









前言
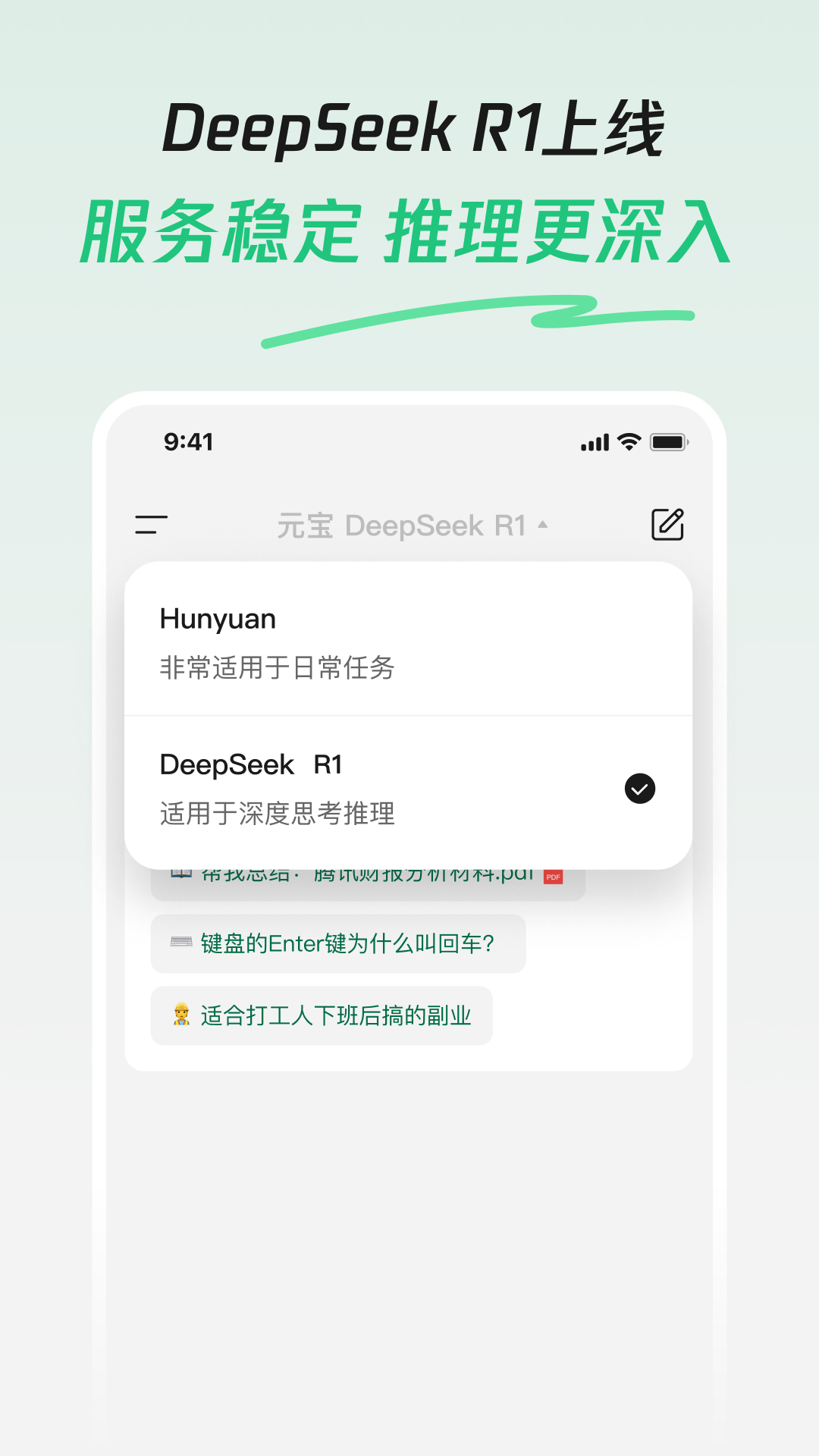
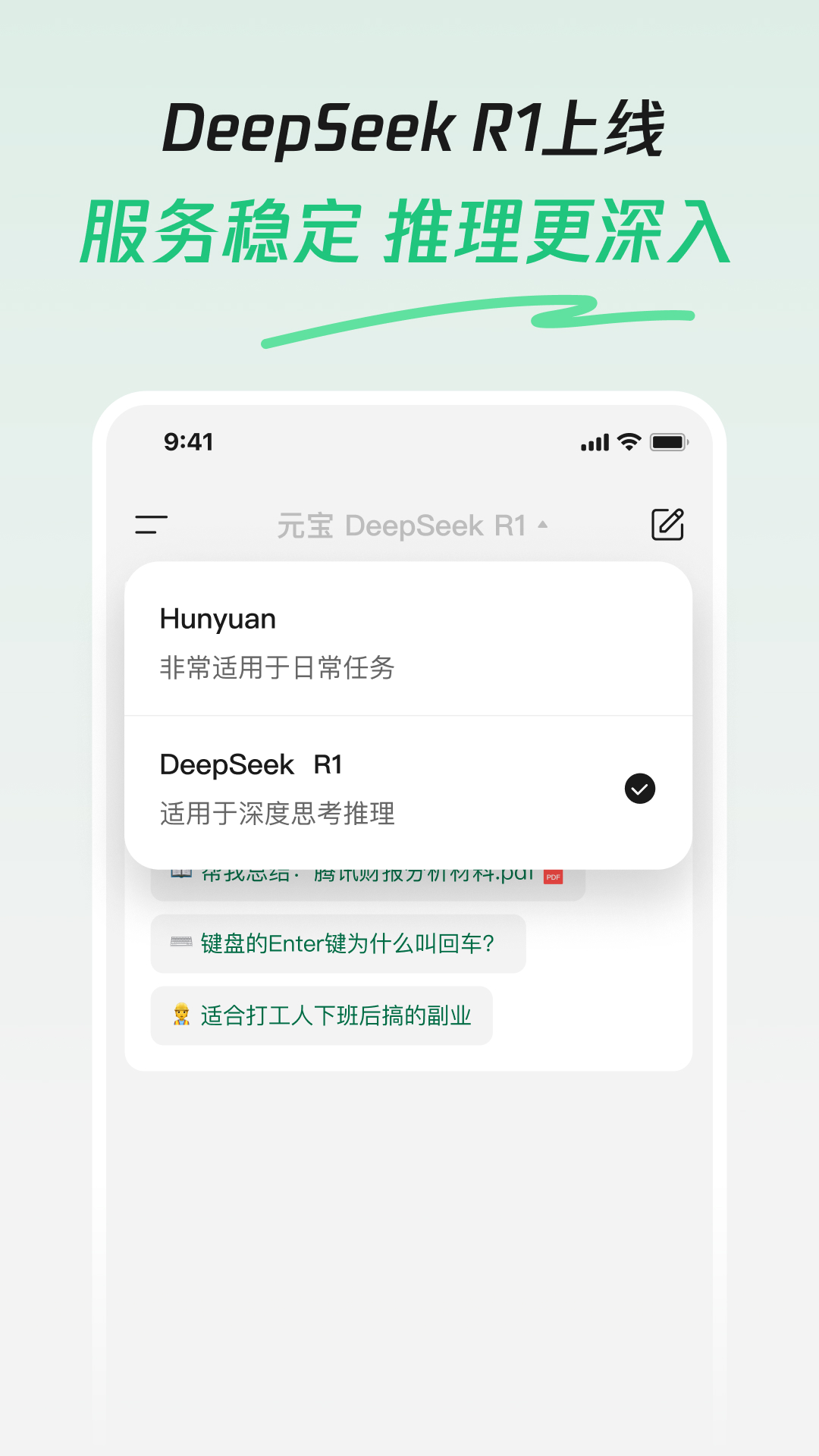
腾讯元宝AI产品于2025年2月13日在应用商店发布更新,正式接入了DeepSeek R1模型,并宣布该模型已联网、满血上线,DeepSeek+腾讯混元,好用不卡机。
腾讯元宝介绍
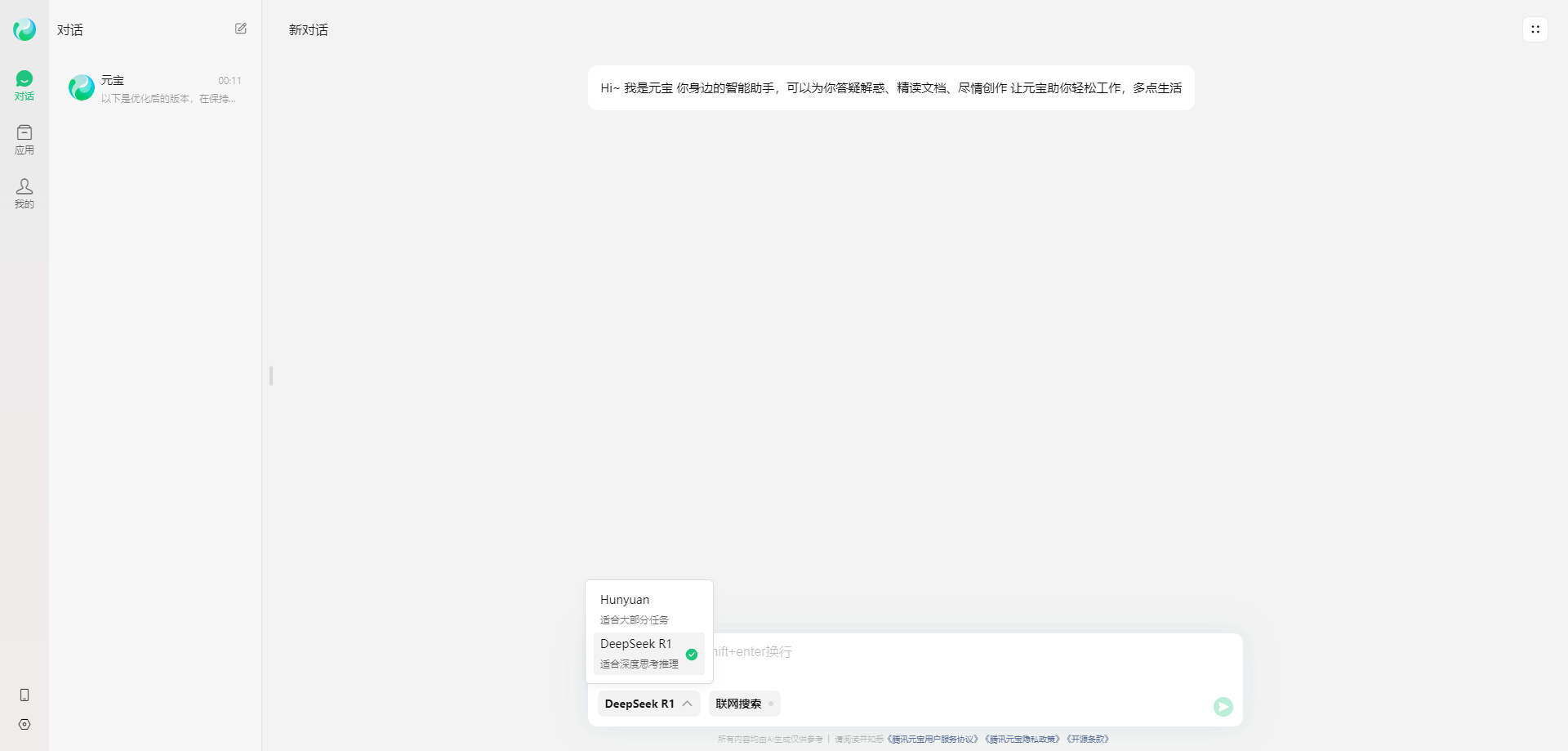
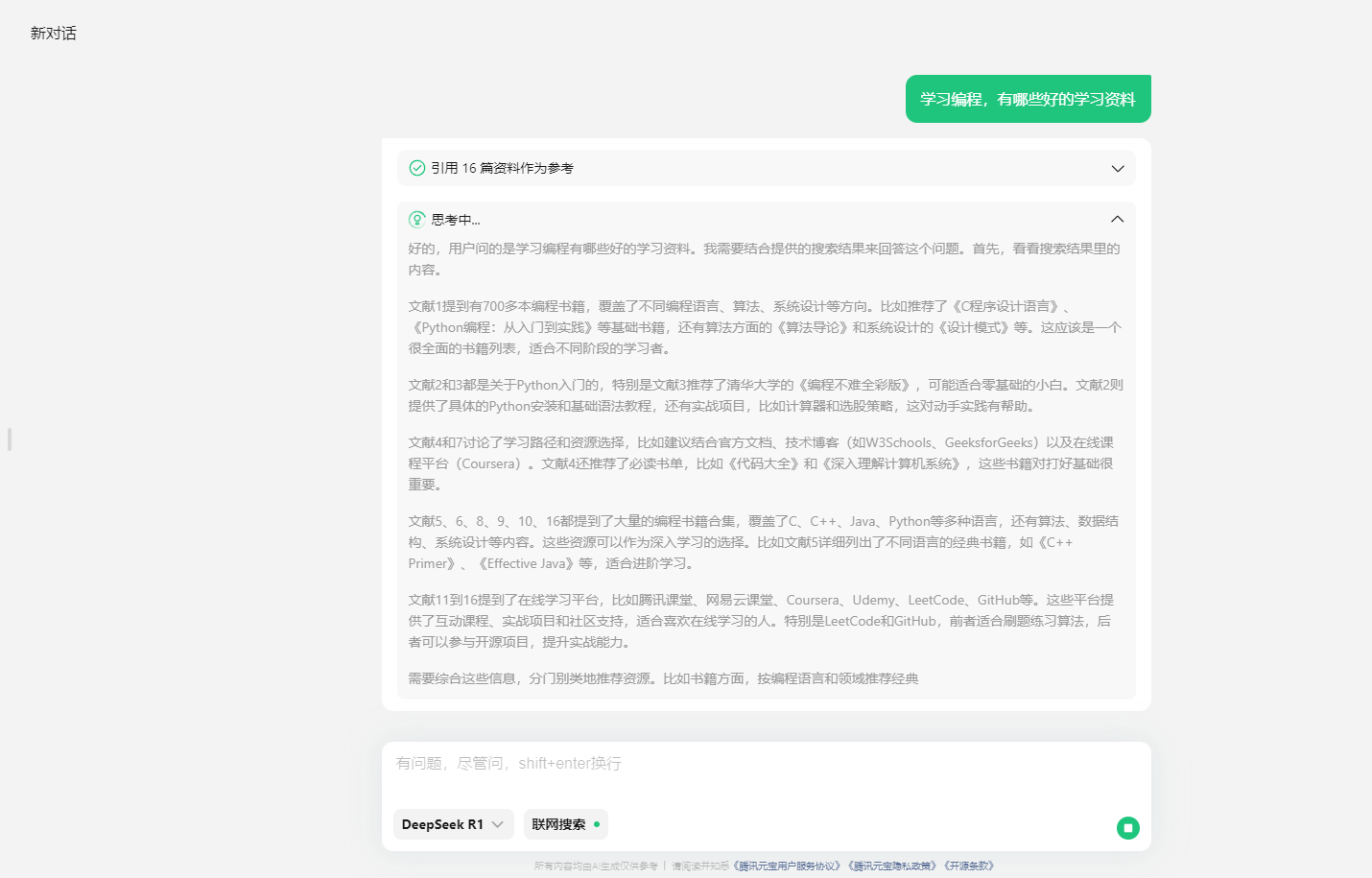
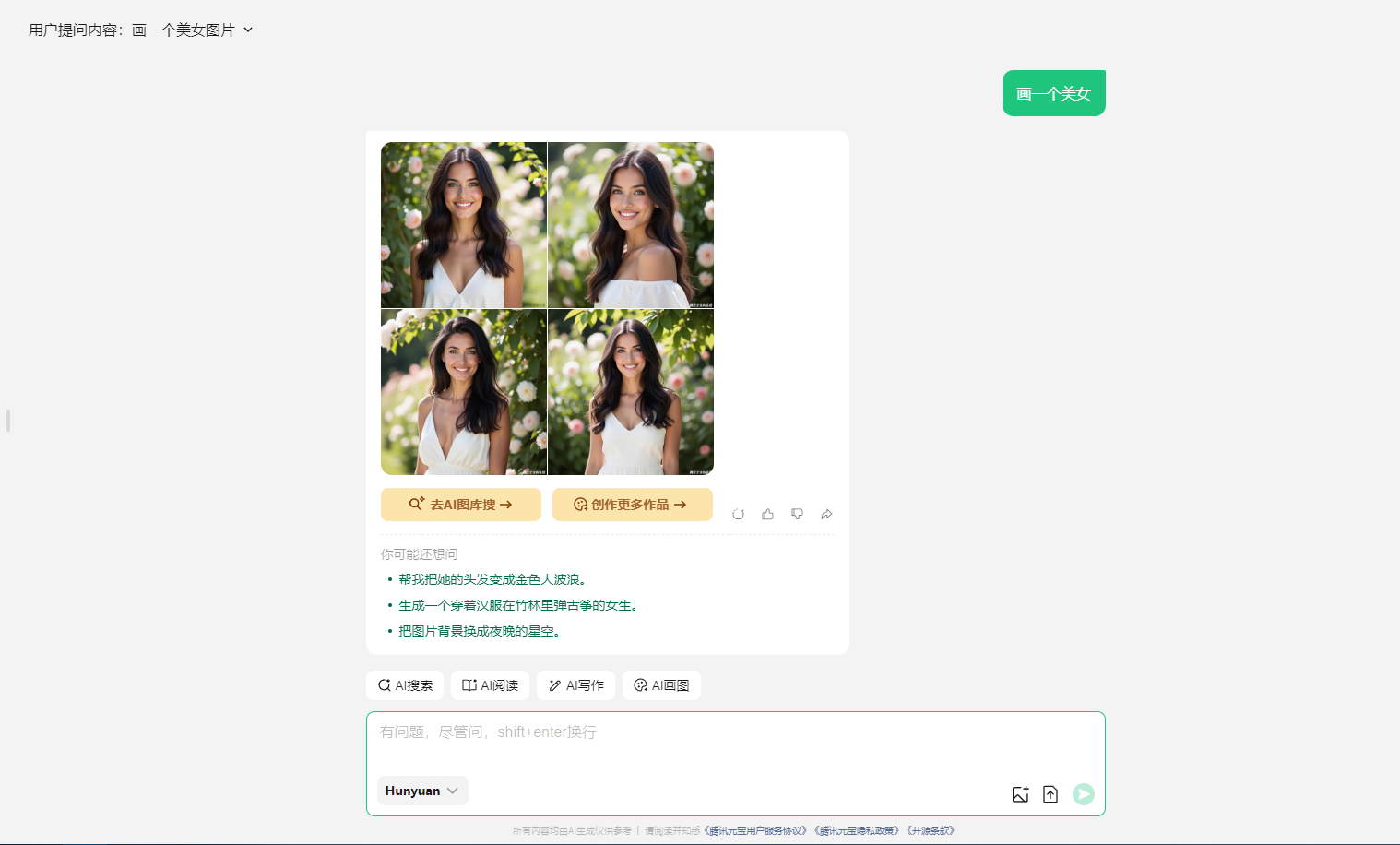
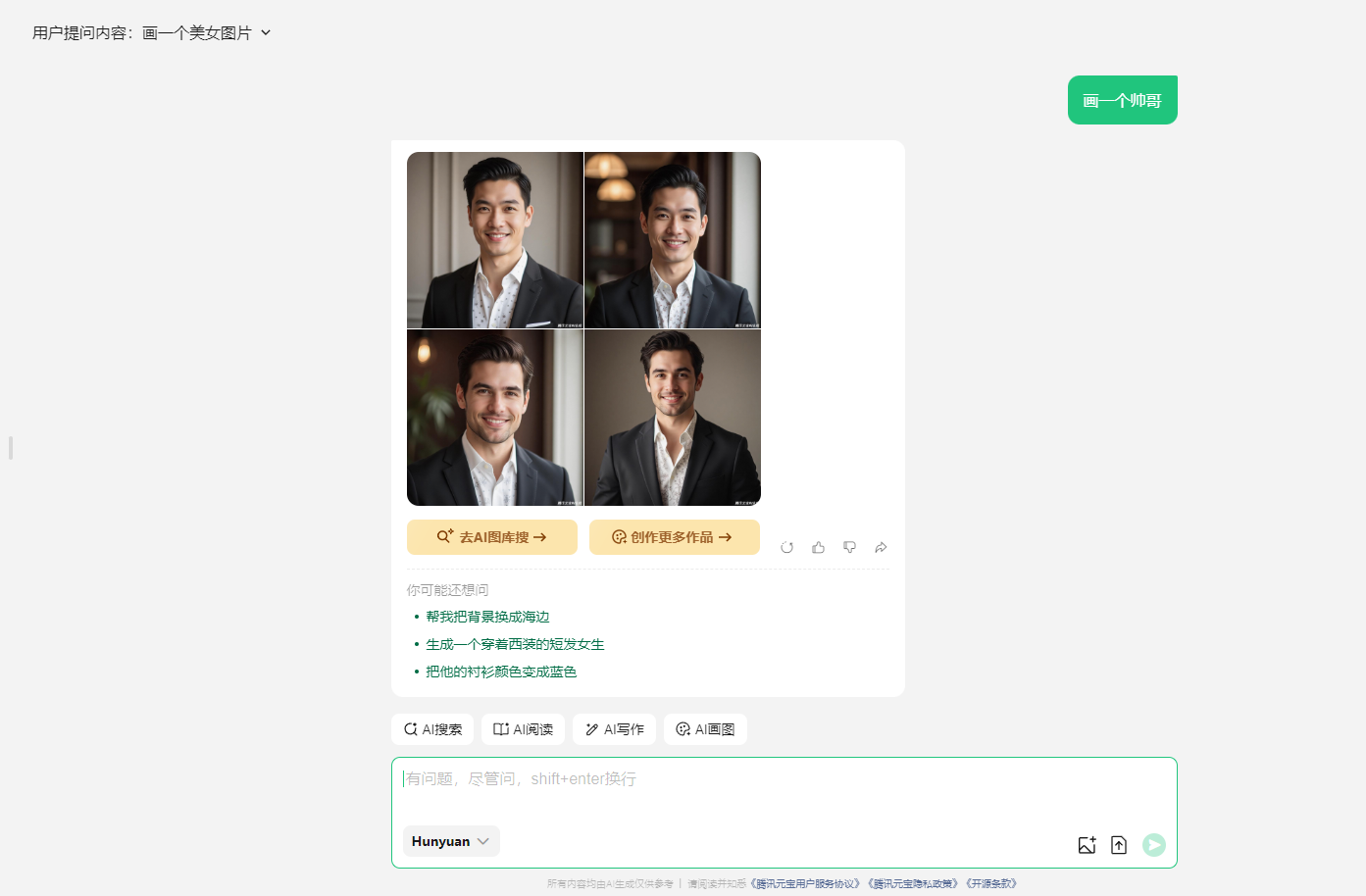
腾讯元宝是依托于腾讯混元、DeepSeek等大模型,基于跨知识领域和自然语言理解能力的大模型AI产品。元宝期望通过AI能力帮助用户在逻辑推理、职场办公、知识学习、趣味创作、生活百科等多个领域提高效率和生活辅助,感受 AI 带来的全新体验。同时,通过联网搜索信息,腾讯元宝能够确保推理和回答的时新性和权威性。
-
访问地址:https://yuanbao.tencent.com/chat
DeepSeek R1模型
腾讯混元模型
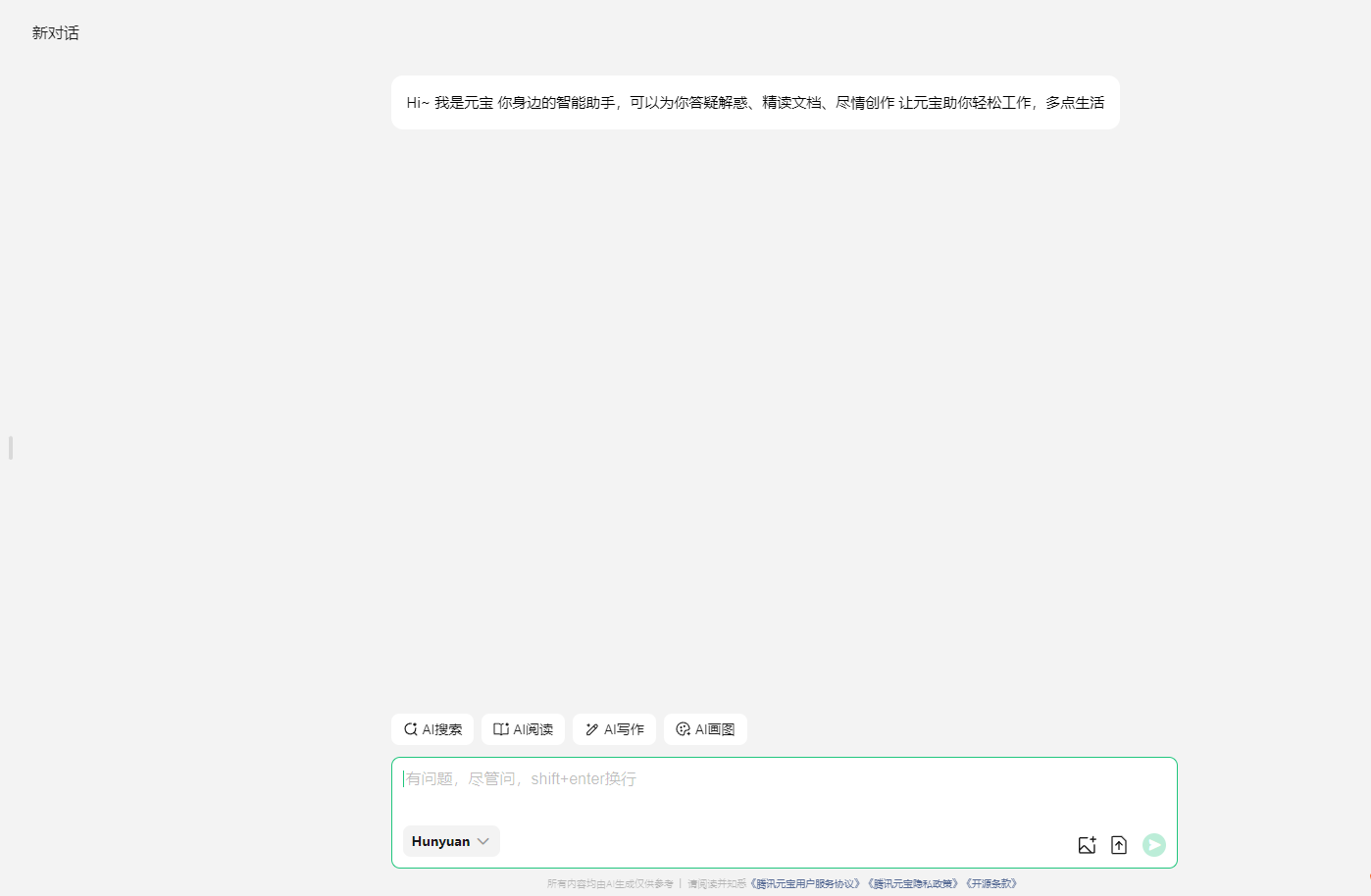
产品功能


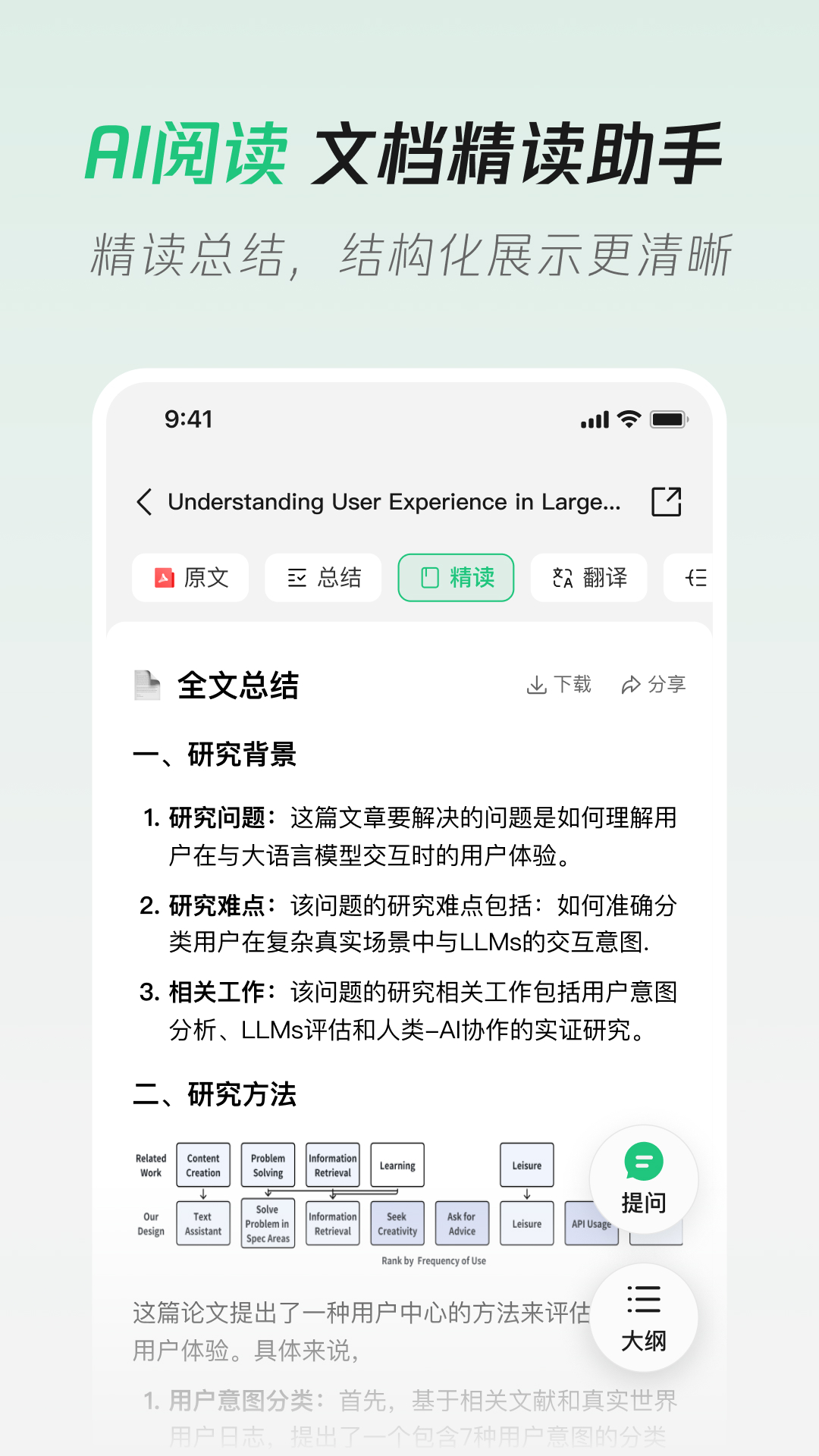
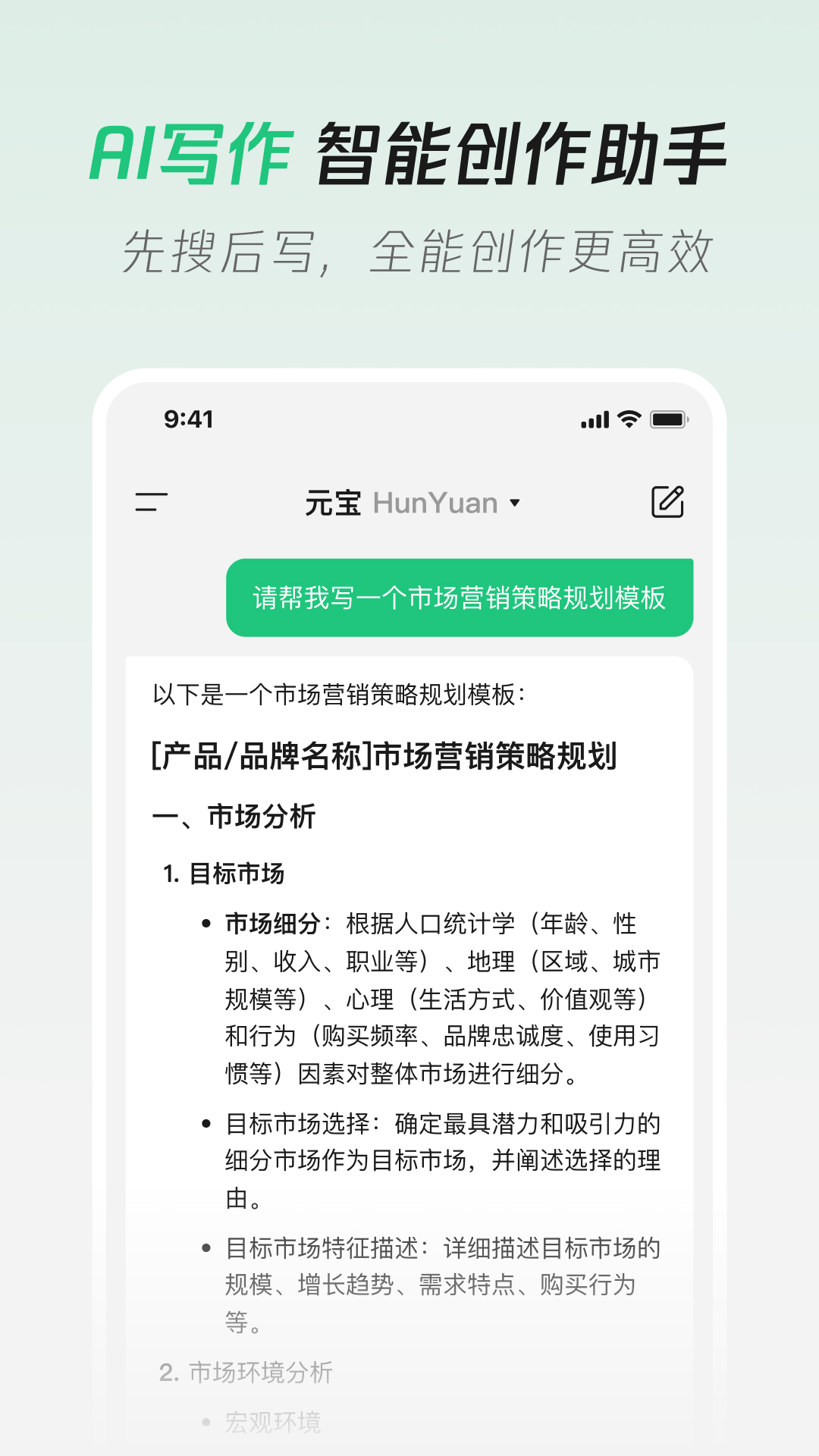
AIGC&AI赋能
-
https://github.com/YSGStudyHards/DotNetGuide

DeepSeek从入门到精通免费教程
-
DeepSeek官方访问地址:https://chat.deepseek.com
公众号「追逐时光者」回复关键字领取下载链接:DeepSeek

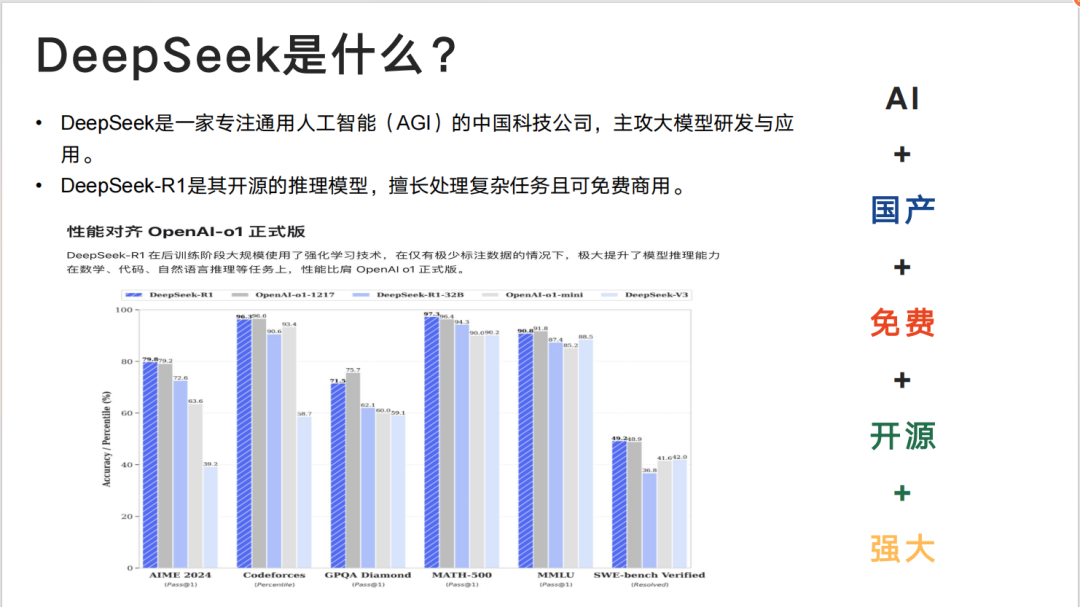
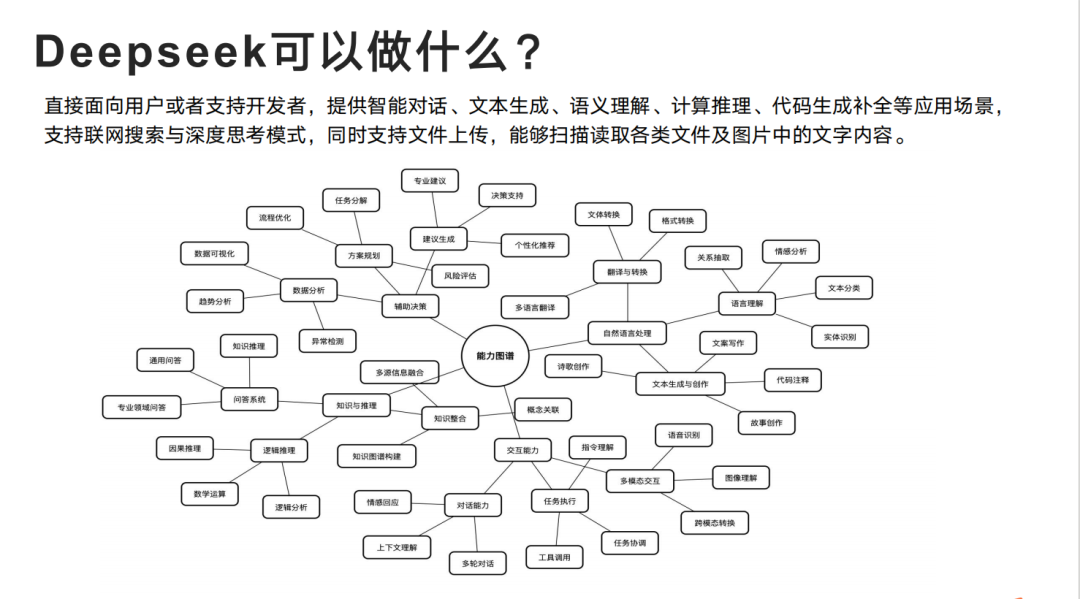
DeepSeek应用场景
-
智能办公:自动生成会议纪要、撰写商业文书、数据分析报告。
-
教育辅助:个性化习题讲解、学习方案定制、论文润色。
-
开发支持:代码自动补全、技术文档生成、系统设计建议。
-
商业分析:行业研究报告生成、竞品分析、市场趋势预测。
-
客户服务:7×24智能问答、工单自动分类、多轮对话接待。
-
等等等......。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











