






自动化测试理解
文章目录
自动化测试分层
金字塔型从上到下:
UI自动化测试
集成测试
单元测试
什么项目适合自动化测试
- 项目变动少
- 项目周期足够
- 项目资源足够
- 产品型项目
- 能够自动编译自动发布的系统
- 回归测试
- 多次重复机械性动作
- 需要频繁运行的测试
适合自动化测试: 产品型项目: 功能是增量式开发, 回归测试的用例量很大, 存在大量重复的测试点
不适合自动化测试的项目: 定制版项目, 周期短, 业务复杂, 需求不稳定
自动化测试需要具备的能力
- 编码研发能力
- 熟悉被测试的系统
- 掌握自动化测试框架/工具
- 善于学习知其然, 知其所以然
- 逻辑思维能力
- 逆向思维能力
自动化测试引入的时机
项目中后期
- 回归测试
- 冒烟测试
- 每日线上巡检
- 构造测试数据
- 建立测试与代码的覆盖关系
自动化测试常用工具
接口/UI自动化测试框架
- Robot Framework
- Selenium
- Jmeter
- SoapUI
移动自动化测试框架
- Robotium
- Appium
- MonkeyRunner
- Monkey
自动化测试总结
-
持续提高生产效率/测试效率
通过最少的手工参与, 实现功能测试的自动化
复用和固化现有测试资产-测试用例, 测试需求, 原型
消除产品积压
-
增加/优化测试覆盖
优化回归测试
线上监控报警,持续监控预防bug
可视化质量版, 数据可视化, 帮助测试人员和开发人员向更好的方向发展
通过转向测试平台, 沉淀测试结果
-
测试自动化
引入只能方法, 自动根据代码或文档判断测试范围, 只能推送所需测试用例
通过API文档自动生成接口测试用例和代码
跨平台和生态系统上自动执行测试
Python自动化测试
Python是后续UI自动化测试, 接口自动化测试等课程阶段的语言基础
Python只是一个编程语言, 需要结合其他的工具使用
Python + selenium web 自动化(功能测试 转化为 代码)
Python + appium 移动端(手机端 APP) 自动化
Python + requests 接口
课程大纲
-
Python基础: 认识, PyCharm, 注释,变量, 变量类型. 输入输出, 运算符
-
流程控制结构: 判断语句, 循环语句
-
数据序列: 字符串, 列表, 元组, 字典
-
函数: 函数基础, 变量进阶, 函数进阶, 匿名函数
-
面向对象: 类, 对象, 继承, 封装, 多态, 类属性和类方法
-
异常, 模块, 文件操作
-
UnitTest框架: UnitTest基本使用, 断言; 参数化; 生成HTML测试报告
基于Selenium自动化测试所需要掌握的内容
自动化的目的: 框架搭建完成后, 不需要写什么代码, 只要添加测试用例就可以实现测试需求. 或者只需要一点脚本就能完成测试.
-
语言 Python: 装饰器, 反射, 日志, 数据库断言, 配置文件
-
设计模式: PO设计模式
-
用例管理: pytest
-
日志监控: logger
-
二次封装: selenium二次封装, yaml二次封装, excel, 数据库
-
测试报告; allure定制
-
ddt, parameterize
-
git, svn集成pycharm
-
持续集成, Jenkins
-
容器 : docker
课程内容
Day1 Python基础
1. Python 介绍
作者: 吉多·范罗苏姆
时间: 1989年
-
简单, 易学, 免费, 开源, 使用人群广泛
-
应用领域:
-
自动化测试,
-
网络爬虫
-
Web开发
-
自动化运维
-
数据分析
-
人工智能
-
机器学习
-
2. Python环境配置
Python 解释器: python代码转化为二进制可执行代码
pycharm: python 代码编辑IDE 工具
3. Pycharm 编写代码
print("hello world")
4. Python基础
注释
# 单行注释
'''
多行注释
'''
"""
多行注释
"""
- PEP8: 是Python 代码的书写规范, 不符合规范的会有灰色波浪线(不影响编译运行)
- 波浪线:
- 红色: 错误
- 灰色: 代码规范
- 绿色: 单词检查
变量类型: 可用type(变量名)查看变量类型
-
Number 数字
- int整形
- float浮点型
- bool
- complex
-
String 字符串
- 字符串表示
a = "abc" b = 'abc' c = '''abc''' d = """abc""" print(a, type(a)) print(b, type(b)) print(c, type(c)) print(d, type(d)) # ======================= ''' abc <class 'str'> abc <class 'str'> abc <class 'str'> abc <class 'str'> ''' # 单引号嵌套双引号, 是为了字符串中有双引号, 双引号嵌套单引号, 是为了字符串有单引号 t = '我说: "你是笨蛋"' # 三引号 的字符串可以换行 t1 = """ 我说: "你是笨蛋" 就这样 """ t2 = ''' 我说: "你是笨蛋" 就这样 ''' # =========================== ''' 我说: "你是笨蛋" 我说: "你是笨蛋" 就这样 我说: "你是笨蛋" 就这样 '''-
字符串格式化
-
print("a:%d, b: %s" % (a,b)) -
print("a:{}, b: {}".format(a,b) -
f-string:
print(f"a:{a}, b:{b}, a+b: {a+b}")a = 5 b = 3 print(f"a:{a}, b:{b}, a+b:{a+b}") # ============================= ''' a:5, b:3, a+b:8 '''
-
-
字符串输入:
input()输入的都是字符串 -
取下标:
a[0],a[-1],a[-2]分别是取第一个, 最后一个, 倒数第二个
-
序列类型
list: 列表, 可变序列, 支持切片, 下边元素,del s[i:j]更新删除操做, , 支持sort(),append(),clear(),copy(),extend(),s.insert(i, x),s.remove(x),s.pop(),s.reverse()tuple: 元组, 不可变序列; 元素的构建主要在于,而不是:range: 整数生成器, 生成的序列后也不可变bytes/bytearray: 字节序列
所有序列都可以支持通用序列操作:
in,not in,s+t,s*n,s[i],s[i:j],len,max,min,index,count -
映射类型: 字典
dict,dict.update(dict2), 将两个字典合并 -
集合类型: 不支持索引, 切片, 是无序的
set: 可变集合, 支持add(),remove()frozenset: 不可变集合
-
常用数据类型转换
注意字节序列转字符串 一定要用decode(), 直接使用str(字节变量) 会很不一样
int(a): 将a转变为整形
float(a): 将a转化为浮点型
str(a): 将变量a转化为字符串
eval(a): 将字符串转化为原始数据类型
注意: eval(str), 变量是字符串时, 会转化为去点双引号的字符串表示的变量
b = 123
a = input("输入: ")
a = eval(a)
print("变量a: {}, 类型: {}".format(a,type(a)))
# ==========================
'''
输入: b
变量a: 123, 类型: <class 'int'>
'''
变量命名: 有字母, 下划线, 数字组成, 且数字不能开头
命名规则: 驼峰命名法, 小驼峰, 大驼峰, 下划线法
切片操作:
切片是值对操作的集合对象截取其中一部分的操作, 字符串, 列表, 元组都支持切片操作
变量[起始:结束:步长] 区间左闭右开
a = "abcdefg"
# b = "abc", 左闭右开, 从0到2
b = a[0:3]
# c = "cdefg", 从i=2到最后
c = a[2:]
# d = "cdef", 从i=2到最后一位, 最后一位不取
d = a[2:-1]
# e = "fedcb", 步长负值, 从后往前取, 从i=5往前到i=0, 左闭右开, i=0不取
e = a[5:0:-1]
下划线:
- 前置的单下划线:_var
- 后置的单下划线:var_
- 前置的双下划线:__var
- 前后置的双下划线:var
- 单独的下划线:_
1. Single Leading Underscore: “_var”
下划线前缀一般约定是为了提示其他程序员,以单个下划线开头的变量或方法供内部使用。 在导入到其他模块中, 下划线前缀的变量, 方法不会导入(或者你显式的在__all__ 列表里定义)
2. Single Trailing Underscore: “var_”
当一个属性名恰好跟 Python 的关键字重名,为了直观,可以在属性名后加个_
>>> def make_object(name, class):
SyntaxError: "invalid syntax"
>>> def make_object(name, class_):
... pass
3.双下划线前缀:“__var”
此时 Python 解释器会重写属性名称垃圾避免子类中命名冲突,这就是所谓的 *mangling,*名字修饰,解释器以某种方式更改变量的名称,以使以后扩展类时更难产生冲突。
使用 Python 内置的函数 dir() 查看下 Test 类的属性。
>>> t = Test()
>>> dir(t)
['_Test__baz', '__class__', '__delattr__', '__dict__','__dir__',
'__doc__', '__eq__', '__format__', '__ge__', '__getattribute__',
'__gt__', '__hash__', '__init__', '__le__', '__lt__', '__module__',
'__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__',
'__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_bar', 'foo']
4. 前后双下划线
常用于 __init__, __call__,__iter__, __next__这些方法里,但是,通常我们自己的方法名最好不要用。
魔术方法:
Python中的魔术(双下划线’xxx’)方法详解 - ZhuGaochao - 博客园 (cnblogs.com)
__new__: 与__init__一同形成类的构造函数
__init__: 初始化
__del__: 在对象生命周期结束的时候会被调用
__getattr__(self, name): 获取类的私有属性.
__setattr__(self, name, value): 设置类的私有属性. 是一个封装的解决方案。无论属性是否存在,它都允许你定义对对属性的赋值行为,以为这你可以对属性的值进行个性定制; 避免无限递归
# 错误用法
def __setattr__(self, name, value):
self.name = value
# 每当属性被赋值的时候(如self.name = value), ``__setattr__()`` 会被调用,这样就造成了递归调用。
# 这意味这会调用 ``self.__setattr__('name', value)`` ,每次方法会调用自己。这样会造成程序崩溃。
# 正确用法
def __setattr__(self, name, value):
self.__dict__[name] = value # 给类中的属性名分配值
# 定制特有属性
__delattr__(self, name): 删除一个属性
____getattribute__(self, name): 定义了你的属性被访问时的行为,相比较,__getattr__只有该属性存在时才会起作用。因此,在支持__getattribute__的Python版本,调用__getattr__前必定会调用 __getattribute__。__getattribute__同样要避免"无限递归"的错误。需要提醒的是,最好不要尝试去实现__getattribute__,因为很少见到这种做法,而且很容易出bug。
5. Single Underscore: “_”
有时候函数返回值不止一个,但有些变量我们不需要,就可以使用 _ 来当个用不到的变量。
>>> for _ in range(32):
... print('Hello, World.')
输入输出
-
输出:
print("输出内容") # out: 输出内容 a = 1 # 格式化输出 print("变量a:%d" % a) # out: 变量a:1 name = lijiang age = 27 print("name: %s, age: %d" %(name, age)) # name: lijiang, age: 27 print("name: {}, age: {}".format(name, age)) # name: lijiang, age: 27 -
输入
input()输入的数据都是string# input("提示信息"), 提示信息也可以不写 a = input("请输入内容") print("变量a:%d" % a)
运算符
除:
12 / 3整除:
11 / 3取模:
11 % 3幂函数:
3 ** 4, 3的4次方
比较运算符:
==,!=,>=,<=
逻辑运算符同erlang:
and: 与
or: 或
not: 非
a = int(input("成绩: "))
if a >= 90:
print("优秀")
elif a >= 80:
print("良好")
elif a >= 70:
print("中等")
elif a >= 60:
print("及格")
else:
print("不及格")
# ===========================
'''
成绩: 85
良好
'''
循环语句
while
i = 0
while i < 10:
print("第{}次".format(i))
i += 1
print("循环结束")
# =======================
'''
第1次
第2次
第3次
第4次
第5次
第6次
第7次
第8次
第9次
第10次
循环结束
'''
- for遍历, 将可迭代集合对象中的元素传递给临时变量
list = [1,2,3,4,5]
for a in list:
print(a)
print("循环遍历结束")
# ========================
'''
1
2
3
4
5
循环遍历结束
'''
导包
import random
import random
a = random.choice([1,2,3])
print(a,type(a))
常见字符串操作函数
-
str.find(str1, start, end): 查找子串, 返回子串起始下标, 否则返回-1 -
str.index(str1, start, end): 查找子串, 返回子串起始下标, 如果不存在, 会报错 -
str.count(str1, start, end): 统计子串, 返回子串出现的次数, -
str.replace(str1, str2, count): 替换子串, 多次替换(count次数) -
str.split(str1, maxsplit): 切分字串, 且有最大切分长度, 返回一个字符串列表 -
str.capitalize(): 字符串首字符如果是字母大写, 其他字符不变 -
str.title(): 字符串每个单词第一个字符是字母则大写 -
str.startswith(str1): 是否以子串str1 开头, 返回 true|false -
str.endswith(str1): 是否以子串str1 结尾, 返回 true|false -
str.lower(): 所有字母字符小写 -
str.upper(): 所有字母字符大写 -
str.lstrip(): 删除左起的空白字符 -
str.rstrip(): 删除右起的空白字符 -
str.strip(): 删除两端的空白字符 -
str.isdigit(): 判断字符串是否只包含数字, 只能判断整数 -
str.join(str1): 在==str1== 每个元素后都加一个stra = "abcde" print(",".join(a)) # ================================ ''' a,b,c,d,e '''
列表操作
-
格式同 列表同erlang 列表, 可以存储不同类型
-
可以通过下标取元素 , 同golang切片
a[0],a[-1是取最后一个元素 -
使用for循环遍历, while 通过下边遍历
-
操作 增加元素
append增加元素, 将元素追加到末尾extend扩展一个列表到当前列表, 相当于erlang: List1 ++ List2insert(idx, data)将元素插入到指定位置
-
操作修改元素 , 根据下标修改元素
a[i] = "lijang" -
查找元素,
in:data in list, 元素是否在列表中not in:data not in list, 元素是否不在列表中index:list.index(data, start, end), 从start 位置到end 查找data, 找到返回下标count:list.count(data, start, end), 从start 位置到end 查找data元素个数
index和count操作同string的index,count相同 -
删除元素操作
del:del list[index], 直接删除列表中下标位置的元素, 如果下标越界,会报错pop:list.pop(index), 将指定位置元素出列, 返回这个元素, 如果没有index参数, 出列最后一个元素, 如果下标越界,会报错remove:list.remove(data), 将元素data从列表中删除, 如果值不存在会报错
-
排序
-
sort:list.sort(), 从小到大排序;list.sort(reverse=True), 从大到小倒叙排列, 必须要保证列表中元素类型一致, 否则会报错, 如果列表中的元素也是一个列表, 则会比较列表的首个元素 -
reverse:list.reverse(), 直接将列表转置
-
元组操作
- 格式:
a=('hello', 223, 321) - 元组的元素不能被修改
- 下标取元素
- for 循环遍历元组元素
count,index: 操作同string, list的count,index操作- 组包
c = a,b, 拆包a,b = c
map(字典)操作
-
格式:
std = {'name':"lijiang", 'id'=26, 'gender'='male'} -
取元素:
std['name'], 键不存在, 会报错 -
取元素:
std.get('name'), 如果键不存在, 返回None -
字典的顺序一般是乱序的, py3.7版本后每个字典定义后打印顺序都是一样的
-
增加或者修改元素:
std['age']=27,std['addr']="wuhan" -
删除元素:
del std['age'] -
删除整个字典:
del std -
清空字段:
std.clear() -
常见操作:
-
len(map): 获取字典大小 -
map.keys(): 获取字典的keys列表 -
map.values(): 获取字典的values列表 -
map.items(): 将字典转化为K-V元组(k,v)的列表形式std = {'name':"lijiang", 'id':26, 'gender':'male'} print(std.items()) #============================== ''' dict_items([('name', 'lijiang'), ('id', 26), ('gender', 'male')]) '''
-
-
字典的遍历
-
遍历字典的key
std = {'name':"lijiang", 'id':26, 'gender':'male'} for key in std.keys(): print(key) -
遍历字典的value
std = {'name':"lijiang", 'id':26, 'gender':'male'} for key in std.values(): print(key) -
遍历字典的项
std = {'name':"lijiang", 'id':26, 'gender':'male'} for i in std.items(): print(i)
-
函数
def funcname():
Exec...
def f1():
print("==================")
print("this is a function!")
print("==================")
def add(a, b):
return a+b
c = add(a, b)
# 函数调用参数可以通过赋值的形式不按顺序放入
print(add(b=10, a=5))
# ====out: 15========
5. Python进阶
面向对象
# class Student: # 经典类定义形式
# class Student(): #新式类定义形式
class Student(object):
def __init__(self, name, age):
self.name = name
self.age = age
def study(self):
print(f"{self.name}可以学习")
def school(self):
print(f"{self.name}可以去学校")
s1 = Student("lijiang", 25)
print(id(s1))
s1.study()
s1.school()
print(s1.name)
#============================
'''
2484973424592
lijiang可以学习
lijiang可以去学校
lijiang
'''
注意:
- object类是所有类的顶级父类
- 类名的命名规则: 大驼峰命名
- 示例方法第一个参数一般是
self, 在类的内部可以通过self 获取属性和示例方法
说明:
- 通过一个类, 可以创建多个对象
__init__(self)中, 默认有1个参数为self, 如果创建对象需要其他参数, 就在init中传入, 初始化对象属性__new__: 创建对象时会调用的方法, 用于创建对象, 并返回对象, 当对象返回时会自动调用__init__方法; 一定要有一个参数__new__(cls)
类自带方法
__str__(): 打印对象属性__del__(): 对象删除时会调用的方法
class Student(object):
def __init__(self, name, age):
self.name = name
self.age = age
def __del__(self):
print("student over")
def study(self):
print(f"{self.name}可以学习")
def school(self):
print(f"{self.name}可以去学校")
s1 = Student("lijiang", 25)
print(id(s1))
s1.study()
s1.school()
print(s1.name)
del s1
# =============================
'''
2572892655568
lijiang可以学习
lijiang可以去学校
lijiang
student over
'''
对象继承
class Person(object):
def __init__(self, name, age):
self.name=name
self.age=age
def grow(self):
self.age+=1
print(f"{self.name} can grow up, age:{self.age}")
class Family(object):
def __init__(self, firstName):
self.firstName=firstName
def grow(self):
self.age+=1
print(f"{self.firstName} happy a year")
class Student(Family, Person):
def __init__(self, name, age, firstName):
self.name=name
self.age=age
self.firstName=firstName
pass
p1 = Person("lijiang", 27)
s1 = Student("lijiang1", 10, "li")
s1.grow()
#=============================
'''
li happy a year
'''
#=============================
class Person(object):
def __init__(self, name, age):
self.name=name
self.age=age
def grow(self):
self.age+=1
print(f"{self.name} can grow up, age:{self.age}")
class Family(object):
def __init__(self, firstName):
self.firstName=firstName
def grow(self):
self.age+=1
print(f"{self.firstName} happy a year")
class Student(Person, Family):
def __init__(self, name, age, firstName):
self.name=name
self.age=age
self.firstName=firstName
pass
p1 = Person("lijiang", 27)
s1 = Student("lijiang1", 10, "li")
s1.grow()
#=============================
'''
lijiang1 can grow up, age:11
'''
#=============================
说明:
-
多继承, 多个父类同名方法, 且子类未重写, 执行首个有同名方法的继承的父类中的方法
-
类中的属性和方法不导出, 在属性名前加下划线
Family._firstName=firstName -
只有一个继承时, 可以用
super.grow()调用父类方法 -
子类条用父类方法
Person.grow(self)
文件操作
- 打开文件操作:
f=open("路径\文件名", "w")第二个参数是文件打开的模式
| 访问模式 | 说明 |
|---|---|
| r | 只读方式, 指针放在文件开头, 这是默认方式 |
| w | 写文件方式, 文件不存在, 创建新文件 |
| a | 最佳方式, 指针于文件末尾, 文件不存在创建新文件 |
| wb | 二进制写入 |
| ab | 二进制追加 |
| r+ | 读写模式, 指针在文件开头, 不存在不会创建 |
| w+ | 读写模式, 文件存在, 写入时覆盖; 文件不存在, 创建新文件 |
- 关闭文件:
f.close() - 打开文件后读取文件:
f.read(), 读取整个文件 - 读取一行数据:
f.readline() - 读取多行数据:
f.readlines(), 每行数据存入一个列表 - 写数据:
f.write(content)
复制文件操作
filename = input("请输入要复制的文件:")
sufNum = filename.rfind(".")
newFile = filename[:sufNum]+"-副本"+filename[sufNum:]
# 二进制方式打开文件
oldf = open(filename, "rb")
newf = open(newFile, "wb")
for temp in oldf.readlines():
newf.write(temp)
oldf.close()
newf.close()
其他文件操作: os模块
- 文件重命名:
os.rename(oldname, newname) - 删除文件:
os.remove(filename) - 创建文件夹:
os.mkdir(filepath) - 获取当前文件夹:
os.getcwd() - 改变默认目录:
os.chdir(otherpath):os.chdir("../") - 获取目录列表:
os.listdir("./") - 删除文件夹:
os.rmdir(path)
异常处理
try ... except ... else ... finally...
import fileinput
import time
fname = input("请输入一个文件名: ")
try:
file = open(fname, "r")
try:
while True:
content = file.readline()
if len(content) == 0:
break
time.sleep(1)
print(content)
except Exception as e:
# 如果读取文件过程中, 产生了异常会被捕获到
print("读取文件捕获异常", e)
finally:
file.close()
print("文件关闭")
except Exception as e:
# 未捕获到异常的处理
print("打开文件捕获异常", e)
print("over")
Exception as 变量名 起别名
else
finally
模块和包
from 包名 import 模块名
__name__: 记录的是当前运行的模块
python的每个包下会有一个__init__.py的文件, 新建包会生成一个__init__.py的空文件
在包下的__init__.py 文件中 加入__all_ = ["模块1", "模块2"], 在需要导入模块的地方就可以from 包名 import *, 也可以使用from 包名.模块名 import *; 但是不建议 import * , 一般使用from 包名.模块名 import 模块1,模块2
如果from 包名 import 模块名 as 别名: 如果模块名重复, 可以使用别名
反射
python的反射机制,核心就是利用字符串的形式去对象(模块)中操作(查找/获取/删除/添加)成员,一种基于字符串的事件驱动!
面向对象的属性方法:
hasattr(object,'attrName'):判断该对象是否有指定名字的属性或方法,返回值是bool类型
setattr(object,'attrName',value):给指定的对象添加属性以及属性值
getattr(object,'attrName'):获取对象指定名称的属性或方法,返回值是str类型
delattr(object,'attrName'):删除对象指定名称的属性或方法值,无返回值注:
getattr,hasattr,setattr,delattr对模块的修改都在内存中进行,并不会影响文件中真实内容。
python中访问类或对象的成员有三种方法:
如下所示 obj 为对象 var为变量 func为函数
1、obj.var 或 obj.func()
2、obj.__dict__['var']
3、getattr(obj,'var')
反射当前模块
还可以导入其他模块,利用反射查找该模块是否存在某种方法.
import sys
def s1():
print('s1')
def s2():
print ('s2')
this_module = sys.modules['__main__'] #__main__表示当前文件
print(hasattr(this_module, 's1')) #判断's1'是否在当前文件的方法名中
getattr(this_module, 's2')() #取出
import和__import__()
import作用:
导入/引入一个python标准模块,其中包括.py文件、带有init.py文件的目录;
__import__作用:
同import语句同样的功能,但__import__是一个函数,并且只接收字符串作为参数
- 函数功能用于动态的导入模块,主要用于反射或者延迟加载模块。
__import__(module)相当于import module__import__(package.module)相当于from package import name,如果fromlist不传入值,则返回package对应的模块,如果fromlist传入值,则返回package.module对应的模块。
我动态输入一个模块名,可以随时访问到导入模块中的方法或者变量.
imp = input("请输入模块:")
dd = __import__(imp)# 等价于import imp
inp_func = input("请输入要执行的函数:")
f = getattr(dd,inp_func,None)
#作用:从导入模块中找到你需要调用的函数inp_func,然后返回一个该函数的引用.没有找到就烦会None
f() # 执行该函数
上面还存在一点点小问题:那就是我的模块名有可能不是在本级目录中存放着
dd = __import__("lib.text.commons") #这样仅仅导入了lib模块
dd = __import__("lib.text.commons",fromlist = True) #改用这种方式就能导入成功
# 等价于import config
inp_func = input("请输入要执行的函数:")
f = getattr(dd,inp_func)
f()
装饰器
作用:装饰器的本质是一个python函数,它可以在不改动其他函数的前提下,对函数的功能进行扩充。
装饰器用于以下场景:引入日志、函数执行时间统计、执行函数后清理功能、权限校验、缓存
装饰器特点:
- 接受函数,并返回函数的函数
- 是一个函数,参数是函数,返回值是函数
"""
装饰器函数格式:
def deco_name(func): # func参数是固定的
def func_name(参数):
pass
return func_name
@deco_name
def func_name(参数):
pass
"""
def test1(func):
def test2(root,key):
if root == "root" and key ==123:
print("您的用户名和密码输入正确")
else:
print("您的用户名或密码输入错误")
return test2
@test1
def test3(root,key):
pass
test3("root",1234)
使用装饰器:
def logs(func): #装饰器
def f(*args,**kwargs):
print(level,datetime.datetime.now(),func.__name__,"开始调用了")
func(*args,**kwargs) #转发参数
print(level,datetime.datetime.now(),func.__name__,"调用结束了")
return f
@logs
def add():
print("add is calling")
等同于
add=logs(add)
装饰器接受参数:
import datetime
def logs(level):
def _logs(func): #装饰器
def f(*args,**kwargs):
print(level,datetime.datetime.now(),func.__name__,"开始调用了")
func(*args,**kwargs) #转发参数
print(level,datetime.datetime.now(),func.__name__,"调用结束了")
return f
return _logs
@logs(level="INFO") #装饰器的使用 logs接收参数 才能完成调用 返回一个返回值
def add(x,y): #被装饰函数
print("add is calling:",f"{x=},{y=}")
def sub(x,y): #被装饰函数
print("sub is calling:",f"{x=},{y=}")
#装饰的过程:被装饰的函数作为参数,传递给装饰器,并且将返回值覆盖原来的函数
#add=logs(add)
if __name__ == '__main__':
add(x=1, y=2)
sub = logs(level="DEBUG")(sub)
sub(x=11, y=22)
"""
INFO 2023-07-25 11:59:04.440378 add 开始调用了
add is calling: x=1,y=2
INFO 2023-07-25 11:59:04.441375 add 调用结束了
DEBUG 2023-07-25 11:59:04.441375 sub 开始调用了
sub is calling: x=11,y=22
DEBUG 2023-07-25 11:59:04.441375 sub 调用结束了
"""
生成器 与 迭代器:
生成器[yield, range]关键字,属于迭代器:交给for循环进行使用
迭代器[iter()函数生成]: for循环是为了迭代器服务的
如果函数中有yield关键字,其调用结果,则返回一个生成器; 生成器是一个可迭代对象,可以被for循环遍历使用
range 就是一个生成器, 在遍历时才执行,并计算返回值
def add(a, b):
c = a + b
print(c)
yield 123
return c
if __name__ == '__main__':
c = add(1, 2)
print(c) # c是生成器
for i in c: # 生成器:在使用数据时,才产生数据
print(f"{i=}")
l = [1, 2, 3]
iter_l = iter(l) # 为列表创建迭代器
for i in iter_l: # for循环是为了迭代器服务的
print(i)
for i in l:
print(i)
"""
<generator object add at 0x000001ECAF650EB0>
3
i=123
1
2
3
1
2
3
"""
迭代器, 生成器相关面试题
什么是可迭代对象, 迭代器, 生成器?
如果一个对象拥有
__iter__方法, 那么这个对象就是可迭代对象; 如果一个对象拥有__iter__和__next__方法, 那么这个对象就是迭代器;生成器是一种特殊的迭代器, 自动实现了
__iter__和__next__方法;具有
yield关键字的函数就是生成器; yield可以理解为return,返回后面的值给调用者。不同的是return返回后,函数会释放,而生成器则不会。在直接调用next方法或用for语句进行下一次迭代时,生成器会从yield下一句开始执行,直至遇到下一个yield.
手写一个函数代替range
def my_range(start, end=None, step=None):
if end == None and step == None: # 说明只有start接收到了参数
start, end = end, start # start和end互换
if start is None:
start = 0
if end is None:
end = 0
if step is None:
step = 1
if step == 0:
return
while True:
if step > 0 and start >= end:
break
elif step < 0 and start <= end:
break
yield start
start += step
if __name__ == '__main__':
print("*" * 10)
for i in my_range(5, 0, 1):
print(i)
print("*" * 10)
for i in my_range(5):
print(i)
print("*" * 10)
for i in my_range(5, 10):
print(i)
print("*" * 10)
for i in my_range(1, 10, 2):
print(i)
Day2 UnitTest框架
0. 介绍
UnitTest框架: UnitTest是Python自带的一个==单元测试==的框架, 用它来做单元测试
pytest框架是第三方框架, 需要先安装再使用
单元测试框架: 主要做单元测试, 一般是开发
测试人员:
UnitTest框架的作用是自动化脚本(用例代码)执行框架 (使用UnitTest框架来管理运行多个测试用例的)
为什么使用UnitTest框架
- 能够组织多个用例去执行
- 提供丰富的断言方法(让程序代码代替人工自动判断预期结果与实际结果是否相符)
- 能够生成测试报告
**UnitTest的核心要素: **
TestCase(核心模块):UnitTest框架的组成部分, 每个TestCase都是一个代码文件, 在这个代码文件中 来 书写真正的用例代码, 用类的方式, 组织对一个功能的多项测试Fixture(测试夹具): 写在TestCase中, 是一种代码结构, 可以在每个方法执行前后都会执行的内容(前置代码, 后置代码), 夹具, 用来固定测试环境TestSuite(测试套件): 用来管理组装 (打包)多个TestCase(用例代码)的TestRunner(测试执行): 执行TestSuite测试套件的, 可以导出测试结果TestLoader(测试加载): 加载管理 组装(打包)多个TestCase(测试用例)的, 根据某一规则找到TestSuiteTestResult(测试结果): 测试报告
1. UnitTest 基本使用
三个步骤:
- 创建测试类: 需要继承
unittest.TestCase - 书写测试方法: 需要以
test开头的示例方法, 且不能有参数 - 执行测试(在pycharm中可以省略)
import unittest
class TestOne(unittest.TestCase):
def test01(self):
print("这是test_01")
def test02(self):
print("这是test_02")
if __name__ == '__main__' :
unittest.main()
#======================================
'''
Testing started at 22:34 ...
Launching unittests with arguments python -m unittest E:\PythonStudyFolder\unitcode\test_unit01.py in E:\PythonStudyFolder\unitcode
这是test_01
这是test_02
Ran 2 tests in 0.025s
OK
'''
2. 断言
Python断言
-
用法
-
assert逻辑表达式
-
assert逻辑表达式, 字符串
-
-
说明
如果逻辑表达式为真, 则继续执行
如果逻辑为假, 则抛出
AssertionError, 并包含字符串信息
UnitTest断言
| 方法 | 检查 | 描述 |
|---|---|---|
| 判断相等 | ||
assertEqual(a, b) | a == b | 验证a是否等于b |
assertNotEqual(a, b) | a != b | 验证a是否不等于b |
assertTrue(x) | bool(x) is True | 验证x是否为ture |
assertFalse(x) | bool(x) is False | 验证x是否为flase |
assertIs(a, b) | a is b | 验证a,b是否为同一个对象 |
assertIsNot(a, b) | a is not b | 验证a,b不是同一个对象 |
assertIsNone(x) | x is None | 验证x是否是None |
assertIsNotNone(x) | x is not None | 验证x是否非None |
| 判断in | ||
assertIn(a, b) | a in b | 验证a是否是b的子串 |
assertNotIn(a, b) | a not in b | 验证a是否非b的子串 |
| 判断类型 | ||
assertIsInstance(a, b) | isinstance(a, b) | 验证a是否是b的实例 |
assertNotIsInstance(a, b) | not isinstance(a, b) | 验证a是否不是b的实例 |
| 判断容器内容是否一致 | ||
assertListEqual(a,b) | 验证a,b列表是否一致 | |
assertTupleEqual(a,b) | 验证a,b元组是否一致 | |
assertSetEqual(a,b) | 验证a,b集合是否一致 | |
assertDictEqual(a,b) | 验证a,b字典是否一致 | |
| 判断小数是否相等 | ||
assertAlmostEqual(a,b) | 验证a,b小数是否近似相等 | |
assertNotAlmostEqual(a,b) | 验证a,b小数是否非近似相等 | |
| 判断大小关系 | ||
assertGreater(a,b) | a>b | 验证是否a大于b |
assertGreaterEqual(a,b) | a>=b | 验证是否a大于等于b |
assertLess(a,b) | a<b | 验证a,b集合是否一致 |
assertLessEqual(a,b) | a<=b | 验证a,b字典是否一致 |
import unittest
class TestOne(unittest.TestCase):
def test01(self):
print("这是test_01")
response = "测试数据成功"
self.assertIn("成功", response)
def test02(self):
print("这是test_02")
if __name__ == '__main__' :
unittest.main()
3. 子测试subtest
可以用来执行多个相似的测试(参数不同), 并得到多次测试结果
官方例子
class NumberTest(unittest.TestCase):
def test_even(self):
"""
Test that numbers between 0 and 5 rae all even
"""
for i in range(0,6):
with self.subTest(i=i):
self.assertEqual(i%2, 0)
4. fixture测试夹具
夹具: 通过固定环境, 来确保测试正常, 想想一个钳子固定物品, 对其加工
说明:
setUp前置方法: 测试环境初始化
tearDown后置方法: 资源回收, 收尾工作
- 如果
setUp执行有异常, 则测试代码 和tearDown也不会执行 - 如果
setUp执行成功, 不管测试 代码是否有异常,tearDown都会执行 - 模块级 > 类级 > 实例级
模块级:
def setUpModule():
print("setUpModule done")
def tearDownModule():
print("tearDownModule done")
类级别
class TestOne(unittest.TestCase):
@classmethod
def setUpClass(self):
print("setUpClass done")
@classmethod
def tearDownClass(self):
print("tearDownClass done")
实例级别
class TestOne(unittest.TestCase):
def setUp(self) -> None:
print("setUp done")
def tearDown(self) -> None:
print("tearDown done")
例子:
import unittest
def setUpModule():
print("setUpModule done")
def tearDownModule():
print("tearDownModule done")
class TestOne(unittest.TestCase):
@classmethod
def setUpClass(self):
print("setUpClass done")
@classmethod
def tearDownClass(self):
print("tearDownClass done")
def setUp(self) -> None:
print("setUp done")
def tearDown(self) -> None:
print("tearDown done")
def test01(self):
print("这是test_01")
response = "测试数据成功"
self.assertIn("成功", response)
def test02(self):
print("这是test_02")
if __name__ == '__main__' :
unittest.main()
# ===========================================
'''
setUpModule done
setUpClass done
setUp done
这是test_01
tearDown done
Ran 2 tests in 0.006s
OK
setUp done
这是test_02
tearDown done
tearDownClass done
tearDownModule done
'''
5. testSuite测试套件
作用: 用来自己组织待测试的内容和顺序
方法:
-
创建
TestSuite对象,suite = unittest.TestSuite() -
添加测试内容
suite.addTest()\suite.addTests()-
添加某个测试类的单个方法
suite.addTest(SomeTestCase("someTestMethod")) -
添加某个测试类多个方法
多次使用上边的方法: 略
通过内置的map函数做到
suite.addTests(map(SomeTestCase, ["someTestMethod1", "someTestMethod2", ...])) -
添加测试类的所有测试方法
from unittest.loader import makeSuite suite.addTest(makeSuite(someTestCase)) -
添加其他的
TestSuite对象:suite.addTest(otherSuite)
-
-
运行(一般会结合
TestLoader使用) (此时未用到)result = unittest.TestResult() suite.run(result)
import unittest
from unittest import TextTestRunner
from test_unit01 import TestOne
from unittest.loader import makeSuite
suite = unittest.TestSuite()
# suite.addTest(TestOne("test01"))
# suite.addTests(map(TestOne,["test01", "test02"]))
suite.addTest(makeSuite(TestOne))
runner = TextTestRunner()
runner.run(suite)
6. TestLoader
可以看作是通过指定规则, 快速找到所有的测试用例(即一个TestSuite)
-
常用代码
test_dir = "./" # 找到当前目录下的, 所有以test_开头的, .py结尾的文件, 并组织成一个TestSuite suite = unittest.defaultTestLoader.discover(test_dir, pattern='test_*.py') # 执行TestSuite runner = TextTestRunner() runner.run(suite)
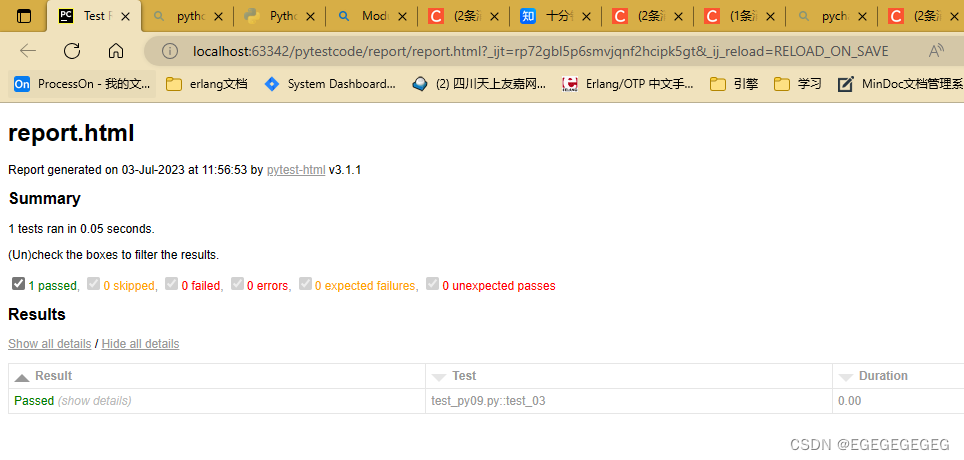
7. 测试报告生成
生成测试结果有多种方式:
-
txt格式的结果: 创建TextTestRunner时指定参数 -
pycharm导出html结果: 使用pycharm执行完成后 通过图标 导出html测试结果 -
通过安装扩展生成HTML报告
-
安装
pip install html-testRunner -
使用 执行测试, 并生成报告
import HtmlTestRunner runner = HtmlTestRunner.runner.HTMLTestRunner() runner.run(suite) -
报告的查看, 报告默认放在当前目录的
reports目录下
-
Day3 pytest框架
0. 介绍
pytest是python的一种单元测试框架, 且自带的unittest测试框架类似, 相比于unittest框架使用起来更简洁, 更高效
特点:
-
非常容易上手, 入门简单, 文档丰富, 有很多实例可以参考
-
支持简单的单元测试和复杂的功能测试
-
支持参数化
-
执行测试过程中可以将某些测试跳过, 或者对某些预期失败的Case标记成失败
-
支持重复执行失败的case
-
支持运行有Nose, unittest编写的测试case
-
具有很多第三方插件, 并且可以自定义扩展
-
方便的 和持续集成工具 集成
安装: pip install -U pytest
1. pytest基本使用
import pytest
def test_a():
print("test_a doing")
return 1 + 0
def test_b():
print("test_b doing")
return 1 / 0
if __name__ == '__main__':
# test_a()
# test_b()
pytest.main()
运行方式:
- 直接运行代码
'''
============================= test session starts =============================
collecting ... collected 2 items
test_py01.py::test_a PASSED [ 50%]test_a doing
test_py01.py::test_b FAILED [100%]test_b doing
test_py01.py:7 (test_b)
def test_b():
print("test_b doing")
> return 1 / 0
E ZeroDivisionError: division by zero
test_py01.py:10: ZeroDivisionError
=================== 1 failed, 1 passed, 1 warning in 0.14s ====================
'''
- 控制台
pytest,pytest会执行当前目录下所有测试文件, 可以在后边添加文件名, 来限制只执行此脚本(用例)
'''
===================== test session starts ====================
platform win32 -- Python 3.9.6, pytest-7.4.0, pluggy-1.2.0
rootdir: E:\PythonStudyFolder\pytestcode
collected 2 items
test_py01.py .F [100%]
====================== FAILURES =====================
_________________test_b ________________________
def test_b():
print("test_b doing")
> return 1 / 0
E ZeroDivisionError: division by zero
test_py01.py:10: ZeroDivisionError
------------------ Captured stdout call ---------------
test_b doing
====================== warnings summary =======================
test_py01.py::test_a
e:\javastudyfolder\zz-python\lib\site-packages\_pytest\python.py:198: PytestReturnNotNoneWarning: Expected None, but test_py01.py::test_a returned 1, wh
ich will be an error in a future version of pytest. Did you mean to use `assert` instead of `return`?
warnings.warn(
-- Docs: https://docs.pytest.org/en/stable/how-to/capture-warnings.html
======================= short test summary info =================
FAILED test_py01.py::test_b - ZeroDivisionError: division by zero
==================== 1 failed, 1 passed, 1 warning in 0.11s ===========
'''
2. pytest 配置
默认规则:
- 模块:
test_*.py或者*_test.py的文件 - 类: 以上模块中 以
Test开头的类, 且没有初始化__init__方法 - 函数及方法: 以上模块, 类中, test开头的函数或者方法
- 其他, 也会执行
unittest定义的测试用例类
自定义规则: 可以通过配置文件进行指定
配置文件: 在运行pytest的时候, 会自动在所在目录中的配置
- 例子
[pytest]
; ini文件中的 英文分号后边的内容是注释
addopts = -s ; 选项 通常是- 或者 -- 开头内容
testpaths = ./scripts ; 测试模块所在目录
python_files = test_*.py *test.py ; 测试模块文件名称规则 多个内容用空格分割
python_classes = Test_* ; 测试类名称规则
python_function = test_* ; 测试函数 或 方法的名称规则
addopts 参数:
-s:表示输出调试信息,用于显示测试函数中print()打印的信息
-v:未加前只打印模块名,加v后打印类名、模块名、方法名,显示更详细的信息
-q:表示只显示整体测试结果
-vs:这两个参数可以一起使用
-n:支持多线程或者分布式运行测试用例(前提需安装:pytest-xdist插件)
–html:生成html的测试报告(前提需安装:pytest-html插件) 如:pytest -vs --html ./reports/result.html
3. pytest 断言
assert + 判断式
4. 标记功能 mark
标记跳过测试: @pytest.mark.skip(reason="跳过这个错误")
标记预期失败: @pytest.mark.xfail(reason="预期失败")
import pytest
def test_a():
print("test_a doing")
return 1 + 1
@pytest.mark.skip(reason="跳过这个错误")
def test_b():
print("test_b doing")
return 1 / 0
@pytest.mark.xfail(reason="预期失败")
def test_c():
print("test_c doing")
return 1 / 0
if __name__ == '__main__':
pytest.main()
'''
============================= test session starts =============================
collecting ... collected 3 items
test_py05.py::test_a test_a doing
PASSED
test_py05.py::test_b SKIPPED (跳过这个错误)
Skipped: 跳过这个错误
test_py05.py::test_c test_c doing
XFAIL (预期失败)
@pytest.mark.xfail(reason="预期失败")
def test_c():
print("test_c doing")
> return 1/0
E ZeroDivisionError: division by zero
test_py05.py:15: ZeroDivisionError
============= 1 passed, 1 skipped, 1 xfailed, 1 warning in 0.11s ==============
'''
5. 参数化
作用: 对相似的过程, 数据不一样的时候, 可以使用参数化
API: parametrize(self, argnames, argvalues, ids=None), 参数名称, 列表或者元组; 参数值: 元素为元组的列表, 每一个元组都是一组参数.
例子:
import pytest
#运行了三组数据
# @pytest.mark.parametrize('a', [99, 98, 97])
# @pytest.mark.parametrize('a,b', [99, 2], [1, 2], [99, 1])
# @pytest.mark.parametrize('a,b', [99, 2], [1, 2], [99, 1])
@pytest.mark.parametrize(["a", "b"], [(99, 2), (1, 2), (99, 1)])
def test_a(a, b):
print("test_a doing")
assert a + b > 100
if __name__ == '__main__':
pytest.main()
# =====================================
'''
============================= test session starts =============================
collecting ... collected 3 items
test_py06.py::test_a[99-2]
test_py06.py::test_a[1-2]
test_py06.py::test_a[99-1]
========================= 2 failed, 1 passed in 0.11s =========================
test_a doing
PASSEDtest_a doing
FAILED
test_py06.py:3 (test_a[1-2])
3 != 100
Expected :100
Actual :3
<Click to see difference>
a = 1, b = 2
@pytest.mark.parametrize(["a", "b"], [(99, 2), (1, 2), (99, 1)])
def test_a(a, b):
print("test_a doing")
> assert a + b > 100
E assert (1 + 2) > 100
test_py06.py:7: AssertionError
test_a doing
FAILED
test_py06.py:3 (test_a[99-1])
100 != 100
Expected :100
Actual :100
<Click to see difference>
a = 99, b = 1
@pytest.mark.parametrize(["a", "b"], [(99, 2), (1, 2), (99, 1)])
def test_a(a, b):
print("test_a doing")
> assert a + b > 100
E assert (99 + 1) > 100
test_py06.py:7: AssertionError
'''
8. pytest夹具, fixture
夹具使用
setup前置方法: 测试环境初始化
teardown后置方法: 资源回收, 收尾工作
**模块级(参数可选): **
def setup_module(module):
pass
def teardown_module((module)):
pass
函数级:
def setup_function(module):
pass
def teardown_function((module)):
pass
类级(@classmethod可不加)
@classmethod
def setup_class(class):
pass
def teardown_class(class):
pass
方法级(method参数可选): 方法名为setup 或者 teardown也可以
def setup(module):
pass
def teardown((module)):
pass
fixture装饰器
除了setup和teardown, pytest提供fixture进行改封为强大的夹具使用
夹具是可以具备返回值的
-
定义夹具
-
无返回值
@pytest.fixture() def before(): print("fixture no return") -
有返回值
@pytest.fixture() def login(): print("fixture with return") return "login"- 有参数, 变量名不能变, 就得是
request,request.prama
@pytest.fixture(params=[1, 2, 3]) def init_data(request): print("fixture with args", request.param) return request.param -
import pytest
@pytest.fixture()
def before():
print("fixture no return")
@pytest.fixture()
def login():
print("fixture with return")
return "login"
# 变量名不能变
@pytest.fixture(params=[1, 2, 3])
def init_data(request):
print("fixture with args", request.param)
return request.param
@pytest.mark.usefixtures("before")
def test_a():
print("test_a ====================")
# 这里的login是形参的名字, 也是夹具函数的名字, pytest会调用夹具, 把返回值传入此测试方法中
def test_b(login):
print("test_b ====================", login)
def test_c(init_data):
print("test_c ====================||%s" % init_data)
assert init_data != 2
if __name__ == '__main__':
pytest.main(["-s"])
运行结果:
fixture no return
test_a ====================
PASSED
test_py08.py::test_b fixture with return
test_b ==================== login
PASSED
test_py08.py::test_c[1]
test_py08.py::test_c[2]
test_py08.py::test_c[3]
========================= 1 failed, 4 passed in 0.42s =========================
fixture with args 1
test_c ====================||1
PASSEDfixture with args 2
test_c ====================||2
FAILED
test_py08.py:28 (test_c[2])
2 != 2
预期:2
实际:2
<点击以查看差异>
init_data = 2
def test_c(init_data):
print("test_c ====================||%s" % init_data)
assert init_data != 2
assert 2 != 2
test_py08.py:31: AssertionError
fixture with args 3
test_c ====================||3
PASSED
参数化使用夹具
执行顺序:
- 因为被测方法中有参数名:
init_data pytest会找到同名的fixture函数- 但装饰器上有参数
params, 长度为3, 所以会执行三次测试函数的调用 - 但测试之前会执行
fixture函数 - 在执行fixture之前, 组装好
request对象, 里边有scope,param等属性
fixture其他参数:
def fixture(
scope="function",
params=None,
autouse=False,
ids=None,
name=None
)
scope: 范围, session, module,function, class
ids: 不能单独使用, 必须和params 一块使用, 可以将params中变量取别名带入
name: 给fixture起别名, 一旦起来别名, 在使用的时候就必须使用别名; 如果夹具函数需要多个模块使用, 不要加别名;
@pytest.fixture(scope="function", autouse=False, params=['lijiang', 'zhanfangyuan', 'litiantian']), ids=['l','z','lt'])
def exe_database_sql(request)
yeild request.param
fixture结合conftest.py文件使用: 将起别名的夹具函数放入conftest.py中, 可以在多个模块中使用别名的夹具函数
conftest.py是专门用于存放fixture的配置文件, 名称是固定的, 不能变conftest.py文件里所有的方法在调用时都不需要导包conftest.py文件可以有多个, 并且多个conftest.py文件里的多个fixture可以被一个用例调用, 顺序按照调用时的参数顺序来
9. pytest第三方插件使用
-
html报告-
安装 :
pip install pytest-html- 可能需要
py.xml, 执行pip install -U py
- 可能需要
-
使用:
-
命令行方式:
pytest --html=存储路径/report.html -
配置文件方式:
[pytest] addopts = -s --html=./report.html
-
-
-
指定执行顺序
-
安装 :
pip install pytest-ordering -
使用:
添加装饰器
@pytest.mark.run(order=x)到测试函数或者方法上-
@标记非负整数的, 越小的先执行, 0 优先1执行, 1优先2执行
-
没有标记的函数
-
@标记负数的, 越小的先执行, -2优先-1执行
-
-
-
**失败重试: **失败后多重试几次
- 安装:
pip install pytest-rerunfailures - 使用:
- 命令行方式:
pytest --reruns 5 - 配置文件方式:
[pytest] addopts = -s --reruns 5
- 命令行方式:
- 安装:
-
多进程运行cases: 当cases量很多时,运行时间也会变的很长,如果想缩短脚本运行的时长,就可以用多进程来运行。
- 安装:
pip install -U pytest-xdist - 使用:
- 命令行方式:
pytest -n 5 - 配置文件方式:
[pytest] addopts = -s -n 5
- 命令行方式:
- 安装:
10. yaml格式测试用例 读, 写, 封装
一个方法读取一个yaml文件
-
name: 获取统一的接口鉴权码
request:
method: get
url: https://api/weixin.qq.com/cgi-bin/token
data:
grant_type: client_credential
appid: xxxxxxx
secret: xxxxxxxxxxxxxxxxxxxxxxx
validate: None
-
name: 获取统一的接口鉴权码
request:
method: get
url: https://api/weixin.qq.com/cgi-bin/token
data:
grant_type: client_credential
appid: xxxxxxx
secret: xxxxxxxxxxxxxxxxxxxxxxx
validate: None
read_yaml(path):
fyaml = open("lijiang.yaml", "r", encoding="utf-8")
yamls = fyaml.read()
yaml_ob = yaml.load(yamls, Loader=yaml.FullLoader)
yield yaml_ob
fyaml.close()
# 第二种
read_yaml(path):
with open("lijiang.yaml", "r", encoding="utf-8") as f:
value = yaml.load(stream=f, Loader=yaml.FullLoader)
return value
@pytest,mark.parametrize('caeinfo', read_yaml("yaml文件路径"))
def test_flag(self, caseinfo):
name = caseinfo['name']
method = caseinfo['request']['method']
url = caseinfo['request']['url']
data = caseinfo['request']['data']
# 数据如果是表格形式, 就用params=data, 如果是json格式, 就用 json=data
res = TestApi.session.request(method=method, url=url, params=data)
print(res.json)
11. allure插件生成更加美观的报告
-
安装
allure-pytest插件:pip install allure-pytest -
安装
allure, 网上找教程, 安装好后将 安装目录下的.\bin目录加到环境变量,allure --version查看版本, 是否安装成功且加入到环境变量中 -
生成报告
-
在
pytest.ini配置文件中 的appopts = -vs --alluredir=./report/temps --clean-alluredir# run.py if __name__ == '__main__': pytest.main() timesleep(3) os.system('allure generate ./report/temps -o ./report/allure --clean')
-
-
报告定制:
- logo
- 项目名称 - 接口 - 用例
- 用例描述 - 参数- 执行步骤
12. 接口自动化测试框架封装
yaml文件如何实现接口关联封装yaml文件如何实现动态参数的处理yaml文件如何实现文件上传yaml文件如何实现断言, 特别是当有参数化的时候如何断言yaml文件数据量太大时怎么办- 接口自动化框架的扩展: 加密接口, 签名接口, 自定义的功能接口
深度思考:
- 做自动化是为了什么? 投入 和 产出
- 如何能够做到只要自动化测试框架搭建完成后, 其他的测试不需要改任何代码, 也可以通过这个框架实现自动化测试
Day4 requests模块详解
1. Requests库介绍
requests库是用来发送http请求以及接受http响应的python第三方库, 主要用于接口自动化测试
安装: pip install requests
2. requests库常用方法
requests.get():
requests.post():
requests.put():
requests.delete():
Day5 selenium 工具使用
(1条消息) selenium入门超详细教程——网页自动化操作_Yunlord的博客-CSDN博客
1. Selenium WebDrive原理
-
Selenium Client Library
Selenium 自动化测试人员可以使用Java, Ruby, Python, C#等语言, 利用他们提供的库编写脚本
-
JSON Write Protocol Over HTTP client
JSON Wire Protocol是在HTTP服务器之间传输信息的RESTful 风格的API, 每个浏览器驱动程序都有他们各自对应的HTTP服务器
-
Browser Drivers
不同浏览器都包含一个单独的浏览器驱动程序
-
Browsers
Selenium支持多浏览器, 如Firefox, Chrome, IE, Safari
2. selenium及相关软件安装
-
基于Python环境搭建(Windows系统)
- Python 3.5
- Pycharm
- selenium包
- 浏览器: 要下载对应浏览器的driver, 下载完放入某个环境变量 path目录下; 如果有报错, 根据对应报错提示需要的浏览器driver, 将
msedgedriver.exe改个名MicrosoftWebDriver,exe
-
selenium 安装, 卸载, 查看命令
-
安装
pip install selenium -
卸载
pip uninstall selenium -
查看
pip show selenium
-
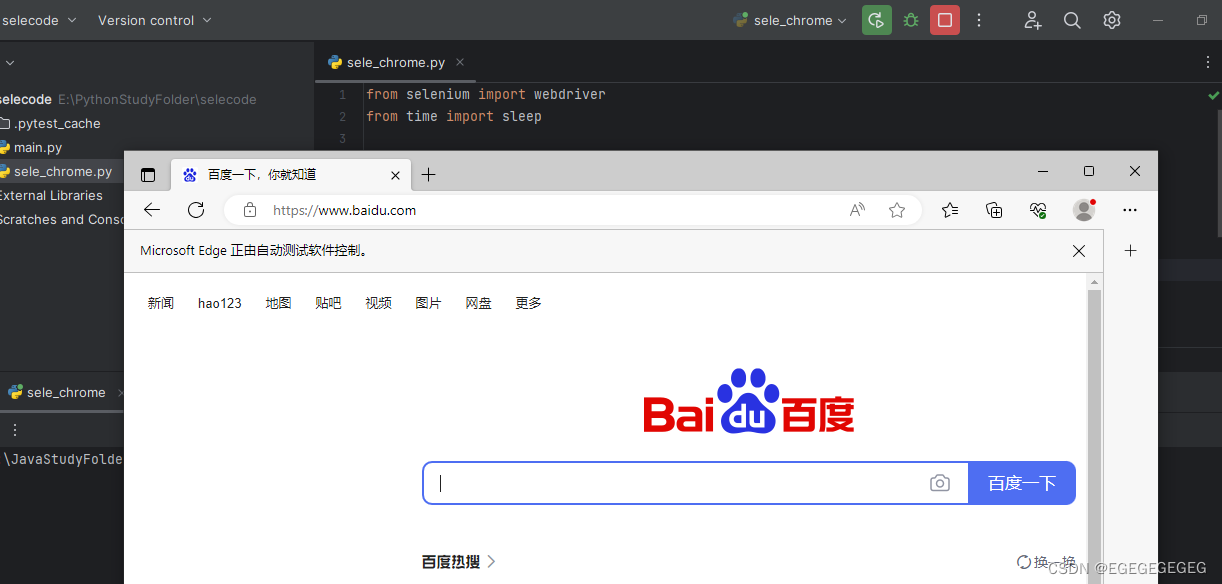
3. selenium 基本使用
from selenium import webdriver
from time import sleep
# 创建WebDriver对象
# 如果没有防止到系统环境变量中, 可不带参数创建
driver = webdriver.Edge()
# 如果没有防止到系统环境变量中, 需要通过参数指定
# driver = webdriver.Chrome(executable_path="./chromedriver.exe")
url = 'https://www.baidu.com'
# 使用浏览器打开页面
driver.get(url)
sleep(10)
# 关闭浏览器
driver.quit()
4. 元素定位
普通元素定位:
- 通过
id查找元素: 在html页面, 确认元素id, 通过id查找元素,find_element_by_id - 通过
name查找:find_element_by_name - 通过
class_name查找:find_element_by_class_name - 通过
tag_name查找:find_element_by_tag_name
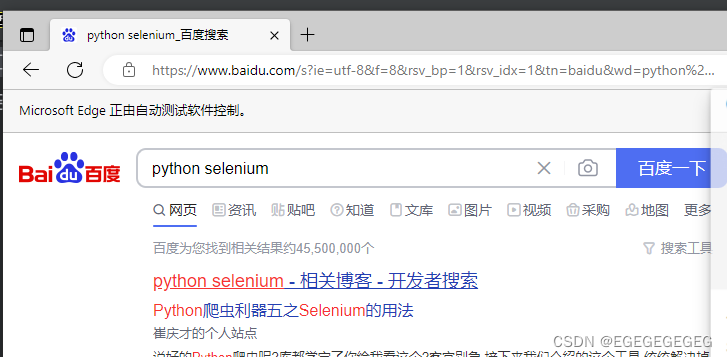
例子:
from selenium import webdriver
from time import sleep
# 创建WebDriver对象
# 如果没有防止到系统环境变量中, 可不带参数创建
driver = webdriver.Edge()
# 如果没有防止到系统环境变量中, 需要通过参数指定
# driver = webdriver.Chrome(executable_path="./chromedriver.exe")
url = 'https://www.baidu.com'
# 使用浏览器打开页面
driver.get(url)
# 查找 元素(标签, 标记, 节点) 通过id 查找
driver.find_element_by_id("kw").send_keys("python selenium")
driver.find_element_by_id("su").click()
sleep(60)
# 关闭浏览器
driver.quit()
找到输入框元素, 向百度输入框输入信息, 并点击百度一下进行百度搜索
超链接定位:
超链接元素, 一般没有name, 没有class_name, 需要通过链接文本来定位
-
通过
link text, 完整链接文本匹配:driver.find_element_by_link_text("新闻").click() -
通过
partial linktext, 部分链接文本匹配:driver.find_element_by_partial_link_text("闻").click()
CSS选择器
- CSS选择器语法
| 选择器 | 例子 | 例子描述 |
|---|---|---|
| .class | .intro | 选择 class=“intro” 的所有元素。 |
| .class1.class2 | .name1.name2 | 选择 class 属性中同时有 name1 和 name2 的所有元素。 |
| .class1 .class2 | .name1 .name2 | 选择作为类名 name1 元素后代的所有类名 name2 元素。 |
| #id | #firstname | 选择 id=“firstname” 的元素。 |
| * | * | 选择所有元素。 |
| element | p | 选择所有 元素。 |
| element.class | p.intro | 选择 class=“intro” 的所有 元素。 |
| element,element | div, p | 选择所有
元素和所有
元素。 |
| element element | div p | 选择
元素内的所有
元素。 |
| element>element | div > p | 选择父元素是
的所有
元素。 |
| element+element | div + p | 选择紧跟
元素的首个
元素。 |
| element1~element2 | p ~ ul | 选择前面有 元素的每个
|
| [attribute] | [target] | 选择带有 target 属性的所有元素。 |
| [attribute=value] | [target=_blank] | 选择带有 target=“_blank” 属性的所有元素。 |
| [attribute~=value] | [title~=flower] | 选择 title 属性包含单词 “flower” 的所有元素。 |
| [attribute|=value] | [lang|=en] | 选择 lang 属性值以 “en” 开头的所有元素。 |
| [attribute^=value] | a[href^=“https”] | 选择其 src 属性值以 “https” 开头的每个 元素。 |
| [attribute$=value] | a[href$=“.pdf”] | 选择其 src 属性以 “.pdf” 结尾的所有 元素。 |
| [attribute*=value] | a[href*=“w3school”] | 选择其 href 属性值中包含 “abc” 子串的每个 元素。 |
| :active | a:active | 选择活动链接。 |
| ::after | p::after | 在每个 的内容之后插入内容。 |
| ::before | p::before | 在每个 的内容之前插入内容。 |
| :checked | input:checked | 选择每个被选中的 元素。 |
| :default | input:default | 选择默认的 元素。 |
| :disabled | input:disabled | 选择每个被禁用的 元素。 |
| :empty | p:empty | 选择没有子元素的每个 元素(包括文本节点)。 |
| :enabled | input:enabled | 选择每个启用的 元素。 |
| :first-child | p:first-child | 选择属于父元素的第一个子元素的每个 元素。 |
| ::first-letter | p::first-letter | 选择每个 元素的首字母。 |
| ::first-line | p::first-line | 选择每个 元素的首行。 |
| :first-of-type | p:first-of-type | 选择属于其父元素的首个 元素的每个 元素。 |
| :focus | input:focus | 选择获得焦点的 input 元素。 |
| :fullscreen | :fullscreen | 选择处于全屏模式的元素。 |
| :hover | a:hover | 选择鼠标指针位于其上的链接。 |
| :in-range | input:in-range | 选择其值在指定范围内的 input 元素。 |
| :indeterminate | input:indeterminate | 选择处于不确定状态的 input 元素。 |
| :invalid | input:invalid | 选择具有无效值的所有 input 元素。 |
| :lang(language) | p:lang(it) | 选择 lang 属性等于 “it”(意大利)的每个 元素。 |
| :last-child | p:last-child | 选择属于其父元素最后一个子元素每个 元素。 |
| :last-of-type | p:last-of-type | 选择属于其父元素的最后 元素的每个 元素。 |
| :link | a:link | 选择所有未访问过的链接。 |
| :not(selector) | :not§ | 选择非 元素的每个元素。 |
| :nth-child(n) | p:nth-child(2) | 选择属于其父元素的第二个子元素的每个 元素。 |
| :nth-last-child(n) | p:nth-last-child(2) | 同上,从最后一个子元素开始计数。 |
| :nth-of-type(n) | p:nth-of-type(2) | 选择属于其父元素第二个 元素的每个 元素。 |
| :nth-last-of-type(n) | p:nth-last-of-type(2) | 同上,但是从最后一个子元素开始计数。 |
| :only-of-type | p:only-of-type | 选择属于其父元素唯一的 元素的每个 元素。 |
| :only-child | p:only-child | 选择属于其父元素的唯一子元素的每个 元素。 |
| :optional | input:optional | 选择不带 “required” 属性的 input 元素。 |
| :out-of-range | input:out-of-range | 选择值超出指定范围的 input 元素。 |
| ::placeholder | input::placeholder | 选择已规定 “placeholder” 属性的 input 元素。 |
| :read-only | input:read-only | 选择已规定 “readonly” 属性的 input 元素。 |
| :read-write | input:read-write | 选择未规定 “readonly” 属性的 input 元素。 |
| :required | input:required | 选择已规定 “required” 属性的 input 元素。 |
| :root | :root | 选择文档的根元素。 |
| ::selection | ::selection | 选择用户已选取的元素部分。 |
| :target | #news:target | 选择当前活动的 #news 元素。 |
| :valid | input:valid | 选择带有有效值的所有 input 元素。 |
| :visited | a:visited | 选择所有已访问的链接。 |
对于标签 <input type="text" class="classname0" name="username" id="username_id" maxlength="100" autocomplete="off"> , 如下代码都可以获取到这个标签
# id选择器 "#username_id"
driver.find_element_by_css_selector("#username_id")
# 属性选择器 "[attr=attr_value]"
driver.find_element_by_css_selector("[name=username]")
# 类选择器 ".classname0"
driver.find_element_by_css_selector(".classname0")
# 标签选择器 找到所有该类型的标签
driver.find_element_by_css_selector("input")
xpath方式定位
xpath: 即xml path, XML是标签语言, 和HTML一样, 通过标签的嵌套来表达信息, 形成了父节点, 子节点, 后代节点, 祖先节点, 同胞节点等关系. 而xpath就是用来这节点中找到需要的
xpath表达式
- 完整表达式:
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档的节点, 而不考虑位置 |
| . | 选择当前节点 |
| … | 选择当前节点的父节点 |
- 获取内容
| 表达式 | 描述 |
|---|---|
| @ | 选取属性 |
| text() | 获取文本 |
- 进阶表达式
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[1] | 选取属于bookstore子元素的第一个book元素 |
| /bookstore/book[last()] | 选取属于bookstore子元素的倒数第一个book元素 |
| /bookstore/book[last()-1] | 选取属于bookstore子元素的倒数第二个book元素 |
| //book/title[text()=‘Harry Potter’] | 选择所有book下的title 元素中文本为 Harry Potter的little元素 |
| //title[@lang=“eng”] | 选择lang属性值为eng的所有title元素 |
速度方法: 在浏览器网页中开发者模式, 选到html源码 标签复制xpath
driver.find_element_by_xpath("//*[@id='kw']").send_keys("mihayou")
driver.find_element_by_xpath("//*[@id='su']").click()
5. 浏览器基本操作
-
浏览器操作方法
方法 说明 maximize_window()最大化浏览器, 固定自动化操作位置 set_window_size(w, h)设置浏览器宽, 高 set_window_position设置浏览器位置,浏览器左上角相对于屏幕左上角位置 back()后退 forward()前进 refresh()刷新页面 close()关闭 quit()退出浏览器 -
浏览器信息/属性
title获取页面titlecurrent_url获取当前页面URL
6. 页面等待
因为代码执行速度 远远快于 页面加载速度, 在加载新的页面, 或者翻页时, 需要给一些反应时间
1. 强制等待: time.sleep(3)
2. 显示等待
- 使用
WebDriverWait包装WebDriver对象 - 使用
webDriverWait的until方法, 传入可调用对象( 一般时presence_of_element_located的函数返回值)
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
# 创建WebDriver对象
# 如果没有防止到系统环境变量中, 可不带参数创建
driver = webdriver.Edge()
# 如果没有防止到系统环境变量中, 需要通过参数指定
# driver = webdriver.Chrome(executable_path="./chromedriver.exe")
url = 'https://www.baidu.com'
# 使用浏览器打开页面
driver.get(url)
# 查找 元素(标签, 标记, 节点) 通过id 查找
driver.find_element_by_id("kw").send_keys("美女")
driver.find_element_by_id("su").click()
# time.sleep(3)
# 显示等待, 每个0.5秒检查一次, 最多5秒时间
element = WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.ID, "1")))
driver.find_element_by_id("1").click()
sleep(60)
# 关闭浏览器
driver.quit()
原理:
- 定时尝试查找元素
- 找到了就返回
- 如果超过指定时间还没找到就报错
3. 隐式等待: driver.implicitly_wait(5)
隐式等待 和 显示等待: 隐式等待, 未标明等待加载什么元素; 显示等待, 表明等待哪个元素加载完成
7. 元素操作
- 元素操作
clear()清除文本send_keys(): 模拟输入click(): 点击
- 元素属性获取
- size: 元素大小
- text: 获取元素文本
- get_attribute(): 获取属性值
- is_display(): 判断元素是否可见
- is_enabled(): 判断元素是否可用
print(driver.find_element_by_xpath("//*[text()='新闻']").size)
print(driver.find_element_by_xpath("//*[text()='新闻']").get_attribute("href"))
print(driver.find_element_by_xpath("//*[text()='新闻']").is_displayed())
print(driver.find_element_by_xpath("//*[text()='新闻']").is_enabled())
#=====================================
'''
{'height': 23, 'width': 26}
http://news.baidu.com/
True
True
'''
8. 鼠标操作
使用步骤:
-
创建
ActionChains对象 -
使用
ActionChains对象的方法进行操作方法 操作 说明 context_click()右击 模拟鼠标右击 double_click()双击 模拟鼠标双击 drag_and_drop()拖动 模拟鼠标双击拖动 move_to_element()悬停 模拟鼠标悬停在什么位置 其他参考 ActionChains源码其他参考 ActionChains源码 -
通过
ActionChains提交这些操作,perform()
import time
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
# 创建WebDriver对象
driver = webdriver.Edge()
url = 'https://www.baidu.com'
# 使用浏览器打开页面
driver.get(url)
# 鼠标操作
action = ActionChains(driver)
# 右击操作
action.context_click(driver.find_element_by_id("su"))
# 拖拽操作
action.drag_and_drop(driver.find_element_by_id("1"), driver.find_element_by_id("2"))
# 鼠标操作事件都要执行
action.perform()
sleep(10)
# 关闭浏览器
driver.quit()
9. 模拟键盘操作
使用: element.send_keys()
参数:
- 普通字符串
- 键盘按键
例子:
- 输入用户名:
admin1, 暂停两秒, 删除1 - 全选用户名:
admin, 暂停两秒 - 复制用户名:
admin, 暂停两秒 - 粘贴到密码框, 暂停两秒
import time
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.keys import Keys
# 创建WebDriver对象
# 如果没有防止到系统环境变量中, 可不带参数创建
driver = webdriver.Edge()
# 如果没有防止到系统环境变量中, 需要通过参数指定
# driver = webdriver.Chrome(executable_path="./chromedriver.exe")
url = 'https://www.baidu.com'
# 使用浏览器打开页面
driver.get(url)
# 查找 元素(标签, 标记, 节点) 通过id 查找
element = driver.find_element_by_id("kw")
# 输入 lijiang
element.send_keys("lijianga")
# driver.find_element_by_id("su").click()
time.sleep(2)
# 文本全选
element.send_keys(Keys.CONTROL, "a")
time.sleep(2)
# 退格键
element.send_keys(Keys.BACK_SPACE)
time.sleep(2)
element.send_keys("zhaifangyuan")
time.sleep(2)
element.send_keys(Keys.CONTROL, "a")
time.sleep(2)
# 剪切
element.send_keys(Keys.CONTROL, "x")
time.sleep(2)
# 复制
element.send_keys(Keys.CONTROL, "v")
sleep(10)
# 关闭浏览器
driver.quit()
10. 下拉框, 单选框, 操作
下拉框是HTML中<select>元素, 主要i操作就是选中某个选项<option>
-
步骤
-
通过
select元素 创建出Select对象 -
通过
Select对象的方法选中选项select_by_index(): 根据option索引来定位, 从0开始select_by_value(): 根据option属性 value值定位select_by_visible_text(): 根据option显示文本定位
-
import time
from selenium import webdriver
from time import sleep
from selenium.webdriver.common.by import By
from selenium.webdriver.support.select import Select
driver = webdriver.Edge()
url = '某个url'
# 使用浏览器打开页面
driver.get(url)
ele = driver.find_element(By.ID, 'selectA')
select = Select(ele)
time.sleep(2)
select.select_by_index(3)
time.sleep(2)
select.select_by_value("bj")
time.sleep(2)
select.select_by_visible_text("A广州")
time.sleep(2)
driver.quit()
11. 页面滚动
滚动条: WebDriver类库中没有直接提供对滚动条进行操作的方法, 但是提供了可调用JavaScript脚本的方法, 所以可以通过JS脚本来达到操作滚动条的目的
方法:
- 让浏览器执行js代码,
driver.execute_script(js代码字符串) - 滚动的js代码
- 绝对滚动
window.scrollTo(x,y) - 相对滚动
window.scrollBy(x,y)
- 绝对滚动
driver.execute_script("window.scrollTo(0, 10000)")
扩展: WebDriver可以扩展很多js代码
12. 警告框
通过js中的alert, confirm, prompt 方法弹出的框, 它会阻挡我们对网页进行操作
相应方法:
- 获得警告框:
alert = driver.switch_to.alert - 关闭警告框,
alert.dismiss(), 适用于三种警告框关闭 - 确认, 也会关闭警告框, 适用于
confirm和prompt alert accept() - 输入文字: 使用于
prompt alert.send_keys() - 获取警告框中的文字,
alert.text
import time
from selenium import webdriver
from time import sleep
driver = webdriver.Edge()
url = '某个url'
# 使用浏览器打开页面
driver.get(url)
driver.find_element_by_id("alerta").click()
# 警告框 切换选中到警告框
alert = driver.switch_to.alert
print(alert.text)
sleep(2)
alert.dismiss()
# alert.confirm()
sleep(5)
# 关闭浏览器
driver.quit()
13. Frame切换
Frame框架: 一个矩形区域, 在一个网页中, 可以轻松嵌套另一个网页, frame 标签<iframe>, <frame>, <frameset>
方法:
- 切换到子frame,
drive.switch_to.frame(frame名或frameid) - 切换到 根页面,
drive.switch_to.default_content()
import time
from selenium import webdriver
from time import sleep
driver = webdriver.Edge()
url = 'https://mail.qq.com'
# 使用浏览器打开页面
driver.get(url)
sleep(2)
# 切换到qq login frame
driver.find_element_by_id("QQMailSdkTool_login_loginBox_tab_item_qq").click()
frame1 = driver.find_elements_by_tag_name("iframe")[1]
driver.switch_to.frame(frame1)
# 切换到登录frame
driver.switch_to.frame("ptlogin_iframe")
sleep(2)
# 点击密码登录, 出现登录框
driver.find_element_by_id("switcher_plogin").click()
sleep(2)
# 输入账号
driver.find_element_by_id("u").send_keys("123456789")
sleep(2)
# 切换根frame
driver.switch_to.default_content()
print(driver.find_element_by_class_name("login_pictures_title").text)
sleep(5)
# 关闭浏览器
driver.quit()
14. 标签页切换, 窗口切换
在selenium中, 通过一个随机生成的字符串(uuid)来唯一标识某个窗口
句柄(Handle): 是一个用来标识对象或者项目的标识符, 可以用来描述窗体, 文件等
handle的获取
- 获取所有:
driver.window_handles - 获取单个:
driver.current_window_handle - 切换:
driver.switch_to.window(handle)
需求:
-
获取注册实例
.html当前窗口句柄 -
点击注册实例
.html页面中注册A页面 -
获取所有窗口句柄
-
遍历判断窗口句柄并切换到注册A页面
-
操作注册A页面元素, 注册信息
from selenium import webdriver
from time import sleep
# 创建WebDriver对象
# 如果没有防止到系统环境变量中, 可不带参数创建
driver = webdriver.Edge()
# 如果没有防止到系统环境变量中, 需要通过参数指定
# driver = webdriver.Chrome(executable_path="./chromedriver.exe")
url = 'https://www.baidu.com'
# 使用浏览器打开页面
driver.get(url)
driver.maximize_window()
print(driver.window_handles)
print(driver.current_window_handle)
sleep(2)
driver.find_element_by_id("kw").send_keys("美女")
driver.find_element_by_id("su").click()
sleep(3)
driver.find_element_by_class_name("image-one-line-item_aBS4H ").click()
sleep(3)
print(driver.window_handles)
print(driver.current_window_handle)
driver.switch_to.window(driver.window_handles[1])
sleep(3)
print(driver.window_handles)
print(driver.current_window_handle)
driver.find_element_by_id("currentImg").click()
sleep(30)
# 关闭浏览器
driver.quit()
# =============================
'''
['C4ACEF39E2B2FD76BFF72E0F2AA1A83B']
C4ACEF39E2B2FD76BFF72E0F2AA1A83B
['C4ACEF39E2B2FD76BFF72E0F2AA1A83B', '905B188F01F602F48A53D532A3E10962']
C4ACEF39E2B2FD76BFF72E0F2AA1A83B
['C4ACEF39E2B2FD76BFF72E0F2AA1A83B', '905B188F01F602F48A53D532A3E10962']
905B188F01F602F48A53D532A3E10962
'''
15. 截图
driver.get_screentshot_as_file(保存路径/文件名.png)
图片保存格式是.png格式的
def test_01(self):
try:
lp = LoginPage(self.driver)
lp.login_ecshop()
assert 1==2
except Exception as e:
filepath = r"E:\PythonStudyFolder\webauto_code\error_image\login_error.png"
self.driver.save_screenshot(filepath)
# 把错误截图以附件的形式加入到allure 报告中
with open(file_path, mode='rb') as f:
allure.attach(f.read(), "login.png",allure.attachment_type.PNG)
16. cookie处理
登录验证码处理
-
验证码介绍: 一些登录功能, 为了避免机器操作, 会添加验证码, 一般是字母数字,旋转图形, 拖动滑块
-
应对处理:
- 去掉验证码: 测试环境采用
- 设置万能验证码: 生产环境下使用
- 验证码识别技术:
Python-tesseract识别图片类型 - 使用打码平台
- 记录cookie, cookie 记录用户验证信息, 携带cookie的会话
cookie处理
-
案例
import time from selenium import webdriver driver = webdriver.Edge() driver.get("https://www.baidu.com") driver.maximize_window() time.sleep(2) driver.add_cookie({"name": "lijiang", "value":"通过Edge浏览器调试工具查看"}) driver.add_cookie({"name": "baidulj", "value":"通过Edge浏览器调试工具查看"}) time.sleep(5) driver.refresh() time.sleep(5) driver.quit()
Day6 Web自动化
企业级框架:
- 编程语言: python, java
- PO模式
pytest深入挖掘的功能- 数据驱动: ddt
- 二次封装: excel, yaml, ini, 数据库
- 日志监控: logger
- 异常处理: try except
jenkins: 无人值守- docker
- allure定制
- 分布式Grid
1. 数据驱动-python操作文件
数据驱动测试(DDT)
-
文本文件(txt文件)
- 打开文件:
file = open("lijiang.txt", "r", encoding="uft-8") - 读取文件:
file.read() - 读取一行:
file.readline() - 读取所有行:
file.readlines()
- 打开文件:
-
csv文件(excel 逗号分隔值文件), 以纯文本形式保存表格数据
lijiang,male,27 zhanfangyuan,female,27 lijiang1,male,27 lijiang2,male,27 zhanfangyuan1,female,27 zhanfangyuan2,female,27import csv file = open("zhaifangyuan.csv", "r", encoding="utf-8") cf = csv.reader(file) print(cf) for t in cf: print(t) # ============================== ''' <_csv.reader object at 0x000002ECA27E5F40> ['lijiang', 'male', '27'] ['zhanfangyuan', 'female', '27'] ['lijiang1', 'male', '27'] ['lijiang2', 'male', '27'] ['zhanfangyuan1', 'female', '27'] ['zhanfangyuan2', 'female', '27'] ''' -
excel文件, 表格文件, excel是二进制文件
最全整理!Python 操作Excel库xlrd与xlwt常用操作详解! - 知乎 (zhihu.com)
xlrd-
需要安装
xlrd库:pip install xlrd -
读取Excel文件的内容
import xlrd e1 = xlrd.open_workbook("litiantian.xlsx") sheet = e1.sheet_by_index(0) print(sheet.nrows) print(sheet.ncols) print(sheet.row_values(0)) print(sheet.row_values(1)) print(sheet.row_values(3)) print(sheet.row_values(4))
pandaspandas是数据处理最常用的分析库之一,可以读取各种各样格式的数据文件,一般输出
dataframe格式。如:txt、csv、excel、json、剪切板、数据库、html、hdf、parquet、pickled文件、sas、stata等等-
安装:
pip install pandas -
read_csv方法
read_csv方法用来读取csv格式文件,输出dataframe格式。import pandas as pd pd.read_csv('test.csv')read_excel方法
读取excel文件,包括xlsx、xls、xlsm格式
import pandas as pd pd.read_excel('test.xlsx')read_table方法通过对sep参数(分隔符)的控制来对任何文本文件读取
read_json方法
读取json格式文件
df = pd.DataFrame([['a', 'b'], ['c', 'd']],index=['row 1', 'row 2'],columns=['col 1', 'col 2']) j = df.to_json(orient='split') pd.read_json(j,orient='split')-
read_html方法: 读取html表格 -
read_clipboard方法: 读取剪切板内容 -
read_pickle方法: 读取plckled持久化文件 -
read_sql方法: 读取数据库数据,连接好数据库后,传入sql语句即可 -
read_dhf方法: 读取hdf5文件,适合大文件读取 -
read_parquet方法: 读取parquet文件 -
read_sas方法: 读取sas文件 -
read_stata方法: 读取stata文件 -
read_gbq方法: 读取google bigquery数据
-
-
json文件
dumps()方法将python对象转化为json字符串loads()方法将json字符串转化为python对象
json类型和python类型对照表Python JSON dict: {key:value, k2:v2}object: {key:value, k2:v2}list: [val1, val2, ...], tuple:(val1, val2, ...)array: [value1, v2, ...]str, unicode string int, long, float number True | False | None true | false | null -
XML文件: 可扩展标记语言, 标记电子文件使其具有结构性的 标记语言, 用来标记数据, 定义数据类型
- 开头表明版本, 编码
- 每个标签都又开始有结束
- 大小写敏感
<?xml version="1.0" encoding="UTF-8"?>
<bookstore>
<book category="COOKING">
<title lang="en"> Everyday Italian</title>
<author> ZhaiTiantian </author>
<year> 2023 </year>
<price> 30 </price>
</book>
<book category="LEARNING">
<title lang="en"> Everyday Learning</title>
<author> LiTiantian </author>
<year> 2023 </year>
<price> 23 </price>
</book>
</bookstore>
try:
import xml.etree.cElementTree as ET
except ImportError:
import xml.etree.ElementTree as ET
tree = ET.parse("book.xml")
root = tree.getroot()
print(root.tag)
print(root.attrib)
for child in root:
print(child.tag)
print(child.attrib)
for cchild in child:
print(cchild.tag)
print(cchild.text)
-
yaml文件:
另一种标记语言, 以数据为中心, 去掉了标记的框框,不是一种标记语言- 大小写敏感
- 使用缩进标识层级关系
- 缩进不允许使用
Tab键, 只能使用SPACE空格 - 同级元素左侧对其
数据结构:
- 对象: 键值对几个, 又称映射, 哈希, 字典
- 数组: 一组按次序排列的值, 又称序列 / 列表
- 纯良: 单个的,不可分割的值
安装:
pip install pyyamllijiang: {name: lijiang1, gender: female} zhaifangyuan: {name: zhaifangyuan1, gender: female} namse: - lijiang2 - zhaifangyuan2 - litigantimport yaml fyaml = open("lijiang.yaml", "r", encoding="utf-8") yamls = fyaml.read() yaml_ob = yaml.load(yamls, Loader=yaml.FullLoader) print(yaml_ob) fyaml.close()
2. web自动化项目实战-携程购买火车票
- 需求分析
- 业务场景覆盖(测试用例设计)
- 业务分拆多个页面
- 页面元素分析
- 难点分析
base_function.py
from selenium import webdriver
from datetime import date
import xlrd
from selenium.webdriver.common.by import By
driver = webdriver.Edge()
def choose_date(date_str):
date_split = str.split(date_str, "-")
print(date.today())
print(date.today().month)
if date.today().month == int(date_split[1]):
ele = byxpath("//strong[text()=" + str(int(date_split[1])) + "]")
elif date.today().month + 1 == int(date_split[1]):
ele = byxpath("//strong[text()=" + str(int(date_split[2])) + "][2]")
return ele
def read_excel(filename, ishead=True):
e1 = xlrd.open_workbook(filename)
sheet = e1.sheet_by_index(0)
data = []
for i in range(sheet.nrows):
if ishead:
continue
data.append(sheet[i])
return data
def byname(ele_name):
return driver.find_element_by_name(ele_name)
def byid(ele_id):
return driver.find_element_by_id(ele_id)
def byxpath(ele_xapth):
return driver.find_element(By.XPATH, ele_xapth)
def open_url(url):
driver.get(url)
driver.maximize_window()
def close():
driver.quit()
book_ticket.py
import time
from base_function import *
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
def ticket(start, end, date_str, name, idcard):
action = ActionChains(driver)
url = "https://trains.ctrip.com/"
open_url(url)
byxpath("//*[@aria-label='火车票 按回车键打开菜单']").click()
print("火车票")
WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.ID, "label-departStation")))
start_ele = byid("label-departStation")
start_ele.clear()
start_ele.send_keys(start)
action.move_by_offset(0, 0)
action.click()
action.perform()
WebDriverWait(driver, 5).until(EC.presence_of_element_located((By.ID, "label-arriveStation")))
end_ele = driver.find_element_by_id("label-arriveStation")
end_ele.clear()
time.sleep(1)
end_ele.send_keys(end)
action.move_to_element(end_ele)
action.move_by_offset(-20, -50)
action.click()
action.perform()
byxpath("//div[@class='date']").click()
choose_date(date_str).click()
action.move_by_offset(0, 0)
action.click()
action.perform()
ele = byxpath("//button[text()='搜索']")
action.move_to_element(ele)
action.click()
action.perform()
time.sleep(2)
print("search ok")
byxpath("//*[text()='订'][1]").click()
# action.move_to_element(ele)
# action.click()
# action.perform()
print("checi ok")
time.sleep(2)
byxpath("//*[text()='预订'][1]").click()
# action.move_to_element(ele)
# action.click()
# action.perform()
print("book ok")
time.sleep(10)
close()
test_book.py
import xc_ticket.book_ticket import ticket
from base_function import read_excel
import pytest
data = read_excel("data.xlsx", True)
@pytest.mark.parametrize(["start","end","date", "name", "id"], data)
def test_book_ticket(start, end, date, name, id):
ticket(start, end, date, name, id)
if __name__ == '__main__':
pytest.main(["-s", "test_book.py", "--html=./report.html"])
3. po模式, PageObject模式
一个页面当作一个对象, 页面中的业务放到其他模块中
优点:
- 页面分层, 页面元素和业务逻辑分开
- 方便复用对象
- 每个页面 都是一个独立的测试用例
- 自动化实现更容易
代码结构:
conf层 --> 配置
base 层 --> 基础函数库, 打开网页, 定位元素
common层 --> 读取文件, 日期处理, 公共函数
data层 --> 数据文件
logs层 --> 日志
PO层 --> 页面, 页面对象层, 页面元素动作
testcase层 --> 测试层 测试代码
reports层 --> 测试报告

代码
common_function.python: 公共函数, 和web不相关的
import xlrd
from datetime import date
# 读取xlsx表格数据
def read_excel(filename, isHead=True):
e1 = xlrd.open_workbook(filename)
sheet = e1.sheet_by_index(0)
data = []
for i in range(sheet.nrows):
if isHead:
continue
data.append(sheet[i])
return data
# 选择日期,获取对应xpath
def choose_date(date_str):
date_split = str.split(date_str, "-")
if date.today().month == int(date_split[1]):
xpath = "//strong[text()=" + str(int(date_split[1])) + "]"
elif date.today().month + 1 == int(date_split[1]):
xpath = "//strong[text()=" + str(int(date_split[2])) + "][2]"
return xpath
base_function.py: 定义一个Base类, 后边的每个页面的类都会集成这个Base类
from selenium.webdriver.edge.webdriver import WebDriver
from selenium.webdriver.common.by import By
class Base():
def __init__(self, driver):
self.driver = driver # type: WebDriver
def byname(self, ele_name):
return self.driver.find_element_by_name(ele_name)
def byid(self, ele_id):
return self.driver.find_element_by_id(ele_id)
def byxpath(self, ele_xapth):
return self.driver.find_element(By.XPATH, ele_xapth)
book_ticket_page.py: 定义一个订票页面的类, 对初始页面进行逻辑业务处理
import time
from po_ticket.base.base_function import Base
from po_ticket.common.common_function import choose_date
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
class BookTicket(Base):
def __init__(self):
self.action = ActionChains(self.driver)
def choose_ticket(self):
return self.byxpath("//*[@aria-label='火车票 按回车键打开菜单']").click()
def move_xy_click(self, x, y):
self.action.move_by_offset(x, y)
self.action.click()
self.action.perform()
def move_ele_click(self, ele):
self.action.move_to_element(ele)
self.action.click()
self.action.perform()
def book_start(self):
WebDriverWait(self.driver, 5).until(EC.presence_of_element_located((By.ID, "label-departStation")))
ele = self.byid("label-departStation")
ele.click()
ele.clear()
return ele
def book_end(self):
WebDriverWait(self.driver, 5).until(EC.presence_of_element_located((By.ID, "label-arriveStation")))
ele = self.byid("label-arriveStation")
ele.click()
ele.clear()
return ele
def book_date(self, date_str):
self.byxpath("//div[@class='date']").click()
self.byxpath(choose_date(date_str)).click()
def book_search(self):
ele = self.byxpath("//button[text()='搜索']")
self.move_ele_click(ele)
def book_checi(self):
return self.byxpath("//*[text()='预订'][1]")
def book_seat(self):
return self.byxpath("//*[text()='订'][1]")
def book_ticket(self, start, end, date_str):
self.choose_ticket().click()
# 出发站
self.book_start().send_keys(start)
self.move_xy_click(0, 0)
# 到达站
self.book_end().send_keys(end)
self.move_xy_click(-20, -50)
# 选日期
self.book_date(date_str)
self.move_xy_click(0, 0)
# 搜索
self.book_search()
print("search ok")
# 选车次, 选坐席
self.book_checi().click()
print("book_checi ok")
time.sleep(2)
self.book_seat().click()
print("book_seat ok")
test_book.py: 执行测试用例模块, 使用pytest, 参数化将表格数据写入测试用例执行, 注意夹具函数
from po_ticket.po_do_ticket.book_ticket_page import BookTicket
from selenium import webdriver
from po_ticket.common.common_function import read_excel
import pytest
data = read_excel("data.xlsx")
class TestBook():
def setup(self):
self.driver = webdriver.Edge()
url = "https://trains.ctrip.com/"
self.driver.get(url)
self.driver.maximize_window()
@pytest.mark.parametrize(["start", "end", "date", "name", "id"], data)
def test_01(self, start, end, date, name, id):
ticket = BookTicket(self.driver)
ticket.book_ticket(start, end, date)
def teardown(self):
self.driver.quit()
if __name__ == '__main__':
pytest.main(["-s", "--html=./report/book_ticket.html"])
4. Jenkins持续集成 以及 Allure 报告
-
安装启动
Jenkins, 需要(java, tomcat, git), 登录 -
新建项目, 配置选择项目路径, 并新增启动脚本命令
-
新建完成后, 可以直接在
Jenkins启动项目 -
下载
allure插件(allure-jenkins-plugin) 并放到..\jenkins\plugin目录下Jenkins如何安装配置Allure插件及工具_jenkins安装allure插件_redrose2100的博客-CSDN博客
-
在
jenkins配置中 配置全局的工具配置Global Tool Configuration中, 配置Allure 安装路径 -
在项目中, 点到要增加
Allure报告的项目, 右键点击配置, 在构建后配置中增加Allure Report, 填入temp路径, 点击高级, 填入report路径
Day7 接口测试
0. Jmeter接口测试技能大纲:
- 接口测试分类, 接口框架,
Jmeter安装,Jmeter目录介绍 和 界面详解 Jmeter常用组件, 组件执行顺序, 组件作用域- 接口测试流程 以及 发送不同的请求方式, 不同参数类型(键值对, json, 文件上传)的请求
- 逻辑控制器, 定时器
- 接口关联: 正则表达式和
JSON提取 - 动态参数化处理
Jmeter断言以及Jmeter的接口调试txt或者csv数据文件处理- 需要请求头的接口以及需要加解密的接口处理
Jmeter代理服务器实现脚本录制Jmeter组件beanshell脚本语言Jmeter组件websocket协议以及dubbo协议接口测试Jmeter执行数据库操作Jmeter非GUI运行 以及 常用参数使用 以及Jmeter + Ant + Jenkins实现持续集成
1. 接口定义:
广义(API): 系统与系统之间 进行通讯的协议, 或规范; 可以是抽象的, 可以是可见的
狭义: 后端服务器, 通过http形式, 接受请求, 返回相应数据; 前后端分离的 B/S 和 C/S架构接口; 第三方接口
2. 接口数据格式xml, json
主流接口数据类型都是json
{
"code": "0",
"desc": "成功",
"data": {
"cityInfo": {
"nationCn": "中国",
"nationEn": "china",
"provCn": "山东",
"provEn": "shandong",
"cityCn": "济南",
"cityEn": "jinan",
"areaCn": "济南",
"areaEn": "jinan",
"areaId": "101120101",
"areaCode": "370100"
},
"day": {
"time": "21日白天",
"sunUp": "日出 05:31",
"wind": "北风",
"weather_pic": "d02",
"temperature": "16",
"wind_pow": "4-5级",
"weather": "阴"
},
"alarmList": [
{
"signalType": "大风",
"signalLevel": "黄色",
"issueContent": "济南市气象台2023年04月20日16时50分继续发布大风黄色预警信号:预计20日夜间,全市仍将出现平均风力4到5级阵风7到8级的北风,部分地区阵风可达9级。(预警信息来源:国家预警信息发布中心)",
"issueTime": "2023-04-20 16:51",
"city": "济南市",
"district": "",
"province": "山东省"
}
],
"lifeIndex": {
"穿衣指数": {
"state": "较冷",
"reply": "建议着厚外套加毛衣等服装。"
},
"紫外线指数": {
"state": "最弱",
"reply": "辐射弱,涂擦SPF8-12防晒护肤品。"
},
"感冒指数": {
"state": "极易发",
"reply": "强降温,风力较强,极易感冒。"
}
},
}
}
3. 互联网常用的接口
接口的优点:
- 统计设计标准
- 前后端开发相对独立
- 扩展性灵活
- 前后端都可以使用自己熟悉的技术
不使用接口的缺点:
- 研发标准不统一, 团队磨合难度大
- 研发周期长, 扩展性差
4. 接口测试
定义: 接口测试是测试系统组件间数据交互的一种方式。 通过测试不同情况下的输入参数 和 与之对应的输出结果来判断接口是否符合 或者 满足相应的功能性, 安全性要求。 接口测试就是代替前端 或者第三方, 来验证后端实现是否符合接口规范
接口测试的作用: 测试接口的正确性 和 稳定性, 能为项目平台带来高效的缺陷管理和质量监督能力
接口测试的原理: 模拟客户端 向 服务器发送请求报文, 服务器做相应处理后返回客户端结果, 客户端接受相应数据后进判断 是否正确。 检查返回数据的正确性, 完整性, 安全性
接口一般不会暴露再网上被任意调用, 需要做一些限制, 比如必须登录, 限制请求次数, 频率
接口测试的流程:
- 分析接口文档 和 需求文档
- 编写接口测试计划
- 编写接口测试用例
- 执行接口测试用例
- (缺陷管理)
- 输出接口测试报告
接口测试分类:
-
模块接口测试: 主要是单元测试, 主要测试模块的调用与返回
-
Web接口测试:
- 服务器接口测试
- 外界接口测试: 测试第三方接口
接口测试的要点:
- 接口的功能性实现: 检查接口返回的数据与预期结果的一致性
- 测试接口的兼容性: 传递错误的数据类型能够处理
- 测试接口参数的边界值: 传递的数据足够大 或者 为负数能否处理
- 测试接口性能: 接口处理 和响应数据的时间
- 测试接口的安全性: 如登录的用户名, 密码第三方是否是密文传输
5. jmeter
特点:
- 支持很多类型的测试项目
- web: HTTP 、 HTTPS
- SOAP / REST
- database
- LDAP, FTP, Mail, TCP等
- 脚本, Java对象
- 有界面模式 和 命令行模式
- 支持多种操作系统
- 多线程测试
- 可生成测试
html测试报告 - 扩展丰富: 可链接的取样器, 负载统计, 计时器, 数据分析, 可视化插件, 动态输入到测试, 脚本编程的取样器
安装: Apache JMeter - 下载Apache JMeter
直接下载解压
http默认端口80
https默认端口443
Jmeter主要元件
1、配置元件:维护Sampler需要的配置信息,并根据实际的需要修改请求的内容。
2、前置处理器:负责在请求之前工作,常用来修改请求的设置
3、定时器:负责定义请求之间的延迟间隔。
4、取样器(Sampler):是性能测试中向服务器发送请求,记录响应信息、响应时间的最小单元,如:HTTP Request Sampler、FTP Request Sample、TCP Request Sample、JDBC Request Sampler等,每一种不同类型的sampler 可以根据设置的参数向服务器发出不同类型的请求。
5、后置处理器:负责在请求之后工作,常用获取返回的值。
6、断言:用来判断请求响应的结果是否如用户所期望的。
7、监听器:负责收集测试结果,同时确定结果显示的方式。
8、逻辑控制器:可以自定义JMeter发送请求的行为逻辑,它与Sampler结合使用可以模拟复杂的请求序列。
元件执行顺序:
配置元件->前置处理器->定时器->取样器->后置处理程序->断言->监听器
元件作用域: 靠test_plan的树形结构中元件的父子关系来确定的
配置元件:影响其作用范围内的所有元件。
前置处理器:在其作用范围内的每一个sampler元件之前执行。
定时器:在其作用范围内的每一个sampler有效
后置处理器:在其作用范围内的每一个sampler元件之后执行。
断言:在其作用范围内的对每一个sampler元件执行后的结果进行校验。
监听器:在其作用范围内对每一个sampler元件的信息收集并呈现。
逻辑控制器 只对其子节点中的取样器 和 逻辑控制器起作用
总结:从各个元件的层次结构判断每个元件的作用域。
- 取样器不与其他原件 相互作用, 不存在作用域问题
- 逻辑控制器之对其子节点中的取样器 和 逻辑控制器起作用
- 其他元件
- 如果父节点是 取样器, 则只对父节点起作用
- 如果父节点不是取样器, 则对其父节点 及 父节点的所有后台节点都起作用
JSON提取器: 提取器拿到的变量只在同一个线程组内能用

函数 和 函数助手
-
time: 时间戳, 格式化的时间
-
counter: 计数器, 全局:FALSE; 单线程:TRUE
-
random: 含头含尾
-
randomString: 随机字符串,假数据
关联
概念: 一个取样器, 可以渠道另一个取样器里的数据. 在第一个取样器获得完整的数据, 然后通过后置处理器, 提取出感兴趣的内容, 作为变量, 再在第二个取样器中使用
- 同一个线程使用关联
- 使用提取器获取到内容, 存为变量
- 在后续的取样器中, 使用
${变量名称}使用
- 不同线程组使用关联, 不同线程之间变量不共享, 需要通过
properties属性进行共享- 在线程组A中使用
BeanShell后置处理器添加setProperties函数使用 - 在线程组B中使用函数
properties函数提取属性为变量
- 在线程组A中使用
参数化: k-v结构
- 测试计划参数化: 数据量只有1个
- 前置处理器参数化(用户参数): 数据量较少
- 配置参数化, (配置元件): 数据量很大
断言
- 响应断言: 响应体, 响应头, 响应码,… 包含, 等于, 匹配, …
- 大小断言: 响应头, 响应体的字节大小
JSON断言: 根据返回的json对象, 匹配对应的值XPATH断言
逻辑控制
-
种类
-
if
-
事务
-
循环
-
while
-
forEach: 配合配置原件的
用户定义的变量, 前置处理器中有多个参数 -
Include: 读取其他jmx文件, 作为取样器
-
Runtime: 重复执行, 持续一定时间
-
临界部分控制器
-
交替控制器
-
只执行一次
-
随机控制器: 一组中随机一个
-
随机顺序执行: 一组不同顺序执行
-
吞吐量控制: 按照给定的吞吐量控制
-
switch控制: 根据下标或者名称使用其下的其中一个取样器
-
模块控制器: 与测试片段一起使用
-
测试原件
测试片段: 相当于一个文件夹, 可以存放各种元件, 测试片段不会被执行.
如果要执行测试片段, 需要结合逻辑控制器-模块控制使用

链接数据库
元件: JDBC Connection Configuration
- 准备
mysql_connrct_java.jar驱动 - 打开mysql 服务,
- 新建元件
JDBC Connection Configuration, 连接数据库
- 新建取样器:
JDBC请求, 输入配置, 可以输入数据库执行语句 增删改查, 可以将结果保存
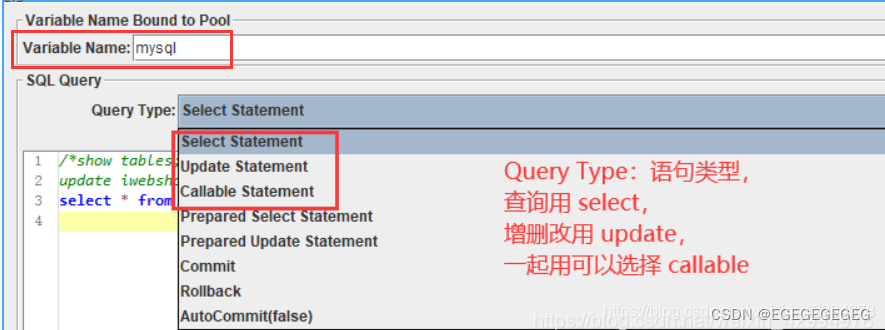
- 新建
Bean Shell取样器, 验证是否可以取出变量
log.info(vars.getObject("result").get(0).get("name"));
log.info(vars.getObject("result").get(0).get("age").toString());
- 新建
HTTP请求取样器, 验证下是否可以在请求中 使用这两个值
Jmeter的非GUI(界面)方式运行
-
执行运行
JMX文件的命令:jmeter -n -t mysql.jmx -l-n是非界面方式运行 ;-t指定jmx文件的位置;-l: 指定生成结果的文件格式.jtl;-e: 生成HTML报告;-o: 指定HTML报告的 文件夹 , 文件夹必须是一个空目录
-
使用
Jmeter + Ant + Jenkins实现持续集成-
下载Ant, 解压后将
ant的 bin目录加到环境变量path中 -
需要一个
build.xml文件,放到和jmx文件目录 -
配置全局配置文件:
jemter.properties中的jmeter.save.saveservice.output_format=xml -
ant构建jmeter报错:taskdef class org.programmerplanet.ant.taskdefs.jmeter.JMeterTask cannot be found将
${apache-jmeter}/extras 文件夹下的 ‘ant-jmeter-1.1.1.jar’ 文件复制到 ${apache-ant-}\lib文件夹下
-
分布式
- 构成
- 控制机
- 执行机
- 原理:
- 执行机监听 网卡端口, 等待接受测试命令
- 控制及链接执行机, 发送测试命令
- 流程:
- 准备几个机器, 并且安装同版本的jdk, Jmeter
- 修改全部机器的
jmeter.poperties配置表, 注意端口设置(同一机器测试分布式时), 修改ssl设置等于true, - 主机设置远程执行机IP, 端口配置:
- 将全部机器的
jmeter-server.bat启动, 启动Jmeter服务 - 启动主控机的GUI图形界面
jmeter.bat, 线程组设置并发后, 执行接口测试, 可以在结果树中查看线程名称的主机IP+Port, 可以看到有执行机的运行
Jmeter接口测试调试方案
- 通过
查看结果树里边的请求信息和响应信息调试 - 使用
调试取样器 Jmeter结合fiddler实现请求, 在没有接口文档, 只能通过抓包去获取接口信息的时候使用
Jmeter中的Bean shell组件和语言规则
Bean shell 是一种完全符合java语法规则的语言, 同时有自己的语法规则
Jmeter有哪些Bean shell:
- 前置处理器:
Bean Shell前置预处理程序 - 定时器:
Bean Shell定时器 - 取样器:
Bean Shell处理器 - 后置处理器:
Bean Shell后置处理程序 - 断言:
Bean Shell断言
Bean Shell的内置的变量和语法规则
作用: 增加一些临时的代码需求, 加密,
-
打印, 输出:
log.info("hello lijiang"); // 在结果输出 System.out.println("hello java console"); // 在cmd控制台输出 -
vars变量:JmeterVariables, 操作Jmeter变量- 用户定义的变量
- 正则表达式,
JSON提取器 - 定义的变量
vars.get("var_key");: 获取变量的值vars.put("var_key", "var_value");: 设置变量的值 -
porps: 存储Jmeter的全局静态变量(其实就是jmeter的配置文件中的变量)(可以跨线程)props.get("conf_name");props.pet("conf_name", "conf_value"); -
prev: 获取前边取样器的值## 获取前边取样器的值 log.ingo(prev.getResponseCode()); log.info(prev.getResponseDataAsString()); -
ctx: 获取到上下文的变量ctx.getProperties();获取上下文全部的变量
Day8 移动测试
1. 移动测试
主要是手机app
测试的内容:
- 功能测试:
- 安装卸载测试
- 升级测试
- 兼容性测试:
- Android, IOS
- 厂商的二次开发
- 不同的分辨率
- 不同的网络
- 网络切换, 中断测试
- 使用过程中 来电话,短信
- 横竖屏切换
- 健壮性: 耗电量, 流量消耗, 崩溃回复
2. 安装
- Java jdk
- android sdk / android studio
- appium
- 夜神模拟器
java jdk 和 android sdk要加入环境变量
3. adb 命令
通过命令操作手机
abd devices: 查看链接的设备
adb shell: 进入adb 命令行
adb shell getprop ro.build.version.release : 获取手机android版本
adb shell dumpsys window windows | findstr mFocusedApp: 获取手机当前运行的程序和界面的名称
adb push: 文件传输,. 电脑 -> 手机
adb pull: 手机上的文件 -> 电脑
adb install 应用名: adb安装应用
adb uninstall 应用名: adb卸载应用
4. 入门案例
from appium import webdriver
import time
# 链接设备所需的参数
desired_caps = {}
# 系统
desired_caps['platformName'] = 'Android'
# 系统版本
desired_caps['platformVersion'] = '7.1'
# 当前设备名
desired_caps['deviceName'] = '127.0.0.1:62001'
# 要启动的app名称(app唯一标识/包名) , 通过 shell dumpsys window windows | findstr mFocusedApp 命令获取
desired_caps['appPackage'] = 'com.android.browser'
# 要启动的app的那个界面
desired_caps['appActivity'] = '.BrowserActivity'
print(" start remote")
driver = webdriver.Remote('http://127.0.0.1:4723/wd/hub', desired_capabilities=desired_caps)
time.sleep(5)
driver.close_app()
print(" close app")
driver.close()
5. Appium 基础操作
-
driverterminal(包名): 关闭打开的应用quit(): 断开连接install_app('绝对路径'): 安装appremove_app('应用包名'): 安装appis_app_installed('应用包名'): 判断应用是否安装push_file(目标位置): 上传文件pull_file(来源位置): 拉取文件page_source: 获取界面xml源码find_element...: 获取元素find_elements...: 获取多个符合的元素current_package(): 当前操作的应用的包名current_activity(): 当前操作的界面名称
-
elementtext(): 获取元素文本click(): 点击元素对应位置get_attribute('属性名'): 获取属性值location(): 获取元素左上角的坐标(相对于屏幕左上角)size(): 获取元素的宽高
from appium import webdriver
import time
# 链接设备所需的参数
desired_caps = {}
# 系统
desired_caps['platformName'] = 'Android'
# 系统版本
desired_caps['platformVersion'] = '7.1'
# 当前设备名
desired_caps['deviceName'] = '127.0.0.1:62001'
# 要启动的app名称(app唯一标识/包名)
desired_caps['appPackage'] = 'com.android.settings'
# 要启动的app的那个界面
desired_caps['appActivity'] = '.Settings'
print(" start remote")
driver = webdriver.Remote('http://127.0.0.1:4723/wd/hub', desired_capabilities=desired_caps)
time.sleep(5)
driver.terminate_app('com.android.browser')
print(" close app")
driver.quit()
driver.find_element_by_xpath("//*[@text='显示']").click() 找界面中text是 显示 的元素点击一下
7. 输入文本
有些元素可以接受文本输入
-
send_keys(文本内容): 可以输入文字, 如果中文无法输入, 可以加上以下两个设置desire_caps['unicodeKeyboard'] = True # unicode设置(允许中文输入) desire_caps['resetKeyboard'] = True # 键盘重新设置如果对同一个元素, 多次调用该方法, 会先一个一个删除掉原有内容, 再输入
-
clear()
8. 手势操作
页面滑动有惯性机制, 回根据按下, 抬起的位置 以及 总的时间, 滚动的不一样的距离
-
滚动:
swipe(self, startx, starty, endx, endy, duration: int=0)- 注意duration 默认600毫秒, 会影响实际滚动的距离.
click()方法点击的是元素的位置, 而不是元素. 在获取到位置的时候, 可以经过滑动, 位置发生了变化, 可能优点不准. 需要有一定睡眠时间, 等待滑动结束
-
scroll(origin_el, destination_el, duration): 直接传递元素 作为 参数即可, 不需要手动获取位置scorll底层实现 和swipe有一些区别, 没有中间的采样点, 只有起始, 结束, 但是效果和swipe一样 -
拖拽: 拖拽等于按下, 等待一定时间松手
drag_and_drop(origin_el, destination_el) -
TouchAction: 构建相对比较复杂, 连续的行为-
创建
TouchAction对象, 需要把driver作为参数传递; 然通过各种方法添加动作; 执行操作perform(), 类似于鼠标操作 -
方法:
-
press(self, ele, x, y, pressure): 按下动作; 如果传了ele,x, y可不传;pressure是IOS专用的 -
long_press(self, el, x, y, duration=1000): 长按动作; 如果传了ele,x, y可不传 -
move_to(self, el, x, y): 长按动作; 如果传了ele,x, y可不传 -
wait(self, ms): 等待动作; ms 等待时间, 毫秒, 默认600ms -
release(): 松开动作 -
tag(self, el, x, y, count=1): 轻敲; tag 和 click()的区别: click()有延迟出发效果(为了检验是不是双击);tag(el, count=2)可以模拟双击 -
action.press(ele1).wait(500).move_to(ele2).wait(2000): 在移动过程中, 两个位置中间一定要加一个wait()
-
-
9. driver 其他操作
device_time: 获取手机时间get_window_size(): 获取屏幕大小network_connection: 手机网络信息;1 - 飞行模式;2 - wifi;4 - 移动数据;6 -2+4; wifi+移动数据set_network_connection: 设置手机网络信息keyevent(): 点击按键get_screenshot_as_file/save_screenshot(图片路径): 截屏, png格式open_notifications(): 打开通知栏
Day10 RobotFramework
1. 简介
RF是一个基于Python语言, 开放的, 可扩展的, 以关键字驱动模式的自动化测试框架
关键字驱动: 把项目中的业务逻辑封装成一个一个关键字, 然后调用不同关键字组成不同的业务
数据驱动: 数据驱动是把测试数据放到excel, yaml文件里边, 然后通过改变文件中的数据去驱动测试用例执行
特点:
- 编写用例非常方便, 常见的有
txt,robot - 自动化生成html报告
- 非常强大的扩展库
- 根据项目的需求自定义关键字
- 支持非GUI的方式运行, 以及和Jenkins实现持续集成
2. 安装
- 安装robotframework:
pip install robotframework==3.1 - 安装RIDE开发工具:
pip install robotfframework-ride
3. RIDE工具
如果没有创建桌面快捷启动, 在[PythonPath]\Scripts\, 打开命令窗口, 运行 python ride_postinstall.py, 弹出窗口点确定
- 新建一个项目, 选择类型: 文件夹
- 创建代码分类文件夹
- 创建测试套件
- 创建测试用例
- 创建资源文件(在文件夹目录下, 类型选择txt格式), 资源文件下可以创建很多 用户自定义关键字, 资源文件可以在测试套件中导入并在测试套件中调用自定义关键字
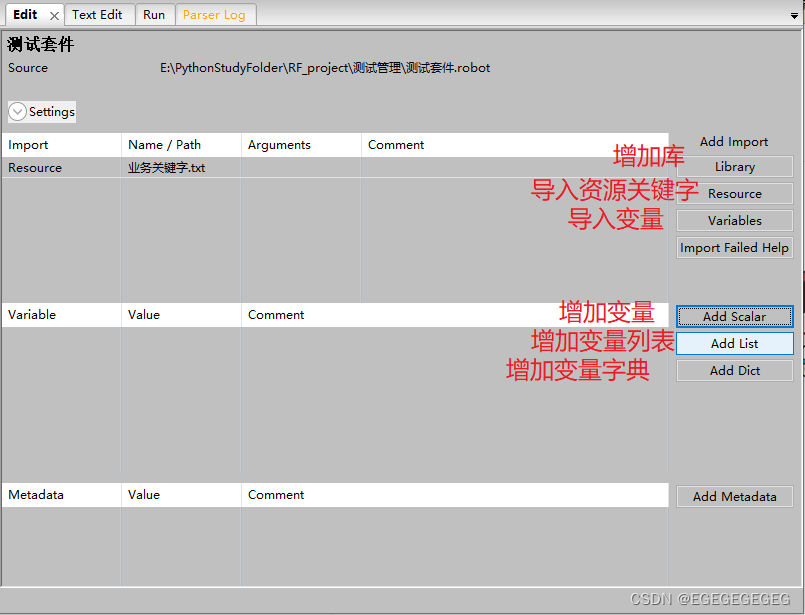
4. robotframework常用的库
-
标准库(RF自带库):
E:\JavaStudyFolder\zz-python\Lib\site-packages\robot\libraries- Builtin: 测试库
- Collections: 集合
- DateTime: 日期时间
- Screenshot: 屏幕截屏
-
扩展库(pip 命令安装的库):
E:\JavaStudyFolder\zz-python\Lib\site-packages-
Web自动化测试:
SeleniumLibrary,Selenium2Library,安装命令:
pip install robotframework-seleniumlibrary -
接口自动化测试:
RequestsLibrary安装命令:
pip install robotframework-requests -
App自动化测试:
AppiumLibrary安装命令:
pip install robotframework-appiumlibrary
-
5. 常用关键字
快捷键:
-
F5: 打开关键字 -
F8: 运行测试用例 -
Ctrl+Shift+Space: 自动补全关键字
常用关键字:
log/Log: 打印日志, 第三格加WARN, 就是加警告日志Comment: 注释某行操作${变量名} \t Set Variable \t 变量值Get Time: 获取时间Catenate: 链接字符串

复杂关键字:
-
列表两种形式:
${list} \t Create List \t ele1 \t ele2 ....,@{list2} \t Create List \t ele1 \t ele2 ...., 后者一般用于遍历 -
取列表元素 :
${list[idx]}: 取列表元素要用$ -
字典:
Create Dictionary,Get Dictionary Keys,Get Dictionary Values,${value_to_name} \t Get From Dictionary \t ${dict1} \t name -
直接执行python 函数:
${rand_num} Evaluate random.randint(1,100) modules=random log ${rand_num} -
直接执行python 自定义函数
import Library E:/PythonStudyFolder/sum.py ${a} Evaluate int(10) ${b} Evaluate int(21) ${sum} sum ${a} ${b} ${sum1} sum ${a} ${rand_num} Log ${sum},${sum1}
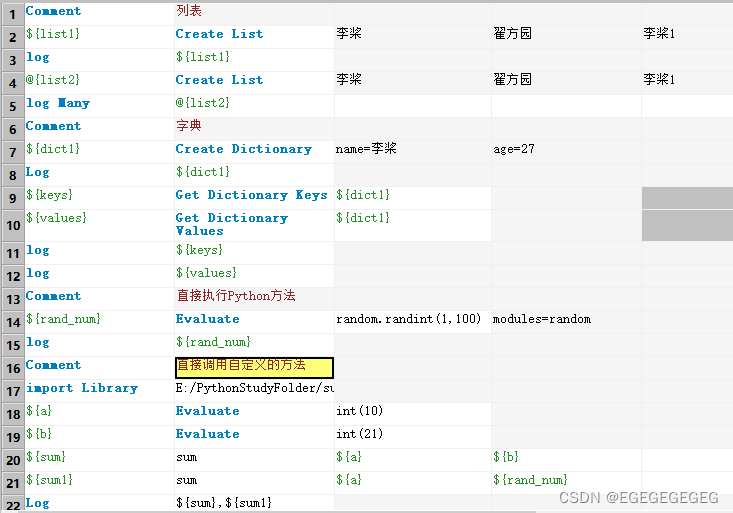
Starting test: RF project.测试管理.测试套件.复杂关键字
20230714 10:23:46.797 : INFO : ${list1} = ['李桨', '翟方园', '李桨1']
20230714 10:23:46.799 : INFO : ['李桨', '翟方园', '李桨1']
20230714 10:23:46.802 : INFO : @{list2} = [ 李桨 | 翟方园 | 李桨1 ]
20230714 10:23:46.804 : INFO : 李桨
20230714 10:23:46.805 : INFO : 翟方园
20230714 10:23:46.805 : INFO : 李桨1
20230714 10:23:46.811 : INFO : ${dict1} = {'name': '李桨', 'age': '27'}
20230714 10:23:46.813 : INFO : {'name': '李桨', 'age': '27'}
20230714 10:23:46.815 : INFO : ${keys} = ['age', 'name']
20230714 10:23:46.818 : INFO : ${values} = ['27', '李桨']
20230714 10:23:46.820 : INFO : ['age', 'name']
20230714 10:23:46.823 : INFO : ['27', '李桨']
20230714 10:23:46.828 : INFO : ${rand_num} = 83
20230714 10:23:46.830 : INFO : 83
20230714 10:23:46.834 : INFO : ${times} = 1689301426.8329048
20230714 10:23:46.842 : INFO : 1689301426.8329048
20230714 10:23:46.857 : INFO : ${a} = 10
20230714 10:23:46.859 : INFO : ${b} = 21
20230714 10:23:46.861 : INFO : ${sum} = 31
20230714 10:23:46.863 : INFO : ${sum1} = 93
20230714 10:23:46.865 : INFO : 31,93
Ending test: RF project.测试管理.测试套件.复杂关键字
流程控制:
Run Keyword If
${score} Set Variable 90
Run keyword If ${score}>=80 log 成绩优秀
... ELSE IF ${score}>=80 log 成绩及格
... ELSE log 成绩不及格
循环:
Comment 循环结构
FOR ${a} IN 李桨 翟方园 翟方园2 李甜甜
Log ${a}
END
@{list1} Create List 李桨1 翟方园1 李甜甜1
FOR ${a} IN @{list1}
Log ${a}
END

FOR ${a} IN RANGE 1 11
Run Keyword If ${a} == 8 Exit For Loop
... ELSE IF ${a}>4 Log ${a}
... ELSE Continue For Loop
END

Starting test: RF project.测试管理.测试套件.流程控制关键字
20230714 10:59:09.549 : INFO : Continuing for loop from the next iteration.
20230714 10:59:09.552 : INFO : Continuing for loop from the next iteration.
20230714 10:59:09.556 : INFO : Continuing for loop from the next iteration.
20230714 10:59:09.559 : INFO : Continuing for loop from the next iteration.
20230714 10:59:09.565 : INFO : 5
20230714 10:59:09.569 : INFO : 6
20230714 10:59:09.571 : INFO : 7
20230714 10:59:09.573 : INFO : Exiting for loop altogether.
Ending test: RF project.测试管理.测试套件.流程控制关键字
6. Web自动化测试
1. 搭建web自动化测试环境
-
安装
SeleniumLibrary, 导入Selenium Library -
安装浏览器, 下载浏览器驱动, Edge浏览器, Edge浏览器驱动, 版本要保持一致, 将驱动程序放到有配置环境变量的地方(可以放到
[python_path]/bin) -
在测试用例中输入
OpenBrowser https://www.baidu.com edge, 看能否打开浏览器,如果打不开, 报错:
TypeError: __init__() got an unexpected keyword argument 'service_log_path', 可能是 selenium版本不对, 我这里本来安装的是selenium-4.10.0, 卸载掉换成selenium-4.9.1就可以打开
2. 打开浏览器的常用关键字
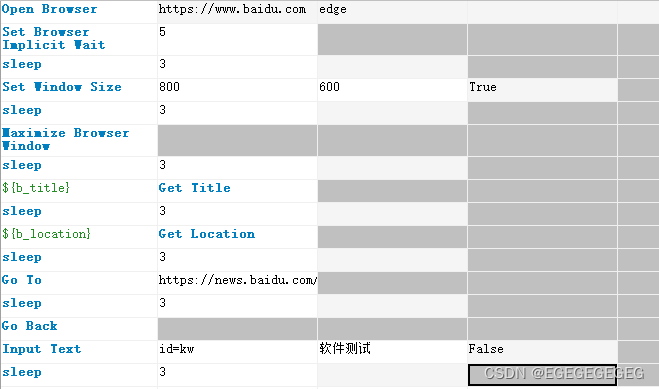
以上操作依次是:
1. 用edge浏览器打开 https:www.baidu.com
2. 智能等待5秒
3. 等待3秒
4. 设置浏览器窗口大小
5. 窗口最大化
6. 获取网页标题
7. 获取网页位置(url)
8. 转到网页 https://news.baidu.com
9. 返回到 上一层页面(百度一下)
10. 向id=kw的输入框 输入文本: "软件测试"
11. Reload Page 刷新页面
3. 网页元素操作
Input Text id=kw 美女: 向输入框输入${txt} \t Get Text \t id=su: 获取元素的文本内容(id=kw的元素)Clear Element Text \t id=kw: 清除输入框内容Click Element \t id=su: 点击元素Get Element Attribute \t id=kw \t class: 获取元素属性Select Frame 框架名/框架id: 切换框架, 要操作框架元素一定要进入要操作元素的框架Close Browser: 关闭浏览器
4. 元素定位
元素定位的前提: 元素属性要唯一
selenium: 八大元素定位
RF: id, name, link(链接文本), partial link(部分链接文本), class, tag, xpath, css, (identifier, dom, jquery
- identifier: 定位元素 集成了id和name, 只要某个元素id或name唯一, 都可以用identifie来定位
xpath :
- 通过绝对路径定位
- 通过相对路径定位
- 通过元素属性定位
- 通过元素部分属性定位
- 通过文本定位
注意: xpath直接右键复制, 为什么要写xpath方式:
-
因为很多元素都是动态的, 复制的
xpath可能定位不到 -
复制的
xpath性能比我们自己写的的性能要低如:
//*[@id='kw']:*是通配符, 匹配所有元素; 自己写的://input[@id='kw'] -
复制的
xpath很多时候比较复杂
7. 其他常用操作
框架切换
Select Frame 框架名/框架id: 切换框架, 要操作框架元素一定要进入要操作元素的框架Unselect Frame: 跳出当前框架
下拉框
-
Select From List By Index \t name=brand_id \t 3: 下拉框选中第4个元素, 下标从0开始 -
Select From List By Value \t name=brand_id \t 9: 下拉框选中value=9的元素 -
Select From List By Label \t name=brand_id \t 联想: 下拉框选中Label=联想的元素
定位完全一样的元素;
@{eles} \t GetWebElements \t xpath=//img[@src='images/icon_trash.gif']
Click Element \t ${ele[0]}
弹窗处理:
Handler Alert: 默认点击弹窗的确定
8. 企业中用RF做自动化的两种方式
1. 使用RF 做分层架构设计(PO设计模式)
分层: 元素层, 业务层, 用例层; 公共层
对应pycharm模块结构: 基础base模块, 页面模块, 测试用例模块; 外加公共函数
Q: 为什么要分层
1. 实现公共方法, 公共数据; 以及元素定位, 测试用例 和 业务逻辑代码分离, 方便集中管理
2. 实现数据驱动
3. 增加脚本的复用性 以及 可维护性
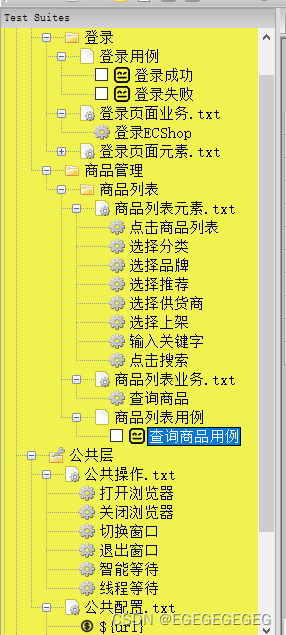
- 元素层
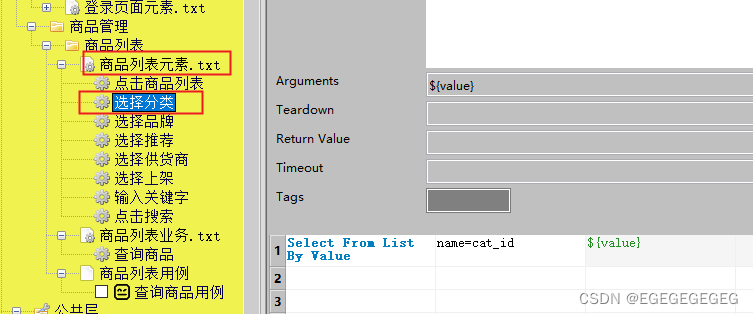
- 业务层
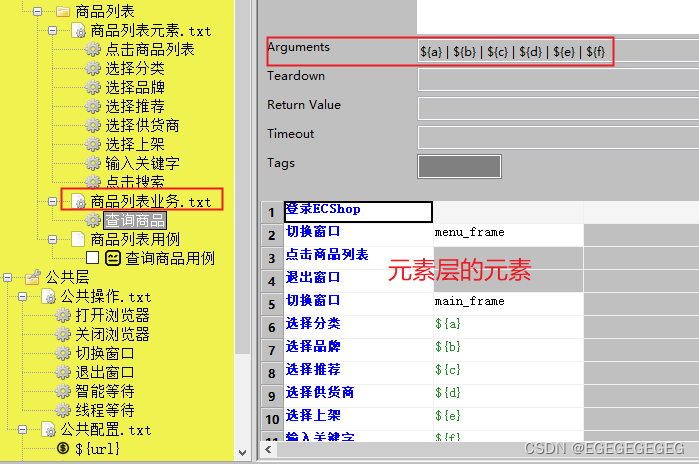
- 测试用例层
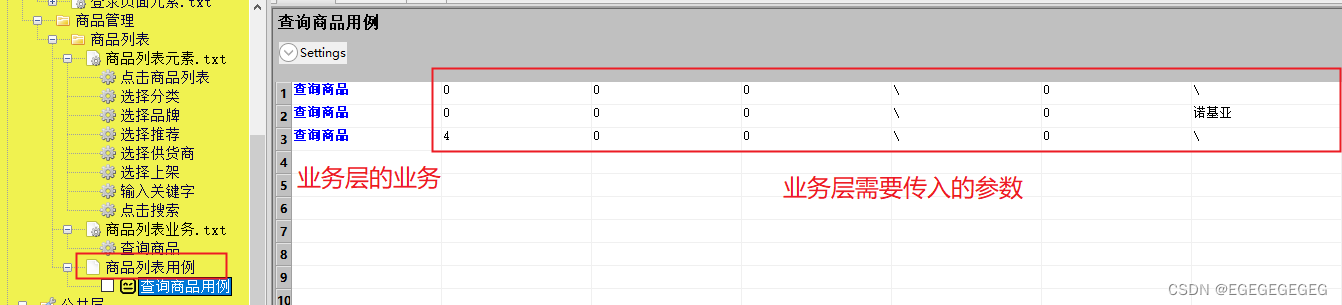
2. 使用pycharm + python + rf实现自动化测试(待研究)
9. RF代码实现非GUI方式运行
pybot -d 测试报告存放路径 项目路径
会生成三个文件: log.html, output.xml, report.html
10. RF 结合Jenkins 实现持续集成
- 打开
jenkins服务:java -jar jenkins.war, 启动成功后, 登录jenkins - 安装
rf插件, 在设置中选择管理插件, 搜索Robot Framework, 选到可安装的插件, 安装 - 新建一个项目,
rf_auto_project - 构建触发器:
Build periodically: 添加一个日程表:* * * * *

-
构建: 选择
windows batch command:pybot -d 报告生成路径 项目存放路径 -
构建: 选择
system Groovy script: 保证报告样式System.setProperty("hudsin.model.DirectoryBrowserSupport.CSP", "") -
构建后操作: 选择
Public Robot Framework test results公共RF测试报告, 点高级选项, 填上输出报告路径(就是上边的生成报告的路径); 填上输出的xml文件名:output.xml; 填上输出的html报告文件名:report.html; 填上输出的log.html报告文件名:log.html; 填上其他的文件:*.*; 最后设置一下 用例通过的百分比: 低于90%红色, 100%蓝色, 中间是黄色 -
保存项目配置
-
在项目列表界面 选中新加的RF项目, 右键Build
-
在Manager界面, 配置
Configure System, 有发送邮件的配置, 配置邮箱 的 很多配置, 就可以集成邮件发送了
11. 其他操作
执行js脚本的关键字:
多窗口处理
鼠标键盘事件
断言
发送电子邮件
Day 11 ApiPost
1. Apipost介绍
ApiPost-Api 管理工具, 相比Postman, 更适合国内开发者操作习惯, 学习成本低, 快捷文档分享, 多人实时协作, 调试次数无限, 项目接口无限, Mock次数无限
围绕api工作常用的工具: API Swagger, Postman, Mock.js, Jmeter
Apipost的 四大核心模块:
API设计: 用于接口还没开发完成时, 预定义接口请求参数 和 响应期待(Mock), 并自动生成Mock URL, 让前端和测试提前进入研发流程… *Apipost7开始, 支持可视化的KSON-Schema*方式生成响应期望(Mock)数据结构API调试: 用于接口开发过程中 或者 开发完成即将交付时, 进行初步的接口测试, 校验接口是否符合规范;Apipost7开始, 支持http,websocket,grpc类型的接口调试, 并且预先(后置)执行脚本以及断言语法 !00%兼容Postman- 自动化测试: 用于接口开发完成交付后, 测试人原进行复杂场景的自动化测试工作, 从而发现一些问题;
Apipost7开始, 自动化测试支持类Jmeter的条件控制器, 循环控制器, 等待控制器, 全局断言控制器, 以及脚本控制器等 API文档: 用于快速生成标准, 美观的接口文档. 并支持在线HTML,Markdown,Word等格式;Apipost7开始, 支持上传自动逸文档logo
特点:
- 完全支持离线使用
- 可视化Mock
- 支持HTTP调试
- 支持gRPC调试
- 支持WebScoket调试
- 多场景自动化调试
- 轻量交互
2. Apipost下载安装
直接官网下载客户端就好
3. Apipost快速入门
4. Apipost中变量的使用
设置环境变量, 单个环境中才能使用的变量
-
在脚本中:
// 设置环境变量 api.environment.set("keyname", "value"); // 获取环境变量 let name1 = api.environment.get("keyname"); console.log(name1) // 删除环境变量 api.environment.delete("keyname"); -
选到环境的预览按钮, 在其中可以增加环境变量
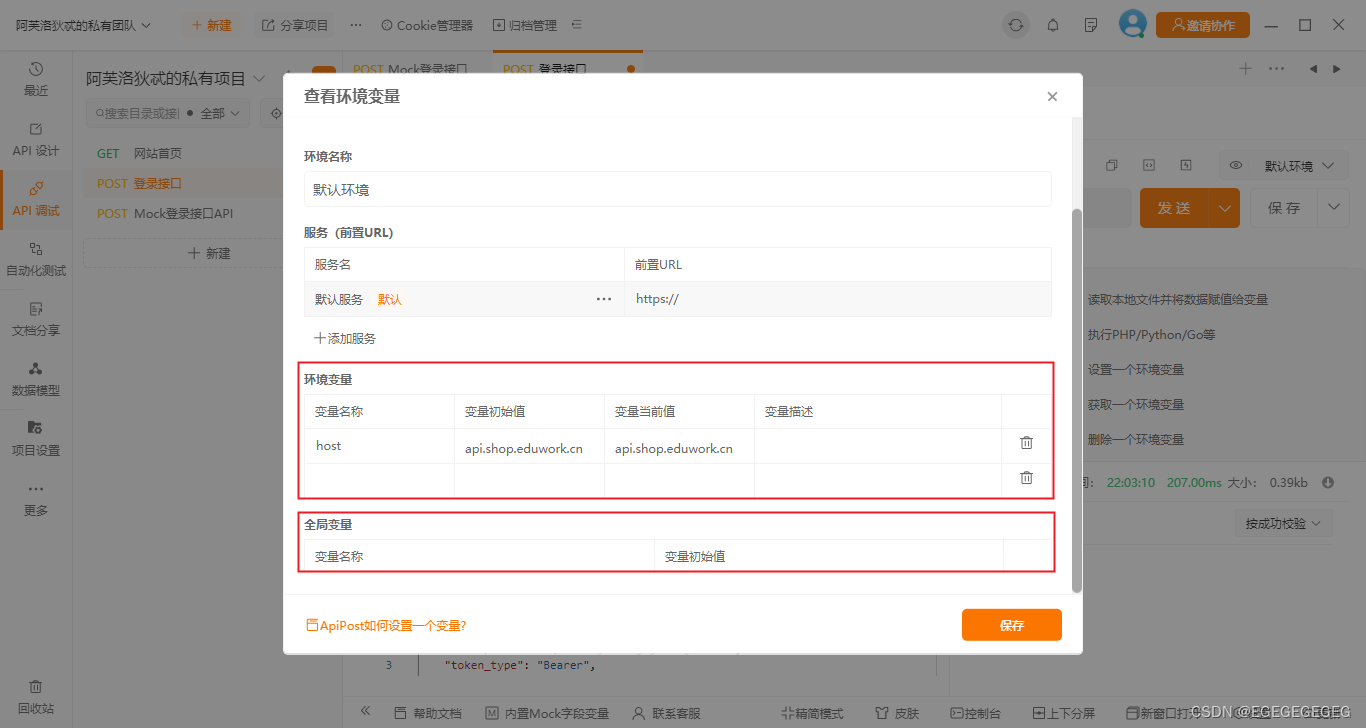
- 在使用的地方
{{变量名}}即可使用
设置全局变量, 不分环境, 都可以使用全局变量
- 在脚本中:
// 设置全局变量
apt.globals.set("varname", "valuename");
// 获取环境变量
let name1 = apt.globals.get("keyname");
console.log(name1)
// 删除环境变量
apt.globals.delete("keyname");
待续…


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









