







1.详解Requests和Limits参数
以CPU为例,下图显示了未设置Limits与设置了Requests和Limits的CPU使用率的区别
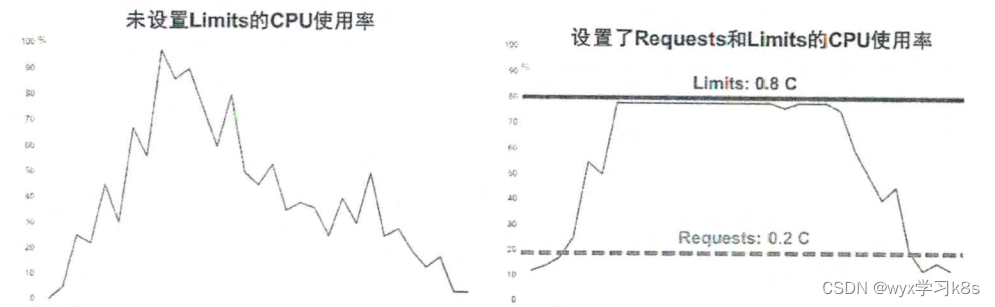
尽管Requests和Limits只能被设置到容器上,但是设置了Pod级别的Requests和Limits能大大提高管理Pod的便利性和灵活性,因此在Kubernetes中提供了对Pod级别的Requests和Limits的配置。对于CPU和内存而言,Pod的Requests或Limits指该Pod中所有容器的Requests或Limits的总和(对于Pod中没有设置Requests或Limits的容器,该项的值被当作0或者按照集群配置的默认值来计算)。下面对CPU和内存这两种计算资源的特点进行说明 。
(1)CPU
CPU的Requests和Limits是通过CPU数(cpus)来度量的。CPU的资源值是绝对值,而不是相对值,比如O.1CPU在单核或多核机器上是一样的,都严格等于0.1CPU core。
(2)Memory
内存的Requests和Limits计量单位是字节数。使用整数或者定点整数加上国际单位制来表示内存值。国际单位制包括十进制的E、P、T、G、M、K、m或二进制的Ei、Pi、Ti、Gi、Mi、Ki。KiB与MiB是以二进制表示的字节单元,常见的KB与MB则是以十进制表示的字节单位,简而言之:
1KB=1000Bytes=8000Bits
1KiB=Bytes=1024Bytes=8192Bits
2.基于Requests和Limits的Pod调度机制
当—个Pod创建成功时,Kubernetes调度器(Scheduler)会为该Pod选择一个节点来执行。对于每种计算资源(CPU和Memory)而言,每个节点都有一个能用于运行Pod的最大容量值。调度器在调度时,首先要确保调度后该节点上所有Pod的CPU和内存的Requests 总和,不超过该节点能提供给Pod使用的CPU和Memory的最大容量值 。
例如:某个节点上的CPU资源充足,而内存为4GB,其中3GB可以运行Pod,而某Pod的Memory Requests为1GB、Limits为2GB,那么在这个节点上最多可以运行3个这样的Pod。
有个情景:可能某个节点上的实际资源使用量非常低,但是已运行Pod配置的Requests值的总和非常高,如果要新调度Pod的Requests值+已运行所有Pod配置的Requests值>节点提供给Pod资源容量上限,这是该Pod不会在该节点上运行。
用数字量化来说就是3个Pod实际使用内存都不足500M,但是3个Pod的Request值相加已经达到了节点可用内存上限3G,故K8S不会在调度Pod到该节点上了
3.Requests和Limits的背后机制
kubelet在启动Pod的某个容器时,会将容器的Requests和Limits值转化为相应的容器启动参数传递给容器来执行,传递参数给Docker的过程如下:
1.spec.container[].resources.requests.cpu
这个参数值会被转化为core数(比如配置100m会转化成0.1),然后乘以1024,再将这个结果作为--cpu-shares参数的值传递给docker run命令,在docker run命令中,--cpu-share参数是一个相对权重值(Relative Weight),这个相对权重值会决定Docker在资源竞争时分配给容器的资源比例。
这里举例说明--cpu-shares参数在Docker中的含义:比如将两个容器的CPU Requests分别设置为1和2,那么容器在docker run启动时对应的--cpu-shares参数值分别为1024和2048,在主机CPU资源产生竞争时,Docker会尝试按照1:2的配比将CPU资源分配给这两个容器使用。
其中,这个参数对于Kubernetes来说是绝对值,是多少就会转换后传递给docker的--cpu-shares参数,主要用于Kubernetes的调度和管理,但是对于Docker来说是相对值,按照比例来分配资源
2.spec.container[].resources.limits.cpu
这个参数值会被转化为millicore数(比如配置的1被转化为1000, 而配置的100m被转化为100),将此值乘以100000,再除以1000,然后将结果值作为--cpu-quota参数的值传递给docker run 命令。docker run命令中的另一个参数--cpu-period 默认被设置为100000,表示Docker重新计算和分配CPU的使用时间间隔为100000µs ( 100ms ) 。
Docker的--cpu-quota参数和--cpu-period参数一起配合完成对容器CPU的使用限制:比如在Kubernetes中配置容器的CPU Limits为0.1, 那么计算后--cpu-quota为10000,而--cpu-period 为 100000, 这意味着Docker在l00ms内最多给该容器分配10ms*core的计算资源用量,10/100=0.1 core 的结果与 Kubernetes 配置的意义是一致的。
3.spec.container[].resources.requests.memory
这个参数值只提供给Kubernetes调度器作为调度和管理的依据,不会作为任何参数传递给Docker
4.spec.container[].resources.limits.memory
这个参数值会被转化为单位为Bytes的整数,值作为--memory参数传递给docker run。
如果一个容器在运行过程中使用了超出其内存Limits配置的内存限制值,那么它可能会被“Kill”掉,如果这个容器的重启策略是always,那么kubernetes会在kill掉后重新拉起,此时应该重新评估设置limits.memory值。
与内存Limits不同的是,CPU在容器技术中属于可压缩资源,因此对CPU的Limits配置一般不会因为偶然超标使用而导致容器被系统”Kill"。
4.计算资源使用情况监控
Pod的资源用量会作为Pod的状态信息一同上报给Master。如果在集群中配置了Heapster来监控集群的性能数据,那么还可以从Heapster中 查看Pod的资源用量信息。
5.计算资源常见问题分析
1.Pod状态为Pending,错误信息为FailedScheduling。如果Kubernetes调度器在集群中找不到合适的节点来运行Pod,那么这个Pod会一直处于未调度状态,直到调度器找到合适的节点为止。可以用这个命令来查看pod事件信息:kubelet describe pod $pod,如果有类似FailedScheduling ailed for reason PodExceedsFreeCPU and possibly others的日志,说明是CPU资源不够导致调度失败。解决方法:
1.添加更多的Node节点
2.停止一些非必要的Pod,释放资源
3.检查Pod配置,错误的配置肯可能会导致该Pod永远无法被调度执行。例如:整个集群的所有节点都是1CPU,而Pod的配置CPU Requests为2,这样该Pod永远无法调度
查看节点计算资源命令:
[root@k8s-master ~]# kubectl describe node k8s-node01
Name: k8s-node01
Roles: <none>
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=k8s-node01
kubernetes.io/ingress=nginx
kubernetes.io/os=linux
Annotations: kubeadm.alpha.kubernetes.io/cri-socket: unix:///var/run/containerd/containerd.sock
node.alpha.kubernetes.io/ttl: 0
projectcalico.org/IPv4Address: 11.0.1.13/24
projectcalico.org/IPv4IPIPTunnelAddr: 172.16.85.192
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Wed, 20 Mar 2024 10:42:57 +0800
Taints: <none>
Unschedulable: false
Lease:
HolderIdentity: k8s-node01
AcquireTime: <unset>
RenewTime: Fri, 12 Apr 2024 09:21:48 +0800
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
NetworkUnavailable False Wed, 10 Apr 2024 08:30:50 +0800 Wed, 10 Apr 2024 08:30:50 +0800 CalicoIsUp Calico is running on this node
MemoryPressure False Fri, 12 Apr 2024 09:20:17 +0800 Fri, 12 Apr 2024 09:15:11 +0800 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Fri, 12 Apr 2024 09:20:17 +0800 Fri, 12 Apr 2024 09:15:11 +0800 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Fri, 12 Apr 2024 09:20:17 +0800 Fri, 12 Apr 2024 09:15:11 +0800 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Fri, 12 Apr 2024 09:20:17 +0800 Fri, 12 Apr 2024 09:15:11 +0800 KubeletReady kubelet is posting ready status
Addresses:
InternalIP: 11.0.1.13
Hostname: k8s-node01
Capacity:
cpu: 2
ephemeral-storage: 18121Mi
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 1862816Ki
pods: 110
Allocatable:
cpu: 2
ephemeral-storage: 17101121099
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 1760416Ki
pods: 110
System Info:
Machine ID: 770cecbd0b4543279b46495d03f3e1d7
System UUID: 83374D56-C17C-C044-73D5-E8B739FCF790
Boot ID: 69a2e659-996e-4876-8324-5413b3880695
Kernel Version: 3.10.0-1160.108.1.el7.x86_64
OS Image: CentOS Linux 7 (Core)
Operating System: linux
Architecture: amd64
Container Runtime Version: containerd://1.6.28
Kubelet Version: v1.27.1
Kube-Proxy Version: v1.27.1
Non-terminated Pods: (3 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits Age
--------- ---- ------------ ---------- --------------- ------------- ---
kube-system calico-kube-controllers-6c99c8747f-lth46 0 (0%) 0 (0%) 0 (0%) 0 (0%) 2d
kube-system calico-node-2jq57 250m (12%) 0 (0%) 0 (0%) 0 (0%) 2d
kube-system kube-proxy-bvrr7 0 (0%) 0 (0%) 0 (0%) 0 (0%) 22d
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 250m (12%) 0 (0%)
memory 0 (0%) 0 (0%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-1Gi 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal NodeHasSufficientMemory 6m45s (x8 over 14d) kubelet Node k8s-node01 status is now: NodeHasSufficientMemory
Normal NodeHasNoDiskPressure 6m45s (x8 over 14d) kubelet Node k8s-node01 status is now: NodeHasNoDiskPressure
Normal NodeHasSufficientPID 6m45s (x8 over 14d) kubelet Node k8s-node01 status is now: NodeHasSufficientPID
Normal NodeReady 6m45s (x8 over 14d) kubelet Node k8s-node01 status is now: NodeReady
我们细致的来看这两条配置:
Capacity:
cpu: 2
ephemeral-storage: 18121Mi
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 1862816Ki
pods: 110
Allocatable:
cpu: 2
ephemeral-storage: 17101121099
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 1760416Ki
pods: 110
超过可用资源容量上限(Capacity)和已分配资源量(Allocated resources)差额的Pod无法运行在该Node上。
2.容器被强行终止(Terminated)。如果容器使用的资源超过了它配置的Limits,那么该容器可能被强行终止。可以用这个命令来查看pod事件信息:kubelet describe pod $pod,如果有类似Last Termination State:Terminated 以及Restart Count:5,说明容器上个状态是终止的并且已经根据重启策略重启了5次
kubectl get pod -o go-template='{{range.status.containerStatuses}} {{"Container Name:" }} {{.name}}{{"\r\nLastState: "}} {{.lastState}} {{end}}' -n kube-system $POD
可以查看是否有OOM
6.对大内存页 (Huge Page) 资源的支持
我们可以将Huge Page理解为一种特殊的计算资源:拥有大内存页的资源。而拥有Huge Page资源的Node也与拥有GPU资源的Node一样,属于一种新的可调度资源节点(Schedulable Resource Node)。
Huge Page类似于CPU或者Memory资源,但不同于CPU或者Memory,Huge Page资源属于不可超限使用的资源,也支持ResourceQuota实现配额限制。
举例说明:
1.节点规划分配多种规格的巨页
在etc/default/grub 中添加
[root@k8s-master ~]# cat /etc/default/grub
GRUB_TIMEOUT=5
GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)"
GRUB_DEFAULT=saved
GRUB_DISABLE_SUBMENU=true
GRUB_TERMINAL_OUTPUT="console"
GRUB_CMDLINE_LINUX="crashkernel=auto spectre_v2=retpoline rhgb quiet hugepagesz=1G hugepages=2 hugepagesz=2M hugepages=512"
GRUB_DISABLE_RECOVERY="true"
代表了分配了 2*1GiB 的 1 GiB 页面和 512*2 MiB 的 2 MiB 页面。
2.查看节点计算资源
kubectl describe node $node
Capacity:
cpu: ...
ephemeral-storage: ...
hugepages-1Gi: 2Gi
hugepages-2Mi: 1Gi
memory: ...
pods: ...
Allocatable:
cpu: ...
ephemeral-storage: ...
hugepages-1Gi: 2Gi
hugepages-2Mi: 1Gi
memory: ...
pods: ...3.创建pod yaml文件
apiVersion: v1
kind: Pod
metadata:
name: huge-pages-example
spec:
containers:
- name: example
image: fedora:latest
command:
- sleep
- inf
volumeMounts:
- mountPath: /hugepages-2Mi
name: hugepage-2mi
- mountPath: /hugepages-1Gi
name: hugepage-1gi
resources:
limits:
hugepages-2Mi: 100Mi
hugepages-1Gi: 2Gi
memory: 100Mi
requests:
memory: 100Mi
volumes:
- name: hugepage-2mi
emptyDir:
medium: HugePages-2Mi
- name: hugepage-1gi
emptyDir:
medium: HugePages-1Gi














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









