







在一个高并发的分布式系统中,缓存系统是必不可少的一部分,大多数情况下,我们需要设计一个多级缓存系统到生产中使用,那么如何设计呢?这也是笔者在前一段时间的面试中,被问到的一个问题,虽然当时这道题过了,但是面试结束之后对自己的回答不是很满意,所以,再反复思考之后决定分享下自己的设计思路。欢迎留言批评指正。
首先我们需要明白,什么是一个多级缓存系统,它有什么用。所谓多级缓存系统,就是指在一个系统 的不同的架构层级进行数据缓存,以提升访问效率。
我们都知道,一个缓存系统,它面临着许多问题,比如缓存击穿,缓存穿透,缓存雪崩,缓存热点等等问题,那么,对于一个多级缓存系统,它有什么问题呢?
- 缓存热点:多级缓存系统大多应用在高并发场景下,所以我们需要解决热点Key问题,如何探测热点key?
- 数据一致性:各层缓存之间的数据一致性问题,如应用层缓存和分布式缓存之前的数据一致性问题。
- 缓存过期:缓存数据可以分为两大类,过期缓存和不过期缓存?如何设计,如何设计过期缓存?
在这之前,我们先看看一个简单的多级缓存系统的架构图:
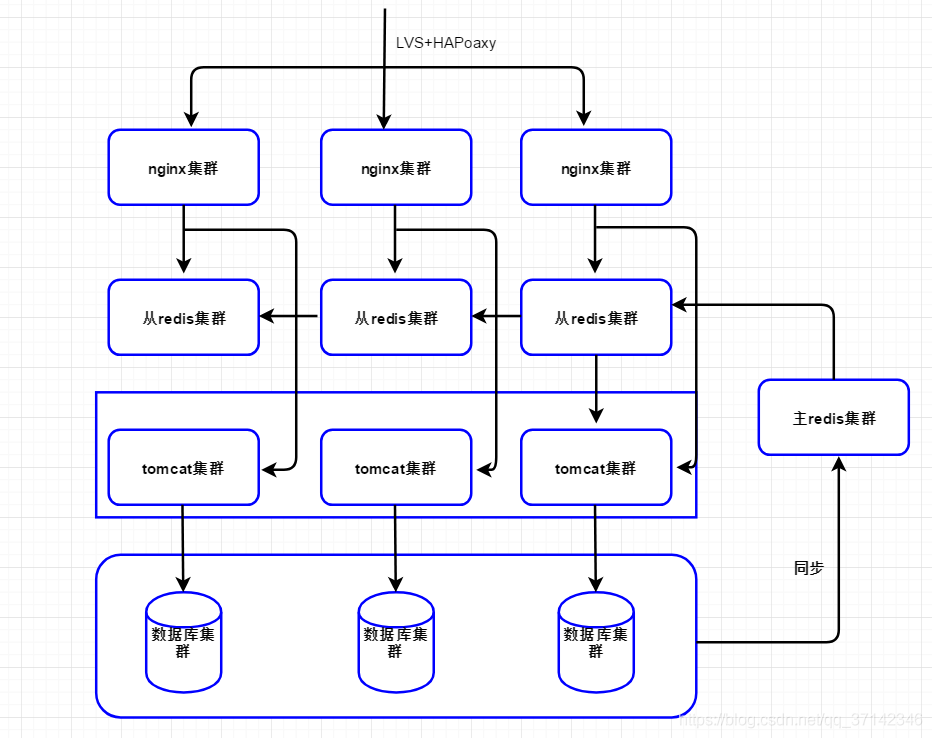
整个多级缓存系统被分为三层,应用层nginx缓存,分布式redis缓存集群,tomcat堆内缓存。整个架构流程如下:
- 当接收到一个请求时,首先会分发到nginx集群中,这里可以采用nginx的负载均衡算法分发给某一台机器,使用轮询可以降低负载,或者采用一致性hash算法来提升缓存命中率。
- 当nginx层没有缓存数据时,会继续向下请求,在分布式缓存集群中查找数据,如果缓存命中,直接返回(并且写入nginx应用缓存中),如果未命中,则回源到tomcat集群中查询堆内缓存。
- 在分布式缓存中查询不到数据,将会去tomcat集群中查询堆内缓存,查询成功直接返回(并写入分redis主集群中),查询失败请求数据库;堆内缓存。
- 如果以上缓存中都没有命中,则直接请求数据库,返回结果,同步数据到分布式缓存中。
在简单了解了多级缓存的基本架构之后,我们就该思考如何解决上面提到的一系列问题。
缓存热点
缓存热点,是一个很常见的问题,比如“某某明星宣布结婚”等等,都可能产生大量请求访问的问题,一个最麻烦也是最容易让人忽视的事情就是如何探测到热点key,在缓存系统中,除了一些常用的热点key外,在某些特殊场合下也会出现大量的热点key,我们该如何发现呢?有以下策略:
- 数据调研。可以分析历史数据以及针对不同的场合去预测出热点key,这种方式虽然不能百分百使得缓存命中,但是却是一种最简单和节省成本的方案。
- 实时计算。可以使用现有的实时计算框架,比如storm、spark streaming、flink等框架统计一个时间段内的请求量,从而判断热点key。或者也可以自己实现定时任务去统计请求量。
这里我们着重讨论一下第二种解决方案,对于热点key问题,当缓存系统中没有发现缓存时,需要去数据库中读取数据,当大量请求来的时候,一个请求获取锁去请求数据库,其他阻塞,接着全部去访问缓存,这样可能因为一台服务器撑不住从而宕机,比如正常一台服务器并发量为5w左右,产生热点key的时候达到了10w甚至20w,这样服务器肯定会崩。所以我们在发现热点key之后还需要做到如何自动负载均衡。
结合以上问题我们重新设计架构,如下图所示:
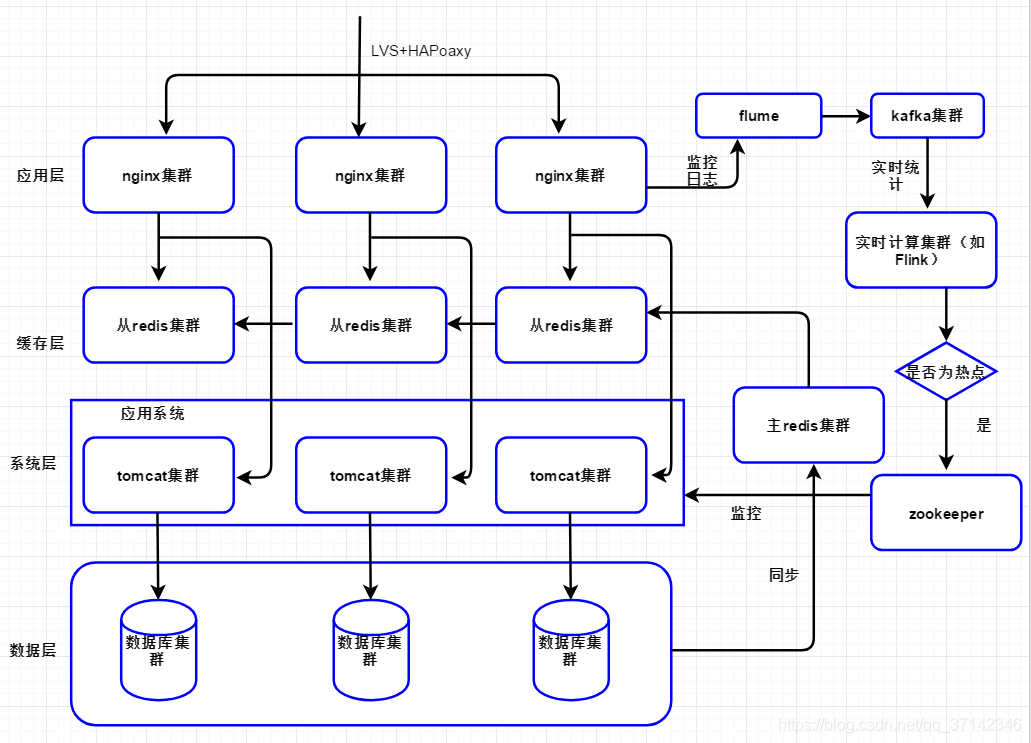
我们将整个应用架构分为应用层,分布式缓存、系统层以及数据层。
在应用层,我们采用nginx集群,并且对接实时计算链路,通过flume监控nginx日志,将数据传输到kafka集群中,然后flink集群消费数据进行统计,如果统计 结果为热点key,则将数据写入zookeeper的节点中,而应用系统通过监控znode节点,读取热点key数据,去数据库中加载数据到缓存中并且做到负载均衡。
实际上,对于应用系统中的每一台服务器,还需要一层防护机制,限流熔断,这样做的目的是为了防止单台机器请求量过高,使得服务器负载过高,不至于服务器宕机或者大量请求访问数据库。简单思路就是为每一台服务器设计一个阀值,当请求量大于该值就直接返回用户空白页面或者提示用户几秒后刷新重新访问。
数据一致性
数据一致性问题主要体现在缓存更新的时候,如何更新缓存,保证数据库与缓存以及各层缓存层之间的一致性。
对于缓存更新问题,先写缓存还是先写数据库,这里省略若干字。之前的文章介绍过,有兴趣的读者可以翻阅。
在单层缓存系统中,我们可以先删除缓存然后更新数据库的方案来解决其数据一致性问题,那么对于多级缓存呢?如果使用这种方案,我们需要考虑,如果先删除缓存,那么需要逐层去做删除操作,那么这一系列操作对系统带来的耗时也是和可观的。
如果我们使用分布式事务机制,就需要考虑该不该将写缓存放入事务当中,因为我们更新分布式缓存,需要走网络通信,大量的请求将导致网路抖动甚至阻塞,增加了系统的延迟,导致系统短时间内不可用。如果我们不将写缓存这一操作放入事务当中,那么可能引起短时间内数据不一致。这也就是分布式系统的CAP理论,我们不能同时达到高可用和一致性。那么该如何抉择呢?
这里我们选择保证系统的可用性,就一个秒杀系统来讲,短暂的不一致性问题对用户的体验影响并不大(当然,这里不涉及支付系统),而可用性对用户来说却很重要,一个活动可能在很短的时间内结束,而用户需要在这段时间内抢到自己心仪的商品,所以可用性更重要一些(这里需要根据具体场景进行权衡)。
在保证了系统的可用性的基础上,我们该如何实现呢?如果实时性要求不是很高,我们可以采用全量+增量同步的方式进行。首先,我们可以按照预计的热点key对系统进行缓存预热,全量同步数据到缓存系统。接着,在需要更新缓存的时候,我们可以采用增量同步的方式更新缓存。比如我们可以使用阿里Canal框架同步binlog的方式进行数据的同步。
缓存过期
缓存系统中的所有数据,根据数据的使用频率以及场景,我们可以分为过期key以及不过期key,那么对齐过期缓存我们该如何淘汰呢?下面有常用的几种方案:
- FIFO:使用FIFO算法来淘汰过期缓存。
- LFU:使用LFU算法来淘汰过期缓存。
- LRU:使用LRU算法来淘汰过期缓存。
以上几种方案是在缓存达到最大缓存大小的时候的淘汰策略,如果没有达到最大缓存大小,我们有下面几种方式:
- 定时删除策略:设置一个定时任务,在规定时间内检查并且删除过期key。
- 定期删除策略:这种策略需要设置删除的周期以及时长,如何设置,需要根据具体场合来计算。
- 惰性删除策略:在使用时检查是否过期,如果过期直接去更新缓存,否则直接返回。
本篇文章就介绍这里,以上是自己的一些技术总结,欢迎留言批评指正。















 56
56











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









