







在描述redis之前先来了解一个概念,什么是NoSql?
NoSql = Not Only Sql不仅仅是sql,泛指非关系型数据库,随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,如高并发读写,对海量的数据高效率存储和访问等,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
NoSql特点:易扩展,大数据量高性能,灵活的数据模型,高可用
NoSql数据库的分类:1.键值(key--value)存储,2.列存储,3.文档数据库,4.图形数据库。
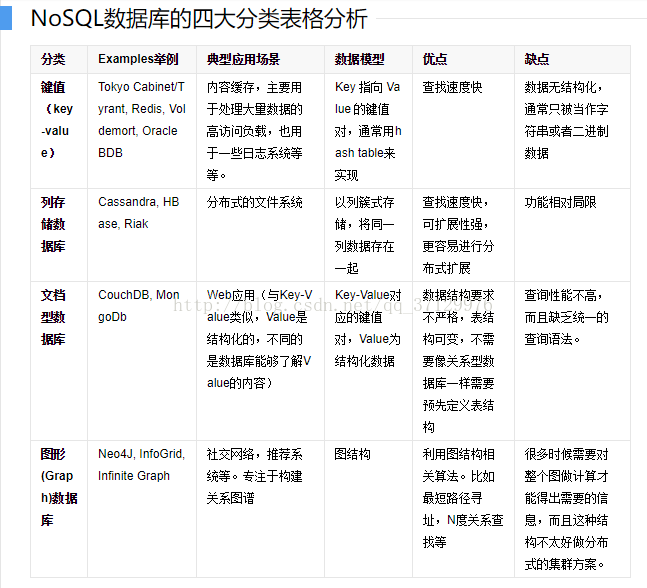
综上所述,NoSql已经成为了web2.0新时代的宠儿。
而redis就是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、高性能Key-Value数据库,并提供多种语言的API。它通过提供多种键值类型来适应不同场景下的存储需求,目前redis支持的键值类型有很多种,比如有1.字符串类型,2.列表类型,3.有序集合类型,4.散列类型,5.集合类型。
应用场景:1.缓存,2.任务队列,3.应用排行榜,4.网站访问统计,5.数据过期处理,6.分布式集群架构中的session分离。最主要的应用场景为缓存。
下载:Windows 版本的Redis,地址:https://github.com/MSOpenTech/redis, 这里你可以选择下载源码后自己编译,也可以直接下载发布后的版本,我是直接下载的发布后的版本 Release版,下载后,直接解压之后,可以直接启动redis服务器
启动后界面如下
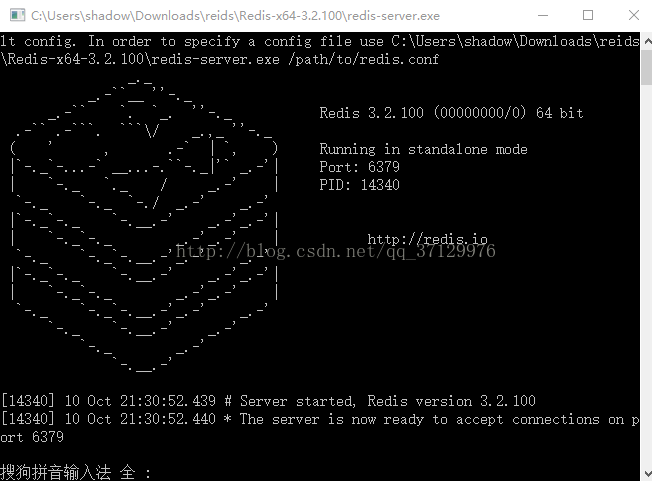
启动客户端redis-cli.exe就可以通过Redis的相关命令进行操作
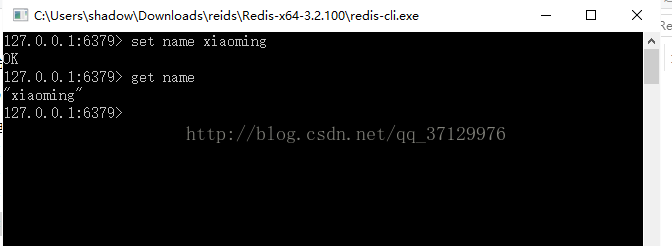
注意:由于以上的操作只能实现的是本地访问本地的服务器, 如果Redis 服务器在 远程的服务端,不在本地的时候,这个时候就需要修改配置文件 , 绑定服务器的 IP 地址,这样就能实现 远程连接 Redis 服务器了
上述为使用命令的方式向redis存入和获取数据,这种方式在实际开发中往往是不会使用的,因为在实际开发中往往通过一些程序来想redis存入和获取数据,所以我们需要来认识一下Jedis,redis不仅能使用命令操作,现在主流的开发语言都支持它的客户端的操作,比如java,c,c++等等。而Jedis是redis官网推荐的java语言连接Redis数据库的工具包,官网可以下载,下面进行测试创建java项目,导入jar包
@Test
/**
* 单实例测试
*/
public void test() {
//设置IP地址和端口号
Jedis jedis=new Jedis("127.0.0.1", 6379);
//保存数据
jedis.set("name", "tom");
//获得数据
System.out.println(jedis.get("name"));
//释放资源
jedis.close();
}
jedis和jdbc是很类似的,它也可以使用连接池来进行基本的操作,下面为连接池的方式来连接
@Test
/**
* 连接池方式
*/
public void test2(){
//获得连接池的配置对象
JedisPoolConfig config=new JedisPoolConfig();
//设置最大连接数
config.setMaxTotal(30);
//设置最大空闲数
config.setMaxIdle(10);
//获得连接池
JedisPool jedisPool=new JedisPool(config, "127.0.0.1", 6379);
Jedis jedis=null;
try {
//通过连接池获得jedis
jedis=jedisPool.getResource();
//设置数据
jedis.set("name", "tom");
//获得数据
System.out.println(jedis.get("name"));
} catch (Exception e) {
// TODO: handle exception
e.printStackTrace();
}finally{
if (jedis!=null) {
jedis.close();
}
if (jedisPool!=null) {
jedisPool.close();
}
}
}那么java中什么时候使用redis呢?
举例:假如系统中有2千万用户信息,用户信息基本固定,一旦录入很少变动,那么你每次加载所有用户信息时,如果都要请求数据库,数据库编译并执行你的查询语句,这样效率就会低下很多,针对这种信息不经常变动并且数据量较大的情况,通常做法,就是把它加入缓存,每次取数据前先去判断,如果缓存不为空,那么就从缓存取值,如果为空或者数据已经改变,这时再去请求数据库,并将数据加入缓存,这样大大提高系统访问效率















 2116
2116

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









