







group by子句将查询结果按某一列或多列的值分组,值相等的为一组。
对查询结果分组,是为了细化“聚集函数”的作用范围。
如果不对查询结果分组,“聚集函数”将作用于整个查询结果。
分组后“聚集函数”将作用于每一组,即每一组都有一个函数值。
这是在《数据库系统概论》里的话,但我觉的,group by子句可以理解成,先把数据按group by子句分组,再在分组里分别执行select。
查询结果分组
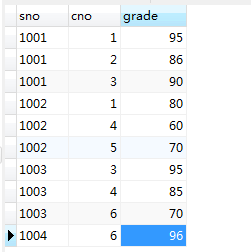
select cno 课程代号, count(sno) 选课人数
from sc
group by cno
将查询结果按课程代号分组,然后在各个分组里count
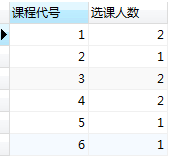
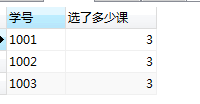
having
select sno 学号, count(cno) 选了多少课
from sc
group by sno
having count(*)>=3
having是将group by的分组进行筛选。
本例中,
- group by sno 将数据分为四组,
- having count(*)>=3 将元组数大于3的组筛选出来
- select sno 学号, count(cno) 选了多少课 最后执行select
where、having的区别
where子句作用于基本表或视图,从中选择满足条件的元组。
having短语作用于group by 组,从中选择满足条件的组。















 6552
6552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









