









ELK 分布式日志解决方案
1. ELK是什么?
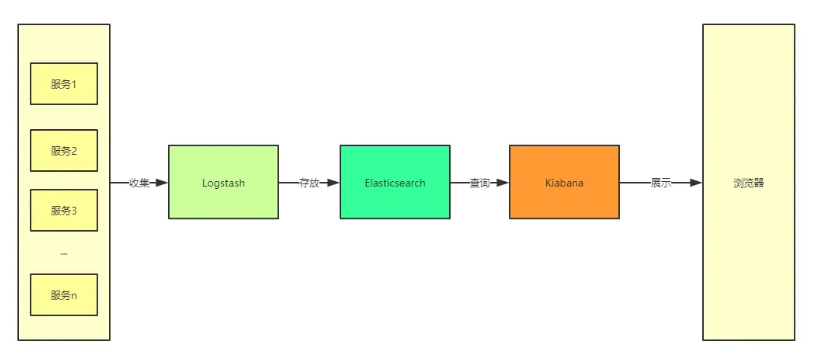
ELK其实是Elasticsearch,Logstash 和 Kibana三个产品的首字母缩写,这三款都是开源产品。
ElasticSearch: 是一个实时全文搜索和分析的引擎,也是一个非关系型数据库(和 Redis 一样),由于底层使用倒排索引的缘故,ElasticSearch 的搜索性能很高,其提供搜集、分析、存储数据三大功能,是一套开放 REST 和 JAVA API 等结构提供高效搜索功能,可扩展的分布式系统。它构建于 Apache Lucene 搜索引擎库之上。
LogStash: 是一个服务端的数据处理管道,可以从各个服务器来源采集数据,对数据进行一定的筛选和处理,然后把数据输出到 ES 这样的数据库中,解决了多节点部署服务场景下的日志读取问题。
**Kibana:**为 Elasticsearch 提供了分析和 Web 可视化界面,并生成各种维度表格、图形。
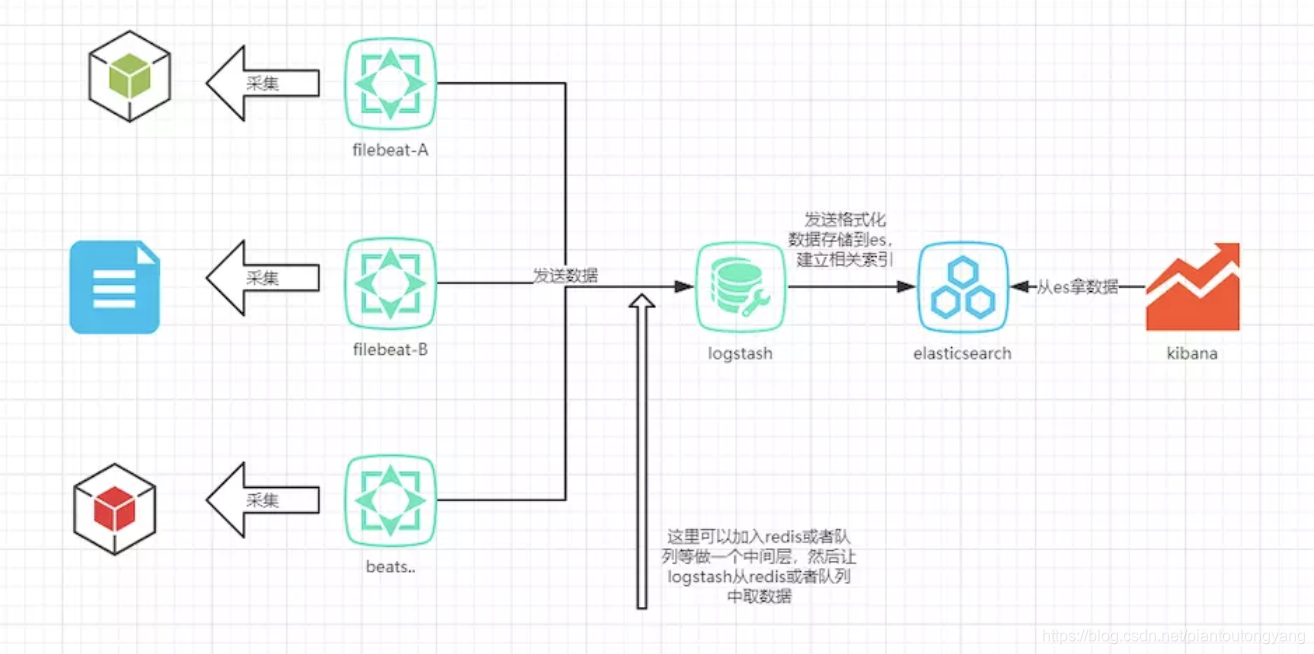
ELK 架构优化
由于Logstash本身 其实是一个 Java 程序,放置在应用端对 CPU、内存、IO 的占用较高,因此 Elastic NV 也就是官方推出了使用 Go 语言写的 Beats 这一轻量级采集器,进行数据的采集,这是加入Beats后的ELK架构:
2. 为什么要使用ELK?
对于日志的收集、存储、分析、监控、报警是一项非常非常重要的基础工作。
日志可以帮助我们:
- 检查系统是否健康;
- 回溯用户行为,跟踪程序运行轨迹;
- 业务层面的大数据分析,一切用数据说话,反哺给产品经理;
- 帮助分析与调试程序bug;
- 遇到错误时第一时间报警,重大事故前的预警,让运维和开发不再被动;
没有日志的帮助,我们的系统可以说是寸步难行,如同瞎子一般,时不时的崩溃也在情理之中。当然,日志的内容也是需要拿捏的,多打有意义的日志,少打无意义的日志,具体情况具体分析,要结合业务场景。
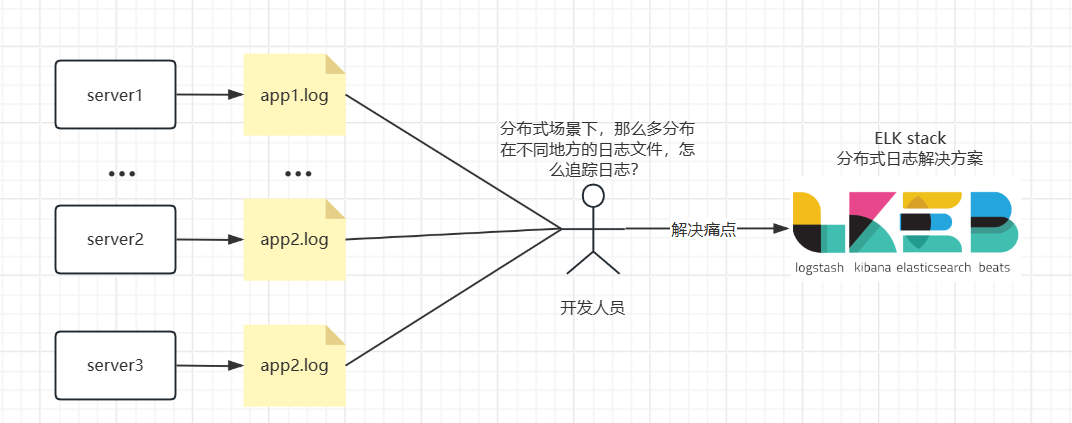
而当今哪怕是没有玩上服务化、微服务架构的公司也会部署多个节点做集群来保证系统的高可用,提升整体吞吐量。
那么在面对这种分布式的应用场景下(你的程序被同时部署在多个节点上),你的日志也是分布式的。
以往,我们会使用类似于log4j、logback(springboot2.0默认日志框架)等日志框架来打log,程序通过配置文件往本地磁盘中的某一个目录下输出log,并形成xxx.log文件。
那么痛点来了,如果你的程序部署到了10个节点上,你要去查看这些日志该怎么办?
远程进入这10个节点的linux系统,然后用tail命令?如果上游的路由规则是随机飘到任意一个下游节点,你怎么跟?
业务量很大,日志嗖一下的刷没了,根本抓不到。业务量很大,日志文件体积特别大,几个G,无论是打开和下载都很慢。
综上所述,在分布式场景下,我们需要一个地方,来集中管理所有节点的日志信息,这个地方允许我们按不同的维度查询,报警,监控,这就是ELK所能帮我们解决的问题。
3. ELK 的安装与使用(Docker 环境下)
注意:本次基于原始ELK架构进行安装和使用,后续优化的版本后续学习后补充。。。
安装注意事项
首先要声明两点安装的注意事项:
-
后续部署的几个组件要做到版本统一(例如 ES 是 7.17.7,那么 LogStash 也应该是 7.17.7)
-
由于部署需要 Java 环境,大很多人都是用 JDK1.8,那么最好这些组件使用 7.xx 版本,本次文章使用7.17.7
3.1 Elasticsearch安装
1 拉取镜像
docker pull eslasticsearch:7.17.7
2 显示VM最大数量并修改
sysctl -a|grep vm.max_map_count
# 若为65530 则 加大设置 ,否住容器会启动失败,原因待后续补充
sysctl -w vm.max_map_count=262144
3 准备挂载文件
mkdir -p /usr/local/softwares/elk/elasticsearch
cd /usr/local/softwares/elk/elasticsearch
mkdir conf
mkdir data
mkdir plugins
4. 进入conf目录下,创建elasticsearch.yml配置文件
http:
host: 0.0.0.0
cors:
enabled: true
allow-origin: "*"
xpack:
security:
enabled: false
4.1 修改文件的权限
chmod /usr/local/softwares/elk/elasticsearch/**
#将es文件夹下所有的文件权限修改避免启动容器报异常 AccessDeniedException 或者 AccessControlException
5 创建并运行容器
docker run -itd \
--name es \
--privileged \
--network wn_docker_net \ #这是自定义的静态网络,为了防止docker容器的ip变动
--ip 172.18.12.80 \
-p 9200:9200 \
-p 9300:9300 \ #绑定默认的端口
-e "discovery.type=single-node" \ # 以单一节点模式启动
-e ES_JAVA_OPTS="-Xms4g -Xmx4g" \ # 虚拟机内存不足可以尝试分配 Xms2g
-v /usr/local/softwares/elk/elasticsearch/conf/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /usr/local/softwares/elk/elasticsearch/data:/usr/share/elasticsearch/data \
-v /usr/local/softwares/elk/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
elasticsearch:7.17.7
6. 成功性验证
输入 ip + 容器端口(如:192.168.216.129:9200)后网页显示:

如果失败,则可以使用docker logs 容器名称 查看具体报错信息
7. 安装分词器
下载压缩包(7.17.7版本)
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases?page=2
安装到容器中并解压
#7.17.7版本的分词器需要解压在容器的/usr/share/elasticsearch/plugins/ik下
#因而在容器挂载文件plugins目录下创建ik文件夹(与容器对应),并上传es分词器到该文件夹下,拷贝到容器ik目录下
docker cp elasticsearch-analysis-ik-7.17.7.zip es:/usr/share/elasticsearch/plugins/ik/
#进入容器目标位置,解压文件
docker exec -it es bash
docker cd /plugins/ik
upzip elasticsearch-analysis-ik-7.17.7.zip
重启容器
docker restart es
成功性检测
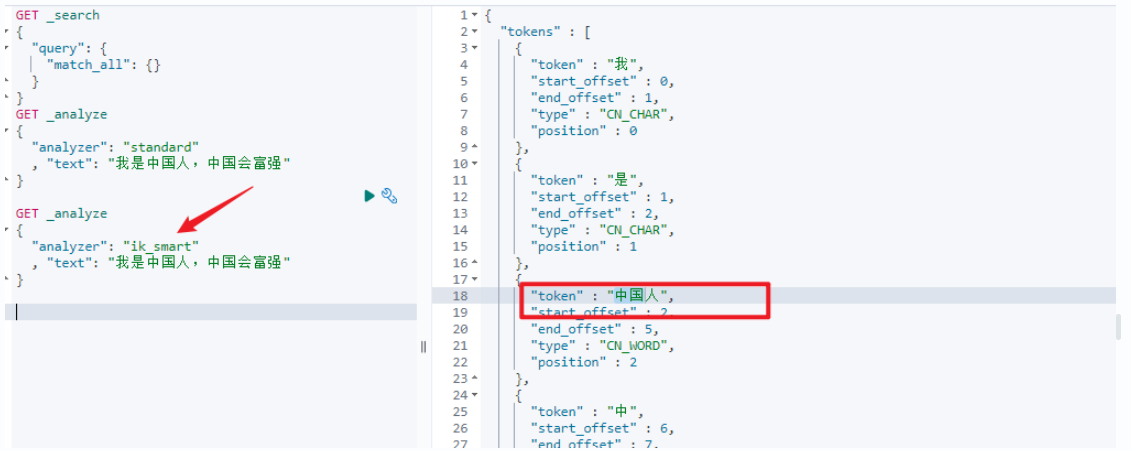
自定义分词字典
核心文件:容器中plugins/ik/config下的IKAnalyzer.cfg.xml 文件
在挂载文件相应位置中进行修改IKAnalyzer.cfg.xml 文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">
ext_dict_my.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<!-- <entry key="remote_ext_dict">words_location</entry> -->
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
在挂载文件夹对应位置创建ext_dict_my.dic文件
# 文件内容 ,分词就是哪几个字看作一个词
网络安全
测试
开发
重启容器
docker restart es
成功性检测
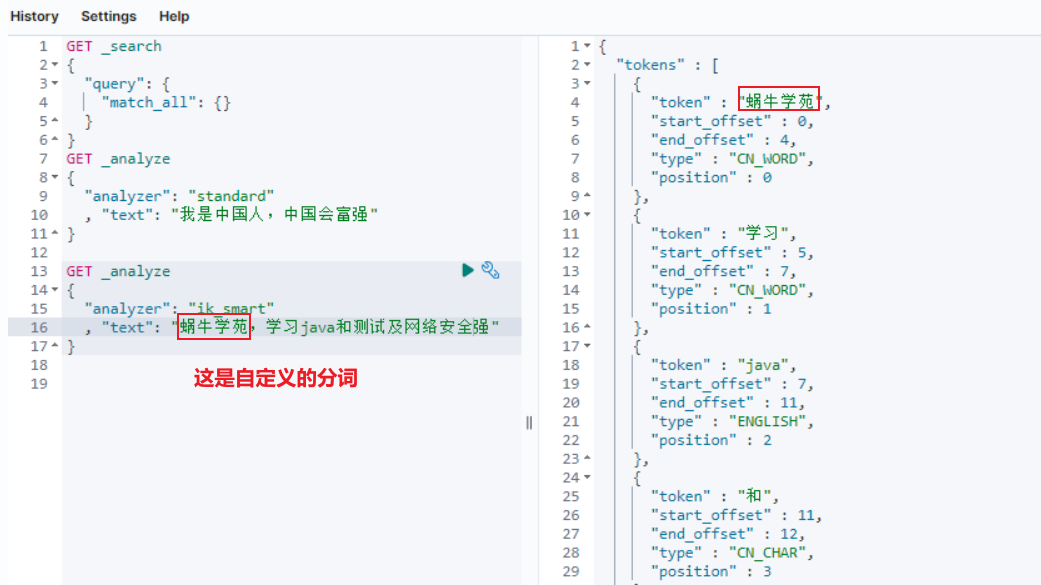
3.2 Kibana安装
1. 拉取镜像
docker pull kibana:7.17.7
2. 创建容器(必须先安装Es)
docker run -it \
--name kibana \
--privileged \
--network wn_docker_net \
--ip 172.18.12.81 \
-e "ELASTICSEARCH_HOSTS=http://192.168.216.129:9200" \
-p 5601:5601 \
-d kibana:7.17.7
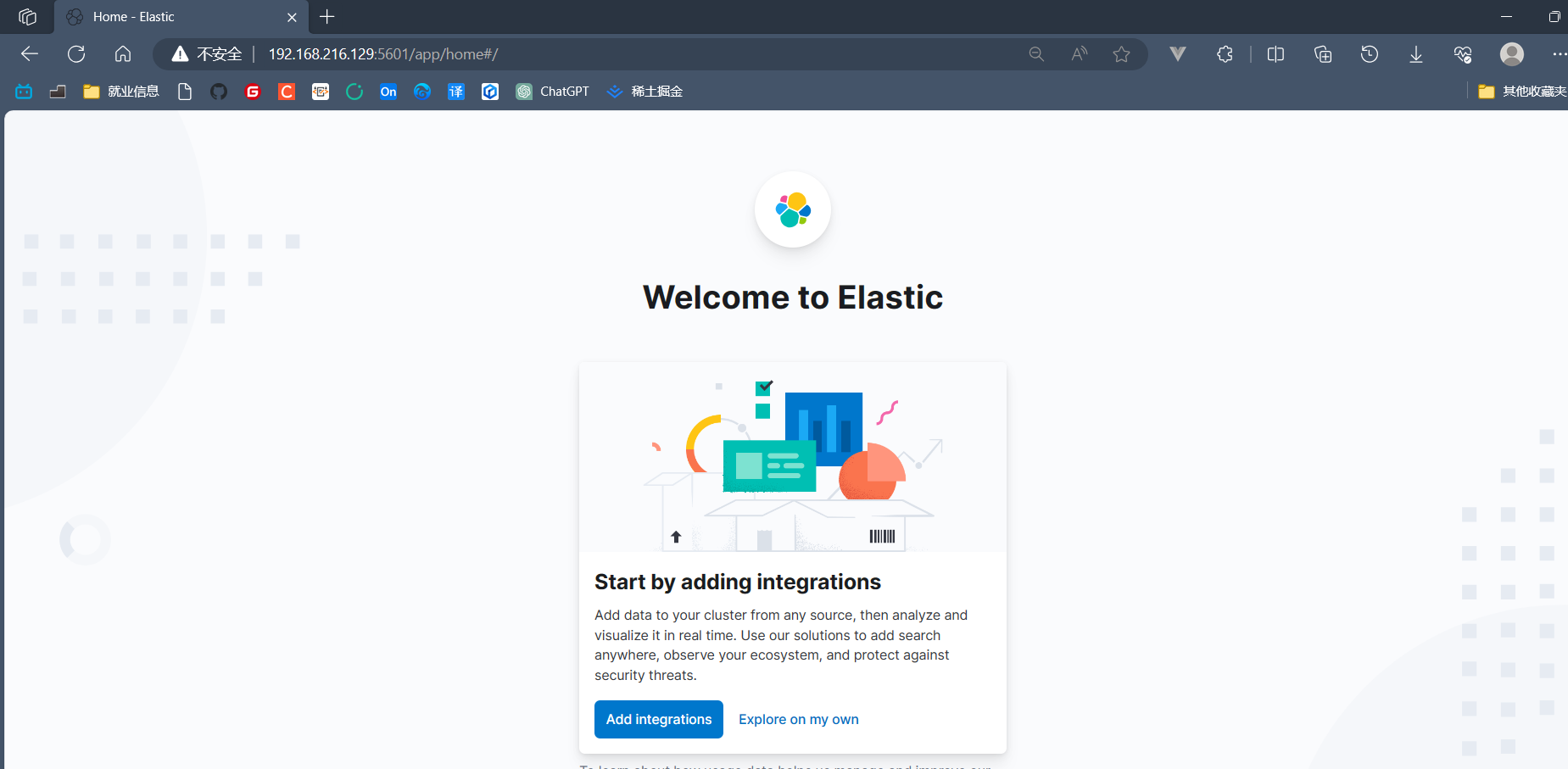
3. Kibana检验成功
网页输入ip + 容器端口显示如下:
3.3 Logstash安装
1. 拉取镜像
docker pull logstash:7.17.7
2. 创建容器
docker run -it \
--name logstash \
--privileged \
-p 5044:5044 \
-p 9600:9600 \
--network wn_docker_net \
--ip 172.18.12.72 \
-v /etc/localtime:/etc/localtime \
-d logstash:7.17.7
3. 从容器拷贝配置文件并进行修改,再拷贝回去(笨方法)
进入容器
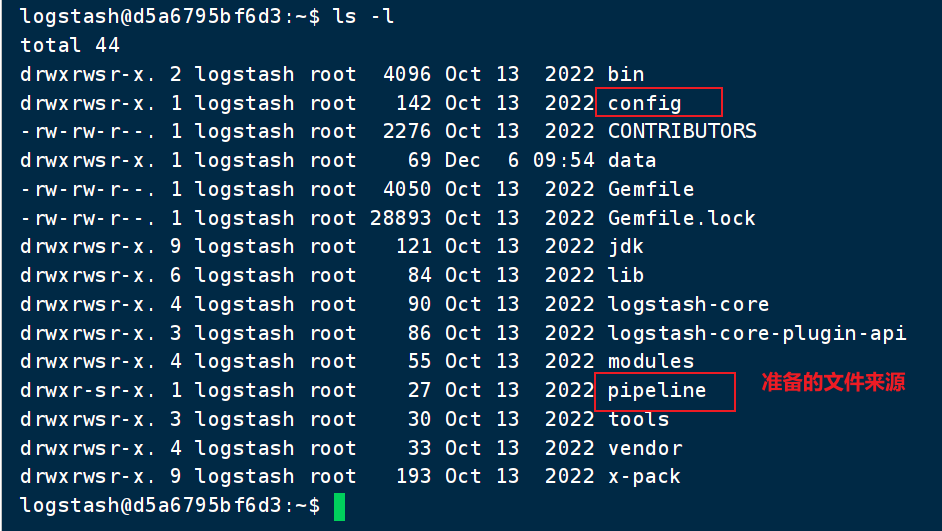
拷贝文件如下
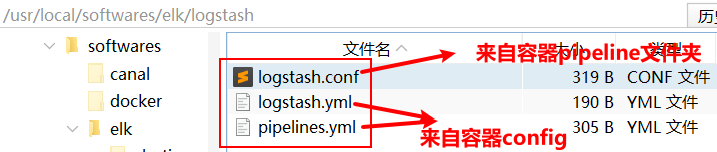
修改准备的文件并复制到容器原位置
Logstash.yml修改
在容器内创建logs文件夹

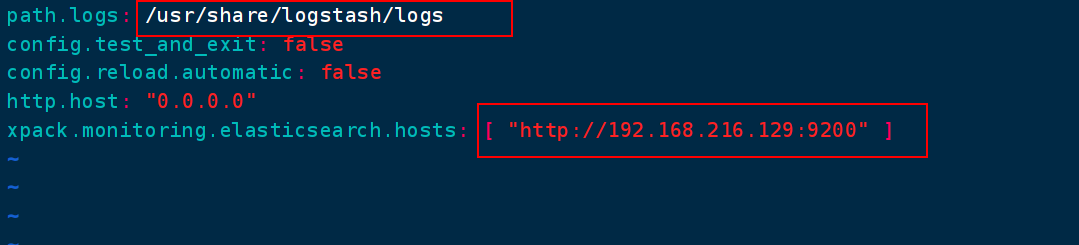
pipelines.yml配置
# This file is where you define your pipelines. You can define multiple.
# # For more information on multiple pipelines, see the documentation:
# # https://www.elastic.co/guide/en/logstash/current/multiple-pipelines.html
#
- pipeline.id: main
path.config: "/usr/share/logstash/pipeline/logstash.conf"
Logstash.conf 配置
input {
tcp {
mode => "server"
host => "0.0.0.0"
port => 5044
codec => json_lines
}
}
filter{
}
output {
elasticsearch {
hosts => ["192.168.216.129:9200"] #elasticsearch的ip地址
index => "elk" #索引名称
}
stdout { codec => rubydebug }
}
拷贝回容器
docker cp 修改后的文件 容器名:文件对应容器中的路径
docker restart logstash # 重启容器
成功性检测
docker logs logstash # 查询容器日志是否正常
4. SpringBoot进行整合
文章借鉴
链接:https://juejin.cn/post/7282211221831024695
=> “elk” #索引名称
}
stdout { codec => rubydebug }
}
#### 拷贝回容器
```shell
docker cp 修改后的文件 容器名:文件对应容器中的路径
docker restart logstash # 重启容器
成功性检测
docker logs logstash # 查询容器日志是否正常
4. SpringBoot进行整合
文章借鉴
链接:https://juejin.cn/post/7282211221831024695
原文链接:https://blog.csdn.net/piantoutongyang/article/details/88811840















 202
202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









