







自适应时频变换
上一章是瞬态检测结果在后续的所有步骤中几乎都有应用,本章节的自适应时频变换也是基于瞬态稳态状态进行处理的。对于稳态信号,为了有效地表示其特点,采用高频率分辨率的变换;而对于暂态信号, 为了更好的描述信号快速变化的频谱信息,采用高时间分辨率的变换。
这两种操作模式共享一个公共的缓冲和窗口模块,并且从一个操作模式到另一个操作模式的切换是即时的。因此,在瞬态检测中不需要额外的预先信息。这使得编解码器能够在低复杂度和零额外延迟的情况下具有可选的时间分辨率。
从文档给出的结构图可以看出时频变换的基本步骤:
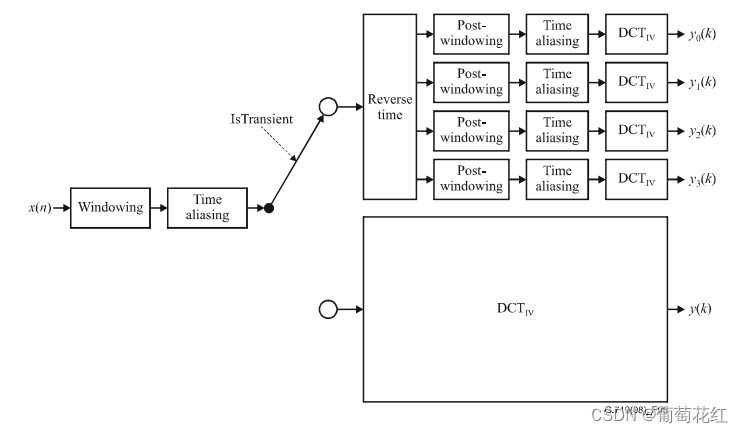
时频变换会经过三个步骤,分别是:加窗、时域混叠、DCT-IV即离散余弦变换。经过三个步骤,稳态信号会输出
y
(
k
)
y(k)
y(k)
k=0,1,2……L-1,瞬态信号会输出四组:
y
0
(
k
)
,
y
1
(
k
)
,
y
2
(
k
)
,
y
3
(
k
)
y_{0}(k),y_{1}(k),y_{2}(k),y_{3}(k)
y0(k),y1(k),y2(k),y3(k) k = 0, …, L/4 – 1。
加窗
加窗使用的音频序列是初始的音频序列,即音频最初的输入序列,并不是经过瞬态检测高通滤波的序列。
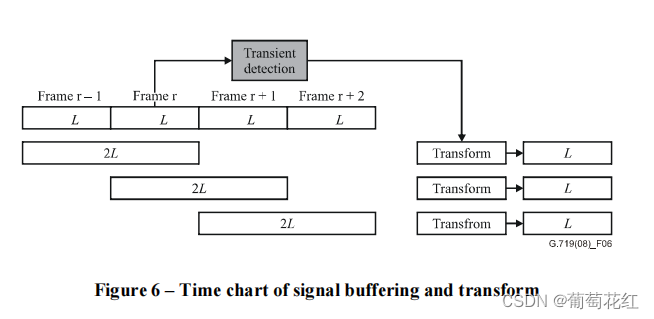
文档中图6表示的是整个时频转换的输入和输出,可以看出,整个流程是将前后两个输入帧,经过转换,变成一个输出长为L的序列。
输入的每一帧的数据长为20ms,将这一帧与前一帧缓存到一起,组成一个40ms的数据,然后将这个数据加一个正弦窗,具体可以看文中的图7.
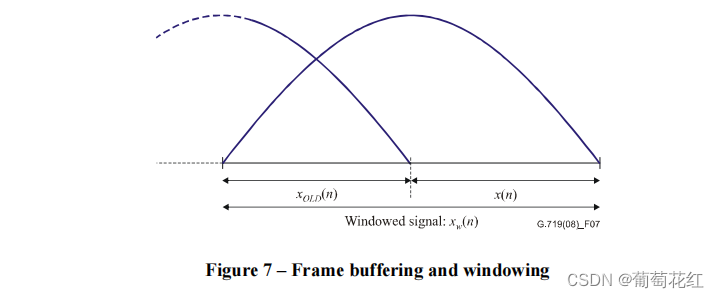
可以看出,两帧数据组合到一起,该正弦窗的公式是:
h
(
n
)
=
s
i
n
[
(
n
+
1
2
)
π
2
L
]
(1)
h(n) = sin[(n+\frac{1}{2})\frac{\pi }{2L}]\tag{1}
h(n)=sin[(n+21)2Lπ](1)
使用点数学知识,这很好算出来。因此,经过加窗后的缓存数据表示为:
x
w
(
n
)
=
{
h
(
n
)
x
o
l
d
(
n
)
n
=
0
,
1
,
…
…
L
−
1
,
h
(
n
)
x
(
n
−
1
)
n
=
L
,
L
+
1
,
…
…
2
L
−
1
(2)
x_{w}(n)=\begin{cases}h(n)x_{old}(n) n=0,1,……L-1,\\h(n)x(n-1) n=L,L+1,……2L-1\end{cases}\tag{2}
xw(n)={h(n)xold(n)n=0,1,……L−1,h(n)x(n−1)n=L,L+1,……2L−1(2)
此时$ x w ( n ) x_{w}(n) xw(n)的长度是40ms即,1920个数字。
时域混叠
经过加窗后,生成的1920个数据,经过时域混叠操作将其再次转换为20ms,即960个数据,时域混叠操作是通过矩阵计算的。
x
~
=
[
0
0
−
J
L
/
2
−
I
L
/
2
I
L
/
2
−
J
L
/
2
0
0
]
x
w
(3)
\tilde{x} = \begin{bmatrix} 0 &0 &-J_{L/2} &-I_{L/2} \\ I_{L/2} &-J_{L/2} &0 &0 \end{bmatrix}x_{w}\tag{3}
x~=[0IL/20−JL/2−JL/20−IL/20]xw(3)
其中,KaTeX parse error: Can't use function '$' in math mode at position 8: I_{L/2}$̲和J_{L/2}$是 L / 2的特征矩阵,和时域反转矩阵。
J
L
/
2
=
[
0
.
.
.
1
.
.
.
.
.
.
.
.
.
1
.
.
.
0
]
I
L
/
2
=
[
1
.
.
.
0
.
.
.
.
.
.
.
.
.
0
.
.
.
1
]
(4)
J_{L/2}=\begin{bmatrix} 0 &... &1 \\ ... & ...& ...\\ 1&... &0 \end{bmatrix}I_{L/2}=\begin{bmatrix} 1 &... &0 \\ ... & ...& ...\\ 0&... &1 \end{bmatrix}\tag{4}
JL/2=
0...1.........1...0
IL/2=
1...0.........0...1
(4)
根据矩阵的乘法,Lx2L矩阵与2Lx1的矩阵相乘,结果是Lx1,因此,经过处理后,得到的数据又变成了L长度。
矩看起来相对比较麻烦,文档中给出更好理解的图示。
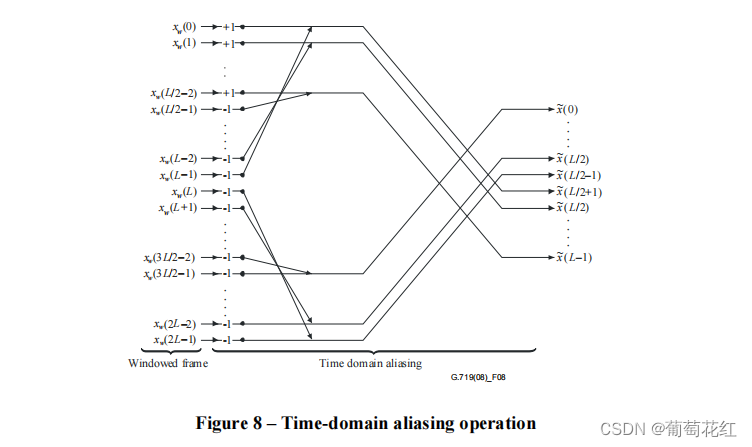
可以看出,对于前L个数据(前一帧),头数据减去尾数据会位于混叠结果的后半部分,而后L个数据(当前帧)处理后位于混叠结果的前半部分。
x
(
0
)
−
x
(
L
−
1
)
=
x
~
(
L
/
2
)
x(0)-x(L-1) = \tilde{x}(L/2)
x(0)−x(L−1)=x~(L/2)
x
(
1
)
−
x
(
L
−
2
)
=
x
~
(
L
/
2
+
1
)
x(1)-x(L-2) = \tilde{x}(L/2+1)
x(1)−x(L−2)=x~(L/2+1)
…
…
……
……
x
(
L
/
2
−
2
)
−
x
(
L
)
=
x
~
(
L
−
1
)
x(L/2-2)-x(L) = \tilde{x}(L-1)
x(L/2−2)−x(L)=x~(L−1)
相反地,
−
x
(
2
L
−
1
)
−
x
(
L
)
=
x
~
(
L
/
2
−
1
)
-x(2L-1)-x(L) = \tilde{x}(L/2-1)
−x(2L−1)−x(L)=x~(L/2−1)
−
x
(
2
L
−
1
)
−
x
(
L
+
1
)
=
x
~
(
L
/
2
−
2
)
-x(2L-1)-x(L+1) = \tilde{x}(L/2-2)
−x(2L−1)−x(L+1)=x~(L/2−2)
…
…
……
……
−
x
(
3
L
/
2
−
2
)
−
x
(
3
L
/
2
−
1
)
=
x
~
(
0
)
-x(3L/2-2)-x(3L/2-1) = \tilde{x}(0)
−x(3L/2−2)−x(3L/2−1)=x~(0)
因此后半部分的数据可以是不用计算的,直接缓存起来,每次计算直接将前一帧的混叠结果拷贝到窗的后面,只计算当前帧的混叠结果即可,这也是代码中的实现。
代码实现
时域加窗和时域混叠在G719的代码中集合到了一起,通过wtda函数来实现,函数调用点:
wtda(audio, wtda_audio, c->old_wtda);
顾名思义,Windowing and Time Domain Aliasing 窗口化和时域混叠。其中:
- audio是原始输入数据
- wtda_audio是经过混叠加窗的输出数据。
- c->old_wtda是上一次计算的加窗混叠数据,长度为480,对应混叠区域的后半部分。
void wtda(float new_audio[], //960
float wtda_audio[], //960
float old_wtda[]) { //480
short i;
float *x1,*x2;
float *y1,*y2;
float *c ,*s;
/* Second half */
for(i = 0; i < FRAME_LENGTH / 2 ; i++) { //0-480
wtda_audio[FRAME_LENGTH/2 + i] = old_wtda[i]; //从480往后, 把old_wtda(10ms)拷贝到后480个位置
}
/* First half */
y1 = wtda_audio; //wtda_audio 第一个位置
y2 = old_wtda + FRAME_LENGTH / 2 - 1;// old_wtda的最后一个指针
x1 = new_audio + FRAME_LENGTH/2; // 输入数据的中间,往后+
x2 = new_audio + FRAME_LENGTH / 2 - 1; //输入数据的中间,往前-
c = window + FRAME_LENGTH/2 - 1; //windows + 480中间,往前-
s = window + FRAME_LENGTH/2; //windows + 480中间,往后+
for(i = 0; i < FRAME_LENGTH / 2 ; i++) {// 0 - 479,矩阵计算
*y2 = *c * *x2 - *s * *x1 ;
*y1 = -*s * *x2 - *c * *x1 ;
y1++;
y2--;
x1++;
x2--;
c--;
s++;
}
}
两个功能通过不到30行代码实现,传进来的三个参数列表的长度分别是960,960,480。
- 首先定义几个位移指针,用于计算当前帧的时域混叠。
- 9-11行将上一次计算的时域混叠结果保存到后半部分,也就是后480个直接使用缓存数据。
- 然后y1与y2分别表示前480个数据的头指帧和old窗的尾指针,为什么这么计算,可以看上图8例子,计算方向是相反的。wtda_audio的480个数据保存的是当前帧在最终帧的前半部分数据,用于当此计算。old_wtda 保存是当前帧计算出的下一次数据,保存到下一帧的后半段。这样的数据结构首先可以减少内存分配,少分配一半的变量存储40ms数据,同时也减少了遍历。
- 这里主要是用了对半计算的思想,y1和y2计算的两行分别表示矩阵计算3中的上半部分和下半部分。
- 最后,c和s这两个值用于加权,这里主要是用于加窗的,可以查看window 表,表格里都是已经计算好的参数值。由于公式1只和n有关,因此对每一帧数据,值都是一样的,表示正弦曲线上的值,可以提前计算,不需要调用三角函数,加快了计算事件。
这里wtda_audio和old_wtda 的计算比较绕,多看两遍加上图应该就能理解了。
时频变换
对时域信号经过加窗和混叠处理之后,接下来就是通过离散余弦变换将数据转换到频域了。这里有稳态数据、暂态数据的变换差别。
稳态数据
稳态数据直接通过第四型的离散余弦变换(DCT-IV),进行频域转换,长度为L的数据的DCT变换公式为:
y
(
k
)
=
∑
L
−
1
n
=
0
x
~
(
n
)
c
o
s
[
(
n
+
1
2
)
(
k
+
1
2
)
π
L
]
(5)
y(k)= \sum_{L-1}^{n=0}\tilde{x}(n)cos[(n+\frac{1}{2})(k+\frac{1}{2})\frac{\pi }{L}]\tag{5}
y(k)=L−1∑n=0x~(n)cos[(n+21)(k+21)Lπ](5)
其中 y ( k ) y(k) y(k)表示输入数据的频谱系数。这里使用加窗、混叠、DCT相当于对信号进行MLT 重叠调制变换。
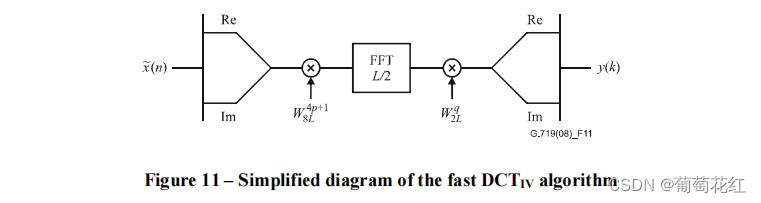
对于DCT-IV,根据文档描述,使用了一种简单有效的算法。该算法是基于输入信号长度L/2的FFT算法。这里的具体计算方法如下图所示:
-
首先将混叠后的时域序列转换为一个复数序列:
z ( p ) = x ~ ( 2 p ) + j x ~ ( L − 1 − 2 p ) , p = 0 , 1 , 2 ⋯ L / 2 − 1 (6) z(p)= \tilde{x}(2p)+j\tilde{x}(L-1-2p), p=0,1,2\cdots L/2-1\tag{6} z(p)=x~(2p)+jx~(L−1−2p),p=0,1,2⋯L/2−1(6)
其中j为复变量。实部是序列的偶数子列,虚部是奇数子列的反序列。 -
前处理:所形成的复杂序列进行预调制:
z ~ ( p ) = W 8 L 4 p + 1 z ( p ) (7) \tilde{z}(p)= W_{8L}^{4p+1}z(p)\tag{7} z~(p)=W8L4p+1z(p)(7)
其中:
W N = e j 2 π N (8) W_{N} = e^{j\frac{2\pi }{N}}\tag{8} WN=ejN2π(8)
根据欧拉公式 e j θ = c o s θ + j s i n θ e^{j\theta } = cos\theta +jsin\theta ejθ=cosθ+jsinθ:
W 8 L 4 p + 1 = e j ( 4 p + 1 ) 2 π 8 L (9) W_{8L}^{4p+1} = e^{j\frac{(4p+1)2\pi }{8L}}\tag{9} W8L4p+1=ej8L(4p+1)2π(9)
W 8 L 4 p + 1 = c o s ( ( 4 p + 1 ) π 4 L ) + j s i n ( ( 4 p + 1 ) π 4 L ) (10) W_{8L}^{4p+1} = cos(\frac{(4p+1)\pi }{4L})+jsin(\frac{(4p+1)\pi }{4L})\tag{10} W8L4p+1=cos(4L(4p+1)π)+jsin(4L(4p+1)π)(10)
可以看出,虚部和实部至于p相关,p又是固定值,因此可以提前计算出来。
根据复数的乘法,可以得出:
z
~
(
p
)
=
(
c
o
s
(
(
4
p
+
1
)
π
4
L
)
+
j
s
i
n
(
(
4
p
+
1
)
π
4
L
)
)
(
x
~
(
2
p
)
+
j
x
~
(
L
−
1
−
2
p
)
)
=
(
c
o
s
(
(
4
p
+
1
)
π
4
L
)
x
~
(
2
p
)
+
s
i
n
(
(
4
p
+
1
)
π
4
L
)
x
~
(
L
−
1
−
2
p
)
)
+
(
c
o
s
(
(
4
p
+
1
)
π
4
L
)
x
~
(
L
−
1
−
2
p
)
−
s
i
n
(
(
4
p
+
1
)
π
4
L
)
x
~
(
2
p
)
)
j
\tilde{z}(p)= (cos(\frac{(4p+1)\pi }{4L})+jsin(\frac{(4p+1)\pi }{4L}))( \tilde{x}(2p)+j\tilde{x}(L-1-2p)) = (cos(\frac{(4p+1)\pi }{4L}) \tilde{x}(2p)+sin(\frac{(4p+1)\pi }{4L})\tilde{x}(L-1-2p))+(cos(\frac{(4p+1)\pi }{4L})\tilde{x}(L-1-2p)-sin(\frac{(4p+1)\pi }{4L})\tilde{x}(2p))j
z~(p)=(cos(4L(4p+1)π)+jsin(4L(4p+1)π))(x~(2p)+jx~(L−1−2p))=(cos(4L(4p+1)π)x~(2p)+sin(4L(4p+1)π)x~(L−1−2p))+(cos(4L(4p+1)π)x~(L−1−2p)−sin(4L(4p+1)π)x~(2p))j
- FFT计算
序列
z
~
(
p
)
\tilde{z}(p)
z~(p)的傅里叶变换
Z
~
(
p
)
\tilde{Z}(p)
Z~(p)的计算方法是:
Z
~
(
q
)
=
∑
p
=
0
L
/
2
−
1
z
~
(
p
)
W
L
/
2
p
q
(12)
\tilde{Z}(q)= \sum_{p=0}^{L/2-1}\tilde{z}(p)W_{L/2}^{pq}\tag{12}
Z~(q)=p=0∑L/2−1z~(p)WL/2pq(12),
这个算法来自于Winograd FFT。
对于 W L / 2 p q W_{L/2}^{pq} WL/2pq,和上方的计算类似,p和q的值是固定的,因此也可以算出具体的参数值,提前存在表格中便于计算。
- 后处理。对FFT后的复数序列进一步处理:
Z ˉ ( q ) = W 2 L q Z ( q ) (13) \bar{Z}(q)= W_{2L}^{q}Z(q)\tag{13} Zˉ(q)=W2LqZ(q)(13)
其中:
W 2 L q = c o s ( q π L ) + j s i n ( q π L ) (14) W_{2L}^{q} = cos(\frac{q\pi }{L})+j sin(\frac{q\pi }{L})\tag{14} W2Lq=cos(Lqπ)+jsin(Lqπ)(14) - 得到频域数据。DCT-IV的最终结果就是
Z
ˉ
(
q
)
\bar{Z}(q)
Zˉ(q)的实部和虚部的组合:
{ y ( 2 q ) = R e { Z ˉ ( q ) } , y ( L − 1 − 2 q ) = − I n { Z ˉ ( q ) } (15) \begin{cases}y(2q) = Re\{\bar{Z}(q)\},\\y(L-1-2q) = -In\{\bar{Z}(q)\}\end{cases}\tag{15} {y(2q)=Re{Zˉ(q)},y(L−1−2q)=−In{Zˉ(q)}(15)
这一步的取值和公式6中的取值基本相同。
稳态部分代码
对于时频变换部分,其主要代码为:
direct_transform(wtda_audio, t_audio, is_transient);
- wtda_audio是经过混叠的时域数据
- t_audio是经过变换后的频域数据
- is_transient为稳态、暂态标记
direct_transform会根据is_transient进行稳态、暂态的处理,暂态处理相对麻烦,这里先看稳态数据处理函数dct4_960,顾名思义,对960个数据进行DCT4转换。
void dct4_960(float v[MLT960_LENGTH], float coefs32[MLT960_LENGTH]) {
short n;
float f_int[MLT960_LENGTH];
for(n = 0; n < MLT960_LENGTH; n += 2) { // 960 步长为2/ (a+bi)·(c+di)=(ac-bd)+(ad+bc)i
f_int[n] = ((v[n] * dct480_table_1[n>>1].r -
v[(MLT960_LENGTH_MINUS_1-n)] * dct480_table_1[n>>1].i)); //959
f_int[n+1] = ((v[n] * dct480_table_1[n>>1].i +
v[(MLT960_LENGTH_MINUS_1-n)] * dct480_table_1[n>>1].r));
}
//960转换为480的fft
wfft480((complex *)f_int, (complex *)v);
for(n = 0; n < MLT960_LENGTH; n += 2){
coefs32[n] = ((v[n] * dct480_table_2[n>>1].r -
v[n+1] * dct480_table_2[n>>1].i))/4.0f;
coefs32[MLT960_LENGTH_MINUS_1-n] = -(v[n] * dct480_table_2[n>>1].i +
v[n+1] * dct480_table_2[n>>1].r)/4.0f;
}
}
函数分为三部分:前处理,FFT、后处理。
- 前处理部分是上述步骤1和2的集合,这一部分(4-9行)是对公式11的展开形式,其中v[n]表示的是公式11中的x,dct480_table_1中存储的是cos和sin函数。根据这些表格数据都是可以提前计算出来,直接使用乘法进行计算即可。dct480_table_1可通过公式10计算。
- 后处理部分(12-17行)则是上述步骤4和步骤5的集合。这一步同样是应用了复数的乘法,同时取了实部和-虚部填充序列的值。dct480_table_2可通过公式14计算得到。
FFT部分是这部分的大头,主要实现是第十一行的wfft480函数,即对480个数据进行wfft。
static void wfft480(complex *pI, complex *pO)
{
//略
for(i = 0; i < 480; i+=120) {
wfft120(pI+i);
}
//略
return;
}
这个函数代码相对变换较多,这里就不多分析(其实是不容易看,没看明白),感兴趣可以自己研究下,从代码中可以看出,经过一系列变换之后,wfft480会将480个数据分成4组进行计算,得到最终的数据。
DCT-IV的5个计算步骤,对于瞬态信号同样适用,只不过,瞬态信号并不是直接进行DCT变换,变换之前需要进行其他的处理。
瞬态信号
对于瞬态信号,可以看文章最开始的图,首先会对数据进行重排,保证滤波器组时频响应一致。不排序产生的滤波器组基函数将有一个非相干的时间和频率响应。这里会对时间混叠序列重排,重排机制为:
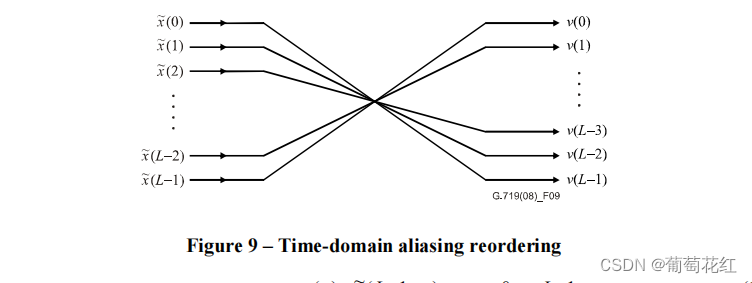
其实就是倒序:
v
(
n
)
=
x
~
(
L
−
1
−
n
)
v(n)=\tilde{x}(L-1-n)
v(n)=x~(L−1−n)
倒序后得到的数组v,两次填充L/8个0数据,然后以50%的重叠数据将整个序列分成多个L/2长度的数据,同样使用正弦窗进行处理。如下图:
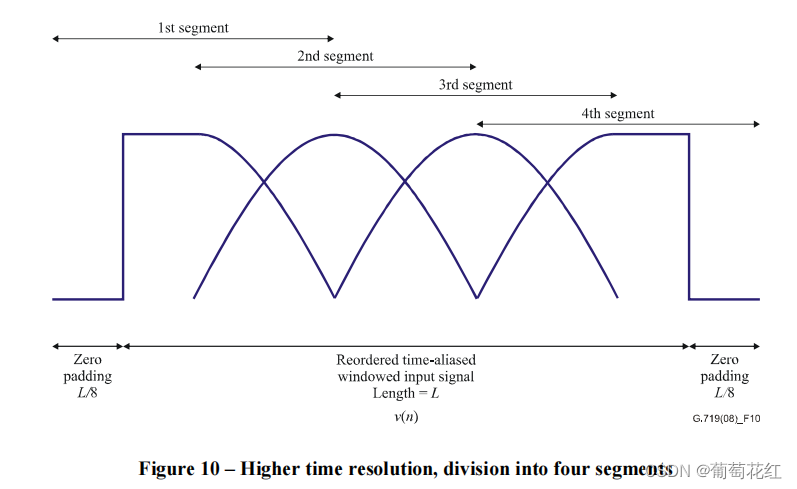
对划分出的四块数据进行 time aliasing + DCTIV,得到四个L/4的输出,这也不会增加总输出结果。
代码中这部分主要是通过wscw16q15窗系数以及dct4_240函数实现,dct4_240和上述dct4_960函数类似,最终都是调用wfft120进行FFT变换。
代码相对不大好阅读,感兴趣可以自己研究下,不再介绍。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









