









背景:
通常线上服务的内存泄漏问题排查,大致步骤如下:
- 尝试复现问题
- 结合go pprof等工具分析内存使用情况,及对应的函数调用栈
- 发现问题所在
- 修复问题,验证问题是否解决
- 回归测试,打包上线
那么接下来就来介绍下go pprof性能分析工具的基本使用方法 ~ 进入正题 …
一、Go导入pprof包的选择及go版本要求:
- 如果你是使用 net/http 包来构建web服务(有启动http服务),想查看服务运行的相关状态,就可以使用
net/http/pprof包,导入方式:"_ net/http/pprof",匿名引用是为了执行其 init() 函数,只要其 init() 函数被执行,pprof 就会自动持续地监控我们的程序了。基本不需要主动在程序中调用代码采集和输出性能分析结果。 - 但如果只是一个普通的单机程序,就只能使用原生的
"runtime/pprof"了,需要主动在程序中调用代码采集和输出性能分析结果。 - 如果你是使用 github.com/gin-gonic/gin 包来构建web服务,想查看服务运行的相关状态,就需要使用
github.com/gin-contrib/pprof包。本文是使用gin框架来构建web服务的,因此导入的是"github.com/gin-contrib/pprof"包。具体gin框架构建web服务示例可参考:GO Gin框架的Post/Get请求示例
- go version >= 1.1
- 由源码可知,基于 http 的 pprof 是在你页面请求 profile 时,它会临时采集一个时间区间(比如30秒)内的对应性能数据,如下图;而访问其他指标会立即返回。所以在采集数据时需要先压测,这样才会有数据。
二、代码中嵌入pprof的使用示例
使用Go语言的pprof工具来分析一个函数的各部分执行耗时。具体实现可以按照以下步骤:
1. 在函数中插入pprof.StartCPUProfile()和defer pprof.StopCPUProfile()语句,用于启动和停止CPU性能分析器。
2. 运行程序,并使用go tool pprof命令连接到正在运行的程序。
3. 使用pprof工具的web命令生成一个交互式的HTML报告,该报告显示了函数的各部分执行耗时。
以下是一个示例代码:
package main
import (
"fmt"
"os"
"runtime/pprof"
)
func main() {
f, err := os.Create("profile.prof")
if err != nil {
fmt.Println(err)
return
}
defer f.Close()
if err := pprof.StartCPUProfile(f); err != nil {
fmt.Println(err)
return
}
defer pprof.StopCPUProfile()
sum := 0
for i := 0; i < 100000000; i++ {
sum += i
}
fmt.Println(sum)
}
在上面的示例代码中,我们使用pprof.StartCPUProfile()函数启动CPU性能分析器,并使用defer pprof.StopCPUProfile()函数停止CPU性能分析器。我们还使用os.Create()函数创建一个名为profile.prof的文件,用于保存分析结果。最后,我们使用go tool pprof命令连接到正在运行的程序,并使用web命令生成一个交互式的HTML报告。该报告显示了函数的各部分执行耗时
在得到 profile.prof 文件后,你可以使用 go tool pprof 命令来分析和查看性能剖析数据。以下是一些常用的命令和用法:
- 通过命令行查看分析结果:
go tool pprof profile.prof - 生成交互式的命令行报告:
go tool pprof -text profile.prof - 生成交互式的 Web 报告:
go tool pprof -web profile.prof - 在命令行中查看某个函数的耗时:
go tool pprof -text -function 函数名 profile.prof - 在 Web 界面中查看某个函数的耗时:
go tool pprof -web -function 函数名 profile.prof
在进入 pprof 命令行界面后,你可以使用 top命令查看耗时最高的函数,使用 list命令查看函数的源代码和耗时分布,使用 web 命令在浏览器中打开交互式的 Web 报告。
除了使用命令行工具,你还可以使用一些第三方工具,如 go-torch、go-delve 等,来可视化和分析性能剖析数据。
请注意,分析性能剖析数据需要在具有足够运行时间和工作负载的情况下进行,以获得准确的结果。
更多详情请继续往下看~
三、pprof查看web服务原始状态数据
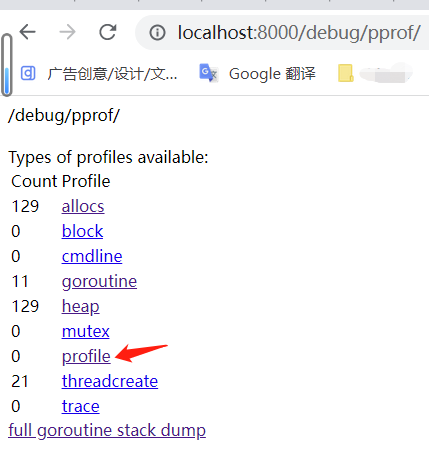
浏览器访问:http://localhost:8000/debug/pprof/,结果如图:
注意:
- 端口使用你自己web服务的监听端口号,例如我这里是:8000 端口
- 采集前需要先压测,在压测过程中才会有数据被收集
四、go tool pprof 数据图形可视化
通过 pprof 得到的信息都是原始数据,阅读起来很费劲,我们可以通过 go tool pprof 命令来辅助查看以及将原始数据图形化的方式来展示。
-
下载安装可视化图形软件工具 graphviz :https://graphviz.org/download/。可自行选择Linux、Windows、Mac等对应版本,并且记得将该工具添加到系统环境变量中,否则会报错:
failed to execute dot. Is Graphviz installed? Error: exec: "dot": executable file not found in %PATH%。我这里下载的是windows-64位的版本。

-
采集前需要先压测,在压测过程中才会有数据被收集:
- go-wrk 是一个用Go语言实现的轻量级的http基准测试工具,先下载压测go工具:
go get github.com/adjust/go-wrk go-wrk -c=400 -t=8 -n=100000 http://127.0.0.1:8000/api/getReq。400个连接,8个线程, 模拟10w次请求。具体可参考:通过go-wrk进行HTTP接口压力测试。
注意:压测试,wrk的命令行参数只能发送类似于 get、delete 这种不在请求体body中带参数的http请求。如果要发送 post 这类请求,必须要写Lua脚本。 具体可参考:wrk入门(2):发送post请求
go-wrk 压测结果如下图所示:
- 压测的同时采集数据,并生成 profile 数据分析-结果文件:
- cpu概要文件(在默认情况下,Go语言的运行时系统会以100 Hz的频率对CPU使用情况进行取样):
go tool pprof http://127.0.0.1:8000/debug/pprof/profile - 内存概要文件(保存在用户程序执行期间的堆内存使用情况):
go tool pprof http://127.0.0.1:8000/debug/pprof/heap - 程序阻塞概要文件(保存用户程序中的Goroutine阻塞事件的记录):
go tool pprof http://127.0.0.1:8000/debug/pprof/goroutine
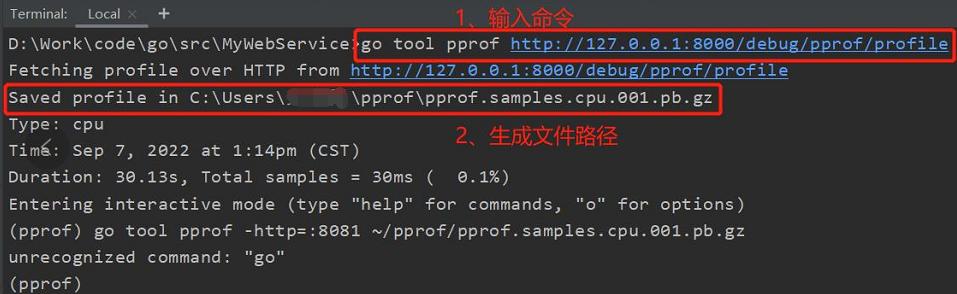
注意: - 由提示可知,它是先将下载的原始数据保存在临时文件,然后再进一步去分析。比如图中所示的 pprof.samples.cpu.001.pb.gz
-
记住关键点:不管哪种方式收集,一定是在服务正在被压测或者业务逻辑正在执行的同时启动收集
\color{blue}{记住关键点:不管哪种方式收集,一定是在 服务正在被压测 或者 业务逻辑正在执行的同时 启动收集}
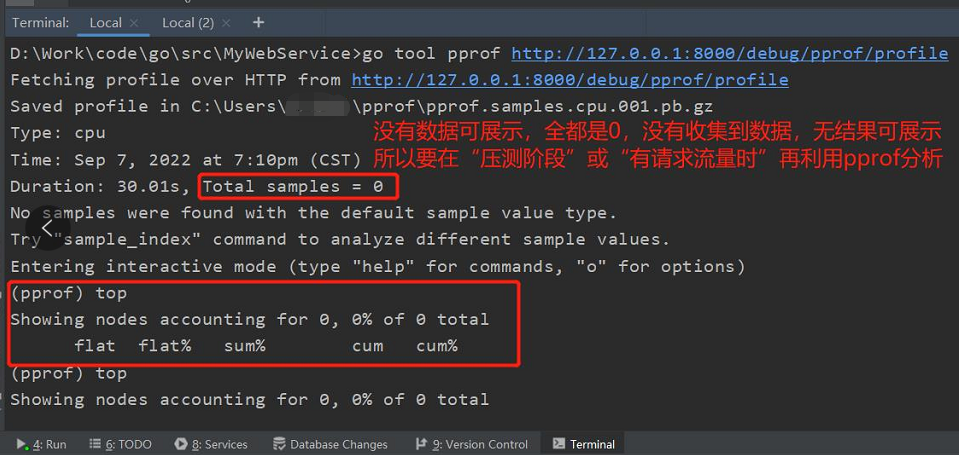
记住关键点:不管哪种方式收集,一定是在服务正在被压测或者业务逻辑正在执行的同时启动收集;刚开始不熟悉流程,可能在服务都没有任何请求的时候就去收集,这是毫无意义的,也不会收集到明显的 profile 信息,可能就会像下面这样,啥数据都看不到:
- 然后会进入一个交互界面,列表中各参数代表含义如下:
flat:当前函数占用CPU的时间
flat%:当前函数占用CPU百分比
sum%:当前所有函数累加使用 CPU 的比例
cum:当前函数以及子函数占用CPU的时间
cum%:当前函数以及子函数占用CPU的百分比
另外交互界面常用命令如下:
help:命令可以提供所有pprof支持的命令说明
top 10:列出前10
web:调用 graphviz 生成svg图片并打开
list:查看具体的函数分析
pdf:命令可以生成可视化的pdf文件
tree:以树状显示
png:以图片格式输出
svg:生成浏览器可以识别的svg文件
pprof具体定位代码段示例:
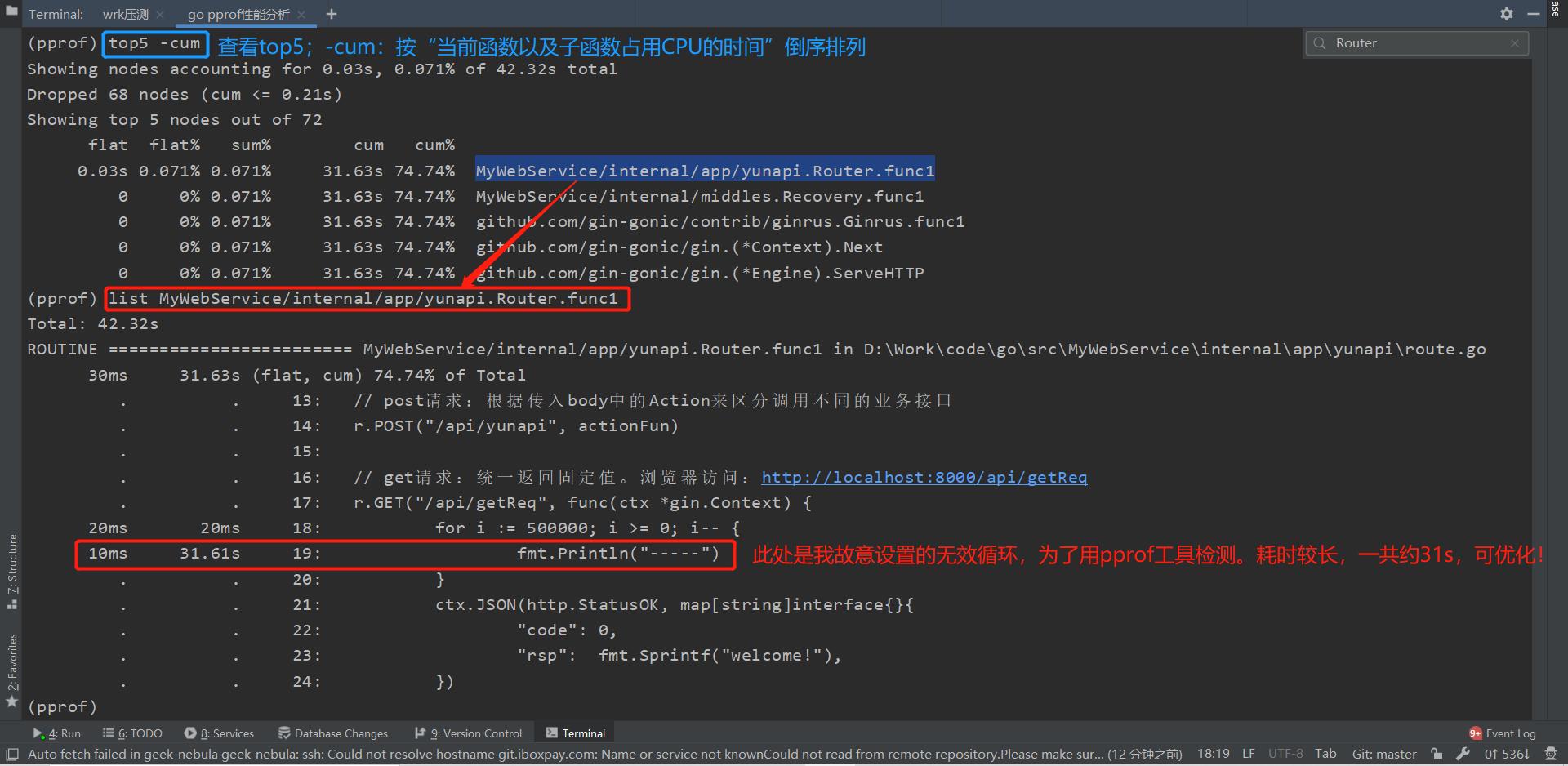
此处可以通过终端交互方式来定位具体耗时较长的代码段,如下:
top5 -cum:按 “当前函数以及子函数占用CPU的时间” 倒序排列list MyWebService/internal/app/yunapi.Router.func1:根据具体调用函数名来查找对应代码段。可以看到下方的 “无效循环” 是导致此处执行耗时较长的根因,所以可以针对性的做优化,比如去除 “无效循环”
示例:当输入 web 后,会自动生成.svg文件,并在浏览器中显示可视化图形分析,如图所示: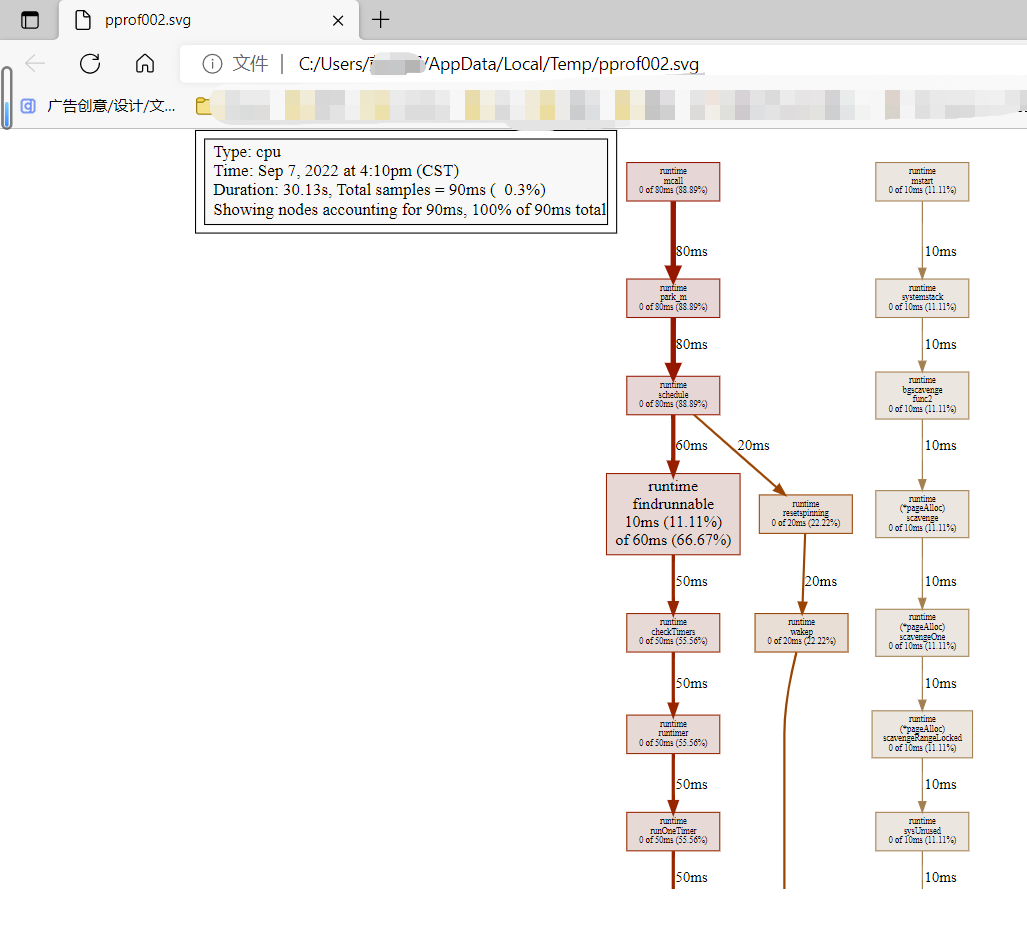
流程图中有不同被调函数运行时长所占百分比,同时方框越大对应CPU耗时越久。不过只是这样仍然很难去分析,还有更直观的方式 ~
-
退出命令行,复制上面步骤3图中 Saved profile 后面的文件名及路径,比如:C:\Users\xxx\pprof\pprof.samples.cpu.001.pb.gz
-
输入以下
go tool pprof xxx命令,会自动打开浏览器图形可视化页面,包含火焰图等…(其中-http=:8081,或-http localhost:8081会启动一个http服务,端口为8081,然后浏览器会弹出此结果文件的图示页面)
- linux下:
go tool pprof -http=:8081 ~/pprof/pprof.samples.cpu.001.pb.gz - windows下路径用双反斜杠表示:
go tool pprof -http localhost:8081 C:\\Users\\xxx\\pprof\\pprof.samples.cpu.001.pb.gz

Graph图示:
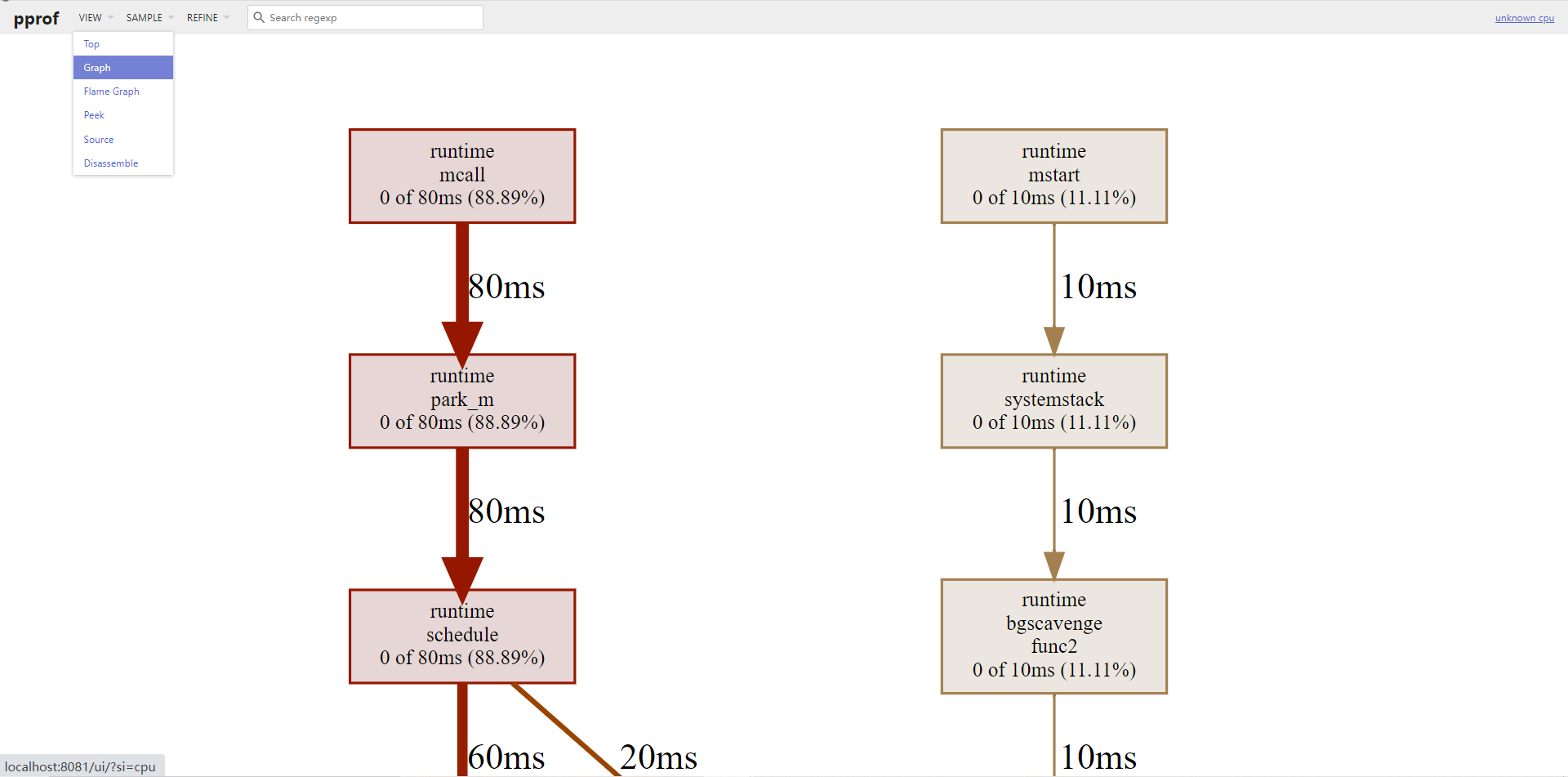
火焰图:
 每个方块代表一个函数,它下面一层表示这个函数会调用哪些函数,方块的大小代表了使用 CPU 所占百分比。火焰图的配色并没有特殊的意义,默认的红、黄配色是为了更像火焰而已。
每个方块代表一个函数,它下面一层表示这个函数会调用哪些函数,方块的大小代表了使用 CPU 所占百分比。火焰图的配色并没有特殊的意义,默认的红、黄配色是为了更像火焰而已。
另外,有时候我们通过其他途径得到了 pprof 文件,也可以通过它来分析使用 go tool pprof 应用程序 应用程序的prof文件 或者 go tool pprof prof 文件
五、pprof使用方法总结:
- 采集前需要先进行压测,在压测过程中再去收集才会有数据:
go-wrk -c=400 -t=8 -n=100000 http://127.0.0.1:8000/api/getReq。400个连接,8个线程, 模拟10w次请求(get请求支持直接写命令行的形式,post请求需要借助lua脚本,较复杂)。
- 压测的同时采集数据,并生成 profile 数据分析-结果文件:
go tool pprof http://127.0.0.1:8000/debug/pprof/profile
- 此时会进入一个交互界面,且生成了一个类似于 pprof.samples.cpu.001.pb.gz 的待分析文件。具体性能结果分析方法,一共有两种:
- 通过 终端交互 (此方法无需借助上述文件来分析):
top10-cum 找到对应cpu/内存占用高的函数名称(-cum:按 “当前函数以及子函数占用CPU的时间” 倒序排列)list xxx(xxx:top10 中最后一列列出的具体被调用函数的名称)
- 通过 可视化图形分析 (此方法需借助上述文件来分析):
- 退出 pprof 命令行,复制上面步骤3图中 Saved profile 后面的文件名及路径,比如:C:\Users\xxx\pprof\pprof.samples.cpu.001.pb.gz
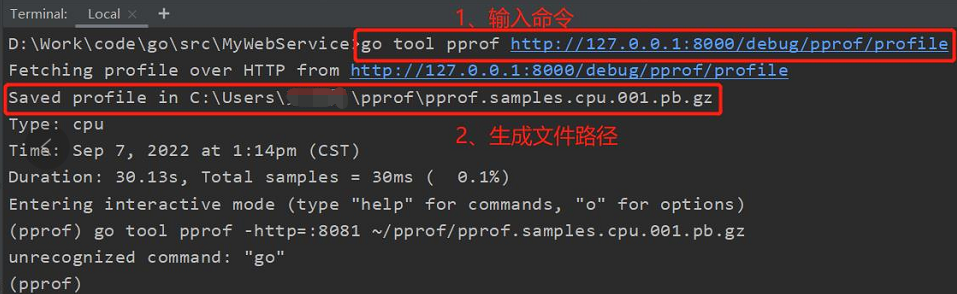
- 输入以下
go tool pprof xxx命令,会自动打开浏览器图形可视化页面,包含火焰图等…- linux下:
go tool pprof -http=:8081 ~/pprof/pprof.samples.cpu.001.pb.gz - windows下路径用双反斜杠表示:
go tool pprof -http localhost:8081 C:\\Users\\xxx\\pprof\\pprof.samples.cpu.001.pb.gz
- linux下:
- 注意:待分析的 .pb.gz 文件和 文件路径 是你自己电脑上对应的路径,这里仅仅是我测试的示例而已,可能会有所不同
- 退出 pprof 命令行,复制上面步骤3图中 Saved profile 后面的文件名及路径,比如:C:\Users\xxx\pprof\pprof.samples.cpu.001.pb.gz
- 通过 终端交互 (此方法无需借助上述文件来分析):
- go tool pprof github markdown参考文档
- 一位大佬的真实案例,,可以帮助你更好的学习问题排查思路:得物-Golang-记一次线上服务的内存泄露排查

















 1548
1548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









