






目录
1 问题 InvalidInputException
org.apache.hadoop.mapred.InvalidInputException:
Input path does not exist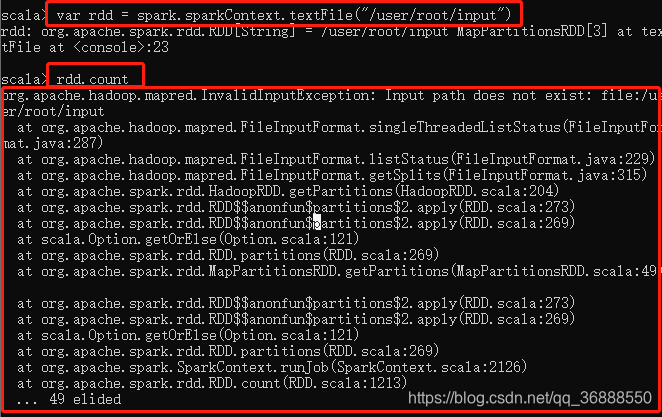
2 背景textFile
textFile是一个从外部创建RDD的函数
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}参数:
path: String 这个地址可以是HDFS、本地文件
minPartitions= math.min(defaultParallelism, 2) 是指定数据的分区,一版默认2(如果核数大于2)
其中,path一般在写作:
hdfs文件:'hdfs:///user/root/1.txt'、‘/user/root/1.txt’;
本地文件:‘file:///user/root/1.txt’
但是,会出现上述报错
3 解决
3.1 hdfs导入 报错原因+解决
原因:我们安装hadoop时修改了文件\hadoop-2.8.5\etc\hadoop\core-site.xml
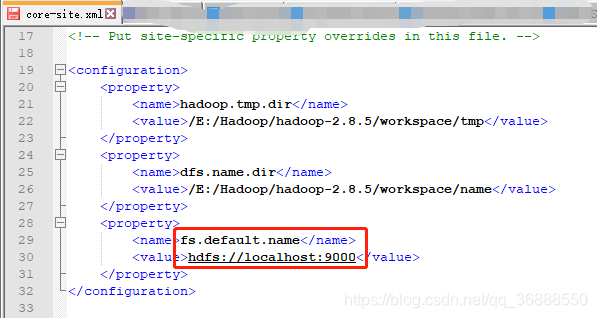
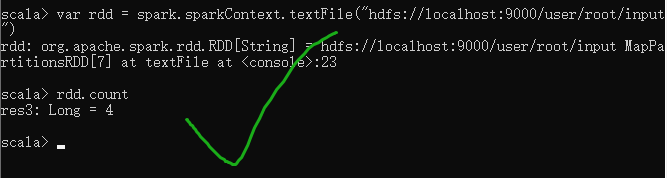
根据我们安装时填写的路径修改代码,即可
比如我的就改成 var rdd = spark.sparkContext.textFile("hdfs://localhost:9000/user/root/input")
3.2 本地导入 报错原因+解决
本地文件导入报错是因为根目录下不存在该文件!
注意hdfs根目录和spark根目录的区别!!!
同一个本地地址,spark查无此人,hadoop却是有的,因为打开spark、hadoop的根目录是不同位置!!
小白OS:不想知道为什么会让我觉得这两个的file://是一个东西 原因指路→3.2.1 【已解决】根目录file://到底在哪里
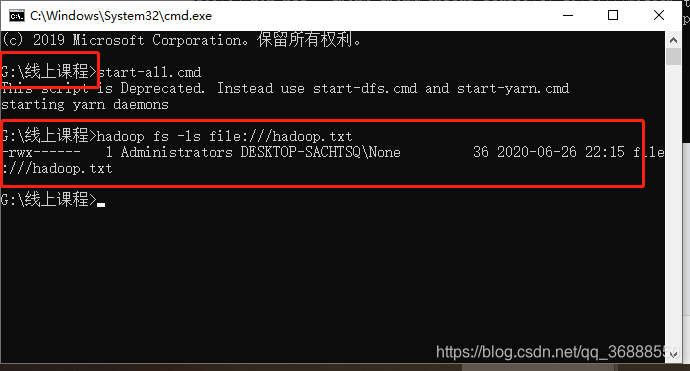
下图可证我的结论,我最后就都在G盘打开这俩东西了,成功
只要在一个盘里打开,即使具体位置不同,也是可以用的,也蛮方便的。
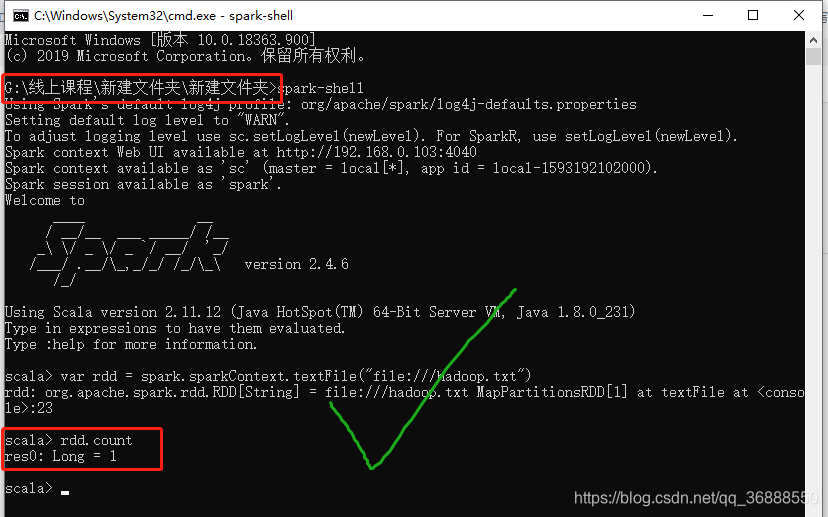
3.2.1 【已解决】根目录file://到底在哪里
在不同文件目录下打开cmd,file://指向的根目录不一样,比如:
一般人用菜单打开cmd,那么file://指C盘
有些人会在D盘安装hadoop,然后在其下打开cmd,那么file://指D盘
如果在同一个盘的不同文件中打开cmd,比如在D:/1/2位置和D:/3/4位置分别打开cmd,那么file://都指D盘
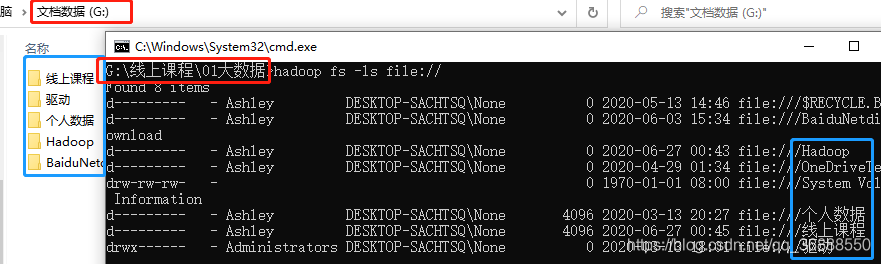
3.2.2 hadoop看根目录
用hadoop fs -ls file://测试一下根目录到底在哪里,根目录下是否有对应文件
一般情况你在什么大盘目录下打开,hadoop默认的根目录就在这个大盘下
举个栗子:
比如在一个G盘文件目录下打开cmd,那么根目录就在G盘下
其中,file:///hadoop目录是hadoop这个软件在自动生成的文件夹,在哪个大盘打开,就在哪里生成
3.2.3 【已解决】本地目录里面不要空格
如果本地地址有空格,报如下错误


















 2180
2180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









