







前言
说到服务信息,我们还是得回到NamingService,因为这是和NacosServer进行服务注册的核心组件,内部提供了注册、获取Nacos实例的能力。至于其他组件,如Ribbon,在调用时需要所有实例信息来进行负载,那肯定就是通过NamingService的能力来获取到所有的实例。
NamingService
在NamingService中获取实例主要有两类方法,一类是getAllInstances、另一类是selectInstances,它们最主要的区别就是selectInstances增加了对实例是否健康的过滤的支持。
既然如此,那我们直接来就看看selectInstances的逻辑:
@Override
public List<Instance> selectInstances(String serviceName, String groupName, List<String> clusters, boolean healthy,
boolean subscribe) throws NacosException {
ServiceInfo serviceInfo;
if (subscribe) {
serviceInfo = hostReactor.getServiceInfo(NamingUtils.getGroupedName(serviceName, groupName),
StringUtils.join(clusters, ","));
} else {
serviceInfo = hostReactor
.getServiceInfoDirectlyFromServer(NamingUtils.getGroupedName(serviceName, groupName),
StringUtils.join(clusters, ","));
}
return selectInstances(serviceInfo, healthy);
}
上述代码有两个逻辑:
1、传入的subscribe,如果是true,就代表是订阅模式,就走hostReactor.getServiceInfo查询,反之走hostReactor.getServiceInfoDirectlyFromServer查询。
2、根据实例的健康状态进行过滤返回。
那我们就先走进HostReactor,对它提供的两个能力进行分析:
HostReactor
这个类是在实例化NamingService时在构造函数中实例化的一个对象。
而在HostReactor实例化时,其构造函数会创建一个定时线程池,核心线程数量可以通过spring.cloud.nacos.discovery.namingPollingThreadCount进行控制,默认是当前机器核心数的一半,最少为1。
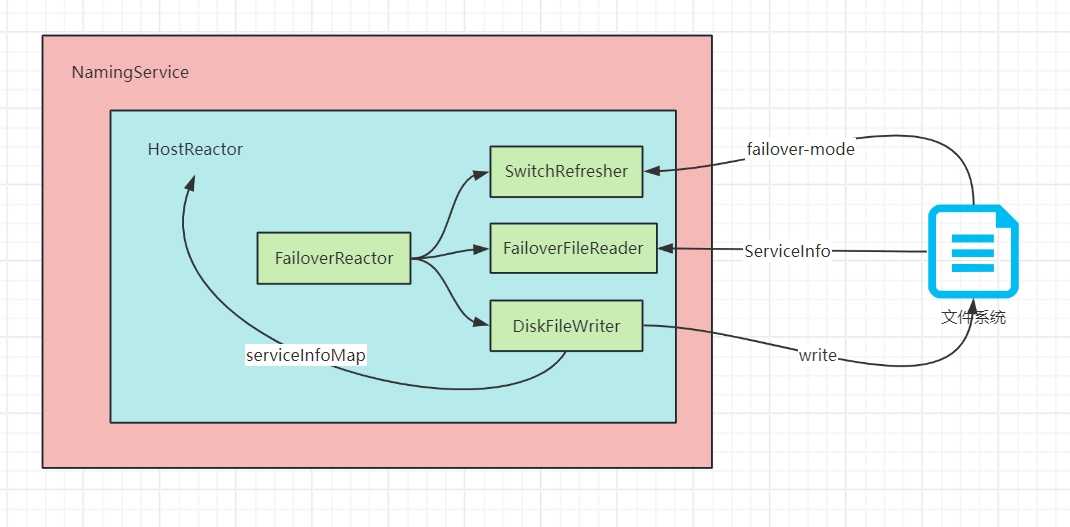
也会实例化一个FailoverReactor,是一个容灾备份反应器,其内部实例化了一个单线程的定时线程池,内部由两个延迟定时任务组成:
-
SwitchRefresher每隔5秒去检查文件系统中是否有
cacheDir + "/failover00-00---000-VIPSRV_FAILOVER_SWITCH-000---00-00"文件,如果有,那么就标记为容灾模式。cacheDir的取值如下:private void initCacheDir() { cacheDir = System.getProperty("com.alibaba.nacos.naming.cache.dir"); if (StringUtils.isEmpty(cacheDir)) { cacheDir = System.getProperty("user.home") + "/nacos/naming/" + namespace; } } -
FailoverFileReader如果是容灾模式,就从文件中读取Service信息。
-
DiskFileWriter初始延迟30分钟,后每隔1天将
serviceInfoMap(服务信息)写入到cacheDir + "/failover文件夹下。
整个FailoverReactor的示意图如下:
在了解了HostReactor的基本情况后,我们来对上面调用的两个方法进行分析。
getServiceInfo
public ServiceInfo getServiceInfo(final String serviceName, final String clusters) {
NAMING_LOGGER.debug("failover-mode: " + failoverReactor.isFailoverSwitch());
String key = ServiceInfo.getKey(serviceName, clusters);
// 如果是容灾模式,就从failoverReactor中获取文件系统中缓存的ServiceInfo信息
if (failoverReactor.isFailoverSwitch()) {
return failoverReactor.getService(key);
}
// 从HostReactor维护的serviceInfoMap中取ServiceInfo
ServiceInfo serviceObj = getServiceInfo0(serviceName, clusters);
// 如果HostReactor中没有
if (null == serviceObj) {
serviceObj = new ServiceInfo(serviceName, clusters);
// 存入serviceInfoMap
serviceInfoMap.put(serviceObj.getKey(), serviceObj);
updatingMap.put(serviceName, new Object());
// 查询服务端的这个Service的信息,如果有,则使用和接收到服务端Service推送一致的更新处理
updateServiceNow(serviceName, clusters);
updatingMap.remove(serviceName);
} else if (updatingMap.containsKey(serviceName)) {
// 如果原来的serviceInfoMap有数据,但updatingMap又存在,说明可能存在了并发问题,则需要锁住serviceObj一段时间,等待执行完成
if (UPDATE_HOLD_INTERVAL > 0) {
// hold a moment waiting for update finish
synchronized (serviceObj) {
try {
serviceObj.wait(UPDATE_HOLD_INTERVAL);
} catch (InterruptedException e) {
NAMING_LOGGER
.error("[getServiceInfo] serviceName:" + serviceName + ", clusters:" + clusters, e);
}
}
}
}
// 用一个定时线程池去执行Servcie的主动更新
scheduleUpdateIfAbsent(serviceName, clusters);
// 从本地serviceInfoMap中获取ServiceInfo
return serviceInfoMap.get(serviceObj.getKey());
}
在现在就去更新服务信息的方法updateServiceNow中,最终会调用的processServiceJson方法,方法太长,直接说逻辑:
public ServiceInfo processServiceJson(String json) {
....
}
1、如果是以前就存在于本地serviceInfoMap中的数据,就分别计算出其中新增,修改,删除的实例,如果是修改的实例,需要更新心跳信息。
2、更新本地serviceInfoMap。
3、使用EventDispatcher发布通知事件。
4、ServiceInfo写入本地磁盘。
在定时更新服务信息的方法scheduleUpdateIfAbsent中:
public void scheduleUpdateIfAbsent(String serviceName, String clusters) {
if (futureMap.get(ServiceInfo.getKey(serviceName, clusters)) != null) {
return;
}
synchronized (futureMap) {
if (futureMap.get(ServiceInfo.getKey(serviceName, clusters)) != null) {
return;
}
ScheduledFuture<?> future = addTask(new UpdateTask(serviceName, clusters));
futureMap.put(ServiceInfo.getKey(serviceName, clusters), future);
}
}
如果futureMap中不存在这个Service的任务,才会使用addTask进行添加。addTask中就是将UpdateTask延迟1s执行一次。具体后续调用是在UpdateTask中实现的。
@Override
public void run() {
long delayTime = DEFAULT_DELAY;
try {
ServiceInfo serviceObj = serviceInfoMap.get(ServiceInfo.getKey(serviceName, clusters));
if (serviceObj == null) {
updateService(serviceName, clusters);
return;
}
if (serviceObj.getLastRefTime() <= lastRefTime) {
updateService(serviceName, clusters);
serviceObj = serviceInfoMap.get(ServiceInfo.getKey(serviceName, clusters));
} else {
// if serviceName already updated by push, we should not override it
// since the push data may be different from pull through force push
refreshOnly(serviceName, clusters);
}
lastRefTime = serviceObj.getLastRefTime();
if (!eventDispatcher.isSubscribed(serviceName, clusters) && !futureMap
.containsKey(ServiceInfo.getKey(serviceName, clusters))) {
// abort the update task
NAMING_LOGGER.info("update task is stopped, service:" + serviceName + ", clusters:" + clusters);
return;
}
if (CollectionUtils.isEmpty(serviceObj.getHosts())) {
incFailCount();
return;
}
delayTime = serviceObj.getCacheMillis();
resetFailCount();
} catch (Throwable e) {
incFailCount();
NAMING_LOGGER.warn("[NA] failed to update serviceName: " + serviceName, e);
} finally {
executor.schedule(this, Math.min(delayTime << failCount, DEFAULT_DELAY * 60), TimeUnit.MILLISECONDS);
}
}
上述代码简化一下,就是以下几个点:
1、如果本地serviceInfoMap中没有这个Service,就去服务端查询并更新。
2、如果通过这样的拉模式下最后修改的时间是大于这个Service本身的修改时间的,才进行更新。
3、下一次执行的时间是根据失败次数来定的,比如第一次失败,那就是delayTime左移一位,失败几次就左移几次,最多左移6次,且最大延迟60s执行。
getServiceInfoDirectlyFromServer
public ServiceInfo getServiceInfoDirectlyFromServer(final String serviceName, final String clusters)
throws NacosException {
String result = serverProxy.queryList(serviceName, clusters, 0, false);
if (StringUtils.isNotEmpty(result)) {
return JacksonUtils.toObj(result, ServiceInfo.class);
}
return null;
}
这个方法就是直接请求服务端拿到ServiceInfo的数据。
思考
看到这里,我们会不会有个疑问?那就是HostReactor是通过定时执行去更新服务信息的,那如果在时间间隔内有其他Servcie信息的更新呢?那我们岂不是得等到下一次任务执行时才能得到更新后的信息?
Nacos是考虑到了的,通过用定时任务通过HTTP去拉数据,和接收服务端通过UDP推送的数据,一拉一推来保证数据的实时性。
HostReactor中的PushReceiver就是客户端侧对服务端侧推数据的处理器。
PushReceiver
HostReactor在实例化时,其构造方法中也会实例化一个PushReceiver,其内部是一个单线程的定时线程池,死循环,用来接收来自服务端的信息,以及向服务端发送ACK确认信息。
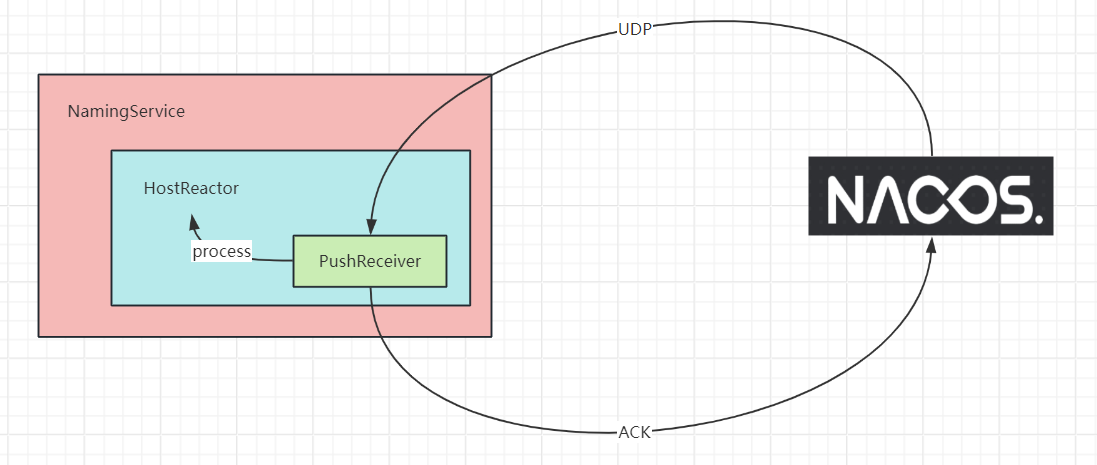
核心代码如下:
@Override
public void run() {
while (!closed) {
try {
// byte[] is initialized with 0 full filled by default
byte[] buffer = new byte[UDP_MSS];
DatagramPacket packet = new DatagramPacket(buffer, buffer.length);
udpSocket.receive(packet);
String json = new String(IoUtils.tryDecompress(packet.getData()), UTF_8).trim();
NAMING_LOGGER.info("received push data: " + json + " from " + packet.getAddress().toString());
PushPacket pushPacket = JacksonUtils.toObj(json, PushPacket.class);
String ack;
if ("dom".equals(pushPacket.type) || "service".equals(pushPacket.type)) {
hostReactor.processServiceJson(pushPacket.data);
// send ack to server
ack = "{\"type\": \"push-ack\"" + ", \"lastRefTime\":\"" + pushPacket.lastRefTime + "\", \"data\":"
+ "\"\"}";
} else if ("dump".equals(pushPacket.type)) {
// dump data to server
ack = "{\"type\": \"dump-ack\"" + ", \"lastRefTime\": \"" + pushPacket.lastRefTime + "\", \"data\":"
+ "\"" + StringUtils.escapeJavaScript(JacksonUtils.toJson(hostReactor.getServiceInfoMap()))
+ "\"}";
} else {
// do nothing send ack only
ack = "{\"type\": \"unknown-ack\"" + ", \"lastRefTime\":\"" + pushPacket.lastRefTime
+ "\", \"data\":" + "\"\"}";
}
udpSocket.send(new DatagramPacket(ack.getBytes(UTF_8), ack.getBytes(UTF_8).length,
packet.getSocketAddress()));
} catch (Exception e) {
NAMING_LOGGER.error("[NA] error while receiving push data", e);
}
}
}
上述代码主要有以下几个逻辑:
1、死循环接收udp的数据。
2、如果是"dom"或者"service"类型的消息,会交由HostReactor进行处理。
3、向服务端发送ack确认信息。
总结
Nacos是通过定时任务使用HTTP拉数据,和接收服务端通过UDP推送的数据来实现更新服务信息的目的。
今天的内容中还涉及到了Nacos的容灾处理,可以通过在磁盘中配置达到开启本地容灾的模式。在获取实例时,就会去本地磁盘中的备份文件中去找服务实例的数据。














 566
566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









