代码
package com.myhadoop.mapreduce.test
import org.apache.hadoop.conf.Configured
import org.apache.hadoop.fs.Path
import org.apache.hadoop.io.LongWritable
import org.apache.hadoop.io.Text
import org.apache.hadoop.mapred.lib.InputSampler
import org.apache.hadoop.mapred.lib.TotalOrderPartitioner
import org.apache.hadoop.mapreduce.Reducer
import org.apache.hadoop.mapreduce.Job
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat
import org.apache.hadoop.util.Tool
import org.apache.hadoop.util.ToolRunner
import java.io.IOException
public class TotalOrderSort extends Configured implements Tool{
public static class myMap extends org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, Text>{
public void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException{
String[] split = value.toString().split("\\s+")
for (int i = 0
Text word = new Text(split[i])
context.write(word,new Text(""))
}
}
}
public static class myReduce extends Reducer<Text,Text,Text,Text>{
public void reduce(Text key, Iterable<Text> values,Context context) throws IOException,InterruptedException
{
context.write(key, new Text(""))
}
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf())
job.setJarByClass(TotalSort.class)
job.setJobName("TotalSortTest")
job.setInputFormatClass(KeyValueTextInputFormat.class)
job.setNumReduceTasks(3)
//因为map和reduce的输出是同样的类型,所以输出一个就可以了
job.setOutputKeyClass(Text.class)
job.setOutputValueClass(Text.class)
job.setMapperClass(myMap.class)
job.setReducerClass(myReduce.class)
FileInputFormat.setInputPaths(job, new Path(args[0]))
FileOutputFormat.setOutputPath(job, new Path(args[1]))
// 设置分区文件,即采样后放在的文件的文件名,不是完整路径
TotalOrderPartitioner.setPartitionFile(job.getConfiguration(), new Path(args[2]))
//采样器:三个参数
InputSampler.Sampler<Text, Text> sampler = new InputSampler.RandomSampler<>(0.01, 10, 100)
//把分区文件放在hdfs上,对程序没什么效果,方便我们查看而已
FileInputFormat.addInputPath(job, new Path("/test/sort"))
//将采样点写入到分区文件中,这个必须要
InputSampler.writePartitionFile(job, sampler)
job.setPartitionerClass(TotalOrderPartitioner.class)
boolean success = job.waitForCompletion(true)
return success ? 0:1
}
public static void main(String[] args) throws Exception {
int ret = ToolRunner.run(new TotalSortTest(), args)
System.exit(ret)
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
注意的地方
InputSampler.Sampler<Text, Text> sampler = new InputSampler.RandomSampler<>(0.01, 10, 100);中三个参数要注意
InputSampler.Sampler<Text, Text> 只能是Text,Text的类型
3. TotalOrderPartitioner.setPartitionFile(job.getConfiguration(), new Path(args[2]));用来给TotalOrderPartitioner初始化赋值,job.setPartitionerClass(TotalOrderPartitioner.class); 进行分区,就不需要自己写分区函数了
4. job.setInputFormatClass(KeyValueTextInputFormat.class); 注意里面是KeyValueTextInputFormat.class,而不是TextInputFormat.class。
5. 在集群上,次程序才能体现出来
6.由于我这里,map的输入和输出都是用的(Text,Text),所以我只需要设置
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
如果不一样,那么 应该设置4个,前两个为map的输出类型,后两个为reduce的输出类型
job.setMapOutputKeyClass(Text.class)
job.setMapOutputValueClass(IntWritable.class)
job.setOutputKeyClass(IntWritable.class)
job.setOutputValueClass(NullWritable.class)
MapReduce全排序的方法1:
每个map任务对自己的输入数据进行排序,但是无法做到全局排序,需要将数据传递到reduce,然后通过reduce进行一次总的排序,但是这样做的要求是只能有一个reduce任务来完成。
并行程度不高,无法发挥分布式计算的特点。
MapReduce全排序的方法2:
针对方法1的问题,现在介绍方法2来进行改进;
使用多个partition对map的结果进行分区,且分区后的结果是有区间的,将多个分区结果拼接起来,就是一个连续的全局排序文件。
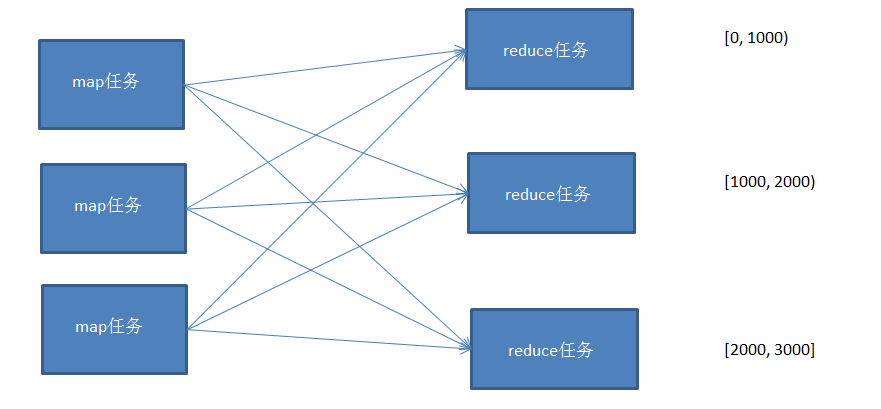
Hadoop自带的Partitioner的实现有两种,一种为HashPartitioner, 默认的分区方式,计算公式 hash(key)%reducernum,另一种为TotalOrderPartitioner, 为排序作业创建分区,分区中数据的范围需要通过分区文件来指定。
分区文件可以人为创建,如采用等距区间,如果数据分布不均匀导致作业完成时间受限于个别reduce任务完成时间的影响。
也可以通过抽样器,先对数据进行抽样,根据数据分布生成分区文件,避免数据倾斜。
这里实现一个通过随机抽样来生成分区文件,然后对数据进行全排序,根据分区文件的范围分配到不同的reducer中。
示例代码:

import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.KeyValueTextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.partition.InputSampler;
import org.apache.hadoop.mapreduce.lib.partition.TotalOrderPartitioner;
import java.io.IOException;
/**
* Created by Edward on 2016/10/4.
*/
public class TotalSort {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//access hdfs's user
System.setProperty("HADOOP_USER_NAME","root");
Configuration conf = new Configuration();
conf.set("mapred.jar", "D:\\MyDemo\\MapReduce\\Sort\\out\\artifacts\\TotalSort\\TotalSort.jar");
FileSystem fs = FileSystem.get(conf);
/*RandomSampler 参数说明
* @param freq Probability with which a key will be chosen.
* @param numSamples Total number of samples to obtain from all selected splits.
* @param maxSplitsSampled The maximum number of splits to examine.
*/
InputSampler.RandomSampler<Text, Text> sampler = new InputSampler.RandomSampler<>(0.1, 10, 10);
//设置分区文件, TotalOrderPartitioner必须指定分区文件
Path partitionFile = new Path( "_partitions");
TotalOrderPartitioner.setPartitionFile(conf, partitionFile);
Job job = Job.getInstance(conf);
job.setJarByClass(TotalSort.class);
job.setInputFormatClass(KeyValueTextInputFormat.class); //数据文件默认以\t分割
job.setMapperClass(Mapper.class);
job.setReducerClass(Reducer.class);
job.setNumReduceTasks(4); //设置reduce任务个数,分区文件以reduce个数为基准,拆分成n段
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setPartitionerClass(TotalOrderPartitioner.class);
FileInputFormat.addInputPath(job, new Path("/test/sort"));
Path path = new Path("/test/wc/output");
if(fs.exists(path))//如果目录存在,则删除目录
{
fs.delete(path,true);
}
FileOutputFormat.setOutputPath(job, path);
//将随机抽样数据写入分区文件
InputSampler.writePartitionFile(job, sampler);
boolean b = job.waitForCompletion(true);
if(b)
{
System.out.println("OK");
}
}
}
测试数据:
1 1
2 1
3 1
4 1
5 1
6 1
7 1
8 1
9 1
10 2
11 2
12 2
13 2
14 2
15 2
16 2
17 2
18 2
19 2
20 2
...
5999 4
6000 4
6001 4
6002 4
6003 4
6004 4
6005 4
6006 4
6007 4
6008 4
6009 4
6010 4
抽样生成的分区文件为:
# hadoop fs -text /user/root/_partitions
2673 (null)
4441 (null)
5546 (null)
生成的抽样文件为sequence file通过 -text打开查看
生成的排序结果文件:

文件内容:
hadoop fs -cat /test/wc/output/part-r-00000
...
2668 4
2669 4
267 3
2670 4
2671 4
2672 4
hadoop fs -cat /test/wc/output/part-r-00001
...
4431 4
4432 4
4433 4
4434 4
4435 4
4436 4
4437 4
4438 4
4439 4
444 3
4440 4
hadoop fs -cat /test/wc/output/part-r-00002
...
554 3
5540 4
5541 4
5542 4
5543 4
5544 4
5545 4
hadoop fs -cat /test/wc/output/part-r-00003
...
99 2
990 3
991 3
992 3
993 3
994 3
995 3
996 3
997 3
998 3
999 3
测试文本
ba bac
df gh hgg dft dfa dfga df fdaf qqq we fsf aa bb ab
rr
ty ioo zks huawei mingtong jyzt beijing shanghai shenzhen wuhan nanning guilin
zhejiang hanzhou anhui hefei xiaoshan xiaohao anqian zheli guiyang
原理分析
利用mapReduce中map到reduce端的shuffle进行排序,MapReduce只能保证各个分区内部有序,但不能保证全局有序,于是我还自定义了分区,在map后、shuffle之前,我先将小于c的放在0分区,c-f的放在1分区,其余的放在2分区,这样,首先保证了分区与分区之间是整体有序,然后各个分区进行各自的shuffle,使其分区内部有序。
代码
package com.myhadoop.mapreduce.test;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
/**
* Created by kaishun on 2017/6/10.
*/
public class TotalSortTest extends Configured implements Tool{
public static class myMap extends org.apache.hadoop.mapreduce.Mapper<LongWritable, Text, Text, Text>{
public void map(LongWritable key,Text value,Context context) throws IOException,InterruptedException{
String[] split = value.toString().split("\\s+");
for (int i = 0; i <split.length ; i++) {
Text word = new Text(split[i]);
context.write(word,new Text(""));
}
}
}
public static class myReduce extends Reducer<Text,Text,Text,Text>{
public void reduce(Text key, Iterable<Text> values,Context context) throws IOException,InterruptedException
{
context.write(key, new Text(""));
}
}
public static class Partition extends Partitioner<Text,Text>{
@Override
public int getPartition(Text value1, Text value2, int i) {
if(value1.toString().compareTo("c")<0){
return 0;
}else if(value1.toString().compareTo("f")<0){
return 1;
}
return 2;
}
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(getConf());
job.setJarByClass(TotalSort.class);
job.setJobName("TotalSortTest");
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setPartitionerClass(Partition.class);
job.setMapperClass(myMap.class);
job.setReducerClass(myReduce.class);
job.setNumReduceTasks(3);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
boolean success = job.waitForCompletion(true);
return success ? 0:1;
}
public static void main(String[] args) throws Exception {
int ret = ToolRunner.run(new TotalSortTest(), args);
System.exit(ret);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
测试结果
生成了三个文件part-r-00000,part-r-00001,part-r-00002
各个分区之间有顺序,分区内部也有顺序,分别为
aa
ab
anhui
anqian
ba
bac
bb
beijing
df
dfa
dfga
dft
fdaf
fsf
gh
guilin
guiyang
hanzhou
hefei
hgg
huawei
ioo
jyzt
mingtong
nanning
qqq
rr
shanghai
shenzhen
ty
we
wuhan
xiaohao
xiaoshan
zhejiang
zheli
zks
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
总结
mapreduce的shuffle是对key值得hashcode进行排序的,所以单词的全排序也是一样的,类似于数据库中的order by 一样, 利用自定义分区,保证整体有序,利用mapreduce内部的shuffle,对key进行排序,保证了局部有序,从而实现了全排序























 1455
1455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









