







参考:https://blog.csdn.net/m0_37925202/article/details/80818561; https://www.cnblogs.com/chengxiao/p/6129630.html
选择排序(Selection Sort)
选择排序的基本思想:每趟从待排序的记录中选出关键字最小的记录,顺序放在已排好序的子文件的最后,直到全部记录排序完毕。常用的选择排序方法有直接选择排序和堆排序。
一、直接选择排序
1.基本思想
n个记录的文件的直接选择排序可经过n-1趟直接选择排序得到有序结果。
- 第1趟从R[0]~R[n-1]中选取最小值,与R[0]交换;
- 第2趟从R[1]~R[n-1]中选取最小值,与R[1]交换;
- 第i趟从R[i-1]~R[n-1]中选取最小值,与R[i-1]交换;
直接选择排序和直接插入排序类似,都将数据分为有序区和无序区,所不同的是直接插入排序是将无序区的第一个元素直接插入到有序区以形成一个更大的有序区,而直接选择排序是从无序区选择一个最小的元素直接放到有序区的最后。
2.代码实现
private static int[] selectSort(int[] arr) {
// 思路:从第一个开始,依次拿最左边的这一个的和其他所有进行比较,一轮下来
// 第一个应该是最小的,然后,拿第二个和右边剩下依次的比较,一轮后,第二个元素确定
if(arr==null||arr.length==0)
return null;
for(int i=0;i<arr.length-1;i++)
// 外循环:控制i位置元素和右边剩下的所有元素依次比较
for(int j=i+1;j<arr.length;j++)
// 内循环:把第i个和剩下的比较
if(arr[i]>arr[j]) {
int temp = arr[j];
arr[j] = arr[i];
arr[i] = temp;
}
return arr;
}3.性能分析
1. 时间效率:无论n个待排序记录的初始状态如何,在第i趟排序过程中,都要经过n-i次比较才能选出排序码最小的记录。因此,不论是在最好、最坏或平均情况下,比较次数都相同。
至于记录的移动次数,在最好的情况下,n个待排序记录是正序排列,则不需要记录的移动,Mmin=0;在最坏的情况下,也就是待排序记录是反序排列的,则每趟排序必须进行一次两个记录的交换,交换次记录需要三次移动才能完成,移动次数为Mmax=3(n-1)。注意,在最坏的情况下,记录的移动次数只是O(n),这是直接选择排序的最大优点。显然,直接选择排序主要时间消耗在比较操作上,其最好最坏或平均时间复杂度均为O(n2)。
2.空间效率:在整个算法中,只需要一个用于交换记录的辅助空间,所以直接选择排序的空间复杂度为O(1)。
(3)稳定性:在直接选择排序过程中,记录的交换不是在相邻位置上进行的,所以直接选择排序是不稳定的,最后说明一点,直接选择排序的思想也适用于单链表的排序。
一、堆
直接选择排序方法比较简单,但其效率不高。不论是最好、最坏还是平均时间复杂度都是O(n2 ),主要原因是算法时间都耗费在排序码之间的比较上。在n个记录中选出排序码最小的记录,必须进行n-1次比较,然后在剩下的n-1个记录中再选出排码最小的记录,还必须进行n-2次比较。其实,在后面做的n-2次比较中,有很多是前面n一1次比较的重复操作。如果能够保留前面的比较结果,就可以避免重复操作的出现,从而减少排序码间的比较次数,提高排序的效率。堆排序就是对直接选择排序的一种改进方法。
在说堆排序之前,我们首先要知道堆是什么?堆这个字我只在了解jvm存储变量的时候见过,在java中,使用new创建的对象一般都会存到堆中,但我还是不知道堆是什么。。。
好,在讲堆之前,你必须要知道二叉树,然后知道完全二叉树。如图:
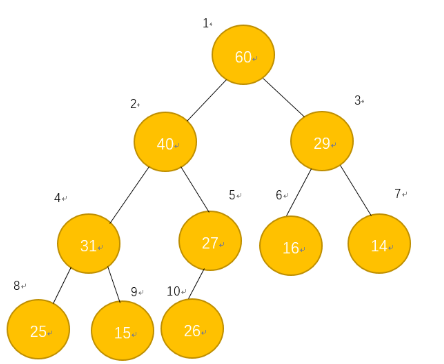
上面这个二叉树就是一个完全二叉树,其特点在于:
- 除最下面一层外其余各层的结点数都达到最大值,并且最下一层上的结点都从该层最左边的位置开始连续排放,这也是完全二叉树的定义。
- 每个结点的值都大于或等于其左右孩子(前提得有孩子)的值。
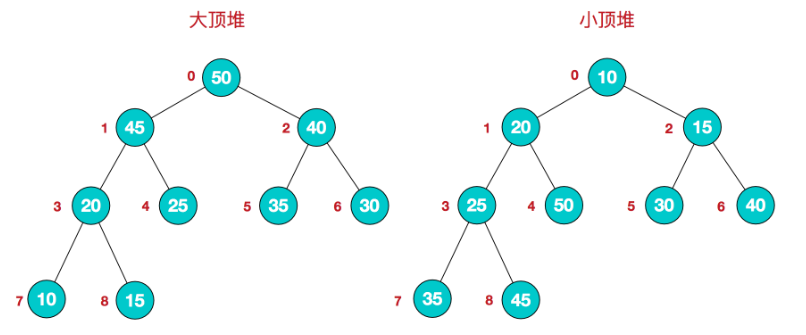
大根堆:每个结点的值都大于或等于其左右孩子结点的值
小根堆:每个结点的值都小于或等于其左右孩子结点的值
这里我有个小小的疑问,我看了网上好多的定义,发现并没有堆的定义。一般我们解释一个名词都是直接解释,比如“葡萄”,你得先解释葡萄是什么,然后才解释绿葡萄、紫葡萄是什么?这里,我姑且认为,如果是堆,那么它肯定是大根堆或小根堆。因此,直接解释大根堆、小根堆即可。
需要注意的是,堆的逻辑结构是如此,但是在计算机内存里我们以数组的形式存储。数组初始下标是0,对其进行编号。
映射到数组中:

该数组从逻辑上讲就是一个堆结构,我们用简单的公式来描述一下堆的定义就是:
大顶堆:arr[i] >= arr[2i+1] && arr[i] >= arr[2i+2]
小顶堆:arr[i] <= arr[2i+1] && arr[i] <= arr[2i+2]
二、知识补充
首先说下编程,编程一般就是把人的思想转化为计算机思想的过程,在过程中有些转化就让我甚是苦恼,比如人们计数一般都是从1开始,然而数组的初始下标却是从0开始。每次我想有关问题都想了好久才能编写出代码。
下面我还要补充下关于完全二叉树的性质。
性质5:对于一棵完全二叉树,若结点i,则其左孩子为2i,右孩子为2i+1。
(引自我的二叉树)
对于性质5:当根结点标号从1开始是如此,但如果按照它以数组的存储方式开始即左孩子为2i+1,右孩子为2i+2。
另外,如果有n个结点,第n个必然是叶子结点;它的父节点必然是最后一个非子结点。父节点的标号是 或
,这里我们利用int向下取整的特性,可以得出,某完全二叉树最后一个非叶子结点的标号为
,当然,按照以数组存储最后一个非叶子结点的数组下标为
。这里面有点不太好反应,就是两个种结果最后统一成一种结果。
三、堆排序思想
堆排序的基本思想是:将待排序序列构造成一个大根堆,此时,整个序列的最大值就是堆顶的根节点。将其与末尾元素进行交换,此时末尾就为最大值。然后将剩余n-1个元素重新构造成一个大根堆,再把堆顶的根结点与剩余结点的最后一个结点交换,如此反复执行,便能得到一个有序序列了。下面将这思想转化为具体的步骤。
步骤一 :构造初始堆
1.将给定无序序列构造成一个大根堆(一般升序采用大根堆,降序采用小根堆),设有一个无序序列 { 1, 3, 4, 5, 2, 6, 9, 7, 8, 0 }
2.此时我们从最后一个非叶子结点开始(使用上述公式计算可知最后一个非叶子结点数组下标是4),从右至左,从下至上进行调整。
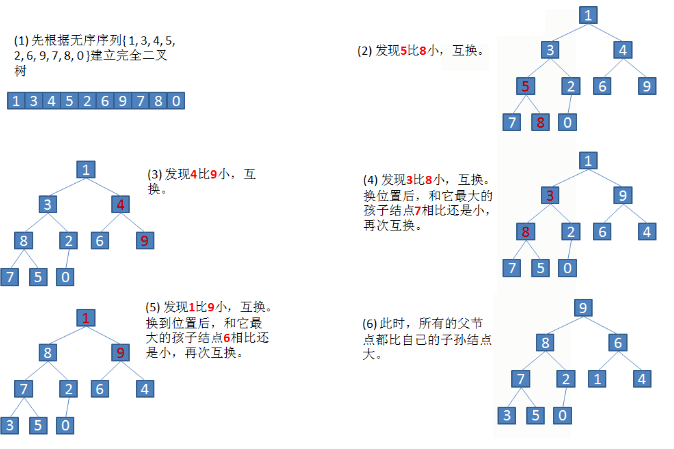
总结:
- 先比较父和子结点的大小关系,然后决定是否交换
- 交换之后还要从此结点向下检查,如果有不符合的还要一直交换。它需要一直检查到不需要交换的结点为止。
可以试图把这几句转化为编程语言:先有个大循环,循环从最后一个非叶子节点开始到根结点结束,里面有个if语句用当前节点与其子节点进行大小判断,满足交换条件,调用交换函数swap(),交换后要调用check()函数进行检查;否则不满足直接退出循环开始下一个节点。
步骤二:进行排序
将堆顶元素与末尾元素进行交换,使末尾元素最大。把末尾元素排除,不再参与排序;然后继续调整堆,再将堆顶元素与末尾元素交换,得到第二大元素。如此反复进行交换、重建、交换。

tips:这里重建的意思就是当把根结点和末结点交换时,这个堆不符合大根堆了,必须从根结点开始自上向下进行检查调整。
代码化
关键字:比较、交换、检查
而且这里面需要注意的是,大循环下是从最后一个非叶子结点到根结点自下而上进行遍历;检查是从当前节点自上而下进行检查。大概有这几个函数:
初始化堆函数,负责初始化
交换函数,负责交换数组中的两个元素
检查函数,负责自此结点向下检查
四、代码实现
public class Demo {
public static void main(String args[]) {
int arr[] = {49,38,65,97,76,13,27,49,23,14,23,66,87,1};
heapSort(arr);
printArr(arr);//打印数组
}
private static void heapSort(int[] arr) {
// 初始化堆
initHeap(arr,arr.length);
int len = arr.length;
// 从最后一个非叶子结点自下而上遍历到根结点,有n个元素,只需确定n-1个位置即可
do {
swap(arr,0,len-1);
check(arr,0,len-1);
len--;
}
while(len>1);
}
private static void initHeap(int[] arr,int len) {
// 此方法用于初始化为大根堆,从最后非叶子结点开始,即len/2-1(取整)开始,依次向上进行处理
// 最后至根结点
for(int i=len/2-1;i>=0;i--) {
int dad = i;
int son1 = 2*i+1;
int son2 = 2*i+2;
int son;//存取两个子节点中最大的值
// 前提是有两个子节点,因为最后一个有子节点的父节点有可能只有一个子节点,所以
// 要判断第二个子节点的下标是否超出长度范围
// 这里比较的方法是先让两个子节点比较出大的,然后再与父节点比较
if(son2<len && arr[son1]<arr[son2])
son = son2;
else
son = son1;
if(arr[dad]<arr[son]) {
swap(arr,dad,son);
// 交换后,以交换过位置的那个子节点为父节点,开始自此结点向下检查
check(arr,son,len);
}
}
}
private static void check(int[] arr,int dad, int len) {
// 此方法用于交换后的检查,当子节点和父节点位置交换后,以该子节点作为父节点和其所对应的子节点是否又满足
// 大小关系呢,需要从上到下依次检查,一直检查到某一节点无需交换的位置
while(dad<=len/2-1) {//最后一个有子节点的父节点
int son1 = 2*dad+1;//左孩子
int son2 = 2*dad+2;//右孩子
int son;//存取两个子节点中最大的值
// 前提是有两个子节点,因为最后一个有子节点的父节点有可能只有一个子节点,所以
// 要判断第二个子节点的下标是否超出长度范围
if(son2<len && arr[son1]<arr[son2])
son = son2;
else
son = son1;
if(arr[dad]<arr[son]) {
swap(arr,dad,son);
// 交换后,以交换过位置的那个子节点为父节点,继续自上而下检查
dad = son;
}
else
// 这个用来终止循环,当你不发生交换了自然就不影响下面的元素了,没必要再比较到最后一个非叶子结点
break;
}
}
private static void swap(int[] arr,int i,int j) {
// 交换函数
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
private static void printArr(int[] arr) {
for(int a:arr)
System.out.print(a+" ");
System.out.println("");
}
}基本思路:
- 将无序序列构建成一个堆,根据升序降序需求选择大根堆或小根堆;
- 将堆顶元素与末尾元素交换,将最大元素"沉"到数组末端;
- 重新调整结构,使其满足堆定义,然后继续交换堆顶元素与当前末尾元素,反复执行调整+交换步骤,直到整个序列有序。
堆排序的性能分析:
时间效率:对n个记录进行堆排序,首先将其建成堆,然后进行n-1趟先交换、后调整的堆排序过程。在整个排序过程中记录交换的次数不会超过比较的次数,所以主要分析比较次数。堆排序的时间主要消耗在检查调整算法中,一共调用了(int)n/2+n-1(约3n/2)次的检查算法,在每次检查算法中,排序码之间的比较次数都不会超过完全二叉树的高度,即(int)log2n+1,所以整个堆排序过程的最坏时间复杂度为O(nlog2n),其平均时间复杂度也是O(nlogzn)。
空间效率:在整个堆排序过程中,需要1个与记录大小相同的辅助空间用于交换记录,故其空间复杂度为0(1)。
稳定性:堆排序中是在不相邻的位置之间进行记录的移动和交换,所以它是一种不稳定的排序方法。
堆排序相对于直接选择排序来说,算法的实现过程比较复杂,但算法的效率有很大的提高,尤其是待排序记录个数n较大的情况下,堆排序的优势更加明显。















 410
410











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









