







基数排序
基数排序(Radix Sort)是桶排序的扩展,它的基本思想是:将整数按位数切割成不同的数字,然后按每个位数分别比较。(桶排序可以参考:我的另一篇博客)
具体做法是:将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
通过基数排序对数组{53, 3, 542, 748, 14, 214, 154, 63, 616},它的示意图如下:
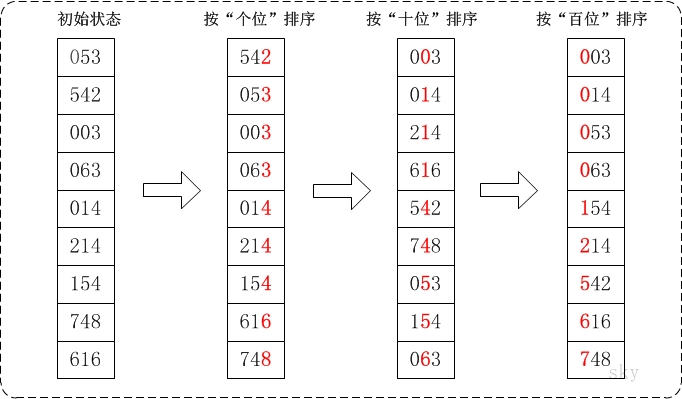
在上图中,首先将所有待比较树脂统一为统一位数长度,接着从最低位开始,依次进行排序。
- 按照个位数进行排序。
- 按照十位数进行排序。
- 按照百位数进行排序。
排序后,数列就变成了一个有序序列。
基数排序代码
/*
基数排序思路:
基数排序(Radix Sort)是桶排序的扩展,它的基本思想是:
将整数按位数切割成不同的数字,然后按每个位数分别比较。
具体做法是:将所有待比较数值统一为同样的数位长度,数位较短的数前面补零。
然后,从最低位开始,依次进行一次排序。
这样从最低位排序一直到最高位排序完成以后, 数列就变成一个有序序列。
*/
#include<stdio.h>
/*
* 获取数组data中最大值
*
* 参数说明:
* data -- 数组
* n -- 数组长度
*/
int getMax(int data[], int n)
{
int i, max;
max = data[0];
for (i = 1; i < n; i++)
if (data[i] > max)
max = data[i];
return max;
}
/*
* 打印data数组元素以及显示提示信息
*
* 参数说明:
* data -- 数组
* n -- 数组长度
* str -- 提示信息
*/
void print_array(int data[], int n,char *str)
{
printf("%s: ",str);
for (int i = 0; i < n; i++)
{
printf("%d ",data[i]);
}
printf("\n ");
}
/*
* 对数组按照"某个位数"进行排序(桶排序)
*
* 参数说明:
* data -- 数组
* n -- 数组长度
* exp -- 指数。对数组a按照该指数进行排序。
*
* 例如,对于数组a={50, 3, 542, 745, 2014, 154, 63, 616};
* (01) 当exp=1表示按照"个位"对数组a进行排序
* (02) 当exp=10表示按照"十位"对数组a进行排序
* (03) 当exp=100表示按照"百位"对数组a进行排序
* ...
*/
void countSort(int data[], int n, int exp)
{
int output[n]; // 存储"被排序数据"的临时数组
int i, buckets[10] = {0};
// 将数据出现的次数存储在buckets[]中
//(data[i]/exp)%10 表示为data[i]的某个位上的数字(由exp决定)
for (i = 0; i < n; i++)
buckets[ (data[i]/exp)%10 ]++;
print_array(buckets,10, "buckets1");
// 更改buckets[i]。目的是让更改后的buckets[i]的值,是该数据在output[]中的位置。
for (i = 1; i < 10; i++)
buckets[i] += buckets[i - 1];
print_array(buckets,10, "buckets2");
// 将数据存储到临时数组output[]中
for (i = n - 1; i >= 0; i--)
{
output[buckets[ (data[i]/exp)%10 ] - 1] = data[i];
buckets[ (data[i]/exp)%10 ]--;
}
print_array(buckets,10, "buckets3");
// 将排序好的数据赋值给a[]
for (i = 0; i < n; i++)
data[i] = output[i];
print_array(data,n, "data");
printf("------完成一次桶排序--------\n\n ");
}
/*
* 基数排序
*
* 参数说明:
* data -- 数组
* n -- 数组长度
*/
void radix_sort(int data[], int n)
{
int exp; // 指数。当对数组按各位进行排序时,exp=1;按十位进行排序时,exp=10;...
int max = getMax(data, n); // 数组a中的最大值
// 从个位开始,对数组a按"指数"进行排序
for (exp = 1; max/exp > 0; exp *= 10)
countSort(data, n, exp);
}
int main()
{
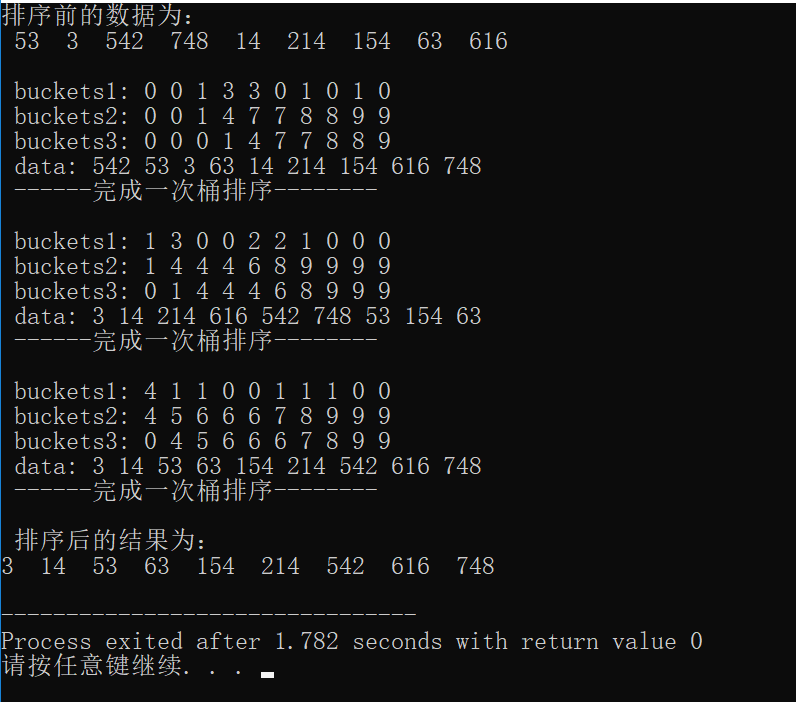
int data[] = {53, 3, 542, 748, 14, 214, 154, 63, 616};
int ilen = (sizeof(data)) / (sizeof(data[0]));
printf("排序前的数据为:\n ");
for(int i=0; i<ilen;i++)
printf("%d ",data[i]);
printf("\n\n ");
radix_sort(data,ilen);
printf("排序后的结果为:\n");
for(int i=0; i<ilen;i++)
printf("%d ",data[i]);
printf("\n");
return 0;
}
结果:
算法分析:
对于给定的n个d位数,取值范围为[0,r],我们使用计数排序比较元素的每一位,基数排序耗时O(n+r),那么基数排序的复杂度为O(d(n+r))。
我们还是和快速排序进行比较,仅仅从渐进性来看,基数排序比快速排序要好,但是隐藏在Θ符号后面的常数项因子是不同的,基数排序循环次数比快速排序循环次数少,但是基数排序每次循环会比快速排序长。更多的时候我们使用哪一种是通过输入数据的特征以及主存容量是否宝贵来决定的。当我们需要原址排序或者主存容量宝贵的时候我们就更倾向于快速排序这样的原址排序。
| 排序方法 | 时间复杂度(平均) | 时间复杂度(最坏) | 时间复杂度(最好) | 空间复杂度 | 稳定性 |
|---|---|---|---|---|---|
| 基数排序 | O(d(n+r)) | O(d(n+r)) | O(d(n+r)) | O( r ) | 稳定 |
参考:https://www.cnblogs.com/skywang12345/p/3603669.html















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









