







Python学习日记-简单小爬虫
简单小爬虫
最近一直在学习python,学了又忘,忘了又学, 好记性不如烂笔头。索性记录下来,方便以后翻看。
一、思路:找一个网页通过python的urllib包获取源代码,在通过re模块和正则表达式匹配需要的字段保存如mysql数据库
二、实现:由于不知爬那个网页,突然浏览器弹出H网链接,那就爬它吧,嘻嘻嘻:https://www.gzkd888.com/2800.html

准备爬取名称出处内容和图片的链接,查看源代码可以看到:

直接把这段copy到RegexBuddy工具开始编写正则。
匹配链接的:alt=“gif出处 No.\d+” alt="" src=".*" />

匹配名称的:

正则OK后着手python代码:
一般爬虫简单分为四步:
1.定义爬虫url
2.通过urllib.request.urlopen方法去打开网页
3.使用read()方法拿到二进制数据
4.再通过decode(“utf-8”)拿到文本

把拿到的数据return看下有没有mian方法打印看下。
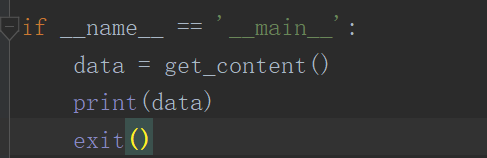
嘻嘻拿到了html代码了

接下来re模块和匹配正则:

这里说下re模块的三个方法search,match,findall三个方法
match:从字符串首字母开始匹配,如果匹配成功,则返回Match对象,反之返回空。若想获取返回Match对象转为值,则用group()方法
search:从这个整个字符串匹配,如果匹配成功,则返回Match对象,反之返回空。若想获取返回Match对象转为值,则用group()方法
findall:匹配所有的字符串,返回的是list。
接下来拿到2个list,通过dict(zip())去凭借成一个字典
准备存入mysql数据库,定义add_av()方法


第一次保存入库成功。
后面请求多几次发现404了,一般网站都做反爬虫,请求次数太频繁就会被拉黑名单或者限制请求时长。爬虫和反爬虫是一直在作斗争















 176
176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









