







一、环境准备
CentOS-6.4-x86_64-minimal.iso
jdk-6u45-linux-i586-rpm.bin
zookeeper-3.4.5.tar
solr-4.6.0.zip
服务器6台: 192.168.56.11- SolrCloud.Shard1.Leader
192.168.56.12-SolrCloud.Shard2.Leader
192.168.56.13-SolrCloud.Shard3.Leader
192.168.56.14-SolrCloud.Shard1.Replica
192.168.56.15-SolrCloud.Shard2.Replica
192.168.56.16-SolrCloud.Shard3.Replica
二、环境安装
1、CentOs 6.4安装
1)配制用户
安装完后配制用户solrcloud 密码: solrcloud
[root@localhost ~]# useradd solrcloud
[root@ localhost ~]# passwd solrcloud
2)修改当前机器名称
vi etc/sysconfig/network
HOSTNAME=SolrCloud.Shard1.Leader
3)修改当前机器ip
vi /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE=eth0
HWADDR=08:00:27:5C:8C:BD
TYPE=Ethernet
UUID=4fc0a398-f82b-49e5-8657-27bf5b260444
ONBOOT=yes
NM_CONTROLLED=yes
IPADDR=192.168.56.11
NETMASK=255.255.255.0
重启服务 service network restart
4)上传安装包(工具上传WinSCP)
创建文件夹 mkdir /solrcloud
赋写权限 chmod 777 /solrcloud
上传所需安装软件包到/solrcloud
2、jdk安装
默认jdk安装会报错,64位系统安装32位jdk报的错

需要安装glic , yum install glibc.i686
安装完后再安装jdk 进入/solrcloud目录
./jdk-6u45-linux-i586-rpm.bin
3、zookeeper集群安装
(集群安装测试时以ip为例说明,正式上线后可以配主机名称)
1)解压zookeeper 安装包
tar -zxvf zookeeper-3.4.5.tar.gz
2)进入zookeeper-3.4.5文件夹,创建data 和log
创建目录并赋于写权限
指定zookeeper的数据存放目录和日志目录
3)拷贝zookeeper配制文件zoo_sample.cfg
拷贝zookeeper配制文件zoo_sample.cfg并重命名zoo.cfg
cp /solrcloud/zookeeper-3.4.5/conf/zoo_sample.cfg /solrcloud/zookerper-3.4.5/conf/zoo.cfg
4)修改zoo.cfg
加入 dataDir=/solrcloud/zookeeper-3.4.5/data
dataLogDir=/solrcloud/zookeeper-3.4.5/log
server.1=192.168.56.11:2888:3888
server.2=192.168.56.12:2888:3888
server.3=192.168.56.13:2888:3888
server.4=192.168.56.14:2888:3888
server.5=192.168.56.15:2888:3888
server.6=192.168.56.16:2888:3888
zoo.cfg配制完后如下:
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/solrcloud/zookeeper-3.4.5/data
dataLogDir=/solrcloud/zookeeper-3.4.5/log
# the port at which the clients will connect
clientPort=2181
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=192.168.56.11:2888:3888
server.2=192.168.56.12:2888:3888
server.3=192.168.56.13:2888:3888
server.1=192.168.56.11:2888:3888
server.2=192.168.56.12:2888:3888
server.3=192.168.56.13:2888:3888
server.4=192.168.56.14:2888:3888
server.5=192.168.56.15:2888:3888
server.6=192.168.56.16:2888:3888
5)进入data文件夹 建立对应的myid文件
例如server.1=192.168.56.11 data文件夹下的myid文件内容为1
6)制zookeeper-3.4.5文件夹到其他机器
7)开启zookeeper的端口
/sbin/iptables -I INPUT -p tcp --dport 2181 -j ACCEPT
/sbin/iptables -I INPUT -p tcp --dport 2888 -j ACCEPT
/sbin/iptables -I INPUT -p tcp --dport 3888 -j ACCEPT
/sbin/iptables -I INPUT -p tcp --dport 8080 -j ACCEPT --顺便启用tomcat 8080端口
/etc/rc.d/init.d/iptables save #将更改进行保存
/etc/init.d/iptables restart #重启防火墙以便改动生效
8)启动zookeeper
进入bin
./zkServer.sh start
查看集群状态
./zkServer.sh status 刚启动可能会有错误,集群中其他节点一并起来后就正常了
4、solr集群安装
1)在solrcloud下新建solrhome,并赋于读写权限
2)将上传的solr.4.6.0压缩包解压缩,
tar -zxvf solr-4.6.0.tgz
3)将solr.4.6.0/dist/solr-4.6.0.war 复制到/solrcloud/solrhome 并重命为solr.war
cp /solrcloud/solr-4.6.0/dist/solr-4.6.0.war /solrcloud/solrhome/solr.war
4)将上传的tomcat解压缩
tar -zxvf apache-tomcat-6.0.29.tar.gz
5)进入tomcat bin目录,启动tomcat
cd /solrcloud/apache-tomcat-6.0.29/bin 进入bin目录
./startup.sh 启动tomcat 此时会在tomcat下的conf文件夹下多出一个目录Catalina
cd /solrcloud/apache-tomcat-6.0.29/conf/Catalina/localhost
新建solr.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8" ?>
<Context docBase="/solrcloud/solrhome/solr.war" debug="0" crossContext="false" >
<Environment name="solr/home"
type="java.lang.String"
value="/solrcloud/solrhome"
override="true" />
</Context>
docBase="/solrcloud/solrhome/solr.war" 指定为solrcloud/solrhome下复制出来solr的war包
6)停tomcat 再次启动tomcat, webapps 下边多了解压出来的solr文件夹
进入solr/WEB-INF/ 下修改web.xml
<!--
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>/put/your/solr/home/here</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
-->
改为 :
<env-entry>
<env-entry-name>solr/home</env-entry-name>
<env-entry-value>/solrcloud/solrhome</env-entry-value>
<env-entry-type>java.lang.String</env-entry-type>
</env-entry>
7)将/solrcloud/solr-4.6.0/example/solr 文件夹下所有东西复制到 /solrcloud/solrhome
cp -r /solrcloud/solr-4.6.0/example/solr/* /solrcloud/solrhome
8)复制solr-4.6.0/example/lib/ext下所有jar包到tomcat 的lib下
cp /solrcloud/solr-4.6.0/example/lib/ext/* /solrcloud/apache-tomcat-6.0.29/lib/
复制 solr-4.6.0/example/resources/log4j.properties 到solr/WEB-INF/class
如果没有class先创建class文件夹,并赋于写权限
cp /solrcloud/solr-4.6.0/example/resources/log4j.properties /solrcloud/apache-tomcat-6.0.29/webapps/solr/WEB-INF/class/
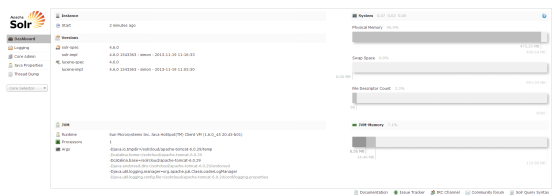
9)启动tomcat 访问 http://localhost:8080/solr 如图,至此单机版solr配制完成
10)配制集群
将zookeeper和tomcat关联
192.168.56.11台机修改tomcat 的 bin目录下catalina.sh文件在第二行加入
JAVA_OPTS="-Dbootstrap_confdir=/solrcloud/solrhome/collection1/conf -Dcollection.configName=myconf -DzkHost=192.168.56.11:2181,192.168.56.12:2181,192.168.56.13:2181,192.168.56.14:2181,192.168.56.15:2181,192.168.56.16:2181 -DnumShards=3"
192.168.56.12-16 , 5台机都修改tomcat 的 bin目录下catalina.sh文件在第二行加入
JAVA_OPTS="-DzkHost=192.168.56.11:2181,192.168.56.12:2181,192.168.56.13:2181,192.168.56.14:2181,192.168.56.15:2181,192.168.56.16:2181"
至此集群配制完毕
创建集合
http://192.168.56.11:8080/solr/admin/collections?action=CREATE&name=guangzhou&numShards=3&replicationFactor=3
任何一个ip均可访问
http://192.168.56.11:8080/solr/#/~cloud

Solr5.5.4+Zookeeper3.4.6+Tomcat8搭建SolrCloud集群
SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud。当一个系统的索引数据量少的时候是不需要使用SolrCloud的,当索引量很大,搜索请求并发很高,这时需要使用SolrCloud来满足这些需求。SolrCloud 是基于Solr和Zookeeper的分布式搜索方案,具体拥有以下几个特色功能:
1)集中式的配置信息
2)自动容错
3)近实时搜索
4)查询时自动负载均衡
SolrCloud在搭建时,通过先搭建完一个Solr实例后,可以很容易地使用Zookeeper来做一个集群。我演示的安装步骤基于一台机器,所以采用伪集群的方式进行安装,如果是真正的生成环境,将伪集群的ip改下就可以了,步骤是一样的。
安装准备
- JDK1.7以上
- Solr5.5.4部署包(solr-5.5.4.tgz 大约130M)
- Tomcat8部署包 (apache-tomcat-8.5.16.tar.gz)
- zookeeper-3.4.6部署包(zookeeper-3.4.6.tar.gz)
Solr5.5.4单机部署与Tomcat8
你可以在Solr5.5.4单机部署找到如何将Solr5.5.4部署在Tomcat8环境下.
Solr5.5.4+Zookeeper3.4.6+Tomcat8集群部署
如果已经成功部署了一个Solr,那么接下来的工作也不会太难。下面的集群部署基于已经成功部署过单个Solr。如果你还没有部署过Solr或者还没有部署过单机版的,讲义看一下Solr5.5.4单机部署里面第二部分,通过tomcat部署Solr,然后再来部署集群。
具体zookeeper集群部署我在这里就不讲啦,如果不会部署zookeeper集群的可以看一下看一下zookeeper集群部署。本次部署详情信息如下:
| 机器 | 192.168.219.11(node11),192.168.219.12(node12),192.168.219.13(node13),192.168.219.14(node14) |
| 系统 | Red Hat Enterprise Linux Server release 6.5 (Santiago) |
| 系统内核 | 2.6.32-358.el6.x86_64 |
| solr版本 | Solr-5.5.4 |
| zookeeper版本 | 3.4.6 |
| zookeeper地址(ip:port) | node11:2282,node12:2282,node13:2282 |
| tomcat版本 | 8.5.16 |
| solr+tomcat地址 | /home/anu/tomcat8 |
| solr_home(core)地址 | /home/anu/tomcat8/solr_home, node11:8888(leader),node12:8888(follower),node13:8888(follower),node14:8888(follower) |
1、我早之前已经在一台机器上那装过单机的Solr(鄙人是在node11机器上安装的,通过tomcat+Solr实现,放在tomcat8中),所以直接来改动它里面的配置就可以啦。
2、为了保证端口不冲突,我们来改一下tomcat端口还有Solr端口

修改./tomcat8/conf/server.xml,将下面几个地方的端口尽量改动一下不要和别的地方冲突

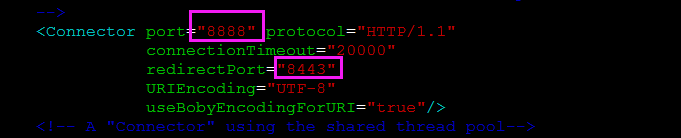

这些地方本人已经改过啦,注意上面那个8888端口是tomcat发布端口,这个后面要用到,需要设置成Solr端口
3、配置tomcat8的启动项,配置zookeeper和各个tomcat进行关联:首先确定leader节点,本人使用node11作为leader,其余的作为follower,现在先配置leader的tomcat目录下(我的是tomcat8)的bin/catalina.sh中的最上面添加一行

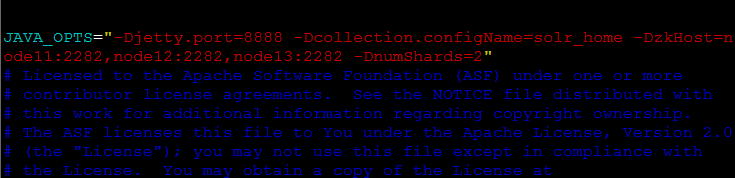
| JAVA_OPTS="-Djetty.port=8888 -Dbootstrap_confdir=/home/anu/tomcat8/solr_home/ustcinfo/conf -Dcollection.configName=solr_home -DzkHost=node11:2282,node12:2282,node13:2282 -DnumShards=2" |
8888:必须要和我们上面配置的tomcat端口一致,
/home/anu/tomcat8/solr_home/ustcinfo/conf:这个是我的Solr_home 的路径,这个下面我们单机安装的时候已经说了这个的由来,下面马上我再说一下
solr_home:是我的solr_home名字,可以随便取,但是尽量和你的solr_home文件名一样,便于查看
node11:2282,node12:2282,node13:2282:这是我的zookeeper集群,前面已经安装并且已经启动
2:表示有两个shard节点
下面大致解释一下这些参数含义:
- -Djetty.port Solr的发布端口,需要和tomcat端口一致,使用jetty.port是响应Solr内部jetty关联
- -Dbootstrap_confdir ZooKeeper需要准备一份集群配置的副本,这个参数是告诉SolrCloud这些配置是放在哪里,同时作为整个集群共用的配置文件。
- -Dcollection.configName 指定你的配置文件上传到zookeeper后的名字,建议和你所上传的核心名字一致,这样容易识别。
- -DzkRun 在Solr中启动一个内嵌的zooKeeper服务器,该服务会管理集群的相关配置。
- -DzkHost 跟上面参数的含义一样,允许配置一个ip和端口来指定用哪个Zookeeper服务器进行协调。
- -DnumShards=2 配置需要把你的数据分开到多少个shard中
- -Dbootstrap_conf=true 将会上传solr/home里面的所有数据到zookeeper的home/data目录,也就是所有的core将被集群管理,本次我未使用这个参数。
这里面配好之后,我们再说说我配置的Solr_home路径由来。
首先,我们在单机中已经将./solr-5.5.4/server/solr 下面所有的东西都拷贝到./tomcat8/solr_home目录下。我们进入到./tomcat/sole_home 目录下

其次,在这个路径下新建一个作为core使用的文件夹,名字可以随意起,鄙人创建名字为ustcinfo的文件夹
然后将./tomcat8/solr_home/configsets/basic_configs 目录下的所有文件都拷贝到我们刚刚新建的ustcinfo 下面
mkdir ustcinfo
cp -r configsets/basic_configs/* ustcinfo/
cd ustcinfo/
ls
cd conf
pwd

![]()
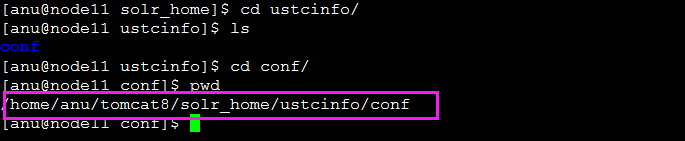
在这就可以看到我们配置的Solr_home地址,用于后面同一创建Solr集合识别core使用。
特别需要注意:上面添加JAVA_OPTS时针对leader节点的,其余三台机器的JAVA_OPTS如下:
JAVA_OPTS="-Djetty.port=8888 -Dcollection.configName=solr_home -DzkHost=node11:2282,node12:2282,node13:2282 -DnumShards=2"
这个配置后面会提到
4、修改solr.xml的jetty.port参数值为tomcat的端口
打开./tomcat8/solr_home/solr.xml 文件,修改jetty.port参数值为tomcat的端口(即我们前面配置的8888)

5、将配置好的tomcat+solr拷贝到其他三台机器node12、node13、node14,
scp -r tomcat8 anu@node12:/home/anu/
scp -r tomcat8 anu@node13:/home/anu/
scp -r tomcat8 anu@node14:/home/anu/
6、修改其他三台follower的tomcat8启动项,
分别进入node12、node13、node14机器,通过vim tomcat8/bin/catalina.sh 打开catalina.sh文件,将tomcat启动项的 -Dbootstrap_confdir=/home/anu/tomcat8/solr_home/ustcinfo/conf 删掉,最终JAVA_OPTS参数如下
JAVA_OPTS="-Djetty.port=8888 -Dcollection.configName=solr_home -DzkHost=node11:2282,node12:2282,node13:2282 -DnumShards=2"
7、分别启动4台机器的tomcat8+Solr
使用命令tomcat8/bin/catalina.sh start 或者tomcat8/bin/startup.sh 启动四台tomcat8
8、通过访问页面查看Sole配置
在浏览器中打开http://192.168.219.11:8888/solr/index.html#/,进入后点击左边导航栏的cloud查看

Java操作solrCloud
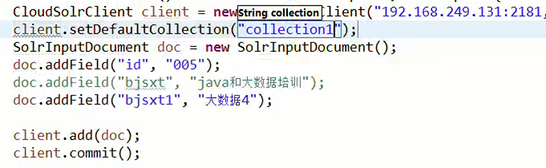
在java中操作solrCloud和操作solr一样,都是通过solrJ,只不过初始化solrServer对象时有点不同:
简单示例:
@Test
public void testAddDocument() throws Exception {
// zkHost:zookeeper的地址列表
String zkHost = "192.168.25.130:2181,192.168.25.130:2182,192.168.25.130:2183";
// 创建一个集群的连接,应该使用CloudSolrServer创建
CloudSolrServer solrServer = new CloudSolrServer(zkHost);
// 设置一个defaultCollection属性
solrServer.setDefaultCollection("collection2");
// 创建一个文档对象
SolrInputDocument document = new SolrInputDocument();
// 向文档中添加域
document.setField("id", "solrCloud01");
document.setField("item_title", "测试商品01");
document.setField("item_price", 123);
// 把文件内容写入索引库
solrServer.add(document);
// 提交
solrServer.commit();
}
测试结果:

如果要在Spring中使用集群版本solr,配置如下:
该配置和单机版的配置同时只能存在一份,不然会报不唯一异常!
<!-- 集群版solrJ,参数为zookeeper的地址列表 -->
<bean id="cloudSolrServer" class="org.apache.solr.client.solrj.impl.CloudSolrServer">
<constructor-arg index="0" value="192.168.25.130:2181,192.168.25.130:2182,192.168.25.130:2183"/>
<property name="defaultCollection" value="collection2"/>
</bean>
然后在代码中通过:
@Autowired
private SolrServer solrServer;
自动注入即可使用,注入后的使用方法和单机版的是一样的。
----------------------------------------------------------------------------------------------------------------------------------------------------------------
solr整合Hbase

1.下载HBaseIndexer 项目:
官网:http://ngdata.github.io/hbase-indexer/
github:https://github.com/NGDATA/hbase-indexer
wiki(配置说明):https://github.com/NGDATA/hbase-indexer/wiki
sep tools cli说明(状态监控):https://github.com/NGDATA/hbase-indexer/tree/master/hbase-sep/hbase-sep-tools
获取HBase索引器
查看代码并构建tar.gz发行版。
git clone git://github.com/NGDATA/hbase-indexer.git
mvn clean package -Pdist -DskipTests
接下来,解压缩tar.gz发行版(在下面的示例中,它在$ HOME目录下解压缩)。
tar zxvf hbase-indexer-dist/target/hbase-indexer-1.0-SNAPSHOT.tar.gz -C ~
cd ~/hbase-indexer-1.0-SNAPSHOT
配置HBase Indexer
在hbase-indexer目录中,编辑文件conf/hbase-indexer-site.xml并配置ZooKeeper连接字符串(两次,一次用于hbase-indexer,一次用于hbase,或者您可以复制hbase-site.xml到conf目录)。
<property>
<name>hbaseindexer.zookeeper.connectstring</name>
<value>zookeeperhost</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>zookeeperhost</value>
</property>
如果您尚未全局定义JAVA_HOME,并且bin / hbase-indexer脚本会抱怨它找不到Java,则可以在脚本中设置JAVA_HOME conf/hbase-indexer-env.sh。
配置HBase
要使用HBase Indexer,必须在HBase中启用复制。还可以设置许多其他HBase设置以优化HBase索引器的工作。
将以下设置添加到所有HBase区域服务器上的hbase-site.xml配置中,然后重新启动HBase。
<configuration>
<!-- SEP is basically replication, so enable it -->
<property>
<name>hbase.replication</name>
<value>true</value>
</property>
<!-- Source ratio of 100% makes sure that each SEP consumer is actually
used (otherwise, some can sit idle, especially with small clusters) -->
<property>
<name>replication.source.ratio</name>
<value>1.0</value>
</property>
<!-- Maximum number of hlog entries to replicate in one go. If this is
large, and a consumer takes a while to process the events, the
HBase rpc call will time out. -->
<property>
<name>replication.source.nb.capacity</name>
<value>1000</value>
</property>
<!-- A custom replication source that fixes a few things and adds
some functionality (doesn't interfere with normal replication
usage). -->
<property>
<name>replication.replicationsource.implementation</name>
<value>com.ngdata.sep.impl.SepReplicationSource</value>
</property>
</configuration>
将索引器jar添加到HBase
HBase Indexer包含两个需要位于HBase类路径中的jar文件。将这些从解压缩的hbase-indexer安装的lib目录复制到每个区域服务器的HBase的lib目录中。
cp lib/hbase-sep-* $HBASE_HOME/lib
启动Solr
确保Solr正在运行。通常,让Solr使用与HBase相同的ZooKeeper实例是最简单的。
假设您已经下载了Solr 4.2.0并且您在当前计算机上运行ZooKeeper,则可以使用示例模式在云模式下启动基本Solr,如下所示:
cd $SOLR_HOME/example
java -Dbootstrap_confdir=./solr/collection1/conf -Dcollection.configName=myconf -DzkHost=localhost:2181/solr -jar start.jar
启动HBase Indexer守护程序
在终端中,执行以下操作(假设$ INDEXER_HOME指向解压缩hbase-indexer tar.gz发行版的目录)。
cd $INDEXER_HOME
./bin/hbase-indexer server
创建一个要在HBase中建立索引的表
在HBase shell中,创建一个表。在本教程中,我们将创建一个名为“indexdemo-user”的表,其中包含一个名为“info”的列族。请注意,表的列族的REPLICATION_SCOPE必须设置为1。
$ hbase shell
hbase> create 'indexdemo-user', { NAME => 'info', REPLICATION_SCOPE => '1' }
添加索引器
现在我们将创建一个索引器,它将索引indexdemo-user表,因为它的内容已更新。
在您喜欢的文本编辑器中,创建一个名为indexdemo-indexer.xml的新xml文件,其中包含以下内容:
<?xml version="1.0"?>
<indexer table="indexdemo-user">
<field name="firstname_s" value="info:firstname"/>
<field name="lastname_s" value="info:lastname"/>
<field name="age_i" value="info:age" type="int"/>
</indexer>
上面的文件定义了三条信息,这些信息将用于索引,如何解释它们以及它们将如何存储在Solr中。
接下来,根据创建的索引器xml文件创建索引器。
./bin/hbase-indexer add-indexer -n myindexer -c indexdemo-indexer.xml \
-cp solr.zk=localhost:2181/solr -cp solr.collection=collection1
请注意,上面的命令假设ZooKeeper在端口2181上的localhost上运行,并且配置了名为“collection1”的Solr Core。如果您在现有的HBase / Solr环境中执行本教程,则可能需要使用不同的设置。
更新表格内容
在HBase shell中,尝试将一些数据添加到indexdemo-user表中
hbase> put 'indexdemo-user', 'row1', 'info:firstname', 'John'
hbase> put 'indexdemo-user', 'row1', 'info:lastname', 'Smith'
添加此数据后,请查看Solr(即http:// localhost:8983 / solr /#/ collection1 / query)。您应该在Solr中看到一个文档,其firstname_s字段设置为“John”,lastname_s字段设置为“Smith”。
注意如果在Solr中未启用autoCommit,则无法立即在Solr中看到更新的内容。演示环境每秒都会为提交启用autoCommit。
方法很简单:找到solrConfig.xml文件
找到以下行,并增加以下配置
<updateHandler class="solr.DirectUpdateHandler2">
<autoCommit>
<maxDocs>10000</maxDocs>
<maxTime>300000</maxTime>
</autoCommit>
说明:
maxDocs:当内存索引数量达到指定值的时候,将内存的索引DUMP到硬盘中,并通知searcher类加载新的索引。
maxTime:每隔指定的时间段,自动的COMMIT内存中的索引数据,并通知Searcher类加载新的索引。
以上两种方式,以最先达到条件执行为准。
现在尝试更新刚刚添加的数据
hbase> put 'indexdemo-user', 'row1', 'info:firstname', 'Jim'
现在检查Solr中的内容。文档的firstname_s字段现在包含字符串“Jim”。
最后,从HBase中删除该行。
hbase> deleteall 'indexdemo-user', 'row1'
您现在可以验证数据是否已从Solr中删除。
--------------------------------------------------------------------------
索引器配置
最基本的索引器配置只需要一个表名和一个字段。但是,有许多配置设置可用于索引器配置文件以自定义行为。
<indexer table="mytable">
<field name="fieldname" value="columnfamily:qualifier" type="string"/>
</indexer>
全局索引器属性
以下是可以在索引器配置中的顶级<indexer>元素上设置的属性列表。
表
table属性指定索引器要索引的HBase表的名称。它是索引器元素中唯一的必需属性。
映射型
mapping-type属性有两个可能的值:row或column。此属性指定是要执行基于行的索引还是基于列的索引。
基于行的索引将单个HBase行中的所有数据视为Solr中单个文档的输入。这是一种用于HBase表的索引,该表在每行中包含一个单独的实体,例如包含用户的表。
基于列的索引将每个HBase单元视为Solr中单个文档的输入。该方法可以用于例如消息传送平台中,其中单个用户的消息全部存储在单个行中,每个消息存储在单独的单元中。
默认的映射类型值是row。
读行
read-row属性有两个可能的值:dynamic或never。
只有在使用基于行的索引时,此属性才有用。它指定索引器是否应重新读取HBase中的数据以执行索引。
设置为“dynamic”时,如果在HBase中执行对行的部分更新,则索引器将从行中读取必要的数据。在动态模式下,如果行更新中包含执行索引所需的所有数据,则不会重新读取该行。
如果此属性设置为never,则索引器将永远不会重新读取该行。
默认设置为“动态”。
映射器
mapper属性允许用户指定一个自定义映射器类,该类将从HBase Result对象创建Solr文档。mapper类必须实现该com.ngdata.hbaseindexer.parse.ResultToSolrMapper接口。
默认情况下,使用内置com.ngdata.hbaseindexer.parse.DefaultResultToSolrMapper。
独特琴键格式化
unique-key-formatter属性指定用于将HBase行键(以及列族和列限定符)格式化为文本的类的名称。Solr中需要索引这些信息的文本表示,因为Solr中的所有数据都是文本的,但行键,列族和列限定符是字节数组。
unique-key-formatter类必须实现该com.ngdata.hbaseindexer.uniquekey.UniqueKeyFormatter接口。
此属性的默认值为com.ngdata.hbaseindexer.uniquekey.StringUniqueKeyFormatter。StringUniqueKey格式化程序只是将行键和其他字节数组视为字符串。
如果您的行键,列族或限定符不能简单地用作字符串,请考虑使用com.ngdata.hbaseindexer.uniquekey.HexUniqueKeyFormatter。
唯一键字段
此属性指定Solr中使用的文档标识符字段的名称。
该字段的默认值为“id”。
行场
row-field属性指定用于存储HBase行键的Solr字段的名称。
此字段仅在执行基于列的索引时很重要。为了使索引器能够从索引中删除单行的所有文档,它需要能够在Solr中找到该行的所有文档。在索引器定义中填充此属性时,它的值将用作Solr中用于存储编码行键的字段的名称。
默认情况下,此属性为空,表示行键未存储在Solr中。这样做的结果是删除HBase中的完整行或完整列族不会删除Solr中的索引文档。
列家族场
column-family-field指定用于存储HBase列系列名称的Solr字段的名称。
有关更多信息,请参阅row-field属性的说明。
默认情况下,此属性为空,因此列族名称不会保存在Solr中。
表名,字段
table-name-field指定Solr字段的名称,该字段用于存储存储记录的HBase表的名称。
默认情况下,此属性为空,因此除非在索引器配置中显式设置此设置,否则不会存储HBase表的名称。
索引器定义中的元素
可以在索引器配置中使用三种类型的元素:<field>,<extract>和<param>。
<字段>
field元素定义要在Solr中索引的单个字段,以及从HBase获取和解释其内容的位置。索引器配置中通常会列出一个或多个字段 - 每个字段用于存储每个Solr字段。
field属性有四个属性,如下所示。
名称
name属性指定用于存储数据的Solr字段的名称。应在Solr模式中定义具有匹配名称的字段。
name属性是必需的。
值
value属性指定要从HBase中使用的数据,以填充Solr中的字段。它采用列族名和限定符的形式,用冒号分隔。
限定符部分可以以星号结尾,星号被解释为通配符。在这种情况下,将使用所有匹配的列族和限定符表达式。
以下是有效值属性的示例:
- mycolumnfamily:myqualifier
- mycolumnfamily:我*
- mycolumnfamily:*
资源
source属性确定HBase KeyValue的哪个部分将用作索引内容。
它有两个可能的值:值和限定符。
指定值时(默认情况下是这种情况),单元格值将用作索引的输入。
指定限定符后,列限定符将用作索引的输入。
类型
type属性定义HBase中内容的数据类型。
因为所有数据都作为字节数组存储在HBase中,但Solr中的所有内容都被索引为文本,因此需要一种从字节数组转换为实际数据类型的方法。
此字段的值可以是HBase Bytes类支持的任何数据类型之一:int,long,string,boolean,float,double,short或bigdecimal。
如果尚未使用基于字节的表示形式在HBase中存储数据,则可以为此属性指定自定义类的名称。自定义类必须实现该com.ngdata.hbaseindexer.parse.ByteArrayValueMapper接口。
<PARAM>
<param>元素定义了一个键值对,它将提供给实现该com.ngdata.hbaseindexer.Configurable接口的自定义类。
<param>元素也可以嵌套在<field>元素中。
该元素有两个属性:name和value。两者都是强制性的
配置示例
下面的示例配置演示了可用于配置索引器的所有元素和属性。
<!--
Do row-based indexing on table "table1", never re-reading updated content.
Store the unique document id in Solr field called "custom-id".
Additionally store the row key in a Solr field called "custom-row", and store the
column family in a Solr field called "custom-family".
Perform conversion of byte array keys using the class "com.mycompany.MyKeyFormatter".
-->
<indexer
table="table1"
mapping-type="row"
read-row="never"
unique-key-field="custom-id"
row-field="custom-row"
column-family-field="custom-family"
table-name-field="custom-table"
unique-key-formatter="com.mycompany.MyKeyFormatter"
>
<!-- A float-based field taken from any qualifier in the column family "colfam" -->
<field name="field1" value="colfam:*" source="qualifier" type="float"/>
<param name="globalKeyA" value="globalValueA"/>
<param name="globalKeyB" value="globalValueB"/>
</indexer>-------------------------------------------------------------------------------------------------
CLI工具
HBase Indexer包含许多用于添加,更新,列出和删除索引器的命令行工具。所有这些工具都是通过向hbase-indexer工具提供命令名来执行的。例如,要使用list-indexers命令,请输入以下内容:
./bin/hbase-indexer list-indexers
使用--help参数运行以下任何命令将显示可能的命令参数列表。
附加索引
“add-indexer”命令用于配置新的索引器。
添加索引器时,您需要至少提供以下内容:
- 索引器的名称
- 索引器的定义(以xml文件的形式)
- Solr使用的ZooKeeper的连接信息
为了添加一个名为“myindexer”的基本索引器,其定义保存在名为myindexer.xml的文件中,ZooKeeper在名为myzkhost:2181 / solr的服务器和名为mycollection的Solr集合上运行,您将执行以下操作:
./bin/hbase-indexer add-indexer \
--name myindexer \
--indexer-conf myindexer.xml \
--cp solr.zk=myzkhost:2181/solr \
--cp solr.collection=mycollection
更新索引
update-indexer命令用于更新索引器的定义或状态。
此命令通常用于更新索引器的定义 - 例如,更改要编制索引的字段列表。
update-indexer工具的参数通常与add-indexer工具的参数相同,但除名称字段外,它们都不是必需的。
要更新在add-indexer的示例中创建的索引器的定义,您将运行以下命令:
./bin/hbase-indexer update-indexer --name myindexer --indexer-conf myupdatedindexer.xml
您提供给update-indexer命令的任何参数(名称参数除外)都将覆盖索引器的现有参数。
列表索引
list-indexer命令列出所有当前配置的索引器,包括有关它们的各种状态信息。
无需任何其他参数即可运行此命令。
删除索引器
delete-indexer命令删除索引器并停止该索引器的所有索引进程。
--name参数对于此命令是必需的。
-----------------------------------------------------------------------------------------------------
可用指标概述
HBase到Solr映射
每个索引器都有一个指标hbaseindexer/DefaultResultToSolrMapper/<indexer_name>/HBase Result to Solr Mapping time。
此度量标准列出了有关将HBase更新事件转换为Solr文档所花费的时间(以毫秒为单位)的信息,以及该过程的一般吞吐量的速率(以文档/秒为单位)。
传入和适用的事件
在hbaseindexer/(Row|Column)BasedIndexer/<indexer_name>,有一对关于传入事件和适用事件的指标。这些度量标准列出了传入的HBase更新事件的速率,以及被认为适用于编制索引的传入HBase事件的速率。
索尔写作
在hbaseindexer/SolrWriter/<indexer_name>,有一些关于Solr的添加和删除率的指标。
还有关于“文档添加/删除错误”和“Solr添加/删除错误”的指标。基于文档的错误是在Solr文档本身确定问题时发生的错误。基于Solr的错误是Solr中发生的错误。
神经节
可以在hbase-indexer-site.xml文件(在conf目录中)中配置向Ganglia报告度量。
要在Ganglia中配置报告,必须提供以下三个配置键:
- hbaseindexer.metrics.ganglia.server - 要报告的Ganglia服务器
- hbaseindexer.metrics.ganglia.port - Ganglia服务器上的端口
- hbaseindexer.metrics.ganglia.interval - 报告的间隔,以秒为单位
Ganglia报告配置示例如下所示
<property>
<name>hbaseindexer.metrics.ganglia.server</name>
<value>mygangliaserver</value>
</property>
<property>
<name>hbaseindexer.metrics.ganglia.port</name>
<value>8649</value>
<property>
<property>
<name>hbaseindexer.metrics.ganglia.interval</name>
<value>60</value>
</property>-------------------------------------------------------------------------批量索引
除了近乎实时地索引HBase更新之外,还可以运行批量索引作业,该作业将索引已包含在HBase表中的数据。批处理索引工具使用与近实时索引器相同的索引语义进行操作,并作为MapReduce作业运行。
在最基本的运行模式下,批量索引可以作为多个索引器运行,这些索引器在HBase区域上运行并直接将数据写入Solr,如下所示:
hadoop jar hbase-indexer-mr-*-job.jar \
--hbase-indexer-zk zk01 \
--hbase-indexer-name docindexer
--reducers 0
通过为--reducers参数提供-1或正整数,也可以在HDFS中生成脱机索引分片,如下所示:
hadoop jar hbase-indexer-mr-*-job.jar \
--hbase-indexer-zk zk01 \
--hbase-indexer-name docindexer \
--reducers -1 \
--output-dir hdfs://namenode/solroutput
最后,索引分片可以离线生成,然后使用--go-live标志合并到正在运行的SolrCloud集群中,如下所示:
hadoop jar hbase-indexer-mr-*-job.jar \
--hbase-indexer-zk zk01 \
--hbase-indexer-name docindexer \
--go-live除了近乎实时地索引HBase更新之外,还可以运行批量索引作业,该作业将索引已包含在HBase表中的数据。批处理索引工具使用与近实时索引器相同的索引语义进行操作,并作为MapReduce作业运行。
在最基本的运行模式下,批量索引可以作为多个索引器运行,这些索引器在HBase区域上运行并直接将数据写入Solr,如下所示:
hadoop jar hbase-indexer-mr-*-job.jar \
--hbase-indexer-zk zk01 \
--hbase-indexer-name docindexer
--reducers 0
通过为--reducers参数提供-1或正整数,也可以在HDFS中生成脱机索引分片,如下所示:
hadoop jar hbase-indexer-mr-*-job.jar \
--hbase-indexer-zk zk01 \
--hbase-indexer-name docindexer \
--reducers -1 \
--output-dir hdfs://namenode/solroutput
最后,索引分片可以离线生成,然后使用--go-live标志合并到正在运行的SolrCloud集群中,如下所示:
hadoop jar hbase-indexer-mr-*-job.jar \
--hbase-indexer-zk zk01 \
--hbase-indexer-name docindexer \
--go-live















 130
130











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









