








当今移动互联网时代,每个人每天都会产生数据,海量数据的存储以及查询使得RDBMS无法满足需求,因此出现了HBase分布式大数据。本文主要介绍的HBase的基本使用以及Hbase的架构原理,使得读者对Hbase有一个更好地认识。
一、HBase介绍
首先,看看官网对于Hbase的介绍:
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
Use Apache HBase™ when you need random, realtime read/write access to your Big Data. This project's goal is the hosting of very large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google's Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
HBase是一个分布式的,可扩展的hadoop大数据仓库,它是基于hadoop之上的。
HBase适合处理海量数据,一般的处理数十亿行数据都是实时的。因此,适合做海量数据的存储于检索。在一张HBase表中,数十亿行,数百万列的数据HBase都可以轻松处理,因此更为准确的说HBase就是一个分布式、海量并且实时的大数据仓库。
HBase的特点有以下几点:
- 线性和模块化可扩展性
- 严格一致的读取和写入
- 表的自动配置和分片
- 支持RegionServers之间的自动故障转移
- 方便的基类支持hadoop的mapreduce作业与Apache HBase的表
- 易于使用的Java API的客户端的访问
- 块缓存和布鲁姆过滤器实时查询
- Thrift网关和REST-FUL Web服务支持XML,protobuf和二进制的数据编码选项。
- 可扩展的基于JRuby的脚本。
- 支持监控信息通过hadoop子系统导出到文件或Ganglia.
二、HBase架构详解
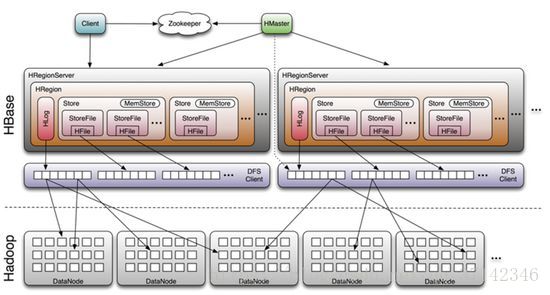
从上面的架构图可以看出HBase是建立在hadoop之上的。HBase有3个重要的组件:Zookeeper、HMaster、HRegionServer。Zookeeper为整个HBase集群提供协助的服务(信息传输)。HMaster主要用于监控和操作集群的所有RegionServer。RegionServer主要用于服务和管理分区(Regions)。
(1)Client
Client使用HBase RPC机制与HMaster和HRegionServer进行通信,对于管理类操作,与HMaster进行RPC通信,对于数据的读写等操作,与HRegionServer进行RPC。
(2)Zookeeper
Zookeeper中除了保存表的地址与HMaster的地址外,HRegionServer也会把自己以Ephemeral方式注册到Zookeeper中,使HMaster可以随时感知到各个HRegionServer的健康转态。
(3)HMaster
HMaster不会有单点故障问题,zookeeper会使用Master Election机制保证总有一个Master运行,HMaster在功能上主要负责Table和Region的管理工作。管理用户对Table的CRUD、管理HRegionServer的负载均衡和调整HRegion分布、在Region Split之后,负责新的HRegion的分配、在某一台HRegionServer停机之后,负责失效的HRegionServer上的Region的数据迁移。
(4)HRegionServer
HRegionServer主要负责响应用户的I/O请求,是HBase的核心模块,它的内部有很多HRegion。
HBase是基于列式存储的数据库,不是行式存储的,它的每一列都存储在不同的文件中,列与列之间是隔离的,在不同的文件。在HBase创建一张表时,需要执行一个rowkey,它是一条记录的唯一标识,类似于RDBMS的索引,还需要执行一个列簇(Column family),列不需要执行指定,在插入数据时动态指定,每一个列簇包含有多个列。HBase会按照rowkey在行的方向上进行Region,并且会按照row key进行字典排序,每一个Region存储在不同的RegionServer上,每一个Region都有startRowkey和endRowkey来划分范围(范围前闭后开),Region时HBase集群分布式存储和负载均衡的最小存储单位(注意:不是最小存储单位)。当一张表刚开始被创建的时候,它只会有一个Region,startRowkey和endRowkey都不会指定,没有值,表示无上下限。当插入数据到一定的阀值后就会进行Split操作,将一个大的Region划分两个小的的Region,父Region下线,两个子Region被HMaster分配到不同的HRegionServer上进行管理。
HStore是HBase的核心存储,它由一个memstore和零至多个storefile组成。在向HBase中插入数据的时候,它首先会向将数据存储在Memstore(内存),并且同时写入日志文件HLog中。HLog是一个实现Write Ahead Log的类,Hlog会定时滚动刷新,保存新的数据,删除旧的数据(已经持久到StoreFile中的数据),同时HLog也肩负着数据恢复的重任。写入HLog的目的是防止RegionServer停机的时候在内存中的数据丢失。当存储在memstore中的数据超过一定的阀值,内存溢出的时候,就会向hdfs 文件中写入storefile。当storefile的数量超过一定的阀值时,就会出发compact过程,将多个storefile合并为一个大的storefile文件,合并过程中会合并每一个column的版本以及删除旧的数据,由此可见,HBase的更新以及删除操作并不会刚开始触发,会在后续过程中完成。这使得用户只需要将操作进入内存中即可返回,保证了HBase I/O性能。
也许上面的很多术语看的你有些糊涂,现在用一个简单的例子来看看HBase表的具体结构。在一张HBase表中,最为重要的是rowkey,它也是为什么HBase可以对海量数据查询很快的原因所在,接着就是column family,依一张user表为例:创建这张表时,需要指定一个rowkey,然后需要一个列簇info,在info中包含name,age,tel,adress, 每一个列可以有多个版本,也就是每次修改的值就是一个版本,HBase不会在每一个修改操作时删除旧的值,而是每一个值对应一个timestamp形成一个版本。比如address可以有多个版本。这种结构类似json数据格式:
user{
info{
'name':'zhangsan',
'age':'20',
'tel':'123456789',
'address':[
shanghaishi,
baijingshi,
]
}
}
下面是表结构的简易图:
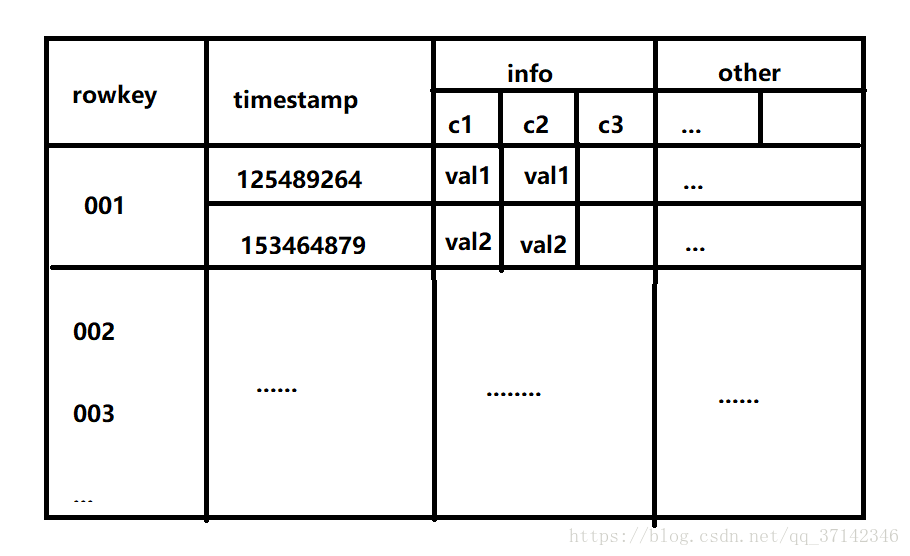
最后,需要注意的是HBase是也一个NOSQL数据库。
下面来看看如何动手安装部署HBase以及简单的CRUD操作.
三、HBase安装部署以及shell的使用
这里,只是简单的部署一个伪分布式的集群环境,即主从节点在一台机器上,读者也可参考官网的配置(http://hbase.apache.org/book.html#quickstart)。
首先,下载HBase,这里使用0.98.6,这个版本比较稳定,需要其他的版本可自行去下载(http://archive.apache.org/dist/)。HBase的安装部署非常简单,不过在这之前需要你熟悉hadoop集群的搭建,并且你的机器上也需要安装hadoop集群才能启动HBase(这里使用hadoop2.x),zookeeper这里使用HBase内部 自带的。
1.下载HBase压缩包,首先解压
tar -zxvf hbase-0.98.6-hadoop2-bin.tar.gz
2.解压后,由于这里使用的是Apache HBase,hadoop2.5,所以需要将hbase中的lib目录中的hadoop2.2的jar包全部替换为2.5版本的。进入conf目录。打开hbase-env.sh文件配置JAVA_HOME:
export JAVA_HOME=/opt/modules/jdk1.7.0_79
3.配置hbase-site.xml:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop-senior.shinelon.com:8020/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop-senior.shinelon.com</value>
</property>
</configuration>
将上面的主机名换为你的主机名即可。
经过上的配置就可以启动HBase了。首先你需要启动HDFS,然后就可以启动了,下面是使用脚本全部启动,你也可以一个一个启动,和HDFS启动过程类似:
bin/start-hbase.sh
现在,HBase就已经启动成功,与HDFS和YARN一样,它也有web监控界面,0.98.6版本的端口号为60010,新版本有变动。

下面,我们使用hbase shell工具来进行增删改查:
bin/hbase shell
进入shell界面后,可以使用help获取帮助信息:
使用下面命令可以获取单个命令的帮助信息:
help 'command'
1.创建一张表,需要指定表名和列簇名:
create 'user','info'
2.插入数据,使用put命令:
put 'user','1001','info:name','zhansgan'
put 'user','1001','info:age','18'
put 'user','1002','info:name','lisi'
put 'user','1002','info:tel','123456'
3.查询数据,总共有三种方式:
(1)、使用get命令
(2)、使用scan range进行范围查询(最常用)
(3)、使用scan进行权标扫描
下面演示一下这些操作:
使用get:

使用scan进行范围查询:

使用scan进行全表扫描:

还有很多命令,读者可以使用help命令去自行查看和使用,这里就不加赘述,HBase的使用也不是很难。
至此,本文就介绍完了HBase的基本原理与使用,如有不足之处还请指出。
如果你想和我一起探讨学习,共同进步,欢迎加群:
















 1734
1734











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









