







参考:https://blog.csdn.net/qq_39207948/article/details/80006224
希尔排序
希尔排序是直接插入排序的改进,传统的之间插入排序对小规模数据或是基本有序数据时十分高效,而希尔排序对于直接插入排序的改进使其对于中等规模的数据的性能表现还不错。
希尔排序思路:
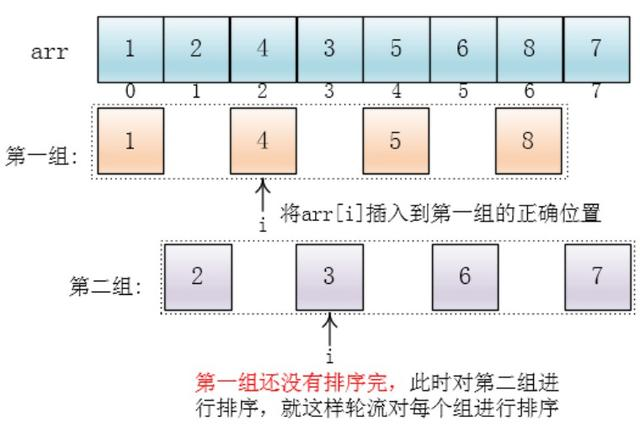
把较大的数据集合分割成若干个小组(逻辑上分组),然后对每一个小组分别进行插入排序,此时,插入排序所作用的数据量比较小(每一个小组),插入的效率比较高。
举例说明:
对于数列(5,7, 8,3, 1,2, 4,6),给他们逻辑上分组,实际上并没有分组,在数组中还是原来的位置,只是将他们看成这么一个分组。
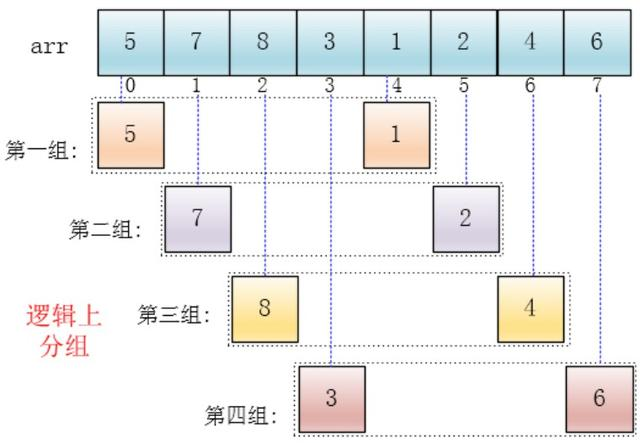
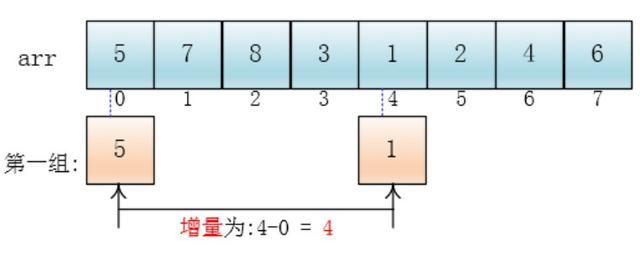
可以看出,他是按下标相隔距离为4分的组,也就是说把下标相差4的分到一组,比如这个例子中a[0]与a[4]是一组、a[1]与a[5]是一组…,这里的差值(距离)被称为增量。
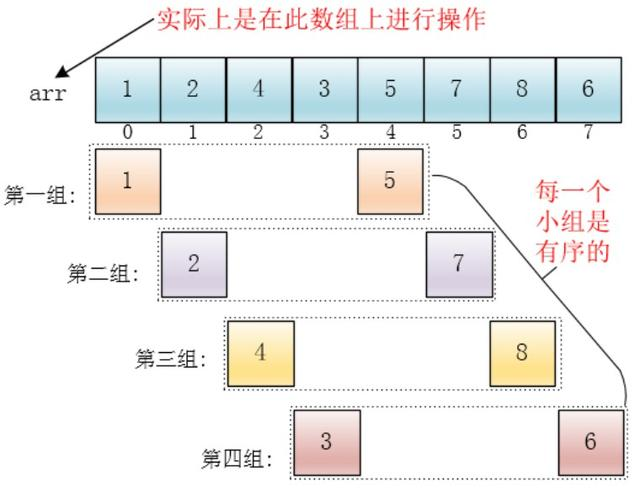
每个分组进行插入排序后,各个分组就变成了有序的了(整体不一定有序)
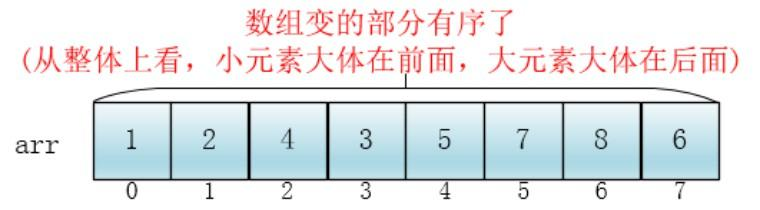
此时,整个数组变的部分有序了(有序程度可能不是很高)
然后缩小增量为上个增量的一半:2,继续划分分组,此时,每个分组元素个数多了,但是,数组变的部分有序了,插入排序效率同样比高
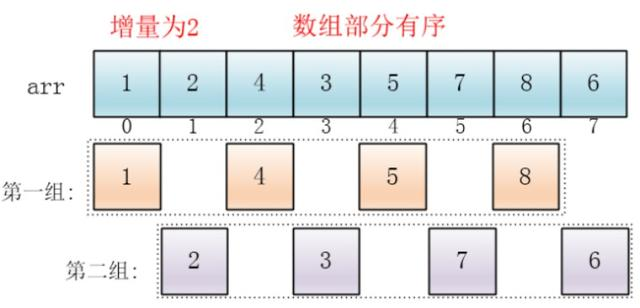
同理对每个分组进行排序(插入排序),使其每个分组各自有序
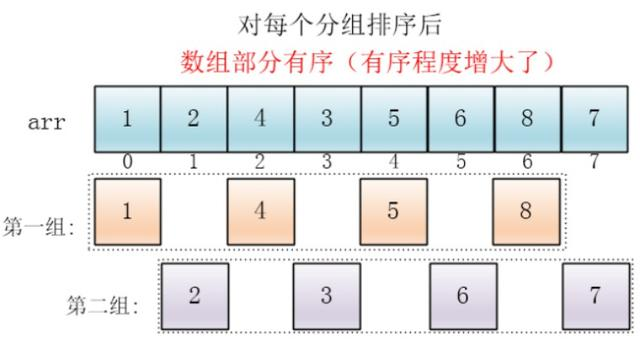
最后设置增量为上一个增量的一半:1,则整个数组被分为一组,此时,整个数组已经接近有序了,插入排序效率高
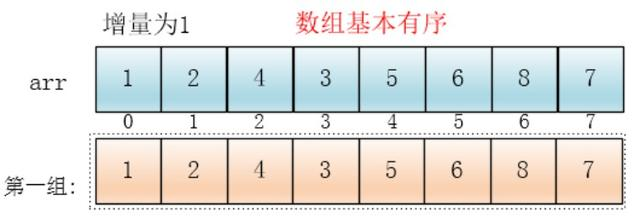
同理,对这仅有的一组数据进行排序,排序完成。
希尔排序代码
/*
希尔排序的排序思路是:
把较大的数据集合分割成若干个小组(逻辑上分组),
然后对每一个小组分别进行插入排序,
此时,插入排序所作用的数据量比较小(每一个小组),插入的效率比较高
*/
#include <stdio.h>
void ShellSort(int data[],int n)
{
int gap = n/2; //增量设置初值
int i,j;
while (gap>0)
{
for (i=gap; i<n; i++)
{
//对相隔gap位置的元素组直接插入排序(temp就是我们要插入的元素)
int temp = data[i];
j = i-gap;
while (j >= 0 && temp < data[j])
{
//temp小于前面有序区的元素,需要继续往前寻找合适位置插入
//所以有序区的和temp比较过的元素需要跟着向后移动
data[j+gap] = data[j];
j = j-gap;
}
//在合适位置插入temp
data[j+gap] = temp;
}
gap = gap/2; //减小增量
}
}
int main()
{
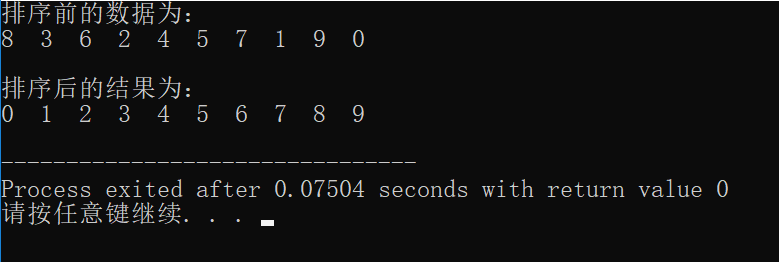
int value[] = {8,3,6,2,4,5,7,1,9,0};
printf("排序前的数据为:\n");
for(int i=0; i<10;i++)
printf("%d ",value[i]);
printf("\n\n");
ShellSort(value,10);
printf("排序后的结果为:\n");
for(int i=0; i<10;i++)
printf("%d ",value[i]);
printf("\n");
return 0;
}
注意:
对各个组进行插入的时候并不是先对一个组进行排序完再对另一个组进行排序,而是轮流对每个组进行插入排序
希尔排序时间复杂度
希尔排序的复杂度和增量序列是相关的
{1,2,4,8,…}这种序列并不是很好的增量序列,使用这个增量序列的时间复杂度(最坏情形)是O(n^2)
Hibbard提出了另一个增量序列{1,3,7,…,2k-1},这种序列的时间复杂度(最坏情形)为O(n1.5)
Sedgewick提出了几种增量序列,其最坏情形运行时间为O(n^1.3),其中最好的一个序列是{1,5,19,41,109,…}
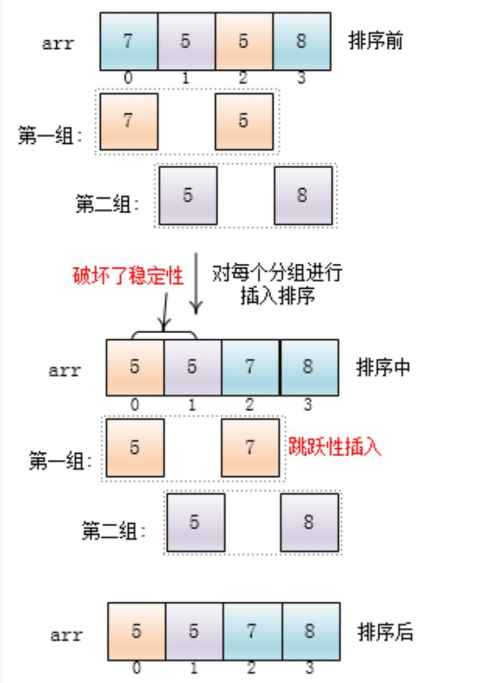
希尔排序稳定性
不是稳定的,虽然插入排序是稳定的,但是希尔排序在插入的时候是跳跃性插入的,有可能破坏稳定性
算法分析:
| 排序方法 | 时间复杂度(平均) | 时间复杂度(最坏) | 时间复杂度(最好) | 空间复杂度 | 稳定性 |
|---|---|---|---|---|---|
| 希尔排序 | O(n1.3) | O(1) | 不稳定 |
参考:https://blog.csdn.net/qq_39207948/article/details/80006224















 400
400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









