











跟着网络上的视频教程在linux上搭建完伪分布式集群后,在我的开发的机器上使用java api下载文件时出现上面的异常。
我学习hadoop是下班后学的,导致弄了好几天才解决这个问题。
一、首先,hadoop 的hdfs启动会把namenode绑定在fs.defaultFS配置的ip上,如果我们的服务器ip是外网的ip,那么可以把namenode绑定在该ip上,这样我们就可以在外网通过FileSystem访问hdfs了。
但是由于我用的是阿里云,踩到一个坑。
百度后了解到阿里云上应用程序不能绑定到外网ip(估计是阿里云服务器本身是一个虚拟机,与虽然可以通过公网ip访问,但是他们是把所有到公网ip请求映射转发到对应的内网ip上,然后阿里云的内网ip在阿里云内部是能够唯一指向一台虚拟机的)...所以,我把core-site.xml的fs.defaultFS配置改为hdfs://内网ip:9000就把hdfs启动成功了,namenode和datanode以及secondaryNamenode都成功了...然后用hadoop 的shell命令各种愉快的玩耍。
注意:阿里云内网ip就是用ifconfig看到的那个。
二、用shell愉快的玩耍没问题了,那就要试试用java api玩耍了。
在自己的电脑上用java ip 去连接我的阿里云服务器上的hadoop时,又出问题了。真蛋疼。
视频教程上的讲师他是在本机用虚拟机上的linux搭建的hadoop,然后后面竟然又在linux上安装图形界面以及linux版本的eclipse,我去,阿里云上的linux能安装图形界面吗?然后就算能安装我怎么远程控制图形界面?然后我就在本地直接用idea跟着敲hadoop下载文件的java代码。。然后讲师的是成功了,我就出现了开头那张图片上的异常。
不能够下载那个block。
我很气啊。
然后就是各种百度了,第一天,没弄成功。。。第二天。。没成功。。然后辞职了,然后新找了工作,
然后今天2019-5-19号终于成功了,其实主要是之前经过各种百度已经有思路了,今天就按照那个思路去尝试,然后就成功了。。贼tm高兴。。今天就不学了,写篇博客记录一下就玩和平精英去。。
1、具体原因
经过各种查找验证,找到了原因:
首先,namenode是可以访问的,但是java api(在本地windows执行)访问不了datanode,那自然是下载不了这个block了。
为什么访问不了datanode呢?继续看....
2、解决步骤
(1)发现datanode的默认端口是50010,我在阿里云上没开这个端口,只开了8088、9000、50070、50075,所以导致可以用50070查看hdfs的信息,甚至用网页版也可以下载文件(网页版下载文件估计不是直接去datanode,而是通过web服务器再中转的),但我在本机的java api上就是不行。
然后我就开启了50010端口,但还是没解决、、、GGGGGGGGG
当然,50010也是要开启的,否则也没用。这个算是找主要错误时不小心发现的另一个错误。。。嘿嘿
继续百度.....
(2)然后debug的时候看到FSDataInputStream的调试信息...然后看到下面这一段:

这不是要下载的block的信息么,然后看到圈起来的这一段,这ip是我阿里云服务器的内网ip,然后瞬间明白了。。
java api访问namenode获取文件的block信息,namenode只会返回该block所在datanode的机器的ip,在阿里云虚拟机中获取到的ip都是阿里云的内网ip,公网ip我们在阿里云控制台页面可以看到,但在机器内是拿不到的)。
此时,错误原因我们已经知道了。java api在本机执行,自然无法使用阿里云内网ip访问到datanode(计算机网络知识,不多说了)。
(3)怎么解决上面的问题呢?
百度....
然后知道在java api中配置:
config.set("dfs.client.use.datanode.hostname", "true");这个配置的作用是:让namenode返回datanode所在机器的hostname。。但是我这样做了,还是不行。。当然,这一步是必须的,不过后面还需要做一些事,使得hostname生效。
接下来在云服务器的/etc/hosts文件中需要配置datanode机器内网ip 与该机器的hostname的映射。。这个时候namenode返回datanode的主机名就会根据datanode绑定的ip从/etc/hosts文件中找到相应的hostname。。。这样的话,java api就可以拿到datanode的主机名了。(这一步总感觉没必要,因为后面我知道了/etc/hostname这个文件就是表示该机器主机名的,按理说获取主机名应该是通过该文件获取的吧)
如果云服务器绑定了域名的话,datanode所绑定的ip对应的主机名可以直接设置为域名,这样java api拿到的就是datanode所在服务器的域名了,java api通过该域名直接从datanode下载block,但是、、、没有域名咋办,我就是没有域名,只能通过外网ip远程访问云服务器。
解决办法就是:在java api应用程序执行的机器上的hosts文件上配置主机名与ip的映射关系。。
比如我java api程序就运行在我自己的电脑上,java api既然可以拿到datanode的hostname,那么我在我自己电脑上的hosts文件中加上该hostname与它的公网ip的映射就可以了。。
3、怎么配置hosts?
代码中加了config.set("dfs.client.use.datanode.hostname", "true");后,
java api从会从namenode拿到datanode所绑定的ip以及该ip在datanode所在机器的hosts文件中对应配置的hostname。
我在datanode所在的阿里云服务器上配置的映射是:
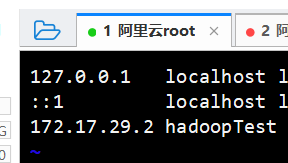
然后在java api获取相应block信息时就拿到block所在datanode所绑定的ip以及主机名。
我的datanode的内网ip就是上面这张图中的172.17.29.2,对应的hostname就是hadoopTest了。
java api获取block的信息就是:
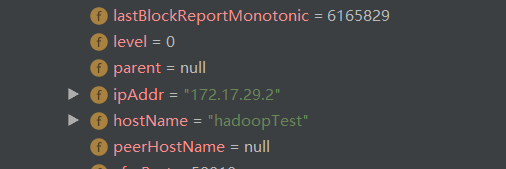
正是因为代码中加了config.set("dfs.client.use.datanode.hostname", "true");后,
hadoop的FileSystem就会使用获取到的hostname去访问datanode。。。前面说了,如果有域名,那么hostname配置为域名自然最好。。。
没有域名的话,那么就要在java api执行的机器上配置hosts文件。
并且是配置该hostname 与datanode所在机器的外网ip的映射:

然后FileSystem使用hostname的时候自然就会转为使用对应hosts文件的ip(如果不再hosts文件中配置,也可以在内网的dns上配置,那就相当于就是域名了)
在我的机器上就是:FileSystem使用hadoopTest这个hostname请求datanode,然后因为我本机hosts上配置了该hadoopTest的映射,所以hadoopTest会被替换为hosts上映射的ip,即47.106.x.x。
对我有参考的文章:















 571
571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









