







 在Python爬虫中处理图片信息时,可以使用pytesseract库配合Tesseract-OCR进行文字识别。首先通过pip安装pytesseract和pillow,然后下载并配置Tesseract-OCR的环境变量。如果遇到'Image cannot be loaded because it does not have enough color channels'错误,需将图片模式从RGBA转换为RGB,以避免分配调色盘给透明通道的问题。
在Python爬虫中处理图片信息时,可以使用pytesseract库配合Tesseract-OCR进行文字识别。首先通过pip安装pytesseract和pillow,然后下载并配置Tesseract-OCR的环境变量。如果遇到'Image cannot be loaded because it does not have enough color channels'错误,需将图片模式从RGBA转换为RGB,以避免分配调色盘给透明通道的问题。
在写爬虫的时候总是遇到一些以图片的形式展示的信息,因此要怎么解析图片上的信息呢?在Google上查了一下,需要安装pytesseract和pillow(我用的python3.7)和Tesseract-OCR
- 安装pytesseract
pip insatll pytesseractpip insatll pytesseract - 安装pillow
- 安装Tesseract-OCR(https://github.com/tesseract-ocr/tesseract)
- 安装完后将Tesseract-OCR的安装路径添加到环境变量中PATH和Path中,都要添加。例如:
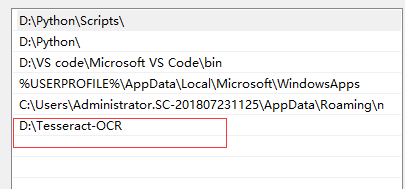
- 在python的安装路径下的修改安装的pytesseract库里面的pytesseract.py,将默认的改成Tesseract-OCR的安装路径
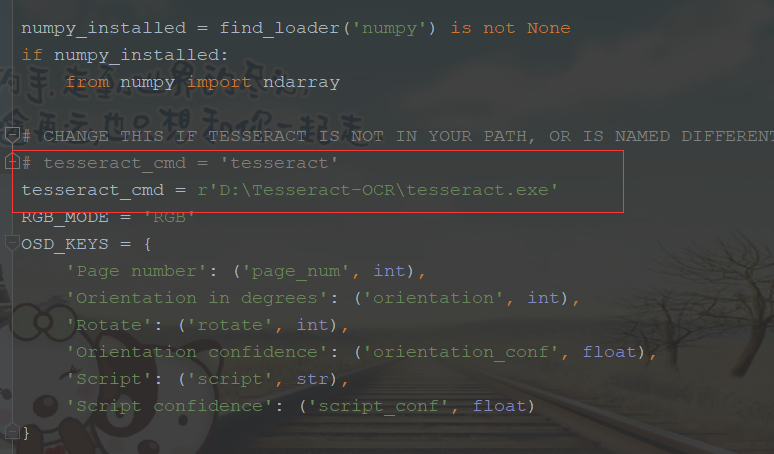
- 配置完了开始撸代码吧
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 718
718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









