如果我们想要删除一个索引,需要两个条件:
- 首先,我们必须指定我们想要删除的索引的名称。
- 其次,索引所属的表的名称。
算法选项
算法选项允许我们指定在表中删除索引的特定算法。 algorithm_option 的语法如下:
Algorithm [=] {DEFAULT | INPLACE | COPY}HTML: 这个算法主要支持两种,即INPLACE和COPY。
COPY: 此算法允许我们将一个表逐行复制到另一个新表,然后对此新表执行DROP Index语句。在这个表上,我们不能对数据进行INSERT和UPDATE操作。
INPLACE: 此算法允许我们重新构建一个表而不是复制原始表。我们可以在这个表上执行所有的数据操作。在这个表上,MySQL在索引删除期间发出一个独占的元数据锁。
注意:如果您未定义算法子句,则MySQL使用INPLACE算法。如果不支持INPLACE,则使用COPY算法。默认算法与不使用任何算法子句的Drop index语句相同。
锁定选项
此子句使我们能够在索引删除期间控制并发读写的级别。lock_option的语法如下:
LOCK [=] {DEFAULT|NONE|SHARED|EXCLUSIVE}在语法中,我们可以看到lock_option包含了 四种模式 ,分别是DEFAULT、NONE、SHARED和EXCLUSIVE。现在,我们将详细讨论所有的模式:
SHARED: 此模式仅支持并发读取,不支持并发写入。当不支持并发读取时,将报错。
DEFAULT: 对于指定的算法,此模式可以实现最大程度的并发性。如果支持并发读取和写入,则启用并发模式;否则强制使用独占模式。
NONE: 如果支持此模式,则可以同时进行读取和写入。否则,将报错。
EXCLUSIVE: 此模式强制执行独占访问。
显示索引
我们可以使用Show Indexes语句获取表的索引信息。此语句可以编写如下:
mysql> SHOW INDEXES FROM table_name;
在上面的语法中,我们可以看到如果我们想要获取表的索引,就需要在FROM关键字之后指定 table_name 。在语句成功执行后,它将返回当前数据库中表的索引信息。
查询SHOW INDEX返回以下字段/信息:
表: 包含表的名称。
非唯一: 如果索引包含重复项,则返回1。否则,返回0。
键名: 是索引的名称。如果表包含主键,则索引名称始终为PRIMARY。
Seq_in_index: 是索引中列的序列号,从1开始。
列名: 包含列的名称。
排序规则: 提供关于列在索引中如何排序的信息。它包含的值为 A 表示升序, D 表示降序,而 Null 表示未排序的。
基数: 给出索引表中唯一值的估计数量,其中较高的基数表示MySQL使用索引的机会较大。
子部分: 是索引的前缀。如果表的所有列都被索引,则其值为NULL。当列部分被索引时,它将返回索引的字符数。
打包: 告诉如何打包索引。否则,返回NULL。
NULL: 如果列没有NULL值,则包含 空 ;否则,返回YES。
索引类型: 包含索引方法的名称,如BTREE,HASH,RTREE,FULLTEXT等。
注释: 包含索引信息,当它们未在列中描述时。例如,当索引被禁用时,返回disabled。
索引列: 当使用 comment 属性创建索引时,它包含指定索引的注释。
可见: 如果索引对查询优化器可见,则包含YES;否则,包含NO。
表达式: MySQL 8.0支持影响 表达式 和 列名 列的 函数键部分 。我们可以通过以下要点更清楚地了解:
- 对于函数部分,表达式列表示关键部分的表达式,列名表示NULL。
- 对于非函数部分,表达式表示NULL,列名表示由关键部分索引的列。
触发器
MySQL触发器是存储程序,它们在数据库表中发生特定事件时自动执行。这些特定事件可以是插入(INSERT)、更新(UPDATE)或删除(DELETE)记录。触发器由三个主要部分组成:触发事件(定义事件)、触发操作(定义需要执行的操作)和触发时间(指示触发器何时执行)。
使用触发器的原因:
- 触发器用于通过将约束和规则应用于数据库来提高数据完整性。您可以定义一个触发器来控制如果某条记录被其他表引用,则不允许删除该记录,确保引用完整性。触发器允许您在插入、更新或删除数据之前自动验证数据,并确保只有有效的数据存储在数据库中。
- 触发器允许在数据库内自动执行重复性任务。您可以定义触发器,在特定事件发生时自动执行一些操作。触发器通过自动化复杂的数据转换或同步过程,帮助减少手动工作量并保持数据准确性。
- 触发器对于跟踪和审计关键数据的更改非常有帮助。您可以通过定义触发器来捕获和记录对特定表或列所做的修改。您还可以追踪更改是由谁进行的、更改了什么以及什么时间进行的。触发器还可以根据特定条件生成通知,实时监控关键数据事件。
- 触发器允许在数据库级别应用特定的业务规则。您可以使用触发器应用安全策略、访问限制或数据验证规则。触发器可以让您在数据库级别实现复杂的业务逻辑,并确保在各种应用程序中遵守预定义规则的一致性。
触发器类型
MySQL有两种类型的触发器:BEFORE触发器和AFTER触发器。
BEFORE触发器:
BEFORE触发器也称为前触发器,它在触发事件发生之前执行。它允许在实际更改发生之前修改数据或执行其他操作。通常用于数据验证或应用业务规则。
MySQL BEFORE触发器有三种不同的类型:
BEFORE INSERT触发器: 该触发器在执行INSERT操作之前执行。它可以用于修改要插入的值或在插入到表中之前验证数据。
BEFORE UPDATE触发器: 该触发器在执行UPDATE操作之前执行。它允许您修改正在更新的值或应用某些条件修改更新操作
AFTER触发器:
AFTER触发器也称为后触发器,它在触发事件完成后执行。它被用于根据触发事件的结果执行操作。通常用于更新相关表、记录更改等任务。
MySQL AFTER触发器有三种不同的类型:
AFTER INSERT触发器: 该触发器在表中插入新行后自动执行。它可以定义为根据插入的数据执行某些操作或计算。
AFTER UPDATE触发器: 该触发器在表中的一行或多行被更新后自动执行。通常用于根据更新的数据采取相应的行动。
AFTER DELETE触发器: 该触发器在表中的一行或多行被删除后自动执行。它允许您根据删除的数据执行操作。
触发器的创建
MySQL触发器的语法和结构:
DELIMITER CREATE TRIGGER trigger_name
trigger_time trigger_event
ON table_name FOR EACH ROW
BEGIN
-- trigger action statements
END
DELIMITER ;
你需要使用CREATE TRIGGER命令来创建一个触发器,其遵循特定的语法。MySQL触发器的结构包含了triggerName、triggerTime、triggerEvent、triggerAction以及用于定义触发器的定界符。
triggerName 是为了标识目的而给触发器起的名字。
triggerTime 定义了触发器应该执行的时间,可以是触发事件发生之前或之后。
triggerEvent 定义了触发触发器的事件,比如UPDATE、INSERT或DELETE。
tableName 是应用触发器的表的名称。
FOR EACH ROW 表示触发器应该对每个受影响的行执行。
在 BEGIN 和 END 块之间,您必须编写定义触发器触发时需要执行的SQL语句。这些语句可以包括对数据的修改、计算或其他存储过程的调用。















 762
762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









