







参考文献:
2013-AAAI-Effective bilingual constraints for semi-supervised learning of named entity recognizers(MengqiuWang,Wanxiang Che,Christopher D. Manning)
命名实体识别器半监督学习的有效双语约束
- 摘要
自然语言处理中的大多数半监督(semi-supervised)方法都利用了单一语言中的未加注释的资源;但是,可以通过使用一种以上语言的并行资源来获取信息,因为将相同的话语翻译成不同的语言有助于消除彼此之间的歧义。我们演示了一种有效利用大量双语文本(又称bitext)来改进单语系统的方法。我们提出了一个被分解的概率序列模型,该模型鼓励跨语言和文档内部的一致性。提出了一种简单的吉布斯采样算法来进行近似推理。使用OntoNotes数据集对英汉命名实体识别(NER)进行的实验表明,在双语测试环境中,我们的方法明显比最先进的单语CRF模型更准确。我们的模型也改进了Burkett等人(2010)的工作,中文和英文的相对误差分别降低了10.8%和4.5%。此外,通过在我们的双语模型中注释适量的未标记的双文本,并使用标记的数据进行升级训练,我们实现了与最先进的斯坦福单语NER系统相比,汉语的错误率降低9.2%。
Introduction
A number of semi-supervised techniques have been introduced to tackle this problem, such as bootstrapping(Yarowsky 1995; Collins and Singer 1999; Riloff and Jones 1999), multi-view learning (Blum and Mitchell 1998;Ganchev et al. 2008) and structural learning (Ando and Copyright c! 2013, Association for the Advancement of Artificial Intelligence (www.aaai.org). All rights reserved.Zhang 2005). Most previous semi-supervised work is situated in a monolingual setting where all unannotated data are available only in a single language.However, in recent years, a vast amount of translated parallel texts have been generated in our increasingly connected multilingual world. While such bi-texts have primarily been leveraged to train statistical machine translation (SMT) systems, contemporary research has increasingly considered the possibilities of utilizing parallel corpora to improve systems outside of SMT. For example, Yarowsky and Ngai (2001) projects the part-of-speech labels assigned by a supervised model in one language (e.g. English) onto word-aligned parallel text in another language (e.g. Chinese) where less manually annotated data is available. Similar ideas were also employed by Das and Petrov (2011) and Fu, Qin, and Liu (2011).
A severe limitation of methods employing bilingual projection is that they can only be applied to test scenarios where parallel sentence pairs are available. It is more desirable to improve monolingual system performance, which is more broadly applicable. Previous work such as Li et al. (2012) and Kim, Toutanova, and Yu (2012) successfully demonstrated that manually-labeled bilingual corpora can be used to improve monolingual system performance. This approach, however, encounters the difficulty that manually annotated bilingual corpora are even harder to come by than monolingual ones.
In this work, we consider a semi-supervised learning scheme using unannotated bi-text. For a given language pair (e.g., English-Chinese), we expect one language (e.g. English) to have more annotated training resources than the other (e.g. Chinese), and thus there exists a strong monolingual model (for English) and a weaker model (for Chinese). Since bi-text contains translations across the two languages, an aligned sentence pair would exhibit some semantic and syntactic similarities. Thus we can constrain the two models to agree with each other by making joint predictions that are skewed towards the more informed model. In general, errors made in the lower-resource model will be corrected by the higher-resource model, but we also anticipate that these joint predictions will have higher quality for both languages than the output of a monolingual model alone. We can then apply this bilingual annotation method to a large amount of unannotated bi-text, and use the resulting annotated data as additional training data to train a new monolingual model with better coverage.[1]
在这项工作中,我们考虑一个使用无注解双文本的半监督学习方案。对于给定的语言对(例如,英汉),我们期望一种语言(例如,英语)比另一种语言(例如,汉语)有更多的带注释的培训资源,因此存在一个强的单语模型(对于英语)和一个弱的模型(对于汉语)。由于双文本包含跨两种语言的翻译,对齐的句子对将显示一些语义和语法上的相似性。因此,我们可以通过联合预测来约束这两个模型,从而使它们彼此一致,而这种联合预测是偏向于更明智的模型的。一般来说,在低资源模型中所犯的错误将由高资源模型来纠正,但我们也预期这些联合预测对于两种语言的质量将高于单语模型的输出。然后,我们可以将这种双语注释方法应用于大量未加注释的双文本,并将得到的带注释的数据作为额外的训练数据来训练一种具有更好覆盖率的新单语模型。
Burkett et al. (2010) proposed a similar framework with a “multi-view” learning scheme where k-best outputs of two monolingual taggers are reranked using a complex self-trained reranking model. In our work, we propose a simple decoding method based on Gibbs sampling that eliminates the need for training complex reranking models. In particular, we construct a new factored probabilistic model by chaining together two Conditional Random Field monolingual models with a bilingual constraint model, which encourages soft label agreements. We then apply Gibbs sampling to find the best labels under the new factored model. We can further improve the quality of bilingual prediction by incorporating an additional model, expanding upon Finkel, Grenager, and Manning (2005), that enforces global label consistency for each language.
Burkett等人(2010)提出了一个类似的框架,该框架采用了一种“多视图”的学习方案,其中两个单语标记器的k-best输出使用复杂的自训练重排序模型进行重排序。在我们的工作中,我们提出了一种基于Gibbs sampling的简单解码方法,这种方法消除了训练复杂重新链接模型的需要。特别地,我们利用双语约束模型将两个条件随机场单语模型连接起来,构造了一个新的因子概率模型,该模型鼓励软标签协议。然后,我们应用吉布斯抽样找到最佳标签下的新因式模型。我们可以通过加入一个附加的模型,在Finkel、Grenager和Manning(2005)的基础上进行扩展,进一步提高双语预测的质量,该模型加强了每种语言的全球标签一致性。
Experiments on Named Entity Recognition (NER) show that our bilingual method yields significant improvements over the state-of-the-art Stanford NER system. When evaluated over the standard OntoNotes English-Chinese dataset in a bilingual setting, our models achieve a F1 error reduction of 18.6% in Chinese and 9.9% in English. Our method also improves over Burkett et al. (2010) with a relative error reduction of 10.8% and 4.5% in Chinese and English, respectively. Furthermore, we automatically label a moderate-sized set of 80k sentence pairs using our bilingual model, and train new monolingual models using an uptraining scheme. The resulting monolingual models demonstrate an error reduction of 9.2% over the Stanford NER systems for Chinese.[2]
Monolingual NER with CRF
Named Entity Recognition is an important task in NLP. It serves as a first step in turning unstructured text into structured data, and has broad applications in news aggregation, question answering, and bioNLP. Given an input sentence, an NER tagger identifies words that are part of a named entity, and assigns the entity type and relative position information. For example, in the commonly used BIO tagging scheme, a tag such as B-PERSON indicates the word is the beginning of a person name entity; and a I-LOCATION tag marks the word to be inside a location entity. All words marked with tag O are not part of any entity. Figure 1 illustrates a tagged sentence pair in English and Chinese.
命名实体识别是自然语言处理中的一项重要任务。它是将非结构化文本转换为结构化数据的第一步,在新闻聚合、问题回答和生物处理方面具有广泛的应用。给定一个输入句子,NER tagger标识作为命名实体一部分的单词,并分配实体类型和相对位置信息。例如,在常用的BIO标记方案中,诸如B-PERSON之类的标记表示该单词是person name实体的开头;I-LOCATION标记将单词标记在位置实体中。所有标记为O的单词不属于任何实体。图1展示了一个带标记的中英文句子对。

Current state-of-the-art supervised NER systems employ an undirected graphical model called Conditional Random Field (CRF) (Lafferty, McCallum, and Pereira 2001). Given an input sentence x, a linear-chain structured CRF defines the following conditional probability for tag sequence y:
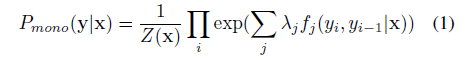
where fj is the jth feature funct
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









