









 本文探讨了如何在内存限制为4GB的情况下,通过将50亿URL文件切割成1000份,利用哈希函数和hash_set技术,高效找出两个文件中共同的URL。方法涉及分治策略和哈希映射,以解决超大规模数据的URL匹配问题。
本文探讨了如何在内存限制为4GB的情况下,通过将50亿URL文件切割成1000份,利用哈希函数和hash_set技术,高效找出两个文件中共同的URL。方法涉及分治策略和哈希映射,以解决超大规模数据的URL匹配问题。
一、问题
给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
二、分析
50亿个url,每个url 64字节:
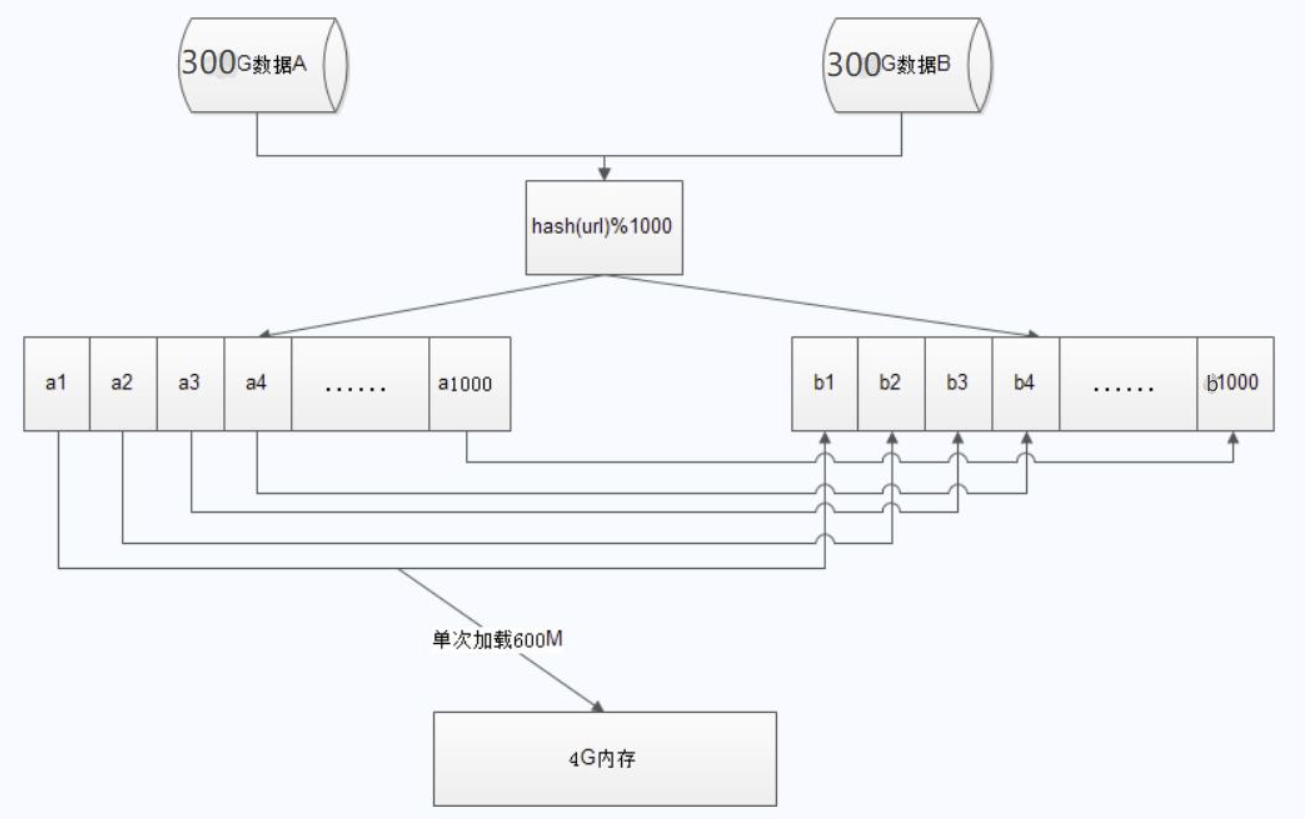
一共需要 50亿 × 64字节 ÷ 1024 ÷ 1024 ÷ 1024 = 298G ≈ 300G ,显然无法一次读入内存的。因此这里采用将大文件切割的分治法。
假设将每个大文件分割为1000个小文件,那么每个小文件大小为:300G ÷ 1000 × 1024 = 307M ≈ 300M,所以同时加载两个文件则需要 300M × 2 = 600M
三、方案
- 分治法 + 哈希取模法
- 使用布隆过滤器(允许一定错误率的情况下进行快速查找)
方案1:分治法 + 哈希取模法
- 将a、b 两个文件,用相同的哈希函数(把url换成数字的话,哈希函数更容易构造),分解为1000个独立哈希值相同的小文件
- 哈希值相同的url必然在序号对应的文件中,因此只要在序号对应的两个文件中进行url的相互匹配即可
- 比较每对序号对应的小文件时,可以使用hash_set
方案2:布隆过滤器
参考:CSDN文章
利用布隆过滤器的特性,在允许一定错误率的情况下,可以快速判断一个元素是否在一个集合中,适用于在有限内存内处理大量数据。
- 先遍历文件a,将其中的url逐一填充到布隆过滤器中
- 再遍历文件b,判断其中的url是否在布隆过滤器当中
注意:布隆过滤器,只能判断某数据一定不存在,不能判断其一定存在,存在误差。

















 1350
1350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









