






Kubernetes 中的 kube-prometheus 是一个基于 Prometheus Operator 的完整监控解决方案,它集成了 Prometheus、Alertmanager、Grafana 以及一系列预定义的监控规则和仪表盘,专为 Kubernetes 集群设计。
一、核心组件介绍
- Prometheus Operator :用于自动化管理 Prometheus 及其相关资源(如 ServiceMonitor、PodMonitor、PrometheusRule)
- Prometheus:负责指标采集、存储和告警规则的评估
- Alertmanager:处理 Prometheus 发送的告警,进行分组、去重、静默和通知(如邮件)
- Grafana:提供预配置的监控仪表盘,可视化集群和应用指标
- 预定义监控规则:包含 Kubernetes 核心组件(API Server、kubelet、etcd 等)的告警规则和仪表盘配置
二、NFS存储部署
1.下载安装nfs和rpcbind
[root@master-2 ~]# yum -y install nfs-utils
[root@master-2 ~]# mkdir -p /ifs/kubernetes
[root@master-2 ~]# chmod -R 777 /ifs/kubernetes
[root@master-2 ~]# vim /etc/exports
/ifs/kubernetes *(rw,no_root_squash,sync)
#作为NFS的依赖服务,协调客户端与服务器端的通信
[root@master-3 ~]# yum -y install rpcbind
2.启动
[root@master-2 ~]# systemctl enable --now rpcbind
[root@master-2 ~]# systemctl enable --now nfs3.测试nfs
#使配置生效
[root@master-2 ~]# exportfs -f
[root@master-2 ~]# showmount -e 192.168.91.19
Export list for 192.168.91.19:
/ifs/kubernetes *
#所有node查看nfs是否可以看到
[root@node-1 ~]# showmount -e 192.168.91.19
Export list for 192.168.91.19:
/ifs/kubernetes *4.部署动态存储
#下载相关安装包
https://pan.baidu.com/s/1gZ3CCKadSyH80ZKxM30smg?pwd=2ayp
#导入镜像
[root@node-2 ~]# docker load -i nfs-client-provisioner.tar.gz
#部署存储
[root@master-1 nfs]# unzip nfs.zip
Archive: nfs.zip
inflating: pvc.yaml
inflating: nfs-class.yaml
inflating: nfs-deployment.yaml
inflating: nfs-rabc.yaml
[root@master-1 nfs]# ll
total 45024
-rw-r--r-- 1 root root 225 Nov 20 2019 nfs-class.yaml
-rw-r--r-- 1 root root 1032 Mar 20 21:40 nfs-deployment.yaml
-rw-r--r-- 1 root root 1526 Nov 20 2019 nfs-rabc.yaml
-rw-r--r-- 1 root root 223 Mar 31 2024 pvc.yaml
#修改nfs的ip地址为自己的nfs地址额
[root@master-1 nfs]# sed -i 's/192.168.91.18/192.168.91.19/g' nfs-deployment.yaml
[root@master-1 nfs]# kubectl apply -f .
[root@master-1 nfs]# kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
managed-nfs-storage fuseim.pri/ifs Delete Immediate false 5s
三、部署监控系统
1.下载镜像和yaml文件
#1.下载
https://pan.baidu.com/s/1wTyT8DqH7_tS6wEWYFxVng?pwd=r6a5
#2.解压
[root@master-1 ~]# tar xf monitor.1.23.tar.gz
[root@master-1 ~]# cd monitor/serviceMonitor
#3.查看k8s组件ip是否正确,根据情况修改
[root@master-1 serviceMonitor]# ls | xargs grep 192.168.91
prometheus-EtcdService.yaml: - ip: 192.168.91.18
prometheus-EtcdService.yaml: - ip: 192.168.91.19
prometheus-EtcdService.yaml: - ip: 192.168.91.20
prometheus-kubeControllerManagerService.yaml: - ip: 192.168.91.18
prometheus-kubeControllerManagerService.yaml: - ip: 192.168.91.19
prometheus-kubeControllerManagerService.yaml: - ip: 192.168.91.20
prometheus-KubeProxyService.yaml: - ip: 192.168.91.21
prometheus-KubeProxyService.yaml: - ip: 192.168.91.22
prometheus-kubeSchedulerService.yaml: - ip: 192.168.91.18
prometheus-kubeSchedulerService.yaml: - ip: 192.168.91.19
prometheus-kubeSchedulerService.yaml: - ip: 192.168.91.202. 创建资源
#crd资源对象 prometheus-operator
[root@master-1 monitor]# kubectl create -f setup/
#监控
[root@master-1 monitor]# kubectl apply -f alertmanager/
#节点的资源
[root@master-1 monitor]# kubectl apply -f node-exporter/
#容器的资源使用率
[root@master-1 monitor]# kubectl apply -f kube-state-metrics/
#可视化界面
[root@master-1 monitor]# kubectl apply -f granfa/
#
[root@master-1 monitor]# kubectl apply -f prometheus/
[root@master-1 monitor]# kubectl apply -f serviceMonitor/
[root@master-1 nfs]# kubectl get pods -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 39m
alertmanager-main-1 2/2 Running 0 39m
alertmanager-main-2 2/2 Running 0 39m
grafana-f44f5bd49-9zxtg 1/1 Running 0 38m
kube-state-metrics-6c8846558c-5ljt7 3/3 Running 0 38m
node-exporter-jcpmw 2/2 Running 0 39m
node-exporter-jkmdt 2/2 Running 0 39m
prometheus-k8s-0 2/2 Running 0 38m
prometheus-k8s-1 2/2 Running 0 38m
prometheus-operator-f59c8b954-vqbwg 2/2 Running 0 39m3.解决pvc绑定问题
[root@master-1 nfs]# vim /etc/kubernetes/cfg/kube-apiserver.cfg
添加添加- --feature-gates=RemoveSelfLink=false
[root@master-1 nfs]# systemctl restart kube-apiserver 5.查看地址并访问
#grafana
[root@master-1 nfs]# kubectl get pod -A -o wide| grep grafana
monitoring grafana-f44f5bd49-9zxtg 1/1 Running 0 39m 172.17.14.8 node-2 <none> <none>
[root@master-1 nfs]# kubectl get svc -A | grep grafana
monitoring grafana NodePort 10.0.0.36 <none> 3000:38801/TCP 40m
#页面访问并导入etcd和node-exporter模板
http://192.168.91.22:38801/
用户与密码: admin/admin
#访问prometheus
[root@master-1 nfs]# kubectl get svc -A | grep prometheus-k8s
monitoring prometheus-k8s NodePort 10.0.0.166 <none> 9090:49004/TCP,8080:34712/TCP 69m
6.监控部分截图
点击general查看监控
监控项
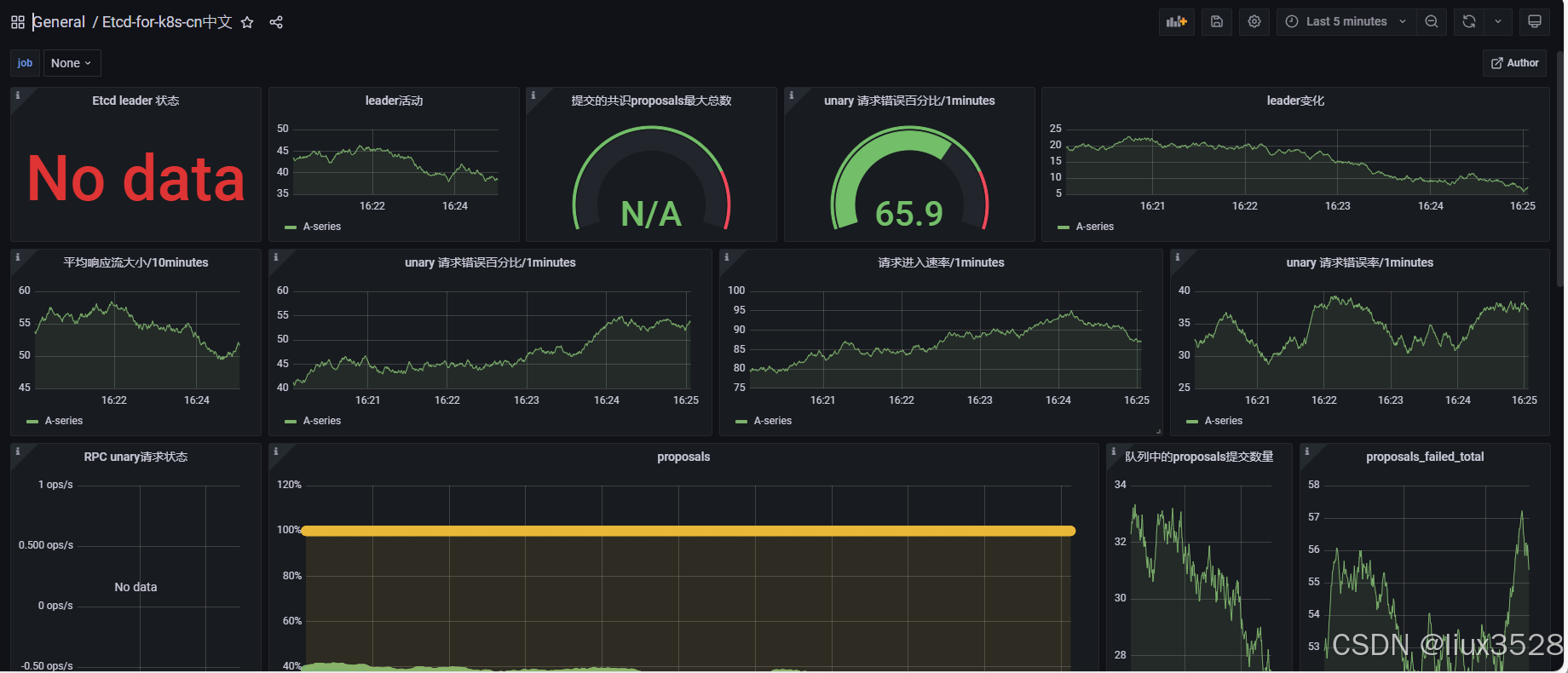
监控etcd


















 1238
1238

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











