









 这段代码展示了如何读取指定文件夹下的图片,通过比较图片名称的前四位来合并具有相同前缀的图片。在循环中,每次取出列表的第一个元素,找到所有前四位相同的图片,将它们的像素值相加,然后保存为新的图片。最终将所有图片合并成一张。
这段代码展示了如何读取指定文件夹下的图片,通过比较图片名称的前四位来合并具有相同前缀的图片。在循环中,每次取出列表的第一个元素,找到所有前四位相同的图片,将它们的像素值相加,然后保存为新的图片。最终将所有图片合并成一张。
- 读取路径下的文件,生成列表A(不一定是有序的)
- while()循环,判断列表A是否为空
- 取列表A的数值,每次取第一个,取完就删,所以每次取的值是不一样的。取第一个数值为a
- 获取数值a的前四位(观察发现,每张图片的前四位是一样的则合并),并从列表A中获取与a相同前四位的值生成列表B
- 遍历列表B,从列表B中取值b,将a与b进行相加,累加得到new_image,取完就删除b的值
- 将new_image矩阵转为image,进行保存
此文件夹下的图片可以合并为一张:
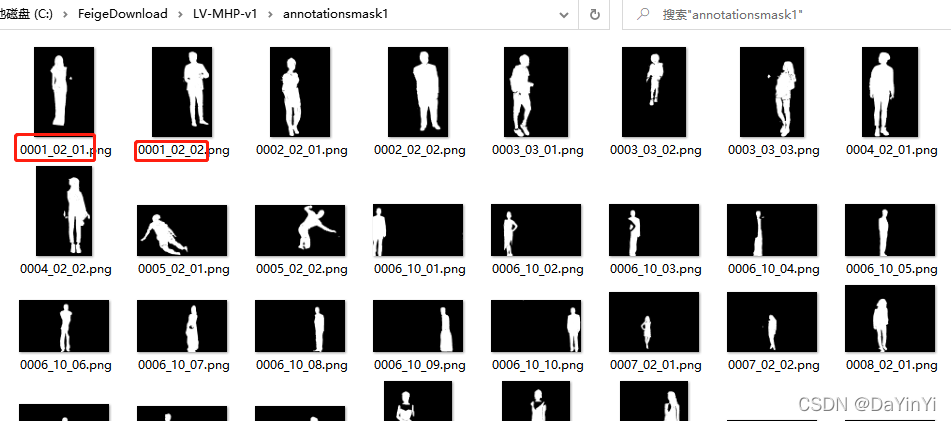
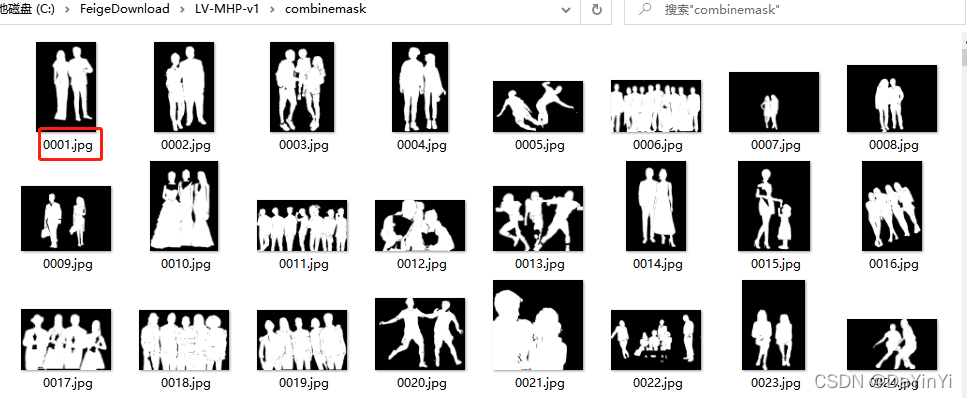
效果:
代码实现:
import os
import cv2
from PIL import Image
import numpy as np
fileFolderPath = 'C:\\FeigeDownload\\LV-MHP-v1\\annotationsmask1\\'
mask_list = os.listdir(fileFolderPath) # 该路径下的文件名 list 如果读成CSV文件,第一个数值为0的话会丢失,00001.jpg -> 1.jpg
save_path = 'C:\\FeigeDownload\\LV-MHP-v1\\combinemask\\'
def find(a_name, b_mask):
# 返回一个列表
fileDataAll = []
# 从列表中获取与特定字符相同的值,将它们写入一个列表中
for i in range(len(b_mask)):
if b_mask[i][0:4] == a_name:
fileDataAll.append(b_mask[i])
return fileDataAll
while(len(mask_list)): # 判断列表是否为空
# 每次取列表的第一位list[0],取完就删
name = mask_list[0][0:4] # 获取文件的前四位名
# 获取图片的像素值
mask_path = os.path.join(fileFolderPath, mask_list[0])
image = cv2.imread(mask_path)
# 从列表中删除该值,该图片已经读取了
mask_list.remove(mask_list[0])
# 找到列表中与图片前四位相同的图片
list = []
list = find(name, mask_list)
for i in range(0, len(list)):
list_path = os.path.join(fileFolderPath, list[i])
# 将两图片的像素值相加
image = cv2.add(image, cv2.imread(list_path))
mask_list.remove(list[i])
# 转为图片进行保存
color_img = Image.fromarray(np.uint8(image)) # Image.fromarray(np.uint8(img)):array转换成image
# 保存路径
vis_root = os.path.join(save_path, name + '.jpg')
color_img.save(vis_root)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









