







各区域Top3商品统计
统计各个区域中Top3的热门商品,热门商品的评判指标是商品被点击的次数,对于user_visit_action表,click_product_id表示被点击的商品。
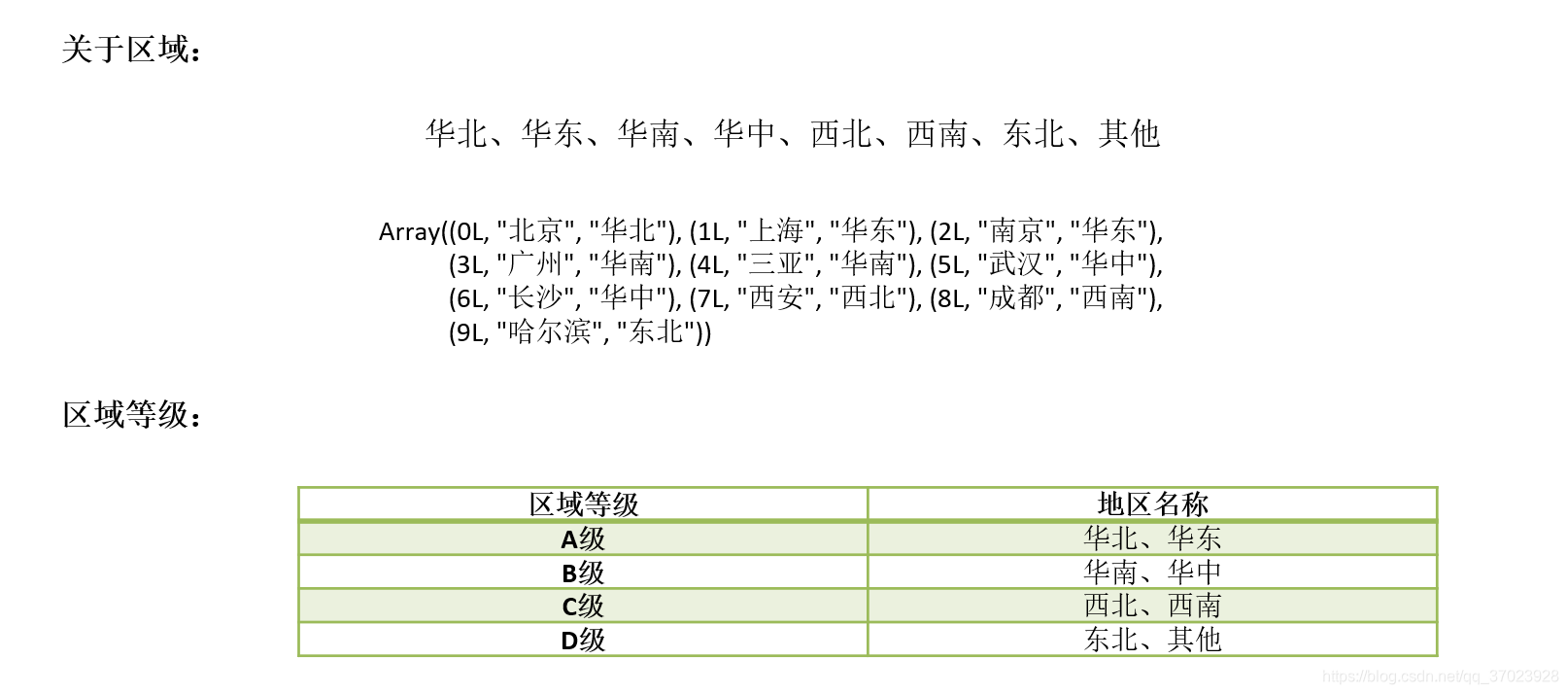
区域与等级:
数据流程:
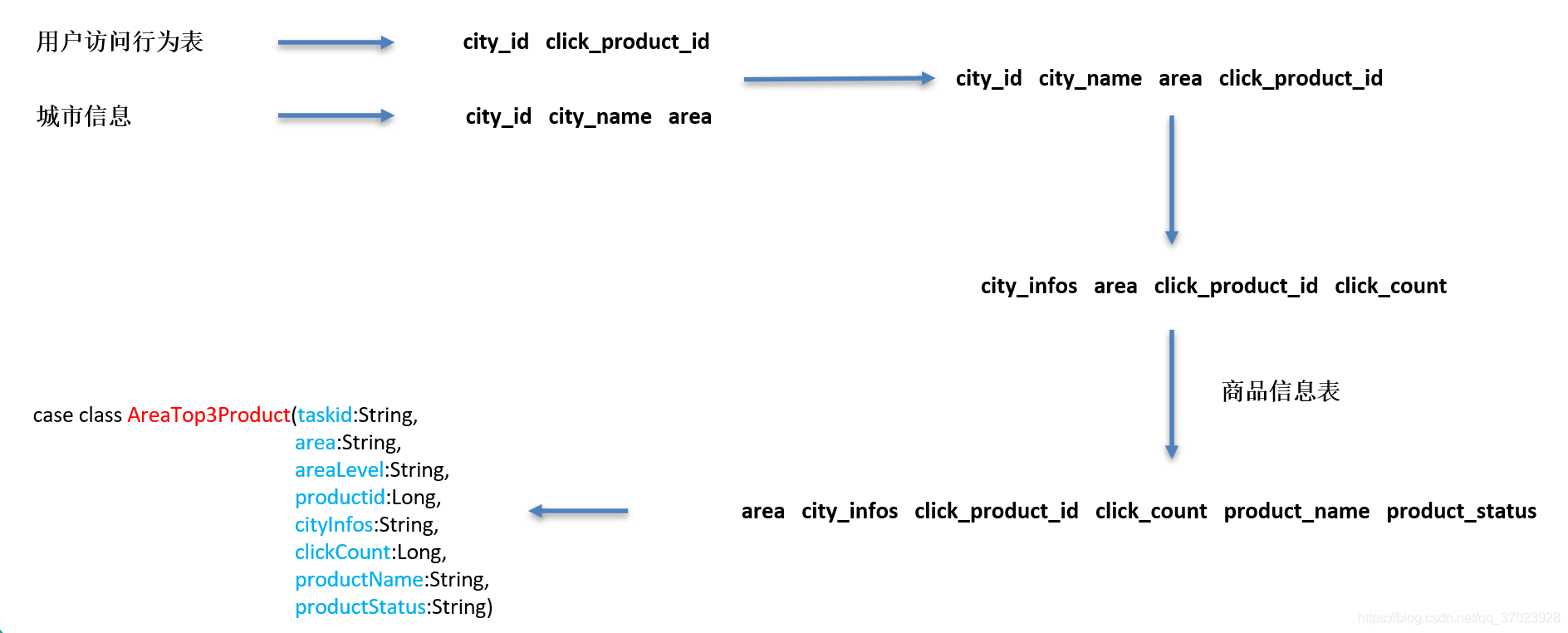
代码:
1.1 case class
case class CityClickProduct(city_id:Long,
click_product_id:Long)
case class CityAreaInfo(city_id:Long,
city_name:String,
area:String)
//***************** 输出表 *********************
/**
*
* @param taskid
* @param area
* @param areaLevel
* @param productid
* @param cityInfos
* @param clickCount
* @param productName
* @param productStatus
*/
case class AreaTop3Product(taskid:String,
area:String,
areaLevel:String,
productid:Long,
cityInfos:String,
clickCount:Long,
productName:String,
productStatus:String)
2.2 转换数据 RDD[(cityId, pid)]、RDD[(cityId, CityAreaInfo)]
def getCityAndProductInfo(sparkSession: SparkSession, taskParam: JSONObject) = {
val startDate = ParamUtils.getParam(taskParam, Constants.PARAM_START_DATE)
val endDate = ParamUtils.getParam(taskParam, Constants.PARAM_END_DATE)
// 只获取发生过点击的action的数据
// 获取到的一条action数据就代表一个点击行为
val sql = "select city_id, click_product_id from user_visit_action where date>='" + startDate +
"' and date<='" + endDate + "' and click_product_id != -1"
import sparkSession.implicits._
sparkSession.sql(sql).as[CityClickProduct].rdd.map{
case cityPid => (cityPid.city_id, cityPid.click_product_id)
}
}
def getCityAreaInfo(sparkSession: SparkSession) = {
val cityAreaInfoArray = Array((0L, "北京", "华北"), (1L, "上海", "华东"), (2L, "南京", "华东"),
(3L, "广州", "华南"), (4L, "三亚", "华南"), (5L, "武汉", "华中"),
(6L, "长沙", "华中"), (7L, "西安", "西北"), (8L, "成都", "西南"),
(9L, "哈尔滨", "东北"))
// RDD[(cityId, CityAreaInfo)]
sparkSession.sparkContext.makeRDD(cityAreaInfoArray).map{
case (cityId, cityName, area) =>
(cityId, CityAreaInfo(cityId, cityName, area))
}
def main(args: Array[String]): Unit = {
val jsonStr = ConfigurationManager.config.getString(Constants.TASK_PARAMS)
val taskParam = JSONObject.fromObject(jsonStr)
val taskUUID = UUID.randomUUID().toString
val sparkConf = new SparkConf().setAppName("area").setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
// 数据转换为RDD[(cityId, pid)]
val cityId2PidRDD = getCityAndProductInfo(sparkSession, taskParam)
// 数据转换为RDD[(cityId, CityAreaInfo)]
val cityId2AreaInfoRDD = getCityAreaInfo(sparkSession)
}
2.3聚合上面的数据
tmp_area_basic_info
def getAreaPidBasicInfoTable(sparkSession: SparkSession,
cityId2PidRDD: RDD[(Long, Long)],
cityId2AreaInfoRDD: RDD[(Long, CityAreaInfo)]): Unit = {
val areaPidInfoRDD = cityId2PidRDD.join(cityId2AreaInfoRDD).map{
case (cityId, (pid, areaInfo)) =>
(cityId, areaInfo.city_name, areaInfo.area, pid)
}
import sparkSession.implicits._
areaPidInfoRDD.toDF("city_id", "city_name", "area", "pid").createOrReplaceTempView("tmp_area_basic_info")
}
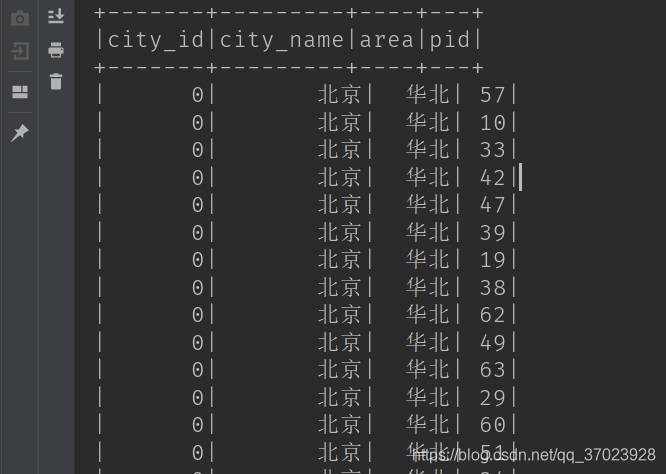
在main函数中调用,并打印一下数据:
// tmp_area_basic_info: 表中的一条数据就代表一次点击商品的行为
getAreaPidBasicInfoTable(sparkSession, cityId2PidRDD, cityId2AreaInfoRDD)
sparkSession.sql("select * from tmp_area_basic_info").show()
结果:
2.4使用UDAF
def getAreaProductClickCountTable(sparkSession: SparkSession): Unit = {
val sql = "select area, pid, count(*) click_count," +
" group_concat_distinct(concat_long_string(city_id, city_name, ':')) city_infos" +
" from tmp_area_basic_info group by area, pid"
sparkSession.sql(sql).createOrReplaceTempView("tmp_area_click_count")
}
上面的sql语句,由于使用了group by,所以select中的字段只能是group by后面的字段,现在希望能够得到城市相关信息,所以使用UDAF函数。
class GroupConcatDistinct extends UserDefinedAggregateFunction{
// UDAF:输入数据类型为String
override def inputSchema: StructType = StructType(StructField("cityInfo", StringType)::Nil)
// 缓冲区类型
override def bufferSchema: StructType = StructType(StructField("bufferCityInfo", StringType)::Nil)
// 输出数据类型
override def dataType: DataType = StringType
override def deterministic: Boolean = true
override def initialize(buffer: MutableAggregationBuffer): Unit = {
buffer(0) = ""
}
override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
var bufferCityInfo = buffer.getString(0)
val cityInfo = input.getString(0)
if(!bufferCityInfo.contains(cityInfo)){
if("".equals(bufferCityInfo)){
bufferCityInfo += cityInfo
}else{
bufferCityInfo += "," + cityInfo
}
buffer.update(0, bufferCityInfo)
}
}
override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
// bufferCityInfo1: cityId1:cityName1, cityId2:cityName2
var bufferCityInfo1 = buffer1.getString(0)
// bufferCityInfo2: cityId1:cityName1, cityId2:cityName2
val bufferCityInfo2 = buffer2.getString(0)
for(cityInfo <- bufferCityInfo2.split(",")){
if(!bufferCityInfo1.contains(cityInfo)){
if("".equals(bufferCityInfo1)){
bufferCityInfo1 += cityInfo
}else{
bufferCityInfo1 += "," + cityInfo
}
}
}
buffer1.update(0, bufferCityInfo1)
}
override def evaluate(buffer: Row): Any = {
buffer.getString(0)
}
}
在main函数中,注册一下UDAF函数,并且打印一下:
sparkSession.udf.register("concat_long_string", (v1:Long, v2:String, split:String) =>{
v1 + split + v2
})
sparkSession.udf.register("group_concat_distinct", new GroupConcatDistinct)
getAreaProductClickCountTable(sparkSession)
sparkSession.sql("select * from tmp_area_click_count").show()
打印结果:
+----+---+-----------+----------+
|area|pid|click_count|city_infos|
+----+---+-----------+----------+
| 西北| 43| 18| 7:西安|
| 西南| 70| 12| 8:成都|
| 东北| 77| 10| 9:哈尔滨|
| 华中| 40| 35| 5:武汉,6:长沙|
| 华中| 57| 22| 5:武汉,6:长沙|
| 西南| 62| 9| 8:成都|
| 华东| 73| 33| 1:上海,2:南京|
| 西南| 65| 18| 8:成都|
| 华中| 0| 28| 5:武汉,6:长沙|
| 华北| 50| 11| 0:北京|
| 华南| 45| 32| 3:广州,4:三亚|
| 东北| 52| 19| 9:哈尔滨|
.....................................
2.5扩展字段转换
def getAreaProductClickCountInfo(sparkSession: SparkSession) = {
// tmp_area_click_count: area, city_infos, pid, click_count tacc
// product_info: product_id, product_name, extend_info pi
val sql = "select tacc.area, tacc.city_infos, tacc.pid, pi.product_name, " +
"if(get_json_field(pi.extend_info, 'product_status')='0','Self','Third Party') product_status," +
"tacc.click_count " +
" from tmp_area_click_count tacc join product_info pi on tacc.pid = pi.product_id"
sparkSession.sql(sql).createOrReplaceTempView("tmp_area_count_product_info")
}
在main函数中:
sparkSession.udf.register("get_json_field", (json:String, field:String) => {
val jsonObject = JSONObject.fromObject(json)
jsonObject.getString(field)
})
getAreaProductClickCountInfo(sparkSession)
sparkSession.sql("select * from tmp_area_count_product_info").show()
输出结果:
+----+----------+---+------------+--------------+-----------+
|area|city_infos|pid|product_name|product_status|click_count|
+----+----------+---+------------+--------------+-----------+
| 西北| 7:西安| 43| product43| Third Party| 18|
| 西南| 8:成都| 70| product70| Self| 12|
| 东北| 9:哈尔滨| 77| product77| Self| 10|
| 华中| 5:武汉,6:长沙| 40| product40| Self| 35|
| 华中| 5:武汉,6:长沙| 57| product57| Self| 22|
| 西南| 8:成都| 62| product62| Self| 9|
| 华东| 1:上海,2:南京| 73| product73| Self| 33|
| 西南| 8:成都| 65| product65| Self| 18|
| 华中| 5:武汉,6:长沙| 0| product0| Self| 28|
| 华北| 0:北京| 50| product50| Self| 11|
| 华南| 3:广州,4:三亚| 45| product45| Third Party| 32|
| 东北| 9:哈尔滨| 52| product52| Third Party| 19|
2.6获取top3(使用开窗函数),结果写入mysql
def getTop3Product(sparkSession: SparkSession, taskUUID: String) = {
/* val sql = "select area, city_infos, pid, product_name, product_status, click_count, " +
"row_number() over(PARTITION BY area ORDER BY click_count DESC) rank from tmp_area_count_product_info"
sparkSession.sql(sql).createOrReplaceTempView("temp_test")*/
val sql = "select area, " +
"CASE " +
"WHEN area='华北' OR area='华东' THEN 'A_Level' " +
"WHEN area='华中' OR area='华南' THEN 'B_Level' " +
"WHEN area='西南' OR area='西北' THEN 'C_Level' " +
"ELSE 'D_Level' " +
"END area_level, " +
"city_infos, pid, product_name, product_status, click_count from (" +
"select area, city_infos, pid, product_name, product_status, click_count, " +
"row_number() over(PARTITION BY area ORDER BY click_count DESC) rank from " +
"tmp_area_count_product_info) t where rank<=3"
val top3ProductRDD = sparkSession.sql(sql).rdd.map{
case row =>
AreaTop3Product(taskUUID, row.getAs[String]("area"), row.getAs[String]("area_level"),
row.getAs[Long]("pid"), row.getAs[String]("city_infos"),
row.getAs[Long]("click_count"), row.getAs[String]("product_name"),
row.getAs[String]("product_status"))
}
import sparkSession.implicits._
top3ProductRDD.toDF().write
.format("jdbc")
.option("url", ConfigurationManager.config.getString(Constants.JDBC_URL))
.option("dbtable", "area_top3_product_0308")
.option("user", ConfigurationManager.config.getString(Constants.JDBC_USER))
.option("password", ConfigurationManager.config.getString(Constants.JDBC_PASSWORD))
.mode(SaveMode.Append)
.save()
}
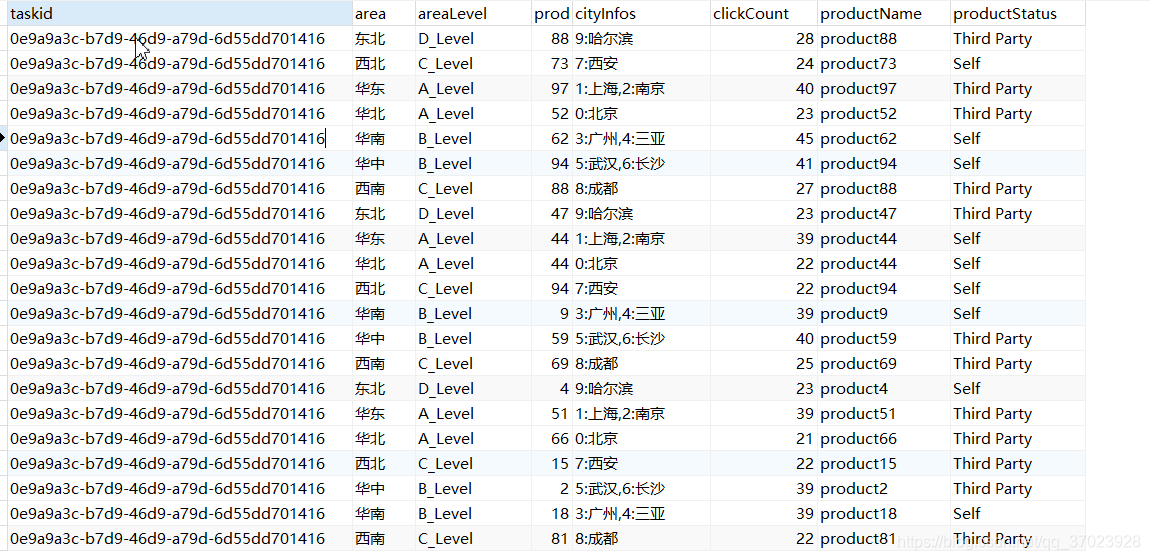
结果:
2.7 开窗函数回顾
开窗函数与聚合函数一样,都是对行的集合组进行聚合计算。
开窗用于为行定义一个窗口(这里的窗口是指运算将要操作的行的集合),它对一组值进行操作,不需要使用GROUP BY 子句对数据进行分组,能够在同一行中同时返回基础行的列和聚合列。
开窗函数的调用格式为:函数名( 列) OVER( 选项)
第一大类:聚合开窗函数----> 聚合函数(列) OVER (选项),这里的选项可以是PARTITION BY 子句,但不可是 ORDER BY 子句。
第二大类:排序开窗函数 ---->排序函数(列) OVER(选项),这里的选项可以是ORDER BY 子句,也可以是 OVER(PARTITION BY 子句 ORDER BY 子句),但不可以是 PARTITION BY 子句。
聚合开窗函数:
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("score").setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
import sparkSession.implicits._
val scoreDF = sparkSession.sparkContext.makeRDD(Array(Score("a1", 1, 80),
Score("a2", 1, 78),
Score("a3", 1, 95),
Score("a4", 2, 74),
Score("a5", 2, 92),
Score("a6", 3, 99),
Score("a7", 3, 99),
Score("a8", 3, 45),
Score("a9", 3, 55),
Score("a10", 3, 78))).toDF("name", "class", "score")
scoreDF.createOrReplaceTempView("score")
scoreDF.show()
sparkSession.sql("select name, class, score, count(name) over() name_count from score").show()
}
查询结果:
+----+-----+-----+----------+
|name|class|score|name_count|
+----+-----+-----+----------+
| a1| 1| 80.0| 10|
| a2| 1| 78.0| 10|
| a3| 1| 95.0| 10|
| a4| 2| 74.0| 10|
| a5| 2| 92.0| 10|
| a6| 3| 99.0| 10|
| a7| 3| 99.0| 10|
| a8| 3| 45.0| 10|
| a9| 3| 55.0| 10|
| a10| 3| 78.0| 10|
+----+-----+-----+----------+
在上边的例子中,开窗函数 COUNT(*) OVER()对于查询结果的每一行都返回所有符合条件的行的条数。OVER 关键字后的括号中还经常添加选项用以改变进行聚合运算的窗口范围。如果 OVER 关键字后的括号中的选项为空,则开窗函数会对结果集中的所有行进行聚合运算。
开窗函数的 OVER 关键字后括号中的可以使用 PARTITION BY 子句来定义行的分区来供进行聚合计算。与 GROUP BY 子句不同,PARTITION BY 子句创建的分区是独立于结果集的,创建的分区只是供进行聚合计算的,而且不同的开窗函数所创建的分区也不互相影响。下面的 SQL语句用于显示按照班级分组后每组的人数:
sparkSession.sql("select name, class, score, count(name) over(partition by class) name_count from score").show()
查询结果:
+----+-----+-----+----------+
|name|class|score|name_count|
+----+-----+-----+----------+
| a1| 1| 80.0| 3|
| a2| 1| 78.0| 3|
| a3| 1| 95.0| 3|
| a6| 3| 99.0| 5|
| a7| 3| 99.0| 5|
| a8| 3| 45.0| 5|
| a9| 3| 55.0| 5|
| a10| 3| 78.0| 5|
| a4| 2| 74.0| 2|
| a5| 2| 92.0| 2|
+----+-----+-----+----------+
排序开窗函数:
对于排序开窗函数来讲,它支持的开窗函数分别为:ROW_NUMBER(行号)、RANK(排名)、DENSE_RANK(密集排名)和 NTILE(分组排名)
sparkSession.sql("select name, class, score, row_number() over(order by score) rank from score").show()
row_number执行结果:
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a8| 3| 45.0| 1|
| a9| 3| 55.0| 2|
| a4| 2| 74.0| 3|
| a2| 1| 78.0| 4|
| a10| 3| 78.0| 5|
| a1| 1| 80.0| 6|
| a5| 2| 92.0| 7|
| a3| 1| 95.0| 8|
| a6| 3| 99.0| 9|
| a7| 3| 99.0| 10|
+----+-----+-----+----+
Rank:
sparkSession.sql("select name, class, score, rank() over(order by score) rank from score").show()
RANK执行结果:
有重复,有跳跃
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a8| 3| 45.0| 1|
| a9| 3| 55.0| 2|
| a4| 2| 74.0| 3|
| a2| 1| 78.0| 4|
| a10| 3| 78.0| 4|
| a1| 1| 80.0| 6|
| a5| 2| 92.0| 7|
| a3| 1| 95.0| 8|
| a6| 3| 99.0| 9|
| a7| 3| 99.0| 9|
+----+-----+-----+----+
dense_rank:
sparkSession.sql("select name, class, score, dense_rank() over(order by score) rank from score").show()
dense_rank执行结果:
有重复,无跳跃
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a8| 3| 45.0| 1|
| a9| 3| 55.0| 2|
| a4| 2| 74.0| 3|
| a2| 1| 78.0| 4|
| a10| 3| 78.0| 4|
| a1| 1| 80.0| 5|
| a5| 2| 92.0| 6|
| a3| 1| 95.0| 7|
| a6| 3| 99.0| 8|
| a7| 3| 99.0| 8|
+----+-----+-----+----+
ntile:
sparkSession.sql("select name, class, score, ntile(6) over(order by score) rank from score").show()
ntile执行结果:
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a8| 3| 45.0| 1|
| a9| 3| 55.0| 1|
| a4| 2| 74.0| 2|
| a2| 1| 78.0| 2|
| a10| 3| 78.0| 3|
| a1| 1| 80.0| 3|
| a5| 2| 92.0| 4|
| a3| 1| 95.0| 4|
| a6| 3| 99.0| 5|
| a7| 3| 99.0| 6|
+----+-----+-----+----+
先按照score进行排序,再分6组。
2.8 各区域Top3商品统计完整代码
package com.atguigu.session.test
import java.util.UUID
import com.atguigu.commons.conf.ConfigurationManager
import com.atguigu.commons.constant.Constants
import com.atguigu.commons.utils.ParamUtils
import net.sf.json.JSONObject
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{SaveMode, SparkSession}
/**
* ClassName:AreaTop3Stat
* Package:com.atguigu.session.test
* Desciption:
*
* @date:2020 /5/13 20:05
* @author:17611219021 @sina.cn
*/
object AreaTop3Stat {
def getCityAndProductInfo(sparkSession: SparkSession, taskParam: JSONObject) = {
val startDate = ParamUtils.getParam(taskParam, Constants.PARAM_START_DATE)
val endDate = ParamUtils.getParam(taskParam, Constants.PARAM_END_DATE)
// 只获取发生过点击的action的数据
// 获取到的一条action数据就代表一个点击行为
val sql = "select city_id, click_product_id from user_visit_action where date>='" + startDate +
"' and date<='" + endDate + "' and click_product_id != -1"
import sparkSession.implicits._
sparkSession.sql(sql).as[CityClickProduct].rdd.map{
case cityPid => (cityPid.city_id, cityPid.click_product_id)
}
}
def getCityAreaInfo(sparkSession: SparkSession) = {
val cityAreaInfoArray = Array((0L, "北京", "华北"), (1L, "上海", "华东"), (2L, "南京", "华东"),
(3L, "广州", "华南"), (4L, "三亚", "华南"), (5L, "武汉", "华中"),
(6L, "长沙", "华中"), (7L, "西安", "西北"), (8L, "成都", "西南"),
(9L, "哈尔滨", "东北"))
// RDD[(cityId, CityAreaInfo)]
sparkSession.sparkContext.makeRDD(cityAreaInfoArray).map{
case (cityId, cityName, area) =>
(cityId, CityAreaInfo(cityId, cityName, area))
}
}
def getAreaPidBasicInfoTable(sparkSession: SparkSession,
cityId2PidRDD: RDD[(Long, Long)],
cityId2AreaInfoRDD: RDD[(Long, CityAreaInfo)]): Unit = {
val areaPidInfoRDD = cityId2PidRDD.join(cityId2AreaInfoRDD).map{
case (cityId, (pid, areaInfo)) =>
(cityId, areaInfo.city_name, areaInfo.area, pid)
}
import sparkSession.implicits._
areaPidInfoRDD.toDF("city_id", "city_name", "area", "pid").createOrReplaceTempView("tmp_area_basic_info")
}
def getAreaProductClickCountTable(sparkSession: SparkSession): Unit = {
val sql = "select area, pid, count(*) click_count," +
" group_concat_distinct(concat_long_string(city_id, city_name, ':')) city_infos" +
" from tmp_area_basic_info group by area, pid"
sparkSession.sql(sql).createOrReplaceTempView("tmp_area_click_count")
}
def getAreaProductClickCountInfo(sparkSession: SparkSession) = {
// tmp_area_click_count: area, city_infos, pid, click_count tacc
// product_info: product_id, product_name, extend_info pi
val sql = "select tacc.area, tacc.city_infos, tacc.pid, pi.product_name, " +
"if(get_json_field(pi.extend_info, 'product_status')='0','Self','Third Party') product_status," +
"tacc.click_count " +
" from tmp_area_click_count tacc join product_info pi on tacc.pid = pi.product_id"
sparkSession.sql(sql).createOrReplaceTempView("tmp_area_count_product_info")
}
def getTop3Product(sparkSession: SparkSession, taskUUID: String) = {
/* val sql = "select area, city_infos, pid, product_name, product_status, click_count, " +
"row_number() over(PARTITION BY area ORDER BY click_count DESC) rank from tmp_area_count_product_info"
sparkSession.sql(sql).createOrReplaceTempView("temp_test")*/
val sql = "select area, " +
"CASE " +
"WHEN area='华北' OR area='华东' THEN 'A_Level' " +
"WHEN area='华中' OR area='华南' THEN 'B_Level' " +
"WHEN area='西南' OR area='西北' THEN 'C_Level' " +
"ELSE 'D_Level' " +
"END area_level, " +
"city_infos, pid, product_name, product_status, click_count from (" +
"select area, city_infos, pid, product_name, product_status, click_count, " +
"row_number() over(PARTITION BY area ORDER BY click_count DESC) rank from " +
"tmp_area_count_product_info) t where rank<=3"
val top3ProductRDD = sparkSession.sql(sql).rdd.map{
case row =>
AreaTop3Product(taskUUID, row.getAs[String]("area"), row.getAs[String]("area_level"),
row.getAs[Long]("pid"), row.getAs[String]("city_infos"),
row.getAs[Long]("click_count"), row.getAs[String]("product_name"),
row.getAs[String]("product_status"))
}
import sparkSession.implicits._
top3ProductRDD.toDF().write
.format("jdbc")
.option("url", ConfigurationManager.config.getString(Constants.JDBC_URL))
.option("dbtable", "area_top3_product_0308")
.option("user", ConfigurationManager.config.getString(Constants.JDBC_USER))
.option("password", ConfigurationManager.config.getString(Constants.JDBC_PASSWORD))
.mode(SaveMode.Append)
.save()
}
def main(args: Array[String]): Unit = {
val jsonStr = ConfigurationManager.config.getString(Constants.TASK_PARAMS)
val taskParam = JSONObject.fromObject(jsonStr)
val taskUUID = UUID.randomUUID().toString
val sparkConf = new SparkConf().setAppName("area").setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).enableHiveSupport().getOrCreate()
// 数据转换为RDD[(cityId, pid)]
val cityId2PidRDD = getCityAndProductInfo(sparkSession, taskParam)
// 数据转换为RDD[(cityId, CityAreaInfo)]
val cityId2AreaInfoRDD = getCityAreaInfo(sparkSession)
// tmp_area_basic_info: 表中的一条数据就代表一次点击商品的行为
getAreaPidBasicInfoTable(sparkSession, cityId2PidRDD, cityId2AreaInfoRDD)
//sparkSession.sql("select * from tmp_area_basic_info").show()
sparkSession.udf.register("concat_long_string", (v1:Long, v2:String, split:String) =>{
v1 + split + v2
})
sparkSession.udf.register("group_concat_distinct", new GroupConcatDistinct)
getAreaProductClickCountTable(sparkSession)
//sparkSession.sql("select * from tmp_area_click_count").show()
sparkSession.udf.register("get_json_field", (json:String, field:String) => {
val jsonObject = JSONObject.fromObject(json)
jsonObject.getString(field)
})
getAreaProductClickCountInfo(sparkSession)
//sparkSession.sql("select * from tmp_area_count_product_info").show()
getTop3Product(sparkSession, taskUUID)
}
}














 200
200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









