





对人脸关键点检测的初步了解
参与ARM公司俱乐部技术组内部竞赛,从零学起。
基本要求:检测占据原图大小的一张人脸的相应关键点
项目参考网址:https://www.kaggle.com/c/facial-keypoints-detection
1. 人脸关键点检测方法
大致分为三种:
(1) 传统方法:ASM(Active Shape Model)和AAM(Active Apperance Model)。
(2)基于级联形状回归的方法。
(3)基于Deep Learning。
显然目前深度学习应用最为广泛,效果也最好,这也是目前ARM俱乐部正在进行学习的内容。
2. DCNN (Deep Convolutional Network)
\hspace{1.5em}
2013年,CNN首次应用于人脸关键点检测。DCNN属于级联回归方法,由3个level构成。其中,Level-1由3个CNN构成;Level-2、3均由10个CNN组成。

\hspace{1.5em}
上图源自2013年CVPR的一篇利用深度学习做人脸特征点定位的paper:《Deep Convolutional Network Cascade for Facial Point Detection》。
论文主页:http://mmlab.ie.cuhk.edu.hk/archive/CNN_FacePoint.htm
此paper讲解博文参考:http://blog.csdn.net/hjimce/article/details/49955149 (作者:hjimce 时间:2015.11.1 QQ:1393852684)
\hspace{1.5em} 博文中详细还原了文章主要思想,对特征点定位从粗到精的层级架构进行了细节剖析。
3. Face++
关于Face++人脸识别参考博文:https://blog.csdn.net/sloanqin/article/details/48193119
\hspace{1.5em}
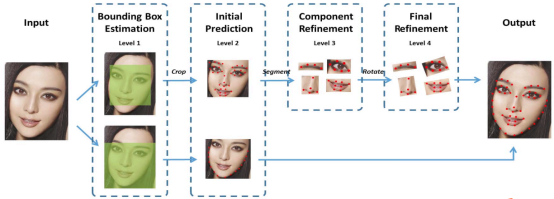
2013年Face++改进DCNN模型并实现68个人脸关键点的高精度定位。该算法将人脸关键点分为内部关键点和轮廓关键点,内部关键点包含眉毛、眼睛、鼻子、嘴巴共计 51 个关键点,轮廓关键点包含 17 个关键点。
针对内部 51 个关键点,采用四个层级的级联网络进行检测。
\hspace{1.7em} 其中,Level-1 主要作用是获得面部器官的边界框;Level-2 的输出是 51 个关键点预测位置,这里起到一个粗定位作用,目的是为了给 Level-3 进行初始化;Level-3 会依据不同器官进行从粗到精的定位;Level-4 的输入是将 Level-3 的输出进行一定的旋转,最终将 51 个关键点的位置进行输出。
针对外部 17 个关键点,仅采用两个层级的级联网络进行检测。
\hspace{1.7em} Level-1 与内部关键点检测的作用一样,主要是获得轮廓的 bounding box;Level-2 直接预测 17 个关键点,没有从粗到精定位的过程,因为轮廓关键点的区域较大,若加上 Level-3 和 Level-4,会比较耗时间。最终面部 68 个关键点由两个级联 CNN 的输出进行叠加得到。
4. MTCNN
\hspace{1.5em}
2016年,Zhang等人提出一种多任务级联卷积神经网络: MTCNN (Multi-task Cascaded Convolutional Networks) 用以处理人脸检测和人脸关键点定位问题。
原paper:《Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks》
原作GitHub参考文件:https://github.com/kpzhang93/MTCNN_face_detection_alignment

MTCNN 实现人脸检测和关键点定位分为三个阶段。
- 首先由 P-Net 获得人脸区域的候选窗口和边界框的回归向量,并用该边界框做回归,对候选窗口进行校准,通过非极大值抑制(NMS)来合并高度重叠的候选框。
- 然后将 P-Net 得出的候选框作为输入,输入到 R-Net,同理,R-Net 通过边界框回归和 NMS 来去掉 false-positive 区域,得到更为准确的候选框;
- 最后,利用 O-Net 输出 5 个关键点的位置。
\hspace{1.8em} 在具体训练过程中,作者就多任务学习的损失函数计算方式进行相应改进。
\hspace{1.8em} 在多任务学习中,当不同类型的训练图像输入到网络时,有些任务时是不进行学习的,因此相应的损失应为 0。
\hspace{1.8em}
例如,当训练图像为背景(Non-face)时,边界框和关键点的 loss 应为 0,文中提供计算公式自动确定 loss 的选取,公式为:
m
i
n
∑
i
=
1
N
∑
j
∈
{
d
e
t
,
b
o
x
,
l
a
n
d
m
a
r
k
}
α
j
β
i
j
L
i
j
min\sum^N_{i=1}\sum_{j∈\{det,box,landmark\}}\alpha_j\beta^j_iL^j_i
mini=1∑Nj∈{det,box,landmark}∑αjβijLij
\hspace{1.8em}
其中,
α
j
\alpha_j
αj表示任务的重要程度,在P-Net和R-Net中,
α
d
e
t
=
1
,
α
b
o
x
=
0.5
,
α
l
a
n
d
m
a
r
k
=
0.5
\alpha_{det}=1,\alpha_{box}=0.5,\alpha_{landmark}=0.5
αdet=1,αbox=0.5,αlandmark=0.5
在R-Net中,通过增大任务的重要性来对关键点进行检测,
β
i
j
∈
{
0
,
1
}
\beta_i^j\in\{0,1\}
βij∈{0,1}作为样本类型指示器。
\hspace{1.8em} 为了提升网络性能,需要挑选出困难样本(Hard Sample),本文提出一种能在训练过程中进行挑选困难的在线挑选方法。
\hspace{1.8em} 方法为,在 mini-batch 中,对每个样本的损失进行排序,挑选前 70% 较大的损失对应的样本作为困难样本,同时在反向传播时,忽略那 30% 的样本,因为那 30% 样本对更新作用不大。
\hspace{1.8em} 实验结果表明,MTCNN 在人脸检测数据集 FDDB 和 WIDER FACE 以及人脸关键点定位数据集 LFPW 均获得当时最佳成绩。在运行时间方面,采用 2.60GHz 的 CPU 可以达到 16fps,采用 Nvidia Titan Black 可达 99fps。
5. 总结
\hspace{1.8em}
深度学习技术在如今AI热潮中的重要性不言而喻,而人脸关键点检测也正是重要突破方向之一,同时这一任务的研究远远没有结束,仍需不断提升与解决。
\hspace{1.8em} 对于本次内部竞赛,由于秋学期缺席了多次培训,同时自身几乎对于AI方面零基础,因此仅能通过查阅资料学习与模仿,也无法一时对于解决问题有质的突破。在此感谢组内乔学长和宋同学对于项目的大力推进。同时感谢Arm公司与俱乐部对于竞赛的支持。
参考阅读
机器之心:从传统方法到深度学习,人脸关键点检测方法综述















 2777
2777











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









