








这次读一读FSE‘03上发表的检查内存越界的paper。它是
路径敏感的,同时能够分析百万行规模的代码。作者分析了几个大的开源项目如OpenBSD, SendEmail, PostgreSQL, Linux内核,平均误报率低于35%。(其中在Linux内核报出的118个错误中,包括21个安全漏洞)
1. 简介
ARCHER (ARray CHeckER)工具的架构图如下:
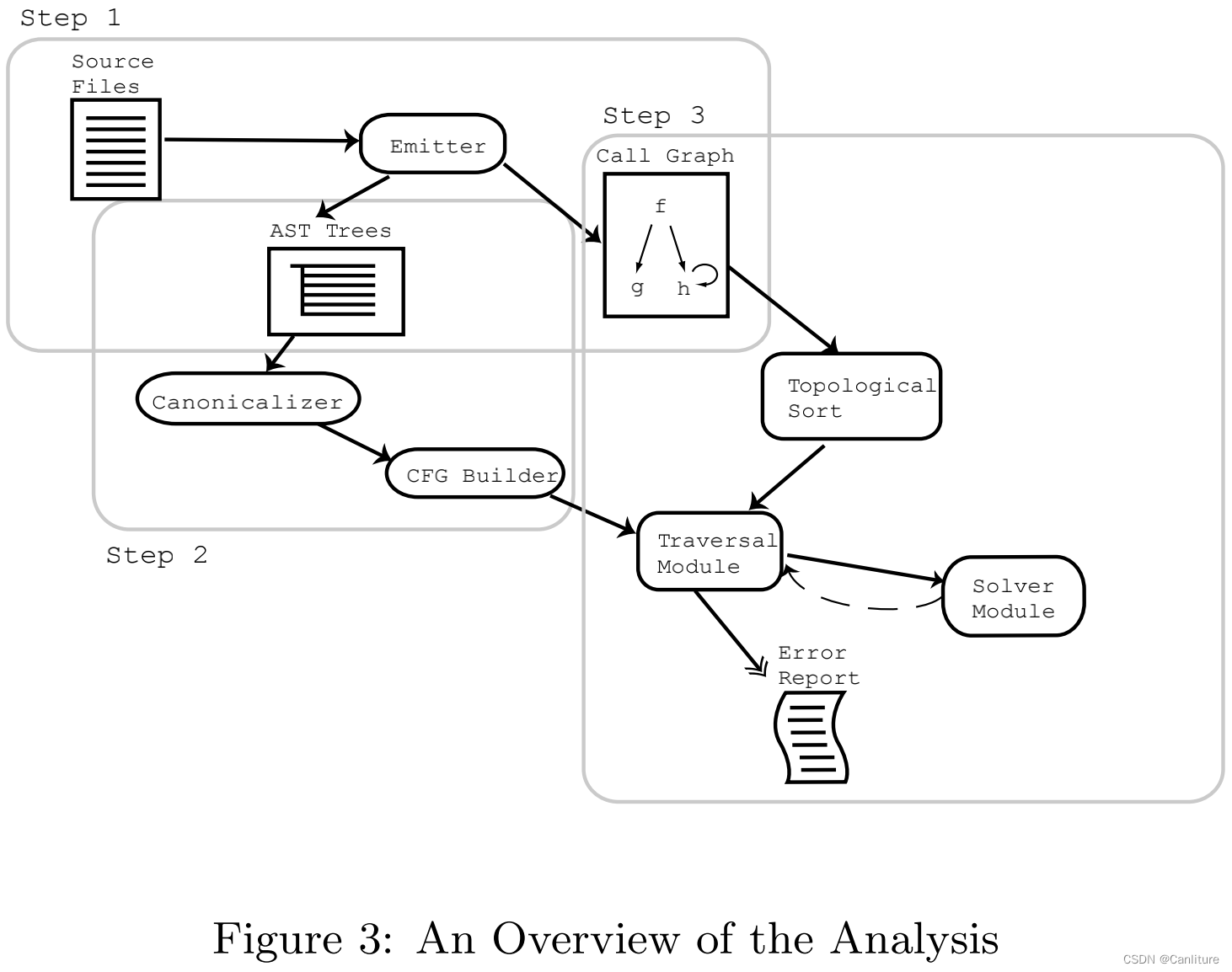
整个分析大体上分为3个步骤。
-
编译前端解析成AST
-
构建中间表示
- 转换成简化的AST
- 这种AST相对直接从Parser生成的AST更低级,
每条语句最多只能有一个副作用。相比低级IR,能够保存高层比较多的源码信息。- 副作用:函数调用,赋值等。
- 类似的编译前端有CIL[1], Mircrosoft AST toolkit[2]
- 这种AST相对直接从Parser生成的AST更低级,
- 构造CFG
- 生成调用图:不考虑函数指针;所以直接通过函数名来连接调用关系。
- 转换成简化的AST
-
遍历模块
- 沿着调用图自底向上,每次分析1个函数,在函数的cfg上穷举路径做符号执行。
- 每个函数设置
5秒的超时时间 - 递归调用,去除调用图上的回边
- 每个函数设置
- 根据语句类型执行作不同的行为
- 条件判断:调用求解器判断条件是否成立
- 如果确定不可行,那么可以剪枝掉不可行的路径。
- 否则,将当前条件分支加入到路径条件中。
- 内存访问
- 求解器求解,看是否内存访问越界。如果是,则报告违反。
- 其它语句
- 更新求解器的状态
- 条件判断:调用求解器判断条件是否成立
- 沿着调用图自底向上,每次分析1个函数,在函数的cfg上穷举路径做符号执行。
分析遍历模块主要的工作:沿调用图自底向上分析,每次分析完一个函数,构建一个摘要,叫做触发器摘要(trigger summary)。表示内存访问跟某些入参有关。
下面简单介绍一下trigger summary。
int arr[10];
void print(int);
void foo(int param) {
int m = param - 10;
print(arr[m]);
}
int main() {
int k = 10;
int t = 9;
foo(k); // A
foo(t); // B
}
在做符号执行时:
- 先分析foo
- 得到arr[m]数组访问索引m的符号值为
param - 10 - 则trigger summary为:
param - 10 < 0Vparam - 10 >= 10
- 得到arr[m]数组访问索引m的符号值为
- 分析main函数
- 调用点A处
k = 10
- 应用trigger summary
- 得到逻辑公式:
k = 10^k = param^(param - 10 < 0Vparam - 10 >= 0) - 交给约束求解器求解
不可满足
- 得到逻辑公式:
- 调用点B处
t = 9
- 应用trigger summary
t = 9^t = param^(param - 10 < 0Vparam - 10 >= 0)- 交给求解器求解
可满足,报告缺陷
- 调用点A处
基本思想比较简单。
2. 处理循环
按照上述符号执行穷举探索路径的方法,可能在处理循环时非常耗时,甚至不能终止。
下面代码在符号执行时需要迭代100次。
i = 100;
while (--i >= 0) {
// ... loop body
}
而如果针对如下代码,则无法终止,因为存在形参(未约束变量)。
void foo(int formal) {
while (--formal >= 0) {
// ... loop body
}
}
两种启发式方法(Unsound)解决这类问题:
第一种方法:循环展开一次
- 类似上文提到的 Calysto分析工具
- 循环分析一次后,在循环退出的时候,将在循环内部更新的变量的符号值替换为
未约束值
i = 0;
tmp = f(); /* tmp is unknown symbolic value */
while (tmp−−) {
i = i + 1;
}
/*
We invalidate the value of i here
Variable i is unknown symbolic value here
*/
第二种方法:对迭代循环结构进行特殊处理。
在Sound的分析中,循环不变式生成,我们之前的文章 Effective Chaotic Iteration Strategies With Widenings 提到,可以采用抽象解释中的widning技术加速收敛。
而在作者提出的bug finding工具中,unsound的处理逻辑可以这么做:给定如下代码
for (i = lb; i < ub; i++) {
/* loop body where i is not modified */
}
在代码中识别到这种迭代循环的特殊结构时,直接将变量i的范围设置为左闭右开区间[lb, ub)。然后循环处理一次即可。
3. 实验
实验环境
- Xeon 2.8GHz CPU
- 512MB内存
- 内存
只有512MB却能分析百万行代码规模,主要是利用了磁盘交换空间 + 一些Unsound决策。
- 内存
如下图所示,能够scale到百万行代码,平均误报率低于35%。
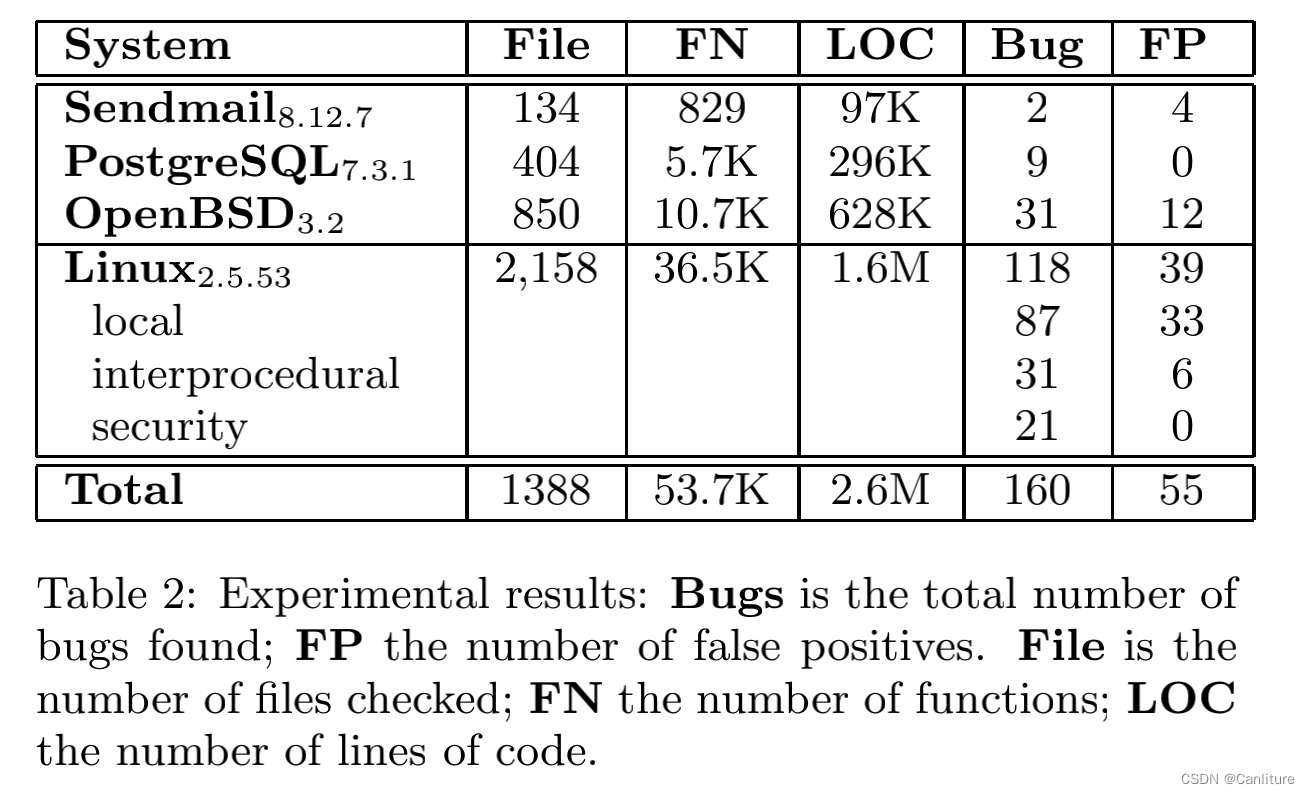
分析时间

4. 总结
实验结果看起来还不错,主要是资源开销比较小,还能够分析百万行代码规模(2003年)。至于文章后面的一些技术细节,这里没有展开,我只对前面的一些设计决策比较感兴趣。具体细节可以详细参考原文[3]。
5. 参考文献
[1] G.C. Necula, S. McPeak, S.P. Rahul, and W. Weimer. CIL: Intermediate language and tools for analysis and transformation of c programs. In International Conference on Compiler Construction, March 2002.
[2] Microsoft Corporation. AST Toolkit. http://research.microsoft.com/sbt/.
[3] Xie, Yichen et al. “ARCHER: using symbolic, path-sensitive analysis to detect memory access errors.” ESEC/FSE-11 (2003).



























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









