







今天开始更新爬虫系列笔记,此系列旨在总结回顾常用爬虫技巧以及给大家在日常使用中提供较为完整的技术参考。在进行正式的爬虫之前有必要熟悉以下爬虫的基本概念,例如爬虫的基本原理、网络通信原理以及Web三件套的相关知识等。
目录
一、爬虫原理
网络爬虫是一种从网页上抓取数据信息并保存的自动化程序。如果我们把互联网比作一张大的蜘蛛网,数据便是存放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛(程序),沿着网络抓取自己的猎物(数据)。下面简要介绍一下爬虫的基本概念与流程:
1.获取网页
网络爬虫第一步首先是通过一定的方式获取网页。所谓获取网页可以简单理解为在本地发起一个服务器请求,服务器则会返回给我们网页的源代码,其中通信的底层原理较为复杂,而Python给我们封装好了urllib库和requests库等,这些库可以让我们非常简单的发送各种形式的请求。
2.提取信息
网页的源代码包含了非常多的信息,而想要进一步的获取我们的想要的信息则需要对源代码中的信息进行进一步的提取。此时我们可以选用python中的re库即通过正则匹配的形式去提取信息,也可以采用BeautifulSoup库(bs4)等解析源代码,除了有自动编码的优势之外,bs4库还可以结构化输出源代码信息,更易于理解与使用。
3.保存数据
在提取到网页源代码中我们想要的信息之后则需要在python中将它们保存起来,可以使用通过内置函数open保存为文本数据等,也可以通过第三方库保存为其它形式的数据,例如可以通过pandas库保存为常见的xlsx数据,如果有图片等非结构化数据还可以通过pymongo库保存至非结构化数据库中。
4.自动化程序
在经过前三步即ETL(Extract-Transform-Load)过程之后就可以将我们的爬虫代码有效地组织起来构成一个爬虫自动化程序,以至于需要相同或相似数据的时候可以高效复用。
二、HTTPS
1.URL
介绍URL之前首先说一下URI。URI(uniform resource identifier)是统一资源标识符,用来唯一的标识一个资源。而URL是uniform resource locator,统一资源定位器,它是一种具体的URI,即URL可以用来标识一个资源,而且还指明了如何定位这个资源。举个栗子:https://www.baidu.com/ 即为一个URL,通过该URL可以进入到百度搜索页面中。
2.HTTPS
HTTPS可以理解为HTTP的加密形式。HTTP(HyperText Transfer Protocol,超文本传输协议)是一个简单的请求-响应协议,它通常运行在TCP之上。它指定了客户端可能发送给服务器什么样的消息以及得到什么样的响应。HTTPS (全称:Hyper Text Transfer Protocol over SecureSocket Layer),是以安全为目标的 HTTP 通道,在HTTP的基础上通过传输加密和身份认证保证了传输过程的安全性。HTTPS 在HTTP 的基础下加入SSL 层,HTTPS 的安全基础是 SSL,因此加密的详细内容就需要 SSL,上文中的链接即为HTTPS链接。
3.请求与响应
http请求过程可分为以下几个部分:建立TCP连接,浏览器向服务器发送请求命令,服务器应答,服务器关闭TCP连接以及浏览器接受到服务器响应的数据。
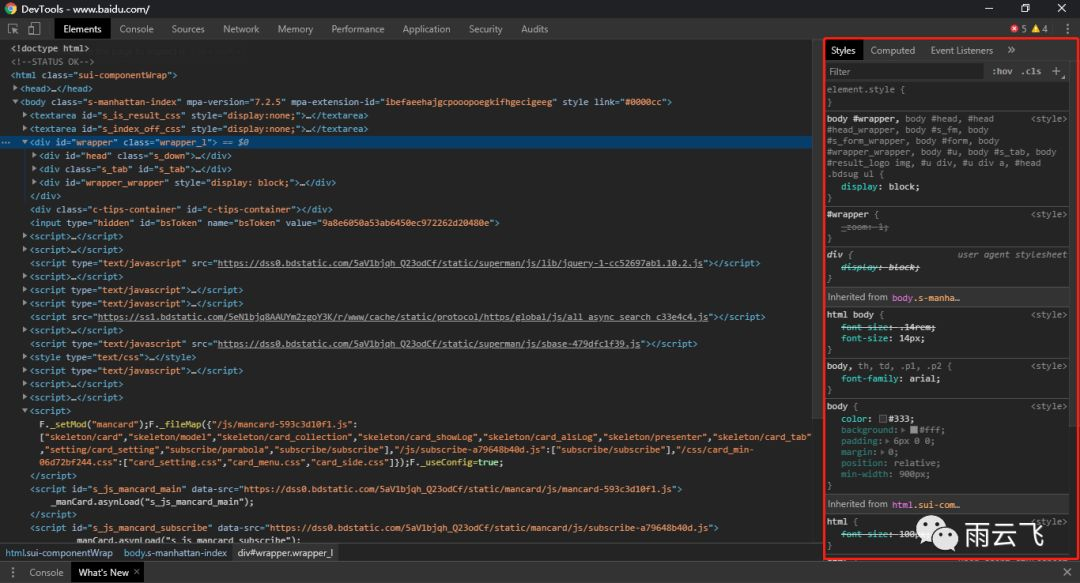
首先开始我们第一个请求,例如我们在谷歌浏览器中输入上述链接打开百度搜索官网,按F12键打开Devtools开发工具,再刷新以下网页可以发现开发工具中弹出诸多响应信息:
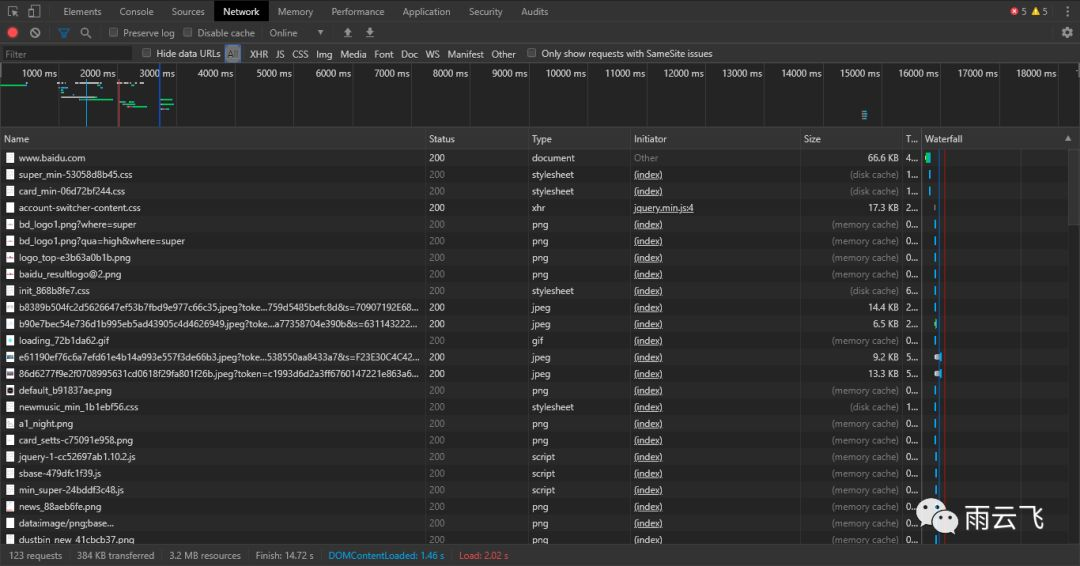
下面的选项卡中,Elements为元素面板,查看Web页面的HTML与CSS,最重要的是可以双击元素,对当前页面进行修改;Console为控制台面板,JavaScript输出信息的控制台;Source为源代码面板,我们在这个页面对JS代码进行调试,可设置断点;NetWork为网络面板,可以明确的查看到访问Web页面所产生的全部请求(包括应答状态、响应时间、数据量等信息)和下载的资源文件;Performance、Memory、Application、Security、Audits分别为性能面板、内存面板、应用面板、安全面板、审计面板;我们主要就是利用NetWork面板的信息进行网络数据采集。
显示的文件信息中,Name代表请求的名称,一般为URL的最后一部分;Status代表响应的状态码,一般为200,代表响应是正常;Type为请求的文档类型,例如第一个为Document文档格式;Initiator为请求源,用来标记请求是由哪个对象或进程发起的;Size是从服务器下载的文件和请求的资源大小;Time为发起请求到获取响应所用的总时间;Waterfall列则展示网络请求的可视化瀑布流。
三、Web三件套
Web网页可以分为HTML、CSS和JavaScript三个部分。如果把网页比作一个人的话,HTML相当于骨架,JavaScript相当于肌肉,CSS相当于皮肤,三者结合起来才能形成一个完善的网页。下面我们分别来介绍一下这三部分的功能。
1.HTML
超文本标记语言(英语:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言。您可以使用 HTML 来建立自己的Web站点,HTML 运行在浏览器上,由浏览器来解析。例如下面即为一个简单的表单HTML:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>表单</title>
</head>
<body>
<form action="https://www.baidu.com/" method="get">
<b>用户名</b><input type="text" name="username"><br>
<b>邮箱</b><input type="email"><br>
<b>密码</b><input type="password" name="password"><br>
<input type="radio" name="gender" value="male">Male <br>
<input type="radio" name="gender" value="female">female <br>
<input type="checkbox" name="gender" value="male">Male <br>
<input type="checkbox" name="gender" value="female">female <br>
<texarea name="message"></texarea>
<input type="submit">
</form>
</body>
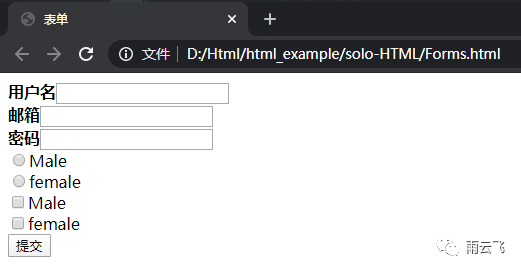
</html>将该代码复制到html文件中再在谷歌浏览器中打开文件,会发现谷歌浏览器已经将其解析为一个表单页面:
2.Javascript
JavaScript(简称“JS”) 是一种具有函数优先的轻量级,解释型或即时编译型的编程语言。虽然它是作为开发Web页面的脚本语言而出名的,但是它也被用到了很多非浏览器环境中,JavaScript 基于原型编程、多范式的动态脚本语言,并且支持面向对象、命令式和声明式(如函数式编程)风格。例如再次打开百度搜索的Devtools后台开发页面,进入Elements选项卡查看源代码,即可发现JavaScript代码,负责网页的行为。
3.CSS
层叠样式表(Cascading Style Sheets)是一种用来表现HTML(标准通用标记语言的一个应用)或XML(标准通用标记语言的一个子集)等文件样式的计算机语言。CSS不仅可以静态地修饰网页,还可以配合各种脚本语言动态地对网页各元素进行格式化。CSS 能够对网页中元素位置的排版进行像素级精确控制,支持几乎所有的字体字号样式,拥有对网页对象和模型样式编辑的能力。
爬虫基础知识至此结束,下一篇将对爬虫常用库进行进一步讲解。此外,爬虫所需的一些Python基础可参考下面的内容:
欢迎关注作者微信公众号:学习号,涉及数据分析与挖掘、数据结构与算法、大数据与机器学习等内容


















 4039
4039

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









