







一、什么是统计信息
-
定义
- 在Oracle数据库中,统计信息是描述数据库对象(如表、索引等)数据特征的一组数据。这些数据帮助优化器更好地理解数据的分布情况,从而生成更高效的执行计划。例如,对于一个表,统计信息可能包括表中的行数、列的数据分布(如最小值、最大值、平均值、标准差等)、索引的叶块数等内容。
-
统计信息的内容
- 表级统计信息
- 行数(Num_Rows):准确记录表中包含的数据行数。例如,在一个存储客户订单信息的表中,统计信息会告诉优化器该表目前有10000个订单记录。这对于优化器估算查询操作(如
SELECT * FROM orders WHERE order_date > '2024 - 01 - 01')返回的结果集大小非常重要。 - 块数(Blocks):表示存储表数据所占用的数据块数量。数据块是Oracle存储数据的基本单位,了解表占用的块数有助于优化器评估I/O操作的成本。比如,一个较大块数的表在全表扫描时可能需要更多的I/O资源。
- 平均行长度(Avg_Row_Len):计算表中每行数据的平均长度,以字节为单位。这个信息可以帮助优化器预估查询返回数据的大小,进而合理安排内存缓冲区等资源。
- 行数(Num_Rows):准确记录表中包含的数据行数。例如,在一个存储客户订单信息的表中,统计信息会告诉优化器该表目前有10000个订单记录。这对于优化器估算查询操作(如
- 列级统计信息
- 最小值(Low_Value)和最大值(High_Value):对于数值型列,统计信息会记录其最小值和最大值。例如,在一个存储产品价格的列中,最小值可能是1.0,最大值可能是1000.0。对于字符型列,也会有相应的最小和最大取值范围。这对于优化器判断查询条件(如
WHERE price BETWEEN 10.0 AND 100.0)能否有效利用索引等非常关键。 - 直方图(Histograms):直方图用于描述列数据的分布情况。当列的数据分布不均匀时,直方图可以提供更详细的信息。例如,在一个存储客户年龄的列中,可能大部分客户年龄集中在20 - 40岁之间,直方图会记录这种分布细节。优化器可以根据直方图来更准确地选择执行计划,特别是对于涉及范围查询的SQL语句。
- 空值数量(Num_Nulls):记录列中包含空值的数量。空值的存在会影响查询的结果和执行计划。例如,在一个
JOIN操作中,如果连接条件的列包含大量空值,优化器可能需要重新考虑连接的方式。
- 最小值(Low_Value)和最大值(High_Value):对于数值型列,统计信息会记录其最小值和最大值。例如,在一个存储产品价格的列中,最小值可能是1.0,最大值可能是1000.0。对于字符型列,也会有相应的最小和最大取值范围。这对于优化器判断查询条件(如
- 索引级统计信息
- 叶块数(Leaf_Blocks):索引的叶块是存储索引键值和对应的行指针的地方。叶块数反映了索引的大小。例如,一个索引有100个叶块,优化器在评估使用该索引进行查询(如
SELECT * FROM table WHERE indexed_column = 'value')的成本时,会考虑叶块的数量,因为这涉及到I/O操作的次数。 - 聚簇因子(Clustering_Factor):聚簇因子用于衡量表中的行按照索引键值排序的程度。如果聚簇因子接近表的块数,说明表中的行按照索引键值的顺序存储得很好,索引的使用效率可能较高;如果聚簇因子很大,说明行的存储顺序与索引键值顺序不一致,可能会增加索引扫描的I/O成本。
- 叶块数(Leaf_Blocks):索引的叶块是存储索引键值和对应的行指针的地方。叶块数反映了索引的大小。例如,一个索引有100个叶块,优化器在评估使用该索引进行查询(如
- 表级统计信息
-
统计信息的作用
- 优化执行计划:优化器依靠统计信息来估算不同执行计划的成本。例如,在执行一个
SELECT语句时,优化器可以根据表和索引的统计信息来判断是使用全表扫描还是索引扫描更高效。如果统计信息显示通过索引可以快速定位到满足条件的少量行,优化器可能会选择索引扫描;如果统计信息表明大部分行都满足查询条件,全表扫描可能是更合适的选择。 - 提高查询性能:准确的统计信息能够使数据库在处理查询时选择最优的执行路径,从而减少查询的响应时间和资源消耗。例如,对于一个复杂的多表连接查询,优化器根据统计信息可以合理安排连接的顺序和方法,提高查询的整体性能。
- 自适应优化调整:在一些高级的数据库特性中,如自适应查询优化,统计信息是基础。数据库可以根据统计信息和查询执行的实际情况动态调整执行计划,以适应数据的变化和查询负载的变化。
- 优化执行计划:优化器依靠统计信息来估算不同执行计划的成本。例如,在执行一个
二、oracle收集和查看统计信息的方法
oracle数据库收集统计信息一般有以下3种方法:
(1)自动收集
(1)使用analyze命令。
(2)使用dbms_stats包。
针对以上6种统计信息,其中“表的统计信息”,“索引统计信息”,“列统计信息”,“数据字典统计信息”使用analyze或dbms_stats包收集均可以,但是“系统统计信息”和“内部对象统计信息”必须要dbms_stats包来收集才可以。
1、自动收集
查看是否自动收集信息:
SQL> col REPEAT_INTERVAL for a60
col DURATION for a30
SELECT w.window_name, w.repeat_interval, w.duration, w.enabled
FROM dba_autotask_window_clients c, dba_scheduler_windows w
WHERE c.window_name = w.window_name
AND c.optimizer_stats = 'ENABLED';

如图是周一到周五 22点开始 持续4小时,周末 6点开始 持续20小时。
开启自动收集:
SQL> SELECT WINDOW_NAME,AUTOTASK_STATUS,OPTIMIZER_STATS,SEGMENT_ADVISOR,SQL_TUNE_ADVISOR FROM DBA_AUTOTASK_WINDOW_CLIENTS;

都需要开启才能使用自动收集。
关(关的AUTOTASK_STATUS)
SQL>BEGIN
DBMS_AUTO_TASK_ADMIN.enable();
END;
/
开
SQL>BEGIN
DBMS_AUTO_TASK_ADMIN.enable();
END;
/
查看是否自动收集统计信息
SQL>select client_name,status from dba_autotask_client;
2、使用analyze命令收集统计信息
SQL>create table t1 as select * from dba_objects;
SQL>create index idx_t1 on t1(object_id);
SQL>analyze index idx_t1 delete statistics;
SQL>analyze table t1 estimate statistics sample 15 percent for table;
SQL>analyze table t1 compute statistics for table;
SQL>analyze table t1 compute statistics for t1 for columns object_name,object_id;
SQL>analyze table t1 compute statistics;
3、使用dbms_stats包收集统计信息
DBMS_STATS包最常见的4个存储过程:
(1)dbms_stats.gather_table_stats:用于收集目标表,目标表上列及目标表上索引的统计信息。
(2)dbms_stats.gather_index_stats:用于收集指定索引的统计信息。
(3)dbms_stats.gather_schema_stats:用于收集schema下所有对象的统计信息。
(4)dbms_stats.gather_database_stats:用于收集全库统计对象的统计信息。
SQL> exec dbms_stats.gather_table_stats(ownname=>'SYS',tabname=>'T1',estimate_percent=>100,method_opt=>'FOR TABLE',cascade=>FALSE);
SQL> exec dbms_stats.gather_table_stats(ownname=>'SYS',tabname=>'T1',estimate_percent=>15,method_opt=>'FOR TABLE',cascade=>FALSE);
SQL> exec dbms_stats.gather_table_stats(ownname=>'SYS',tabname=>'T1',estimate_percent=>15 ,cascade=>TRUE);
三、统计信息查看
表:
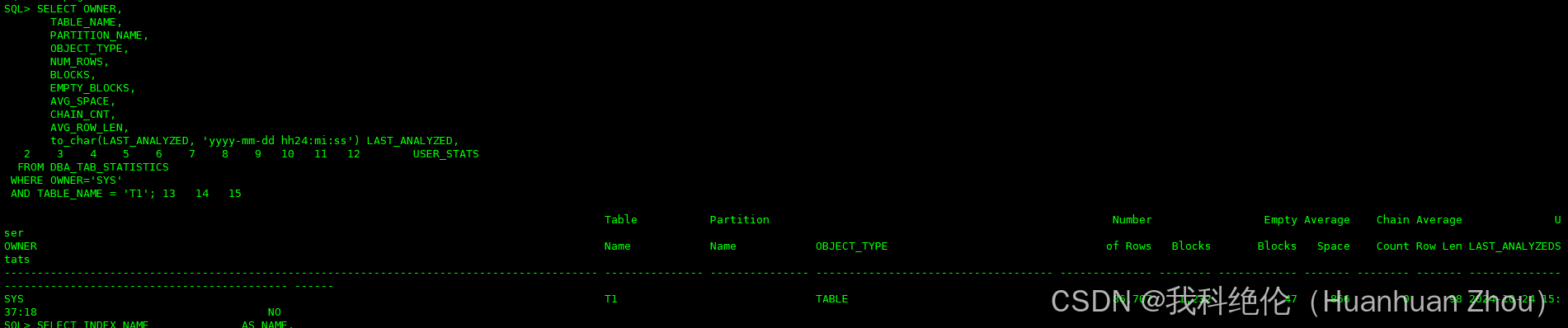
SQL>SELECT OWNER,
TABLE_NAME,
PARTITION_NAME,
OBJECT_TYPE,
NUM_ROWS,
BLOCKS,
EMPTY_BLOCKS,
AVG_SPACE,
CHAIN_CNT,
AVG_ROW_LEN,
to_char(LAST_ANALYZED, 'yyyy-mm-dd hh24:mi:ss') LAST_ANALYZED,
USER_STATS
FROM DBA_TAB_STATISTICS
WHERE OWNER='SYS'
AND TABLE_NAME = 'T1';
索引信息:
SQL> SELECT INDEX_NAME AS NAME,
BLEVEL,
LEAF_BLOCKS AS LEAF_BLKS,
DISTINCT_KEYS AS DST_KEYS,
NUM_ROWS,
CLUSTERING_FACTOR AS CLUST_FACT,
AVG_LEAF_BLOCKS_PER_KEY AS LEAF_PER_KEY,
AVG_DATA_BLOCKS_PER_KEY AS DATA_PER_KEY,
LAST_ANALYZED
FROM DBA_IND_STATISTICS where
TABLE_OWNER='SYS' AND
TABLE_NAME='T1';
SQL> select table_name,index_name,leaf_blocks,blevel,distinct_keys,avg_leaf_blocks_per_key,avg_data_blocks_per_key,clustering_factor,num_rows from dba_indexes where owner = 'SYS' and table_name = 'T1';


列:
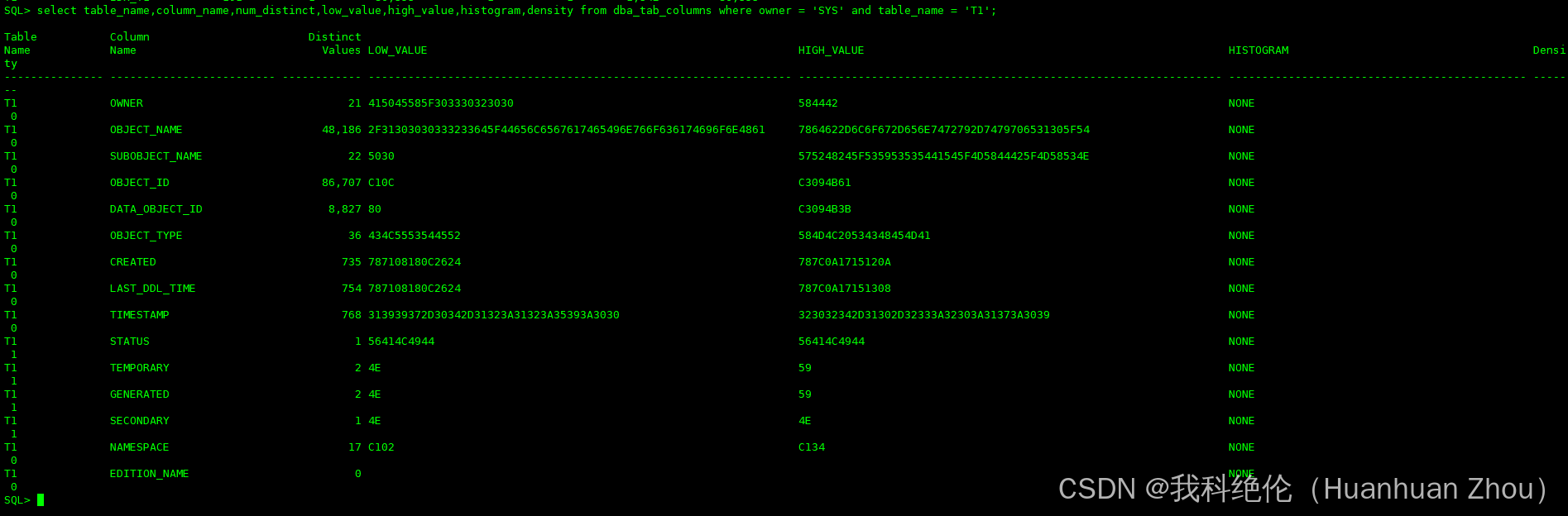
SQL> select table_name,column_name,num_distinct,low_value,high_value,histogram,density from dba_tab_columns where owner = 'SYS' and table_name = 'T1';
批量收集统计信息脚本:
SQL>begin
for tjxx in (select owner, table_name from dba_tables where table_name in ('T1') and owner='SYS') loop
begin
dbms_stats.gather_table_stats(ownname => tjxx.owner,
tabname => tjxx.table_name ,
degree => 8,
cascade => true);
end;
end loop;
end;
/
SQL>select owner, table_name,LAST_ANALYZED from dba_tables where table_name in ('T1') and owner='SYS';
欢迎关注公众号《小周的数据库进阶之路》,更多精彩知识和干货尽在其中。


















 3251
3251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









