




 本文介绍了跳表这一高效的数据结构及其在ConcurrentSkipListMap中的应用。跳表通过多级索引来提高查找效率,同时保持了插入和删除操作的高性能。ConcurrentSkipListMap利用跳表实现了一个线程安全且有序的键值对映射。
本文介绍了跳表这一高效的数据结构及其在ConcurrentSkipListMap中的应用。跳表通过多级索引来提高查找效率,同时保持了插入和删除操作的高性能。ConcurrentSkipListMap利用跳表实现了一个线程安全且有序的键值对映射。
在JDK并发包中有很多的数据结构,最常用的有链表,哈希表等等,除了这些数据结构之外,还有一种特殊的数据结构跳表,可能大多数人都不太了解,因此,本篇文章主要介绍跳表这一数据结构的原理以及它在JDK内部的使用。
一、什么是跳表?
跳表(SkipList),是一种可以快速查找的数据结构,类似于平衡树。它们都可以对元素进行快速的查找。因为跳表是基于链表的(具体结构等下会将),因此,它的插入和删除效率比较高。因此在高并发的环境下,如果是平衡树,你需要一个全局锁来保证整个树的线程安全,而对于跳表,你只需要局部锁来控制即可。对于查询而言,它的时间复杂度为O(logn)。
那么跳表具体的结构到底是怎么样的呢?下图是跳表数据结构的原理图:
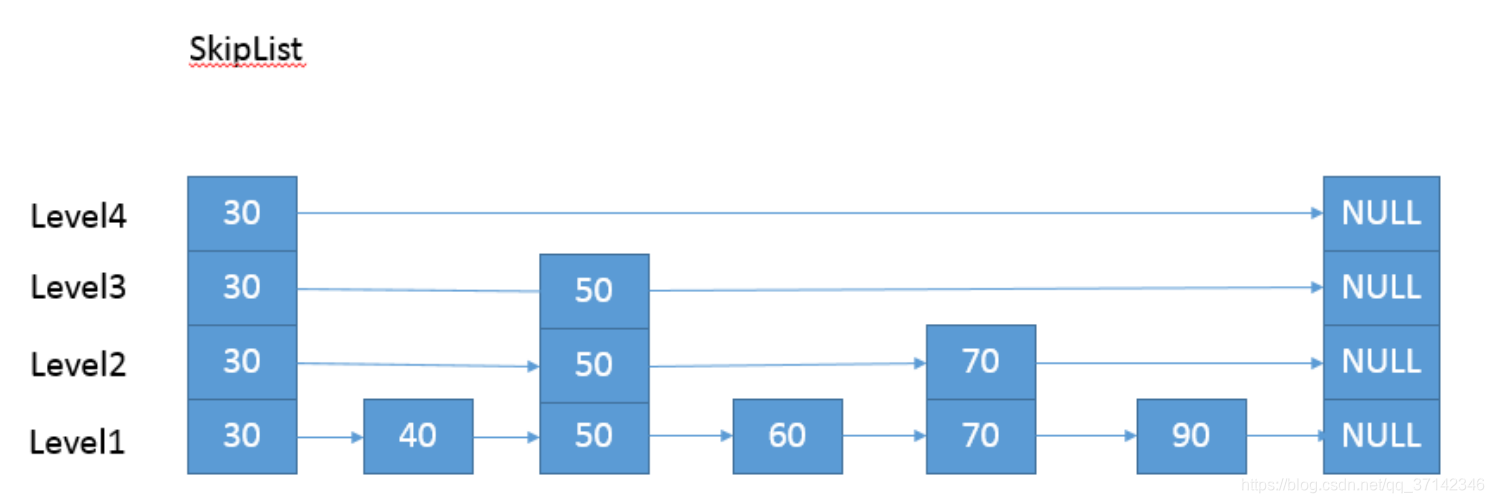
可以明显看到,跳表就是一种典型的以空间换时间的数据结构。
该算法与哈希算法的另一个区别就是:哈希算法不会保存数据的顺序,而跳表内的所有元素都是排序的。因此对于跳表进行遍历会得到一组有序的数据。
在JDK内部,也使用了该数据结构,比如ConcurrentSkipListMap,ConcurrentSkipListSet等。下面我们主要介绍ConcurrentSkipListMap。说到ConcurrentSkipListMap,我们就应该比较HashMap,ConcurrentHashMap,ConcurrentSkipListMap这三个类来讲解。它们都是以键值对的方式来存储数据的。HashMap是线程不安全的,而ConcurrentHashMap和ConcurrentSkipListMap是线程安全的,它们内部都使用无锁CAS算法实现了同步。ConcurrentHashMap中的元素是无序的,ConcurrentSkipListMap中的元素是有序的。它们三者的具体区别可以参考具体的资料,下面主要讲解ConcurrentSkipListMap的实现原理。
二、ConcurrentSkipListMap的实现原理
理解了跳表的原理,ConcurrentSkipListMap的原理不难理解,在它的内部有几个重要的数据结构,首先是Node,一个Node表示一个节点,里面含有两个重要的元素key和value,还有一个next指向Node的节点表示下一个节点。
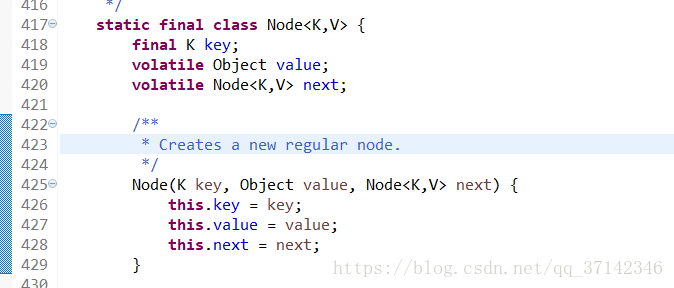
对于Node的所有方法,使用了CAS方法,因此是线程安全的。

上面两个方法一个是设置value,另一个是设置next的,具体实现可以查看源代码。
另外一个重要的数据结构就是Index,从上面跳表的结构可以看出,我们需要知道要一个元素在哪一层,哪一个节点,因此都需要Index来管理。
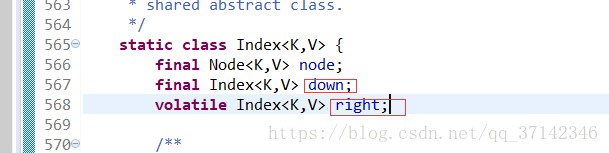
在Index中封装了Node,并且有一个向右和向下的引用。此外,还有一个数据结构也很重要,HeadIndex,它记录每一层的表头处于哪一层,它继承自Index。

上面就简单介绍完了ConcurrentSkipListMap的内部重要数据结构,重点是了解跳表数据结构,理解跳表是掌握ConcurrentSkipListMap的关键。

















 1555
1555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









