







什么Mysql的底层索引要用B+Tree
那就要先说二叉树 : 二叉树以第一个插入的数据作为根节点,假设特定情况他就变成了一个单项链表,查询效率极慢。
其次就是平衡二叉树 平衡二叉树在数据量大的情况下,树会很高,那么我们的检索效率还是不高。
然后是B Tree B tree的树高不会很高
B+ tree 是在 b tree的前提下给优化了一下,把数据也放在了叶子节点中。
B+Tree相对于B-Tree有几点不同:
1.非叶子节点只存储键值信息。
2.所有叶子节点之间都有一个链指针。所有的叶子节点形成了一个闭环
3.数据记录都存放在叶子节点中
分组链接
我们在查询的时候按照某个字段分组,那么我们查询的字段只能是我们分组字段或者是聚合函数,这时我们可以用分组连接函数把其他的字段全部连接起来。
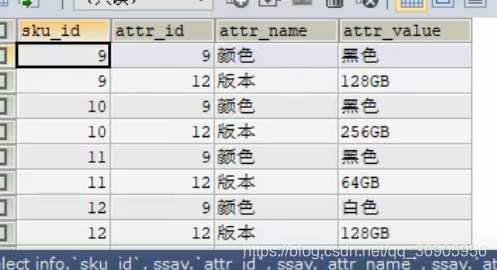
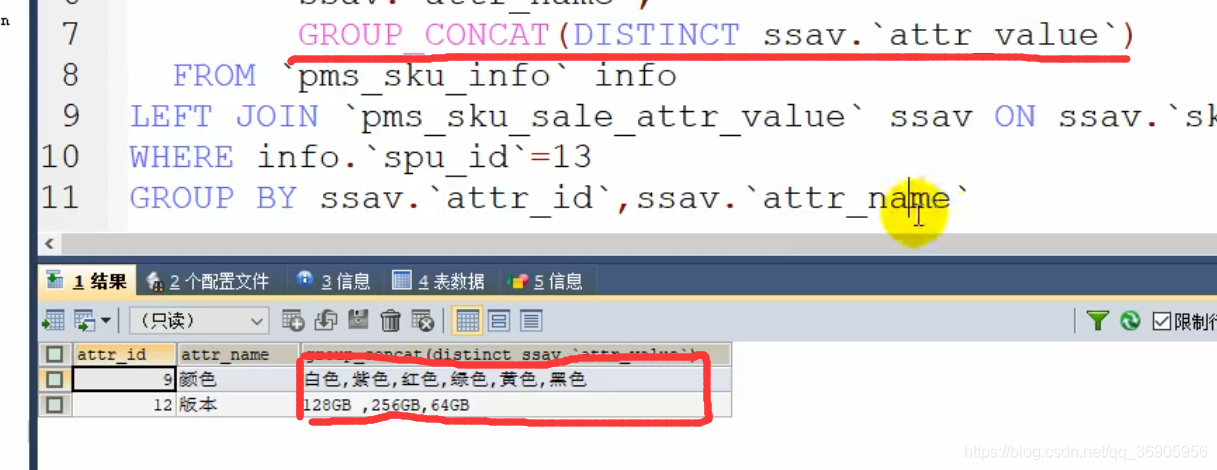
聚餐索引与非聚簇索引的区别

批量新增 冲突时 更新
INSERT INTO `into_shop_device_info`(
`tenant_id`,
`device_no`,
`device_name`,
`is_delete`,
`last_heartbeat_time`,
`xm_device_id`,
`status`,
`create_stime`,
`update_stime`
) VALUES
<foreach collection="deviceInfoList" item="item" separator=",">
(#{item.tenantId},
#{item.deviceNo},
#{item.deviceName},
#{item.isDelete},
#{item.lastHeartbeatTime},
#{item.xmDeviceId},
#{item.status},
NOW(),
NOW())
</foreach>
on duplicate key update
tenant_id=VALUES(tenant_id),
device_no=VALUES(device_no),
device_name=VALUES(device_name),
is_delete=VALUES(is_delete),
last_heartbeat_time=VALUES(last_heartbeat_time),
xm_device_id=VALUES(xm_device_id),
status=VALUES(status),
update_stime=NOW()















 288
288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









