







Region的大小
单个region最大大小官方推荐5~10GB,这是三备份前的数据大小,通过hbase.hregion.max.filesize配置,当超过这个值后region会split,估计好数据量并合理的划分region会减少不必要的性能损失。甚至设置足够大的值,日常监控中发现过大后手工做split。
Region 大小
Region的大小是一个棘手的问题,需要考量如下几个因素。
- Region是HBase中分布式存储和负载均衡的最小单元。不同Region分布到不同RegionServer上,但并不是存储的最小单元。
- Region由一个或者多个Store组成,每个store保存一个columns family,每个Strore又由一个memStore和0至多个StoreFile 组成。memStore存储在内存中, StoreFile存储在HDFS上。
- HBase通过将region切分在许多机器上实现分布式。也就是说,你如果有16GB的数据,只分了2个region, 你却有20台机器,有18台就浪费了。
- region数目太多就会造成性能下降,现在比以前好多了。但是对于同样大小的数据,700个region比3000个要好。
- region数目太少就会妨碍可扩展性,降低并行能力。有的时候导致压力不够分散。这就是为什么,你向一个10节点的HBase集群导入200MB的数据,大部分的节点是idle的。
- RegionServer中1个region和10个region索引需要的内存量没有太多的差别。
最好是使用默认的配置,可以把热的表配小一点(或者受到split热点的region把压力分散到集群中)。如果你的cell的大小比较大(100KB或更大),就可以把region的大小调到1GB。region的最大大小在hbase配置文件中定义:
<property>
<name>hbase.hregion.max.filesize</name>
<value>10 * 1024 * 1024 * 1024</value>
</property>说明:
- 当region中的StoreFile大小超过了上面配置的值的时候,该region就会被拆分,具体的拆分策略见下文。
- 上面的值也可以针对每个表单独设置,例如在hbase shell中设置:
create 't','f'
disable 't'
alter 't', METHOD => 'table_att', MAX_FILESIZE => '134217728'
enable 't'
实现原理
Bulkload过程主要包括三部分:
1、从数据源(通常是文本文件或其他的数据库)提取数据并上传到HDFS。抽取数据到HDFS和Hbase并没有关系,所以大家可以选用自己擅长的方式进行,本文就不介绍了。
2、利用MapReduce作业处理实现准备的数据 。这一步需要一个MapReduce作业,并且大多数情况下还需要我们自己编写Map函数,而Reduce函数不需要我们考虑,由HBase提供。该作业需要使用rowkey(行键)作为输出Key;KeyValue、Put或者Delete作为输出Value。MapReduce作业需要使用HFileOutputFormat2来生成HBase数据文件。为了有效的导入数据,需要配置HFileOutputFormat2使得每一个输出文件都在一个合适的区域中。为了达到这个目的,MapReduce作业会使用Hadoop的TotalOrderPartitioner类根据表的key值将输出分割开来。HFileOutputFormat2的方法configureIncrementalLoad()会自动的完成上面的工作。
3、告诉RegionServers数据的位置并导入数据。这一步是最简单的,通常需要使用LoadIncrementalHFiles(更为人所熟知是completebulkload工具),将文件在HDFS上的位置传递给它,它就会利用RegionServer将数据导入到相应的区域。
整个过程图如下:

代码实现
上面我们已经介绍了Hbase的BulkLoad方法的原理,我们需要写个Mapper和驱动程序,实现如下:
使用MapReduce生成HFile文件
|
|
驱动程序
|
|
通过BlukLoad方式加载HFile文件
|
|
由于Hbase的BulkLoad方式是绕过了Write to WAL,Write to MemStore及Flush to disk的过程,所以并不能通过WAL来进行一些复制数据的操作。后面我将会再介绍如何通过Spark来使用Hbase的BulkLoad方式来初始化数据。
BulkLoad的使用案例
1、首次将原始数据集载入 HBase- 您的初始数据集可能很大,绕过 HBase 写入路径可以显著加速此进程。
2、递增负载 - 要定期加载新数据,请使用 BulkLoad 并按照自己的理想时间间隔分批次导入数据。这可以缓解延迟问题,并且有助于您实现服务级别协议 (SLA)。但是,压缩触发器就是 RegionServer 上的 HFile 数目。因此,频繁导入大量 HFile 可能会导致更频繁地发生大型压缩,从而对性能产生负面影响。您可以通过以下方法缓解此问题:调整压缩设置,确保不触发压缩即可存在的最大 HFile 文件数很高,并依赖于其他因素,如 Memstore 的大小 触发压缩。
3、数据需要源于其他位置 - 如果当前系统捕获了您想在 HBase 中包含的数据,且因业务原因需要保持活动状态,您可从系统中将数据定期批量加载到 HBase 中,以便可以在不影响系统的前提下对其执行操作。
-----------------------------------------------------
不使用脚本的SQL Bulkload (hyperbase)
SQL BulkLoad步骤
SQL BulkLoad绕过 put API直接将数据写入表下的HFile中,避免了用 put API写数据的性能问题。
SQL BulkLoad的适用场景为:
• 初次原始数据导入。
• 增量数据导入。
本次操作使用tpcds生成2G数据中的store_sales表中的数据做测试。
(1) 将数据集上传至HDFS(该步骤可选)。
(2)在Inceptor Engine中建外表指向HDFS上的数据集。
drop table if exists store_sales;
create external table store_sales(
ss_sold_date_sk int,ss_sold_time_sk int,ss_item_sk int,ss_customer_sk int,ss_cdemo_sk int,ss_hdemo_sk int,ss_addr_sk int,ss_store_sk int,ss_promo_sk int,ss_ticket_number int,ss_quantity int,ss_wholesale_cost float,ss_list_price float,ss_sales_price float,ss_ext_discount_amt float,ss_ext_sales_price float,ss_ext_wholesale_cost float,ss_ext_list_price float,ss_ext_tax float,ss_coupon_amt float,ss_net_paid float,ss_net_paid_inc_tax float,ss_net_profit float
)
ROW FORMAT delimited fields TERMINATED BY '|' COLLECTION ITEMS TERMINATED BY '\001' MAP KEYS TERMINATED BY '\003'
LINES TERMINATED BY '\n' STORED AS TEXTFILE location '/user/beeline/tpcds/2/store_sales/';

(3)目标HBase表需要预分Region,如果你已知将要建的HBase表的Split Key,请转向(6),否则的话你需要通过采样来生成Split Key
(4)创建临时表,存放采样结果
create table sampleTable(ss_sold_date_sk int,ss_sold_time_sk int,ss_item_sk int,ss_customer_sk int,ss_cdemo_sk int,ss_hdemo_sk int,ss_addr_sk int,ss_store_sk int,ss_promo_sk int,ss_ticket_number int,ss_quantity int,ss_wholesale_cost float,ss_list_price float,ss_sales_price float,ss_ext_discount_amt float,ss_ext_sales_price float,ss_ext_wholesale_cost float,ss_ext_list_price float,ss_ext_tax float,ss_coupon_amt float,ss_net_paid float,ss_net_paid_inc_tax float,ss_net_profit float)
ROW FORMAT delimited FIELDS TERMINATED BY '|'
COLLECTION ITEMS TERMINATED BY '\001' MAP KEYS TERMINATED BY '\003'
LINES TERMINATED BY '\n' STORED AS TEXTFILE;
(5)通过采样找到splitkey
insert into table sampleTable select sample(8484,ss_sold_date_sk,ss_sold_time_sk,ss_item_sk,ss_customer_sk,ss_cdemo_sk,ss_hdemo_sk,ss_addr_sk,ss_store_sk,ss_promo_sk,ss_ticket_number,ss_quantity,ss_wholesale_cost,ss_list_price,ss_sales_price,ss_ext_discount_amt,
ss_ext_sales_price,ss_ext_wholesale_cost,ss_ext_list_price,ss_ext_tax,ss_coupon_amt,ss_net_paid,ss_net_paid_inc_tax,ss_net_profit) from store_sales;
说明:(1)sample函数中的8484=数据量(5760749)/97/region数(7)
(2)每个region大小按照1G估算,从而根据数据总大小确定出region数。

select mid from ( select max(c) as mid from ( select concat(ss_sold_date_sk) c, ntile(7) over (order by concat(ss_sold_date_sk)) nt from sqlbulkload.sampleTable ) group by nt) order by mid limit 6;

关于生成splitkey操作详细请参考SqlBulkLoad之SplitKey生成大法
(6)在Inceptor 中建HBase表的映射表,使用上一步计算出的Split Key预分Region。
drop table sqlbulkload_test;
create table sqlbulkload_test(
key struct<ss_sold_date_sk:int,uuid:bigint>,
ss_sold_date_sk int,ss_sold_time_sk int,ss_item_sk int,ss_customer_sk int,ss_cdemo_sk int,ss_hdemo_sk int,ss_addr_sk int,ss_store_sk int,ss_promo_sk int,ss_ticket_number int,ss_quantity int,ss_wholesale_cost float,ss_list_price float,ss_sales_price float,ss_ext_discount_amt float,ss_ext_sales_price float,ss_ext_wholesale_cost float,ss_ext_list_price float,ss_ext_tax float,ss_coupon_amt float,ss_net_paid float,ss_net_paid_inc_tax float,ss_net_profit float)
row format delimited FIELDS TERMINATED BY '|'
collection items terminated by '\001' MAP KEYS TERMINATED BY '\003'
LINES TERMINATED BY '\n'
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
tblproperties('hbase.table.splitkey'='2451078,2451328,2451545,2451845,2452152,2452387','COMPRESSION'='SNAPPY','hbase.table.name'='sqlbulkload_test');
(7)向hbase表导入数据
insert into table sqlbulkload_test select /*+USE_BULKLOAD*/ named_struct('ss_sold_date_sk',ss_sold_date_sk,'uuid',uniq()) ns_key ,ss_sold_date_sk int,ss_sold_time_sk int,ss_item_sk int,ss_customer_sk int,ss_cdemo_sk int,ss_hdemo_sk int,ss_addr_sk int,ss_store_sk int,ss_promo_sk int,ss_ticket_number int,ss_quantity int,ss_wholesale_cost float,ss_list_price float,ss_sales_price float,ss_ext_discount_amt float,ss_ext_sales_price float,ss_ext_wholesale_cost float,ss_ext_list_price float,ss_ext_tax float,ss_coupon_amt float,ss_net_paid float,ss_net_paid_inc_tax float,ss_net_profit float from store_sales order by ns_key;

----------------------------------------------------------------------------------
package HbaseBulkLoadTest;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2;
import org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
public class BULKLOAD {
static Logger logger = LoggerFactory.getLogger(BULKLOAD.class);
public static class MyMap extends Mapper<LongWritable,Text,ImmutableBytesWritable,Put>{
public void map(LongWritable key,Text value,Context context)
throws IOException,InterruptedException{
// key1 fm1:col1 value1
String[] valueStrSplit = value.toString().split("\t");
String hkey = valueStrSplit[0];
String family = valueStrSplit[1].split(":")[0];
String column = valueStrSplit[1].split(":")[1];
String hvalue = valueStrSplit[2];
final byte[] rowKey = Bytes.toBytes(hkey);
final ImmutableBytesWritable HKey = new ImmutableBytesWritable(rowKey);
Put HPut = new Put(rowKey);
byte[] cell = Bytes.toBytes(hvalue);
HPut.add(Bytes.toBytes(family), Bytes.toBytes(column), cell);
// MapReduce.Mapper.ConText
context.write(HKey, HPut);
}
}
public static void main (String args[])throws Exception{
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum","172.16.11.221,172.16.11.222,172.16.11.223");
conf.set("hbase.zookeeper.property.clientPort", "2800");
HTable hTable = new HTable(conf,"bulkloadtest");
Job job = Job.getInstance(conf,"bulkloadtest");
job.setJarByClass(BULKLOAD.class);
job.setMapperClass(MyMap.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(HFileOutputFormat2.class);
String inPath = "hdfs://Machenmaster/hbase/BKLDTest/data.txt"; //本人是 hadoop HA 模式 所以这里不是 host:9000
logger.info("jjjjjjjjjjjjjjj"+ inPath);
String hfilePath = "hdfs://Machenmaster/hbase/BKLDTest/bkldOutPut";
FileInputFormat.addInputPath(job,new Path(inPath));
FileOutputFormat.setOutputPath(job,new Path(hfilePath));
HFileOutputFormat2.configureIncrementalLoad(job,hTable);
job.waitForCompletion(true);
LoadIncrementalHFiles load = new LoadIncrementalHFiles(conf);
load.doBulkLoad(new Path(hfilePath),hTable);
hTable.close();
}
hdfs 中的数据:

PS:原来只有data.txt 上面那个目录 是在代码执行后生成的:
data,txt 内容: (就用网上一哥们写的来吧)
key1 fm1:col1 value1
key1 fm1:col2 value2
key1 fm2:col1 value3
key4 fm1:col1 value4
3 创建表:
hbase shell中进行建表:
hbase(main):004:0> create 'bulkloadtest','fm1','fm2'
4 打包方式:win10 IDEA maven
打包生成文件 (打包后上传到linux集群中):
[root@slaver3 share]# ls
doc hadoop HbaseForMe-1.0-SNAPSHOT.jar
[root@slaver3 share]# ^C
[root@slaver3 share]#
5 执行代码:
[root@slaver3 share]# hadoop jar HbaseForMe-1.0-SNAPSHOT.jar
6 截取部分图片:


7. hdfs 查看:

8 查看hbase 中的表:
hbase(main):004:0> scan 'bulkloadtest'
ROW COLUMN+CELL
key1 column=fm1:col1, timestamp=1522060321677, value=value1
key1 column=fm1:col2, timestamp=1522060321677, value=value2
key1 column=fm2:col1, timestamp=1522060321677, value=value3
key4 column=fm1:col1, timestamp=1522060321677, value=value4
2 row(s) in 0.1000 seconds
hbase(main):005:0>
---------------------------------------------------------------------------------------------------------------------------------
hbase复制的状态都存储在zookeeper中,默认情况下存储到 /hbase/replication,这个目录有三个子节点: peers znode、rs znode和state。peer 节点管理slave集群在zk上的配置;state节点记录replication运行的状态;rs 节点记录着本集群rs中对应的hlog同步的信息,包括check point信息。(如果人为的删除 /hbase/replication 节点,会造成复制丢失数据)
peers znode:
存储在 zookeeper中/hbase/replication/peers 目录下,这里存储了所有的replication peers,还有他们的状态。peer的值是它的cluster的key,key包括了cluster的信息有: zookeeper,zookeeper port以及hbase在hdfs的目录。
/hbase/replication/peers
/1 [Value: zk1.host.com,zk2.host.com,zk3.host.com:2181:/hbase]
/2 [Value: zk5.host.com,zk6.host.com,zk7.host.com:2181:/hbase]
每个peer都有一个子节点,标示replication是否激活,这个节点没有任何子节点,只有一个boolean值。
/hbase/replication/peers
/1/peer-state [Value: ENABLED]
/2/peer-state [Value: DISABLED]
rs znode:
rs node包含了哪些WAL是需要复制的,包括:rs hostname,client port以及start code。
/hbase/replication/rs
/hostname.example.org,6020,1234
/hostname2.example.org,6020,2856
每一个rs znode包括一个WAL replication 队列,
/hbase/replication/rs
/hostname.example.org,6020,1234
/1
/2
[说明] hostname.example.org的start code为1234的wal需要复制到peer 1和peer 2。
每一个队列都有一个znode标示每一个WAL上次复制的位置,每次复制的时候都会更新这个值。
/hbase/replication/rs
/hostname.example.org,6020,1234
/1
23522342.23422 [VALUE: 254]
12340993.22342 [VALUE: 0]
二、replication的配置部署
1. 准备
既然是集群间的备份那么我们至少需要准备两个HBase集群来进行试验,并且需要满足:
- 集群间版本需要一致
- 集群间服务器需要互通
- 相关表及表结构在两个集群上存在且相同
2.启用replication步骤
1> HBase默认此特性是关闭的,需要在集群上(所有集群)进行设定并重启集群,通过手动修改或ambari界面管理在hbase-site.xml配置文件中将hbase.replication参数设定为true。
【参考】
master集群配置文件
<property>
<name>hbase.replication</name>
<value>true</value>
<description> 打开replication功能</description>
</property>
<property>
<name>replication.source.nb.capacity</name>
<value>5000</value>
<description> 主集群每次像备集群发送的entry最大的个数,推荐5000.可根据集群规模做出适当调整,slave集群服务器如果较多,可适当增大</description>
</property>
<property>
<name>replication.source.size.capacity</name>
<value>4194304</value>
<description> 主集群每次像备集群发送的entry的包的最大值大小,不推荐过大</description>
</property>
<property>
<name>replication.source.ratio</name>
<value>1</value>
<description> 主集群里使用slave服务器的百分比</description>
</property>
<property>
<name>hbase.regionserver.wal.enablecompression</name>
<value>false</value>
<description> 主集群关闭hlog的压缩</description>
</property>
<property>
<name> replication.sleep.before.failover</name>
<value>5000</value>
<description> 主集群在regionserver当机后几毫秒开始执行failover</description>
</property>
slave 集群配置文件
<property>
<name>hbase.replication</name>
<value>true</value>
<description> 打开replication功能</description>
</property>
2>在主/源集群上和从/目标集群上都新建表:
create 'usertable', 'family'
3>在主集群上设定需要向哪个集群上replication数据
add_peer:增加一个slave集群,一旦add,那么master集群就会向这个slave集群上replication那些在master集群上表列族制定了REPLICATION_SCOPE=>'1'的信息。
[Addpeer] hbase> add_peer '1',"zk1,zk2,zk3:2182:/hbase-prod" (zk的地址,端口和Slave的zk address)
示例:add_peer '1','xufeng-1:2181:/hbase_backup' //重要
#set_peer_tableCFs '1','usertable'
4>在主集群上打开表student的复制特性
disable 'usertable'
alter 'usertable',{NAME => 'family',REPLICATION_SCOPE => '1'} //重要
enable 'usertable'
5>测试replication功能
//上面配置好replication功能后,执行此三条命令会发现slave集群相应的跟着发生了相同变化
put 'usertable','row1','family:info','zzzz'
scan 'usertable',{STARTROW=>'row1',ENDROW=>'row1'}
delete 'usertable','row1','family:info'
6>附:相关命令
shell环境为我们提供了很多方法去操作replication特性。
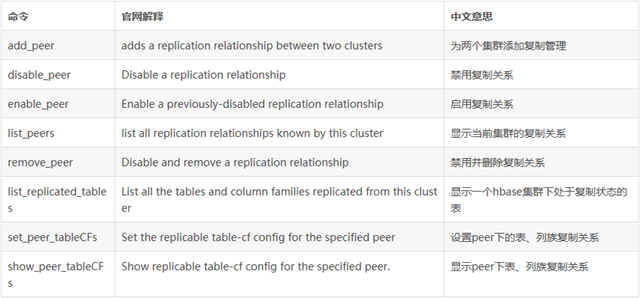
set_peer_tableCFs:重新设定想slave集群replication哪些表的哪些列族,只对列族REPLICATION_SCOPE=>'1'有效
show_peer_tableCFs:观察某个slave集群上呗replication的表和列族信息
append_peer_tableCFs:与set_peer_tableCFs相比是增量设定,不会覆盖原有信息。
remove_peer_tableCFs:与append_peer_tableCFs操作相反。
list_replicated_tables:列出在master集群上所有设定为REPLICATION_SCOPE=>'1'的信息
list_peers:显示当前master集群一共向哪些集群进行replication
hbase(main):009:0> list_peers
PEER_ID CLUSTER_KEY STATE TABLE_CFS
1 xufeng-1:2181:/hbase_backup ENABLED
1 row(s) in 0.0110 seconds
disable_peer:停止向某个slave集群进行replication
hbase(main):010:0> disable_peer '1'
0 row(s) in 0.0110 seconds
hbase(main):011:0> list_peers
PEER_ID CLUSTER_KEY STATE TABLE_CFS
1 xufeng-1:2181:/hbase_backup DISABLED
1 row(s) in 0.0070 seconds
enable_peer:与disable_peer意义相反
hbase(main):031:0> enable_peer '1'
0 row(s) in 0.0070 seconds
hbase(main):032:0> list_peers
PEER_ID CLUSTER_KEY STATE TABLE_CFS
1 xufeng-1:2181:/hbase_backup ENABLED
1 row(s) in 0.0080 seconds
三、运维经验及遇到的问题
- replication不会根据实际插入的顺序来进行,只保证和master集群最终一致性。
- 所有对于replication的shell操作,只对列族为REPLICATION_SCOPE=>'1'才有效。
- 如果写入量较大,Slave 集群必须做好table 的region提前分配,防止写入全部落入1台服务器。
- 暂停服务和重新服务期间的数据还是可以被同步到slave中的,而停止服务和启动服务之间的数据不会被同步。也即同步是针对配置replication后复制的新数据,旧数据需要手动迁移
- 主集群对于同步的数据大小和个数采用默认值较大,容易导致备集群内存被压垮。建议配置减少每次同步数据的大小
replication.source.size.capacity4194304
replication.source.nb.capacity2000
- replication目前无法保证region级别的同步顺序性。需要在slave 集群需要打开KEEP_DELETED_CELLS=true,后续可以考虑在配置检测到属于slave集群就直接把这个值打开
- stop_replication后再start_replication,如果当前写的hlog没有滚动,停止期间的日志会被重新同步过去,类似的如果stop replication后进行了rollhlog操作(手动或重启集群),重新startreplication,新写入的数据不能被马上动态同步过去,需要再rollhlog一次。
- replication.source.ratio 默认值为0.1,这样导致slave集群里只有10%对外提供转发服务,导致这一台压力过大,建议测试环境将此值改为1。
- 目前replication 对于压缩的hlog的wal entry 无法解析,导致无法同步配置压缩hlog 集群的数据。这是有数据字典引起的,目前建议主集群中的配置hbase.regionserver.wal.enablecompression设false。
- 不要长时间使得集群处于disable状态,这样hlog会不停的roll后在ZK上增加节点,最终使得zk节点过多不堪重负。















 399
399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









