







好久没写文章了,总结一下在公司负责的一个花费精力比较多的项目:小票智能审核系统。
前言
在新的公司也呆了快两年了,是新零售性质的公司,公司会接很多品牌的需求,我们这个团队主要是小票相关的活动。
小票活动基本流程都是消费者上传购物小票–>初审录入小票信息–>复审小票信息–>发奖,看着是比较简单,但是其实整个业务流程还是比较复杂的,涉及到各种微信API以及红包发奖。
一、背景
每年公司承接的小票活动大概几百个,涉及小票量几百万张,每年兼职的费用也会花费几十万,所以研发一个可以智能审核的项目是必然要走的路。
二、项目初期
以下分服务来总结一下整个小票智能审核的各个服务和功能。
1.OCR服务
OCR功能是公司数据中心的同事做的,在小票上传完成后,会调用OCR接口进行小票数据的识别,该服务会同步返回OCR结果,包括小票类型(非小票、热敏小票、针打小票、翻拍小票等)、小票文本数据、小票基础数据(各个文本段的坐标数据)等。
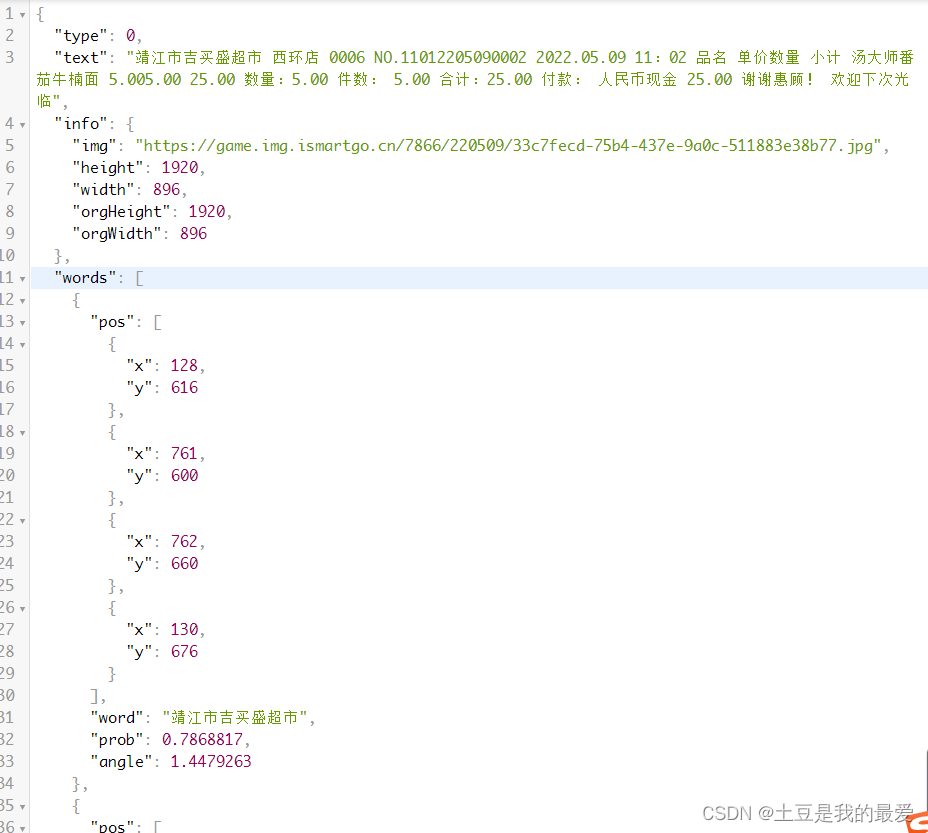
2.结构化服务
通用活动的小票录入信息都是一致的,主要是小票编号、小票时间、小票商品总额、小票商品总数、门店信息、商品列表信息这六大块。
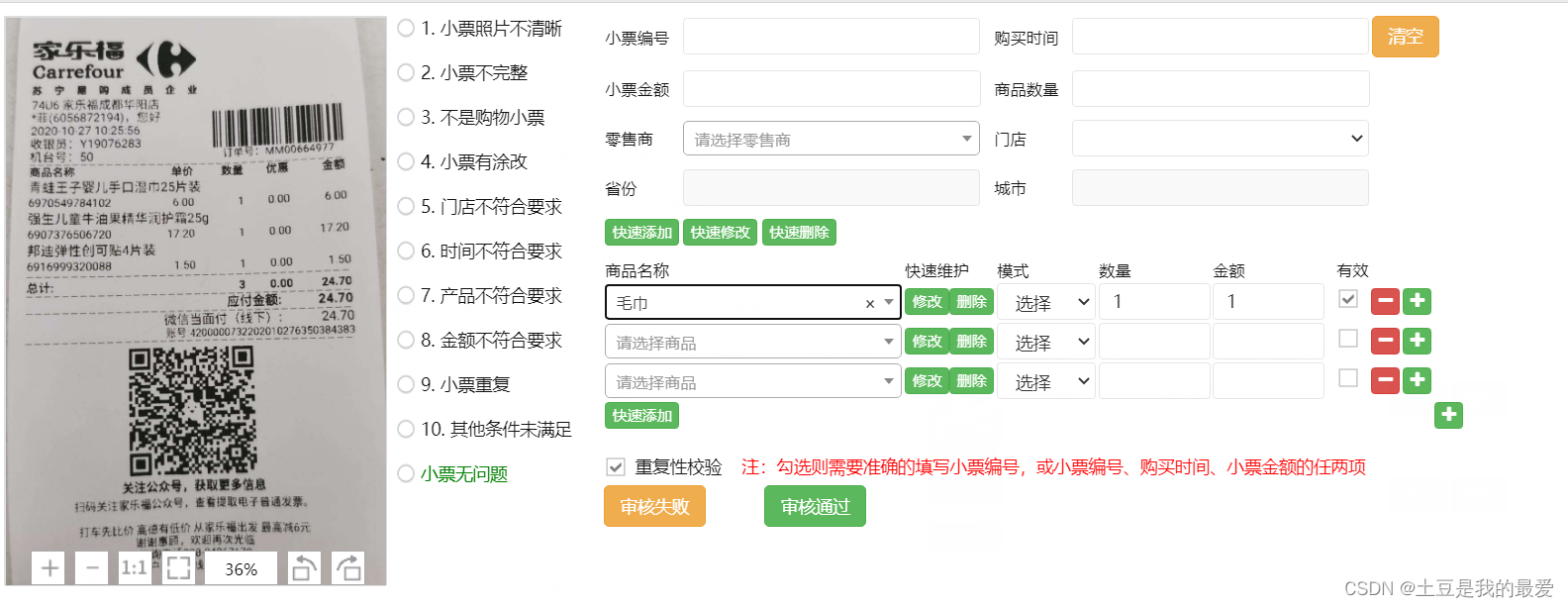
结构化要求
小票编号、时间、金额、数量四个字段可以直接在小票上读取进行录入的,但是小票门店以及商品信息。
因为小票是按活动上传的,每个活动有自己的参与机制限制,所以会导入活动门店库、活动商品库,那么此时是需要进行门店和商品的匹配,只有符合活动要求才可以进行录入和审核。
结构化方式
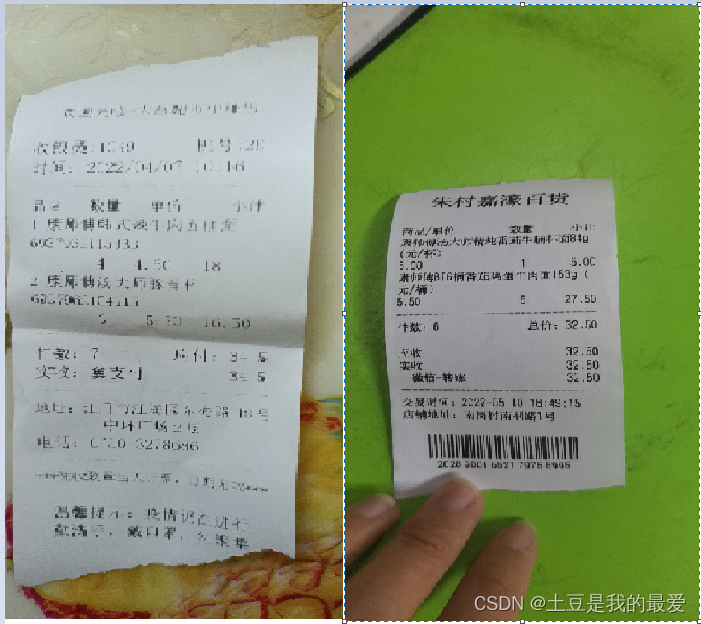
人工录入的话是可以根据常识来判别那个数据是正确的小票所需录入信息的,但是如果要做到智能审核,对于四个直接录入的字段来说,最简单的办事就是收集四个字段的所有可能key值,然后取值时进行遍历,遇到了哪个key,就取对应的value进行录入。
对于商品匹配以及门店匹配,最简单的办法当然就是文本匹配,但是我们只要小票的全长文本以及段短文本,并不知道用哪一段文本来和库中的名称数据进行匹配,总不能拿长文本进行匹配吧。
一张小票只属于一个门店,进行长文本匹配当然也是可以的,但是对于商品列表来说,长文本中包含了全部的商品数据,而这些数据没有进行清洗和拆分,是无法直接拿来进行匹配的。
针对以上,我们需要对小票的OCR数据进行一个结构化,就是从中提取出四个基本数据,以及可能的门店信息串、商品列表串数据。
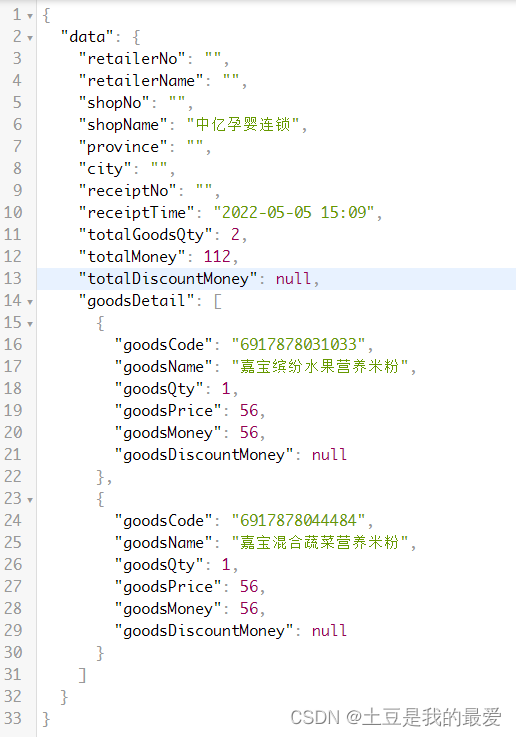
上面的数据就是结构化后的小票数据,通用结构化有两套算法服务:
Python的结构化服务
在调用数据中心的OCR服务时,同步会返回OCR基础数据,异步还会返回他们的结构化数据。他们的结构化服务是通过小票训练模型做到的,具体的内部细节不是很了解。
Java的机构化服务
对于数据中心的结构化服务,因为他们是训练模型,所以是一个很通用的算法,如果有新的小票样式出现,那就又需要进行样本训练,而且很多效果不是很好的小票,人工不好进行更加细节化特殊化的干预处理,所以我们利用他们的OCR基础数据(段短文本及其坐标数据)开发了Java的结构化服务。
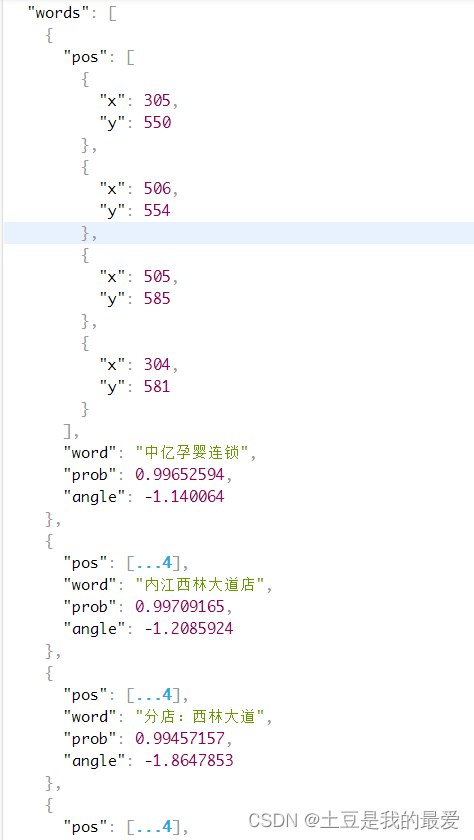
以上基础数据中,有每个小票短文本上下左右四个点的处于小票位置的坐标数据、小票文本串、置信度以及文本的倾斜角度,对于市面上大部分的OCR服务来说,基本也是返回类似的数据结构,调用方可以根据需要进行自己的业务二次开发。
那么得到这个数据后我们要想把他转化成上面的结构化数据结构,还是比较麻烦的。
行数据清洗
这个是结构化的第一步,也是最难、最重要的一步,主要就是把这些段短数据进行行清洗,把属于同一行的数据规整,听着好像不是很复杂是吧,每个文本都有自己的坐标和倾斜度,如果小票是正常平展拍摄的,那么根据倾斜度可以延展出统一水平线的坐标,是可以很轻松的进行行数据的规整的。
但是由于小票机打印会将小票弯曲,以及人工摆放问题,大都不是最理想的情况。那么就需要用一些算法算出最有可能是一行的数据。
方法
根据斜率的渐变性找出最符合渐变线路径的文本
基础字段数据结构化
在行数据清洗的基础上,对于小票编号、时间、金额、总数就可以根据我们历史数据跑出的关键字库来找对应的value值,完成基础字段的结构化。
方法
根据以往小票的OCR文本,进行分词并保存出现次数,跑完后找出出现次数较前的一部分词,因为这类词基本是小票的共性词,简单清洗后得到一个小票商品表头词库。
门店数据结构化
门店数据需要的信息有零售商、省份、城市、门店编号、门店名称。
方法
零售商、省份城市都是可以根据现有词库进行匹配的。门店编号和名称的话可以根据关键字查找,但是大都没有key,只有单独的编号和名称,名称可以根据正则比如包含店的文本等方法。
商品块数据清洗
在行数据清洗的基础上,我们需要将小票中最复杂的一部分割裂出来,那就是小票商品数据,只有将小票商品文本的范围划出来,我们才能对小票商品数据继续进行清洗和机构化。
方法
基本上所有小票上在商品数据的开始都有对应的表头,可以根据这种表头作为商品数据的开始,而商品数据结束一般都有金额的总计和优惠等字样。以此为前后界限分割出商品数据的范围文本

商品数据结构化
在商品块数据清洗完成的基础上,我们需要对该数据继续进行结构化,得到所有的商品信息,包括商品编码、名称、金额、数量。
方法
根据商品表头词库中找到该小票包含的表头词,根据他们的文本相关性(上下左右的位置关系),判断出该小票的表头列数,再结合商品数据行文本进行数据分割。
结构化数据融合
因为有两套结构化服务,Java结构化是对Python结构化服务的查漏补缺,所以对两套数据可以进行融合,每个字段的结构化都有特定的算法,都会有一个附属的置信度字段,可以进行融合比较,最终得到一个更加优化的机构化数据。
3.数据录入
在得到结构化数据之后,对于基础字段数据则进行直接录入。
对于门店和商品数据,因为要匹配到活动真实的门店商品库数据录入方可,则用最简单的文本匹配算法匹配一个最优的数据,也会有一个附属的置信度。
4.自动通过
对于每个活动都可以设置针对每个字段的置信度,不设置则用默认设置。

六部分小票数据都满足活动的门槛设置时,该小票就会自动通过。
二、后期优化
由于小票样式各式各样,我们的结构化服务过于通用,最终效果不是很理想,取得数据不够完整,不够正确,通过率比较低。
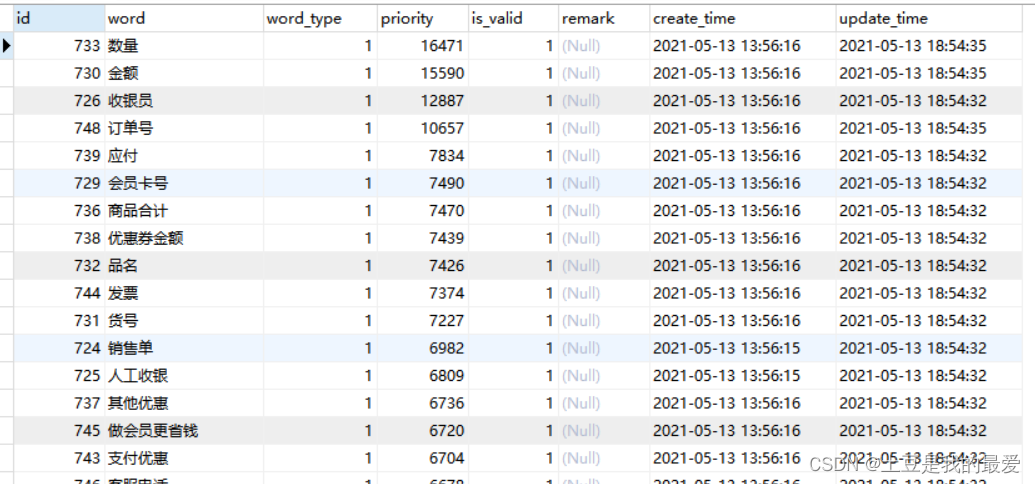
1.小票模板分类
针对不同的小票,进行了模板的分类。
分类方法
(1)骨架词提取
与上述商品表头词清洗的方法类似,将以往的OCR小票文本全部跑一次,用分词算法(结巴分词)进行文本分词,统计出现的词以及次数。
对跑出的结果进行出现次数的排序,然后清洗,把属于小的共性次筛选出来,我们把它叫做骨架词。
(2)模板匹配
当一个小票进入匹配,提取该小票的骨架词,与现有模板库模板的骨架词进行匹配(初始时没有模板),判断相似到一定程度的即认为为同一个模板,归于该模板下,并进行骨架词的合并。
没有找到相似模板或者相似度不足则进行模板新增。
判断相似算法为判断两者骨架词的数量及出现顺序到一定程度(LCS)则认为相似。
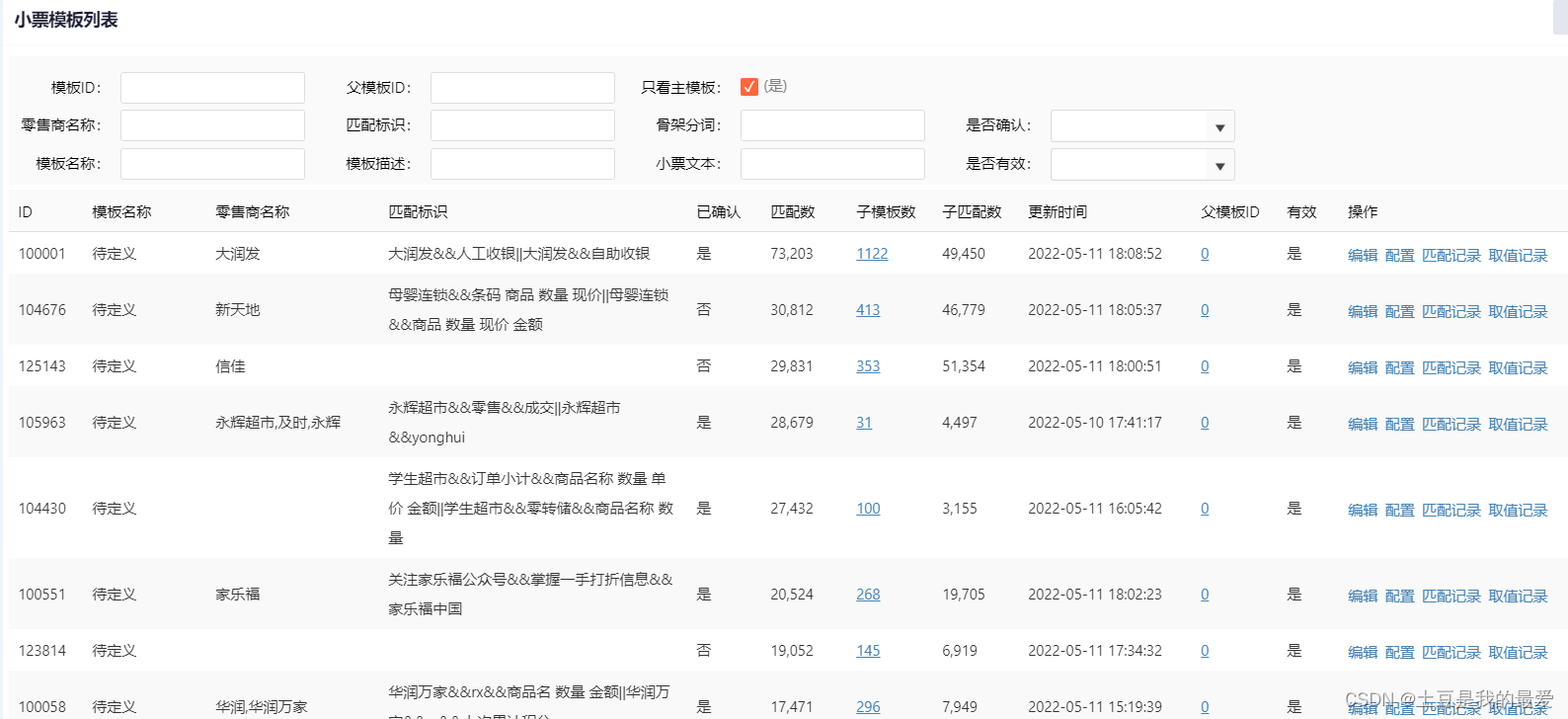
(3)模板融合
在模板匹配过程中,因为小票的完整性与否可能导致产品的小票模板过多,但其中不乏有相同的模板,而模板在匹配过程中骨架词是可能动态发生变化的,那么就要定时对模板库的模板进行模板之间的匹配,匹配相似的认定为同一模板,但是因为模板已经产生关联数据,不可删除,所以建立父子模板的关联。
2.模板配置取值
小票根据模板分类后,可以根据模板进行对应的配置取值。
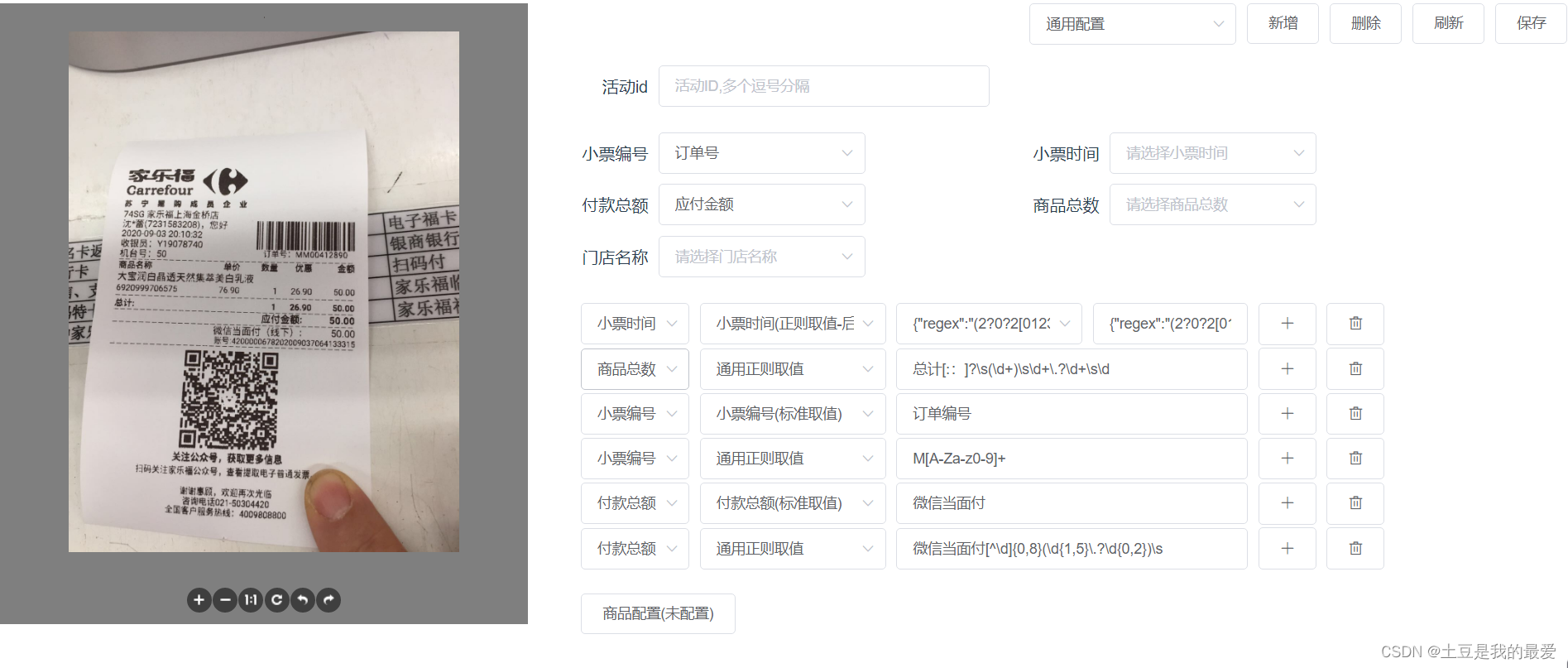
由于数据的多样性,可以进行key-value取值,也可以直接填正则取值,还有其他的一些细节配置暂不赘述。
小票模板化是我们走过很多弯路后一个很大的进步,有了该模板库之后,各种取值的正确率都有了很大的提升。
初期是人工配置为主。
模板配置取值自动学习
对于人工录入通过的小票,进行反馈分析,将正确的结果与OCR文本进行匹配,反向学习得到正确的取值key,记录到模板配置中(与人工配置区分),并在后续应用中记录自动学习值的应用次数及正确次数,渐渐得到更优的自动配置结果。
3.门店匹配算法优化
前期通过文本相似度匹配的方式存在很大的问题,第一:提取出是门店信息的文本段比较难;第二:就算找到了合适的文本段,活动门店中存在门店名称类似,只不过所在区域不同。
标识算法
每个门店都会有很多与自己相关的属性值,我们称之为标识,在小票上传时解析小票OCR文本中门店相关的标识,将小票解析标识与门店已有解析标识进行匹配,找到其中标识更为一致的门店即为匹配的最优门店
属性标识有编号、名称、省份、城市、区域、零售商等。
标识的产生
门店初始标识
每个门店导入时,都会拥有自己的信息可能包括编号、名称、零售商、省份、城市,这些都可以当做该门店的初始标识记录下来。
审核反馈标识
在小票人工审核发奖后,会将人工录入正确的门店名称与该小票文本比较,找到其中最相似的一个文本段也当做该门店的一个标识保存。
标识打分
不同类型的标识产生是有不同的分数的,而标识在被应用后,根据人工是否对智能审核录入结果进行修改来对该标识加减分,所以每个标识都对应一个分数,分数越高的标识越可靠,标识匹配不只是针对标识数量,还有分数,根据数量和分数也可以得到一个匹配的置信度。
4.商品匹配算法优化
标识匹配算法
此思想和门店标识算法一致,只是标识产生的方式有所不同。
商品码匹配算法
商品都是有69码的,导入活动商品有,小票上很多也有,69码如果能匹配到,那么就认为是正确匹配。同时还会将该小票明细69码对应的商品名称加入到被匹配活动商品的标识记录中。
文本相似度算法
(1).单字相似度算法
(2).分词相似度算法
价格相似度辅助算法
以上算法中,都会加入标准价格辅助条件,价格占据一定的匹配权重,该辅助效果在实际应用中还是比较明显的。
标准价格的产生
对于所有的已审核小票,在审核完成后,都会进行学习反馈。将正确的商品价格标记到该商品上,会有一个价格列表,但是只有被标记次数最多的一个价格会当做该商品的标准价格,该值就用作商品匹配的辅助价格,辅助价格匹配也不是相等的关系,可以是该价格的上下浮动价格,当然浮动越大,权重越低,最终匹配出的商品置信度也会相应降低。
5.学习反馈机制
对于智能审核没有成功但是人工审核完成的数据,以及智能审核成功后人工是否修改,这些数据都会进行反馈学习,是的正确的匹配越来越多,错误的
渐渐减少
总结
该项目用了较多的算法:
标识提取(DFA算法):匹配一个文本串和一个词库,得到交集词列表;
模板匹配:匹配两个词列表,得到交集词列表;
商品文本匹配:判断两个文本的相似度(考虑顺序及步长)
商品分词匹配:判断两个分词列表的相似度(考虑分词权重)

















 4103
4103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









