








这篇文章要讨论的是2008年在ICSE会议上发表的静态分析工具论文:
Calysto。这个bug-finding工具有比较好的精度的同时,又能检测比较大规模的代码。它实现
函数间路径敏感,上下文敏感。能够扫描几十万行代码规模的开源项目。
我关注这篇文章主要对一个地方感兴趣:如何实现函数间路径敏感的同时又能扩展到几十万行代码规模,这其中有一些什么样的设计决策?
我对其中的一些设计决策比较感兴趣,读了好几次,有所体会。其中一些决策被用到我平时的开发中,确实有用。
不过作者并没有给出任何算法/伪代码的细节。。。。。。。所以抱着怀疑的态度试着读。。。
1. 简介
函数间路径敏感
- 在考虑分支条件约束
- 考虑函数调用,以下逻辑要保留在约束求解时的逻辑公式中:
- actual与formal参数保证相等
- return与receiver保证相等
函数间路径敏感技术,虽然能够得到精度高的分析结果,但是分析不能扩展到大规模的代码,实用性比较低。而作者提出的方法,能够扩展到几十万行的代码规模。作者提出的方法,实验结果误报率低于23%。
下面是架构图:
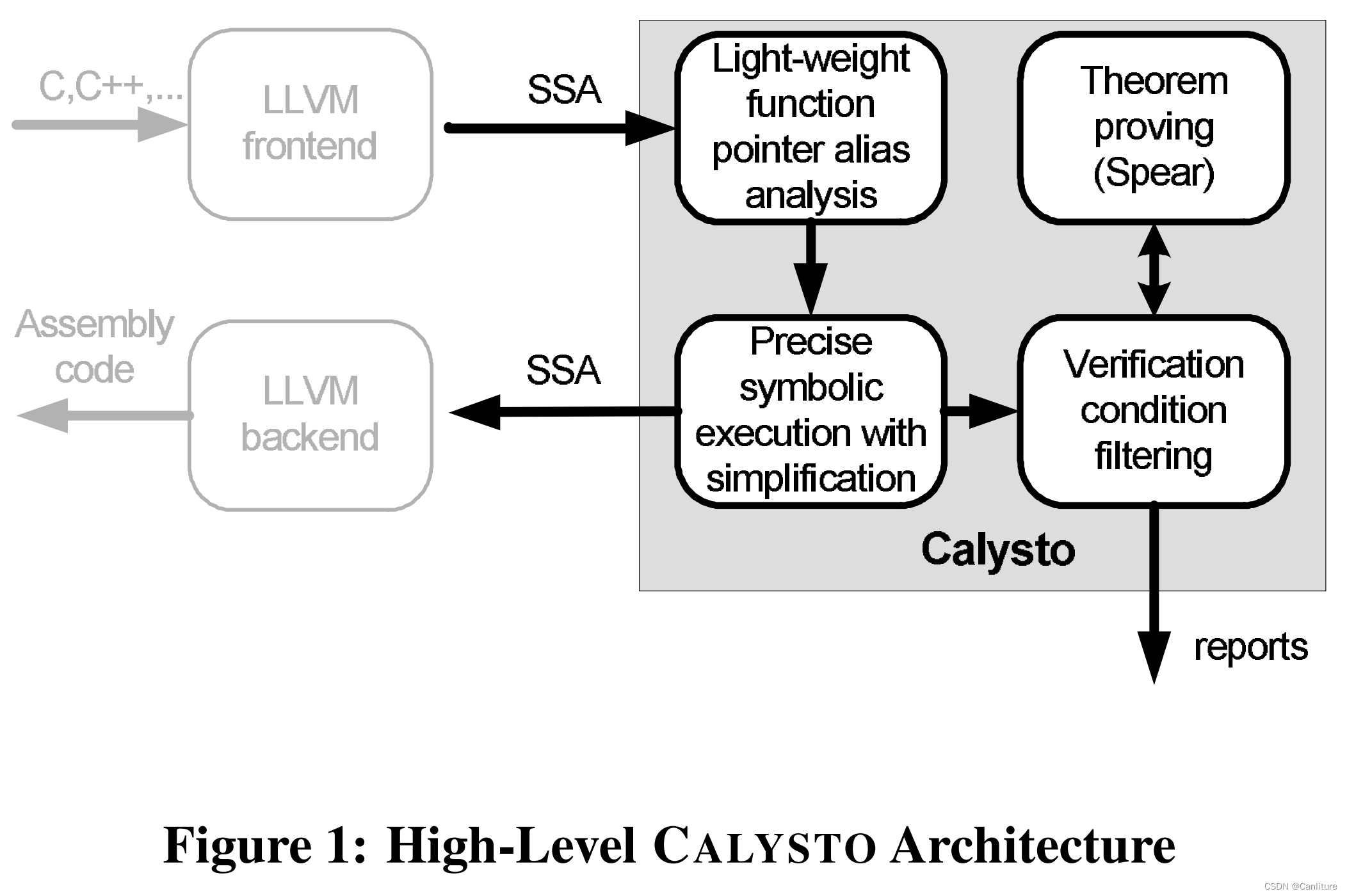
作者把分析过程当做LLVM编译的一个Pass。分析过程分3阶段
-
第一阶段:轻量级的指针别名分析
- 这阶段只是单纯地为了补全调用图上的间接调用
- C程序中,直接调用关系可以直接通过函数名确定
- 它只分析函数指针,用于构造函数指针导致的间接调用边。
- flow-sensitive
- context-insensitive
- 相比整个分析过程的资源开销,可以忽略不计。实际仍然能够获取足够的精度。
- 这阶段只是单纯地为了补全调用图上的间接调用
-
第二阶段:符号执行
- 为每个assert,和每个指针解引用生成verification condition(
VC); - VC就是一些逻辑公式,它如果求解不可满足,那么程序就可能存在某些缺陷。
- 为每个assert,和每个指针解引用生成verification condition(
-
第三阶段:检查,过滤Verification Conditions
- 过滤是避免重复求解
- 同一个上下文下被检查的函数,只报告出一个缺陷 (当然,这会导致漏报)
- 这里所说的上下文是指调用上下文。
- 同一个上下文下被检查的函数,只报告出一个缺陷 (当然,这会导致漏报)
- 检查
- 如果特定缺陷检查时,发现依赖了全局变量,那么在报告缺陷的时候,会把调用图上从main到报出缺陷的函数之间的执行trace记录下来。(这里可以看出,函数间路径敏感的特点)
- 约束求解使用的定理证明器叫Spear,是作者自己开发维护的一个SAT求解器。
2. 设计决策
2.1 提高精度的一些决策:
-
Bit-Precise: 也就是将程序的语义转换为逻辑公式,利用SAT求解器求解bit-vector级别的逻辑公式。 -
Interprocedural-Path-Sensitive: 实际的代码缺陷可能跨5-7层调用深度,仅仅函数内路径敏感可能不够。 -
Fully, precisely context-sensitive:- fully的理解:上下文敏感的同时,又是inter-procedural路径敏感。
2.2 Unsound决策
程序
验证工具要求分析是Sound的,即:能够上近似所有的语义行为,需要处理很多复杂的语言特性,同时需要迭代到不动点,耗时,可能误报率也比较高。但是如果sound的分析工具没有报出警告,就能够证明程序中不存在特定的bug。而bug-finding工具,一般会做出一些unsound的决策:可能并不会处理复杂的语言特性,甚至为了保证一定时间内能够结束分析,不需要一直迭代到不动点,因此可以设置固定的迭代次数。这样,对于一些特定的问题,在精心设计一些决策后,能够得到比较低的误报率。(漏报率是一个问题…)
下面是Calysto做出的一些unsound的决策,这些决策可能导致实际误报/漏报,但是能够提升scalability。
- 浮点操作
- 转换浮点变量/常量为整数
- 循环
- 循环展开一次。这是漏报的主要原因。
- 递归调用
- 与循环类似,识别call graph上的回边,并删除。即:忽略递归调用。
- 指针算数
- 对于指针算数
*(ptr + i), 除非i是已知常数,否则将所有这种表达式都认为等同于*ptr- 也就是说
ptr与ptr + i被认为是别名
- 也就是说
- 对于指针算数
下面是循环的一个例子:
int cnt = 0; bool c2 = false; while (c1) { if (c2) { cnt++; } c2 = true; } if (cnt == 0) { exit(1); } // ...循环展开一次,
if (c2)分支被认为是不可达代码。会导致漏报。 - 过滤是避免重复求解
当然,作者还提到了其它的trace-off,这里不一一介绍,可详细见论文。
3. 提升Scalability
如何保证*-sensitive (path-, context-, field-sensitive)的同时,还能扩展到分析几十万行的代码?
3个方法
- 符号执行
- VC过滤
- 约束求解
3.1 结构保留的符号执行 (Structure-Preserving Symbolic Execution)
3.1.1 符号执行
作者设计的符号执行算法是沿着调用图,自底向上,一次处理一个函数。处理完毕后,为函数的每个副作用存储一份摘要(符号表达式)。
函数副作用指的是
- 返回值
- 修改的全局变量
- 修改的非局部内存位置
- 例如参数指针的某个字段被写
- param->field = xxx
- global->elem = xxx
- 例如参数指针的某个字段被写
下面举个例子,介绍作者提出的Structural Abstraction符号执行
int g;
int b() {
int r = g + 2;
return r;
}
int f() {
int r = g + 1;
int t = r + b(); // call-site A
g = g + 1;
return t;
}
int main() {
int a = f(); // call-site B
int t = a + g;
assert t == 0;
}
调用图为 main -> f -> b
- 首先分析b, 得到返回值副作用的摘要为:
b_ret: b_ret = g + 2
- 再分析f,得到返回值和全局变量的副作用摘要
f_ret: f_ret = g + 1 + A_b_summary_ret_operator- A_b_summary_ret_operator 表示: A处,b的返回值占位
f_g_ret: f_g_ret = g + 1
- 在分析main,得到assert处t的符号表达式为
t: B_f_summary_ret_operator + B_g_summary_ret_operator- +号左侧表示B处f返回值摘要占位符
- +号右侧表示B处全局变量g摘要占位符
检查assert t == 0是否违反
- 如果sat(可满足)
- 意味着,不需要展开summary-operator占位,就已经可满足了。不报告违反。
- 如果不可满足(unsat)
- 如果被检查符号表达式
存在需要展开的summary-operator, 则,展开summary-operator,继续检查。如果不存在,则报告违反。 - 继续进行
sat/unsat判断 ----> 展开的循环中。直到没有可展开的summary-operator。
- 如果被检查符号表达式
// symbols: n1 ^ n2 ^ n3 ^ ... ^ nn ^ sum_op1 ^ sum_op2 ^ ... ^ sum_opn
// 被检查的符号表达式为如上的CNF形式的,可表示成列表:
// [n1, n2, , ..., nn, sum_op1, sum_op2, ..., sum_opn]
// 其中 ni表示一般的符号表达式 (非summary_operator)
// sum_opi表示summary-operator
function checkUnSAT(symbols) {
while (true) {
// 约束求解
unsat <- satSolver(symbols)
if (!unsat) {
// 如果可满足
return false;
}
// 如果不可满足
// 如果不存在需要展开的summary-operator
if (symbols have no summary-operators) {
return true;
}
// 如果存在需要展开的summary-operator
// 替换sum_op为callee对应的符号表达式
(sum_op, symbols) <- remove a summary-operator from symbols
// 这里sum_op表示summary_op对应的变量要等于返回值
// 而返回值又展开成它的副作用符号表达式,这样就维护了上下文敏感,函数间路径敏感
sym <- (sum_op == fun_var_ret ^ fun_var_ret = xxxx)
// 将被移除summary-operator的展开形式插入最终的公式中
symbols <- symbols U sym
// loop迭代,继续求解
}
}
3.1.2 Gated SSA
LLVM IR中的SSA是partial SSA。它将变量分为两类:top-level和address-token。如果一个变量被取过地址,那么它潜在地可能会被间接store,将其当做address-token变量。在进行SSA算法执行时,不考虑这类变量。
这导致两个问题,在实际程序分析中不够用或者不够精确。
- def-use之间的路径条件没有显式化。在传统构造SSA的算法中,并没有将Def到Use之间的路径条件给显式。而在依赖图上做符号执行是需要显式知道def-use之间的path condition。
- SSA只考虑top-level变量。真实程序有必要考虑address-token变量,或者间接内存读写,对精度提升是很重要的。
作者利用Gated Single Assignment替换传统的SSA,能够在Def-Use边上标记路径条件。将phi函数替换为ITE函数。
- Static Single Assignment Form中phi函数可以表示成
a3 = phi(a1, a2);表示a取两个分支的a1,a2定义。 - Gated Single Assignment Form可以表示成:
a3 = ITE(cond, a1, a2)。ITE(If-Then-Else)表示如果条件cond成立则取a1, 否则取a2
关于Gated Single Assignment专门有篇论文讲怎么去构造[1];作者并没有提到处理间接内存访问的细节。。。。
3.1.2 结构保留
作者提出最大共享图(Max-Shared-Graph)的程序结构。
int glob;
...
void f(int a) {
bool flop = false;
if (a < 0) {
a = -a;
flip = true
}
if (flip) {
assert (a != 0); // A
glob /= a;
}
}
对于如上代码,它生成的MSG如下:
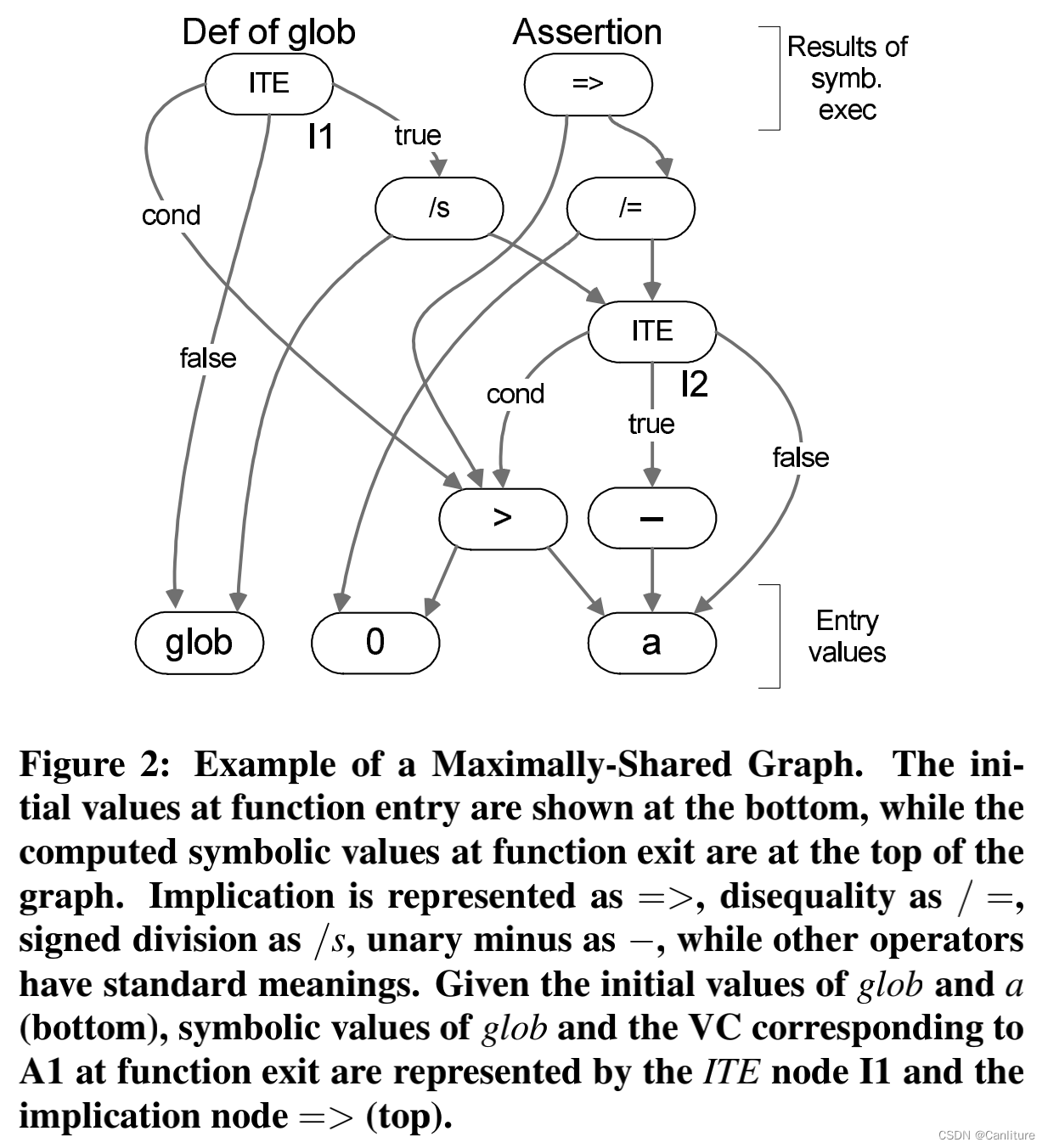
此图上紧凑地编码了切片,数据依赖和控制依赖。共享公共子表达,节约内存开销。关于如何构造,作者并没有给出具体的算法。。。。。
3.1.3 表达式化简与约束求解
在计算得到逻辑符号表达式之后,利用轻量级表达式化简器,简化反例,能够降低求解时的开销。作者也没有给出如何化简的算法。。。
之后是利用作者开发的Spear约束求解器去求解,作者开发的求解器赢得了SMT 2007竞赛的bit-vector算数分类的奖。作者有发表在CAV上的论文[2]专门讨论此求解器的设计,这里不详细讨论。。
4. 实验结果
实验配置
- 每个VC约束求解超时时间设置为10秒
- 每个函数生成VC数量设置为500个
- 每个函数的符号执行的超时时间设置为5000秒
- unsound (这几个决策都是漏报的主要原因)
- 循环/调用图 展开一层
- 单个函数某个asser报出违反,认为后面的代码是不可达的,也就不需要再进行求解/检查。
- 检查空指针解引用和用户提供的assert
实验环境
- 16GB内存
- 2.8GHz
测试集:
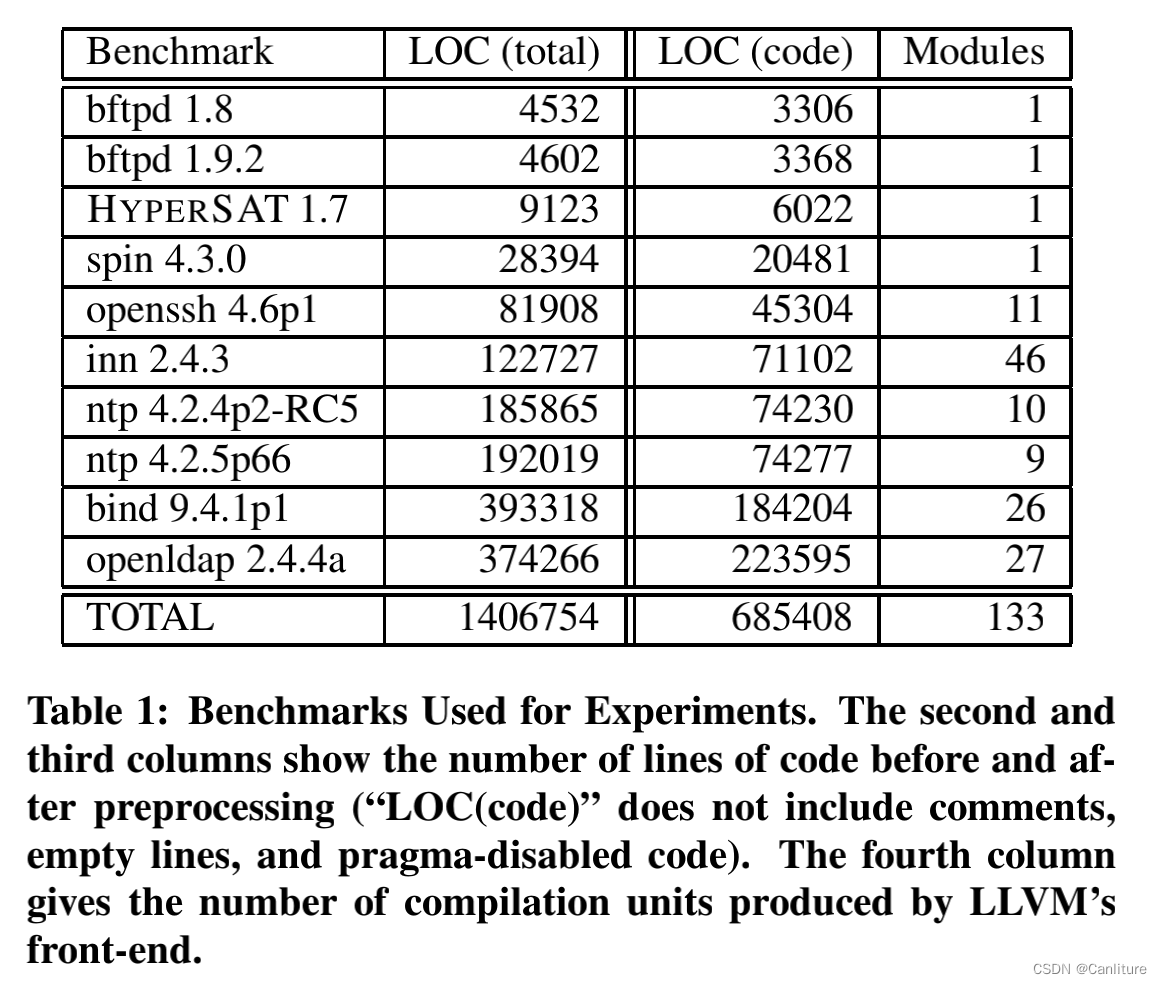
可以看到测试集中最大代码行为37w。
对比工具有:Saturn/CBMC。
下面是对比实验,可以看到作者的工具平均误报率在23% ,时间开销3秒~2个半小时。
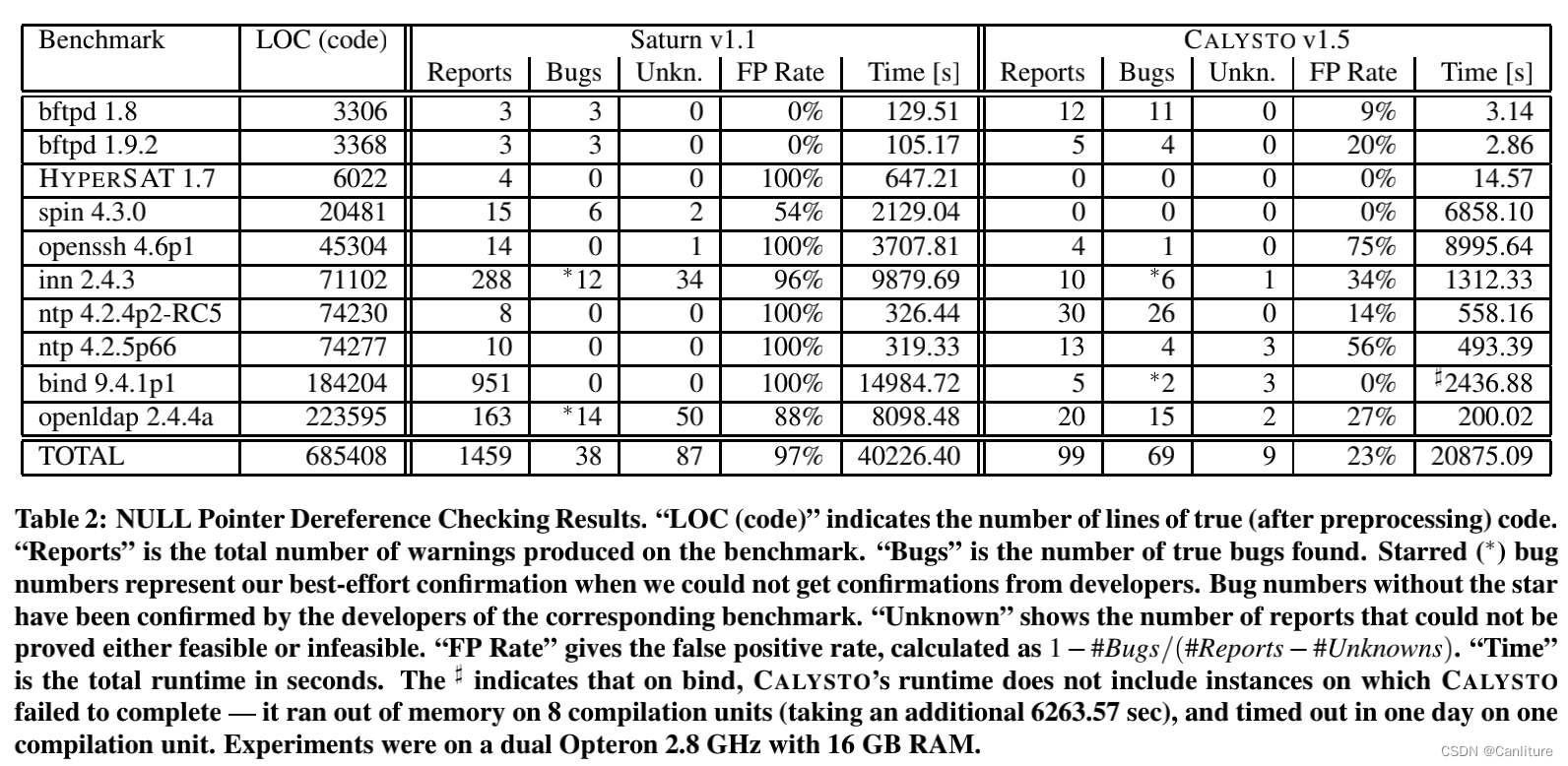
作者还特意将约束求解的时间单独作了统计。可以看到作者的工具话费了大约50%的时间去做约束求解。
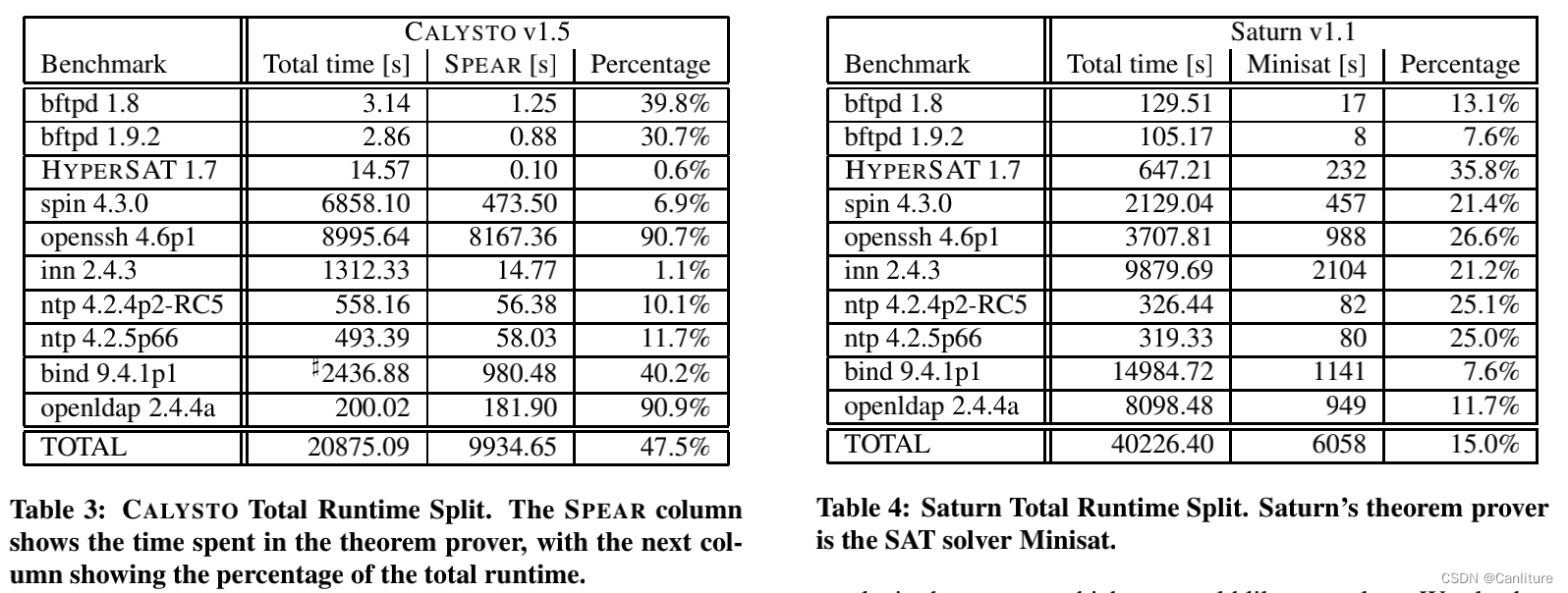
5. 总结
作者几乎没有给出任何算法细节,不过实验结果却看起来还行?其中的一些trade-off设计决策可参考。
[1] Peng Tu and David Padua. 1995. Efficient building and placing of gating functions. SIGPLAN Not. 30, 6 (June 1995), 47–55. https://doi.org/10.1145/223428.207115
[2] Babic, Domagoj & Hutter, Frank. (2008). Spear theorem prover.
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









