







APQ:Joint Search for Network Architecture, Pruning and Quantization Policy
APQ:联合搜索网络结构、剪枝和量化策略
from CVPR2020
MIT HAN Lab
Abstract
本文提出的APQ是一种新的深度学习模型高效部署的新方法。与之前方法将网络结构的优化、兼职策略、量化策略分开优化不同,本文将上述方法以联合的方式进行优化。为了解决搜索空间过大的问题本文设计一个量化感知的精度预测器辅助进行进化搜索,找到适应性最高的架构。由于直接训练预测器需要收集大量的量化数据,十分费时,因此本文提出使用预测器迁移的方法来获得量化感知预测器。这一过程是这样的:首先本文会生成一个由(网络结构,精度)组成的数据对作为训练数据集,这些数据是从预训练的once-for-all网络中采样得到;随后本文用上述数据训练未经量化的预测器;再将预测器的权重迁移训练量化感知预测器,这样大大减少了收集量化后数据的时间。在ImageNet上的实验表明这种联合的优化方式在保持ResNet34 8比特模型原有精度的前提下节省了8倍的BitOps,和MobileNetV2+HAQ相比分别减少了2倍延迟和1.3倍的能耗,与分开进行PeoxylessNAS+AMC+HAQ相比提升了2.3%的精度。
Section I Introduction
深度学习已广泛用于自动驾驶、机器人、移动端AR/VR等,其中网络效率是研究与部署落地之间最大的一块gap。在资源受限的特定平台上(如延迟、模型尺寸、能耗)需要对网络进行精心设计从而获得最优的性能。一般网络的高效设计会分为网络结构设计、模型压缩(量化和剪枝)两步分开进行。但已有研究表明这种串行的设计方法可以显著降低现有模型的cost,再加上调参可以进一步优化性能。但是将全流程考虑进来要考虑的超参数就会成指数增仓,超出人力所能负担的。因此为了解决这一为近期有提出AutoML进行自动化的设计过程,比如使用NAS。基于类似的思路还有研究使用强化学习通过自动剪枝和量化来压缩模型。但是分开优化会导致落入局部最优,往往全精度中性能最优的并不是最终量化和剪枝后性能最优的,并且三者分开进行会导致相当长的搜索时间和能耗,因此本文提出将三者联合起来进行网络在特定平台部署的优化。 但是直接将AutoML技术进行网络优化仍然存在问题,首先搜索难度指数上升,其次每一步的搜索空间之间都是相互影响的,每一步的优化目标也不尽相同,因此串行优化得到的最终结果往往不是最优的。
本文提出的APQ是一种联合优化方法,将传统的模型设计-剪枝-量化的设计过程转变为架构搜索+混合精度搜索过程。前者是一种由粗粒度到细粒度的过程,后者则致力于找到精度和资源之间最优的平衡点。这种转变是合理的,因为模型设计和剪枝可以看做是拓扑结构的改变量化可以看做是模块细节的调整,本文在这两方便都进行了效率的提升。在结构搜索方面本文需要训练一个更灵活的once-for-all的网络,不仅包含具体操作还能调成通道,这样可以在网络结构和通道数上均进行调整。在混合精度搜索方面由于网络结构和量化彼此正交,那么比较耗时的就是量化和预测精度部分,因此本文在量化后训练一个预测器来预测精度。这一预测器较难训练,一是因为它需要预测不同位宽模型的不同精度,二是收集大量量化数据十分费时,因此本文提出Predictor-Transfer Technique预测迁移技术来大大提升采样效率,这种量化感知的预测器从全精度预测器迁移而来,因袭收集的是全精度数据,从超网中收集数据对;然后将训练好的预测器的权重加快训练过程。这种联合优化方法无需重新训练整个系统就可以部署到不同的应用场景和硬件平台。
本文工作总结如下:
本文提出APQ联合优化方法将NAS搜索、剪枝、;量化结合在一起。
本文提出的预测迁移技术解决量化后的精度数据难以收集的问题
这种联合优化方法大大加速了网络的优化过程并且适用于不同的应用场景和硬件平台。
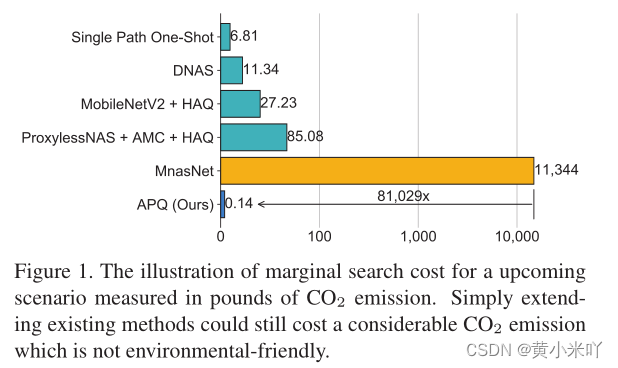
Section II Background and Outline
NAS
NAS一直致力于减少搜索时间,早期的NAS借助增强学习来确定cell级别的网络结构,为了更高效的搜索网络结构有的研究将搜索结构看做一个路径查找问题,还有的研究训练时的网络权重研究混合精度部署。还有的通过预测器预测精度也是为了减少搜索时间。
Pruning
剪枝早期聚焦于细粒度的剪枝,如研究权重矩阵去除某些连接,但是这种方法对CPU或GPU并不友好,主要涉及到矩阵的稀疏计算。后来有的研究提出使用通道级别的剪枝,比如根据L1范数等进行卷积通道的裁剪,但是上述两种搜会导致巨大的搜索空间,因为不同层的敏感度不同,比如第一个卷积对剪枝十分敏感,因为负责提取重要的低级特征,最后一层一般是冗余的所以对剪枝不敏感。因此近期研究主要是通过AutoML来自动决定稀疏哪一层。
Quantization
量化对于模型的硬件部署十分重要,比如将网络部署在FPGA或移动端。比如通过k-means进行量化权重,或者将权重二值化为±1亦或是量化为特定比特。HAQ中建议借助AutoML来确定混合精度的位宽。
Multi-stage Optimization
一般上述NAS搜搜+剪枝+量化的过程会串行分多步进行。
第一阶段在目标数据集上搜索精度最高的网络结构:
第二阶段进行通道剪枝
第三阶段进行混合精度量化
但三者分开进行可能得到的不是最优的结果,比如精度最高的浮点模型量化后也许并不是精度最高的。并且在特定数据及上验证也会花费很长时间,比如300 GPU hours。
Joint Optimization
联合优化致力于将网络的设计和搜索联合进行,因此优化目标变为:
但是这也加大了搜索空间,本文提出的解决办法是:
1-训练一个once-for-all网络包含最大的搜索空间,可以从中提取各种子网络而无需从头训练
2-设计一个量化感知的精度预测器来预测子网络的性能以及确定量化策略
3-建立一个延迟/能耗的查找表从而执行资源作为约束的进化搜索
Section III Joint Design Methodology
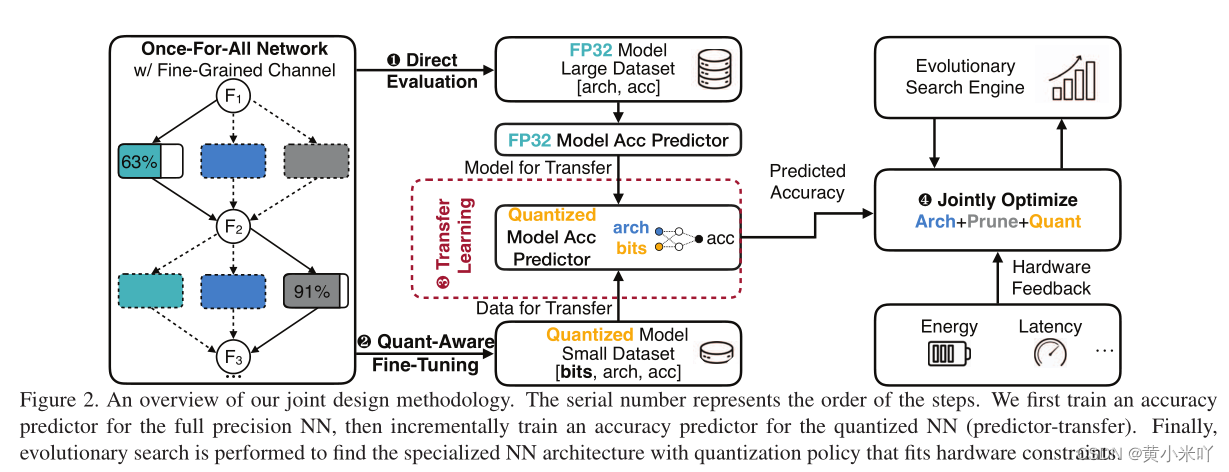
Fig 2展示了整个联合设计过程,包含一个高度灵活的once-for-all网络,细粒度通道裁剪和进化搜索。
Part 1 Once-for-all network with fine-grained channels
NAS致力于在大的搜索空间中找到最优的子网络结构,一般来说每次采样的子网路会计算真实的精度,这一过程十分费时费力。近期one-shotNAS首先会训练一个大网络再从中采样子网络,大网络就叫做once-for-all network,由于深度网络中不同层之间相互独立,因此可以针对每一层进行不同的搜索涉及。
本文使用MobineNetV2作为backbone,卷积核包含3,5,7,通道数包含4,6,8倍,深度有2,3,4,这样包含10^35种子网络。

Architecture and Quantization Policy Encoding
本文在block级别对网络结构进行编码,会对卷积核、通道数、权重、激活值的位宽进行编码,将上述级联作为模块编码后的结果。
举个例子,卷积核包含3,5,7选择那个就用一个one-hot向量表示你,通道数也是,还对编码位宽、连接方式均进行编码,这样一个75维度的向量就可以表征5层网络。
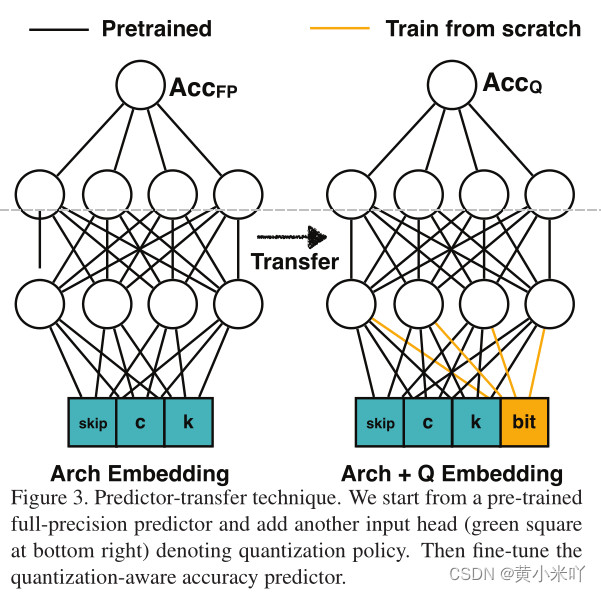
Accuracy Predictor
本文的精度预测器是一个3层的前馈网络,参见FIG 3,每层的嵌入维度为400,输入的是编码后的网络结构设置,但不会经常在目标数据集上进行验证。而是通过增强学习、贝叶斯优化、进化算法等来优化。这一步最大的挑战在于如何收集训练数据<结构,量化策略,精度>,收集这些数据十分费时每个数据点大概需要0.2GPU Hours ,本文测试收集80k数据点需要消耗16000 GOU hours。
本文的量化感知预测器训练起来更困难因为网络结构和量化策略会从两个不用的方面影响网络性能,因此传统的训练方法会导致严重的精度下降。
Transfer Predictor to Quantized Models
虽然收集量化后的精度数据很费事,但是收集全精度的数据很简单,直接选择子网络测试性能就可以。因此本文提预测迁移策略来提升采样效率。由于量化前后的精度一般都会保留,嫩we会预先在大规模数据集上预训练一个预测器来对全精度模型进行一个预测,然后迁移到量化模型上。参见Fig 3通过在当前模块加入量化位宽然后将全精度预训练的权重作为初始值继续进行微调,这样比从头训练所需的数据量要少。
Part 3 Hardware-aware evolutionary search
由于不同的硬件资源不同(内存大小、并行度)因此不同的硬件平台对应的最优的网络结构和量化策略往往是不同的。因此本文直接基于测试的延迟和能耗作为优化目标,而不是采用BitOps。
Measuring Latency and Energy
对实际硬件进行测试十分耗时,得益于神经网络的船型结构可以通过累加的方式计算每一层的延迟和功耗从而获得整体结果。因此对每一个候选操作建立查超标,这样就可以以忽略不计的计算成本累加得到整个结构最终的延迟信息,实际验证也发现推理时预测值十分精确。
Resource-Constrained Evolution Search
本文采用进化搜索来找到资源最优的网络结构,将进化搜索过程结合量化感知预测器精度预测来估计每一个候选结构的精度。计算次数从N次下降到一次,并且可以基于查找表将超出资源预算的选择直接去掉,进一步提升了搜索效率。
Section IV Implementation Details
Data preparation
为了训练量化敏感的预测器本文准备了两种数据,每种2500组:
(1)包含网络结构和量化策略的随机数据
(
2)随机采样网络结构,每种结构对应10种量化策略
这两种数据混合用于全精度预测器的训练,训练出的predictor就可以学习网络结构和量化策略之间的关系。
Evolutionary Achitecture Search
进化搜索中本文将种群规模设置为100,每次选择top-25生成下一代,每一个种群包含的是量化后的网络,使用同一编码方案,突变率为0.1,每次会随机选择新的卷积核和通道数进行变异,对于交叉则是子代会从父代的设置中进行选择。迭代进化500次选择最优的候选网络。
Quantization
量化会对网络权重和激活值均进行量化,每一层的位宽不同:
为了将KL散度降为最低每一层的v也是不同的。
Section V Experiments
为了验证本文的有效性选择两个对设备部署最重要的:延迟和功耗性能作为约束。同时也会比较BitOps这一指标。
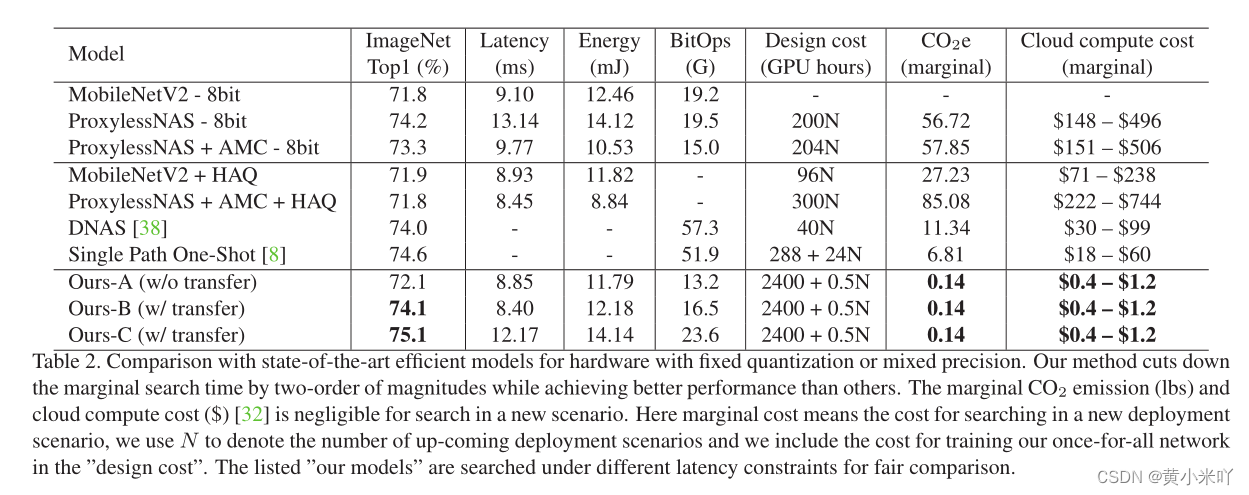
Part 1 Comparison with SOTA Efficient Models
Tab 2展示了不同约束下的效率,可以看到本文的方法在顶点和混合精度下都优于对应的SOTA。混合精度下提升了2.2%,更大的模型精度进一步提升,而BitOps却下降了,这也有利于减少碳排放,更加绿色环保。
Part 2 Effectiveness of Joint Design
Fig 4展示了在不同延迟和能耗约束下BitFusion的结果,本文这种联合优化设计出的模型在固定精度和混合精度下都优于对应的SOTA模型,尤其在资源极其有限的情况下提升更显著。从实验结果也能看出使用本文这种迁移后的精度预测器预测的更加准确,因为常规方法不可避免会丢失一些网络结构与精度之间的关联信息。
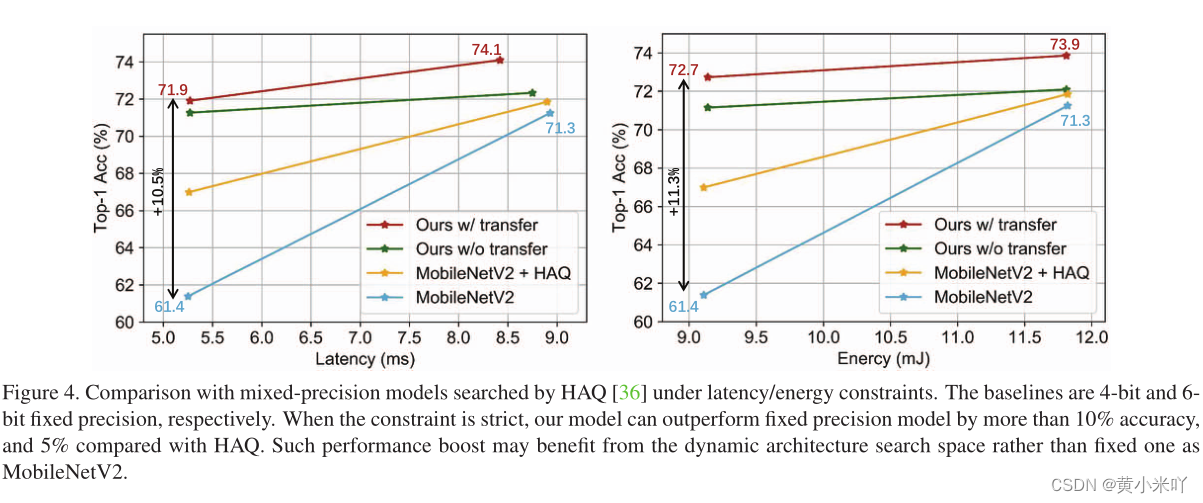
Comparison with Multi-Stage Optimized Model
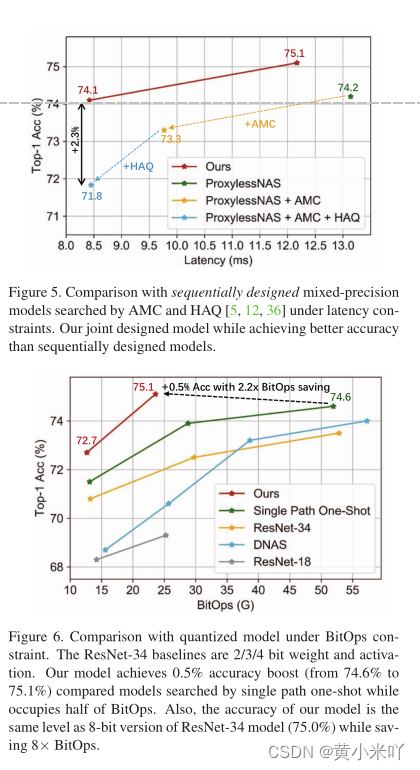
Fig 5展示了本文与多阶段优化方法的性能对比,可以看到在同样约束下,本文的精度比多阶段的提升了2.3%,这也是可以理解的因为每一阶段单独优化并不一定能获得最终的最优结果。
Comparison under Limitd BitOps
Fig 6展示了当BitOps有限时的规避结果,本文提升了2%,或者在达到相同精度下ResNet减少了8x BitOps
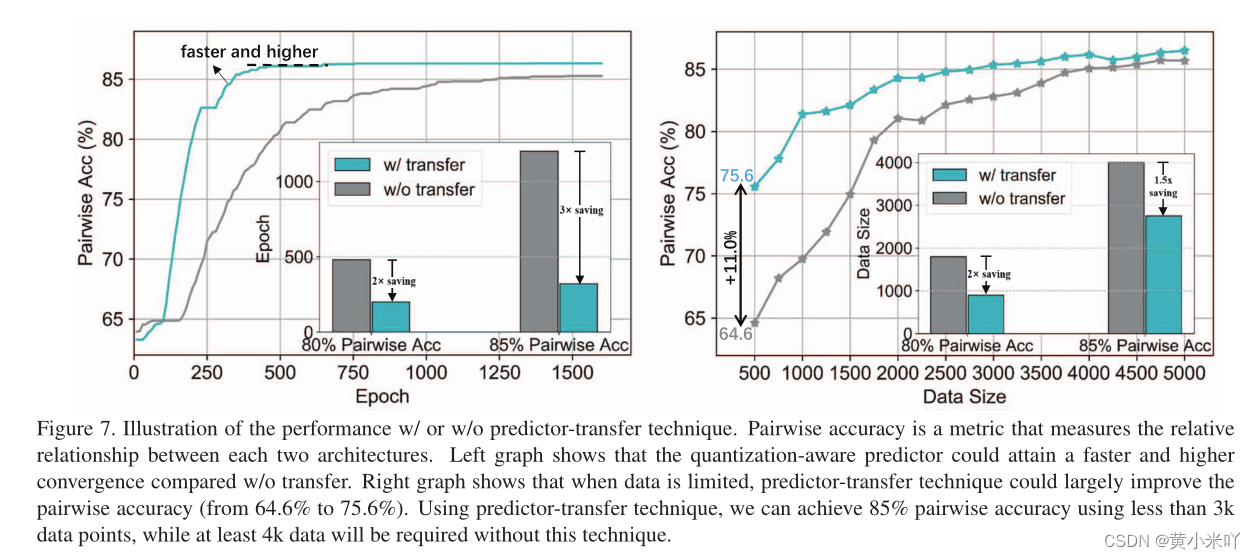
Part 3 Effectiveness of Predictor-Transfer
Fig 7展示了预测器的性能,与从头开始训练相比本文这种基于迁移的方法训练的更快最终精度更高,收敛的更快后续训练所需要的数据量也更少。
Section VI Conclusion
本文提出的APQ是一种将网络搜索、剪枝和量化结合用于混合精度模型设计的方法。与之前方法的不同之处在于不需要多阶段进行而是融合为一个完整的优化流程。本文使用基于预测器的方法有效减少了搜索成本,同时减少了碳排放。为了解决高昂的数据收集问题本文还提出预测器迁移方法,加速了训练减少了数据需求。本文的实验结果充分证实了这种联合优化的有效性。














 3149
3149











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









