






思维导向图

JDBC连接
由于PrepareStatement进行数据库操作更为灵活,所以直接选用此对象。
首先创建表Student
向项目中导入依赖jar包如下:
![]()
将其构建进入项目中
利用JDBC连接数据库,获取连接对象有两种方式,我们这里先使用直连方式,通过DriverManager获得连接对象
具体代码如下:
public static void main(String[] args) {
try(Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test")){
} catch (SQLException e) {
e.printStackTrace();
}
}这里使用JDK7以后的try块,写在try块里面的代码会将资源的关闭交给程序自己,相当于try。。catch。。finally模块。
这里调用DriverManager的getConnection(String url)方法获取连接,需要传入一个URL
URL:localhost相当于本机IP,3306是MySQL数据库的默认端口号,test是我们需要使用的数据库
JDBC插入操作
由于增删改都使用同一个方法功能类似,这里只实现增加功能,详细代码如下:
public static void main(String[] args){
try(Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test")){
//获取预编译对象
try(PreparedStatement pstm =conn.prepareStatement("insert into student(s_id,s_name,s_age,s_sex) " +
"values(null,?,?,?)")){
//给?占位符赋值
pstm.setString(1,"zhangsan");
pstm.setString(2,"1997-12-30");
pstm.setString(3,"男");
//执行插入方法
int rows = pstm.executeUpdate();//返回影响的行数
if(rows>0){
System.out.println("插入成功");
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}执行结果:
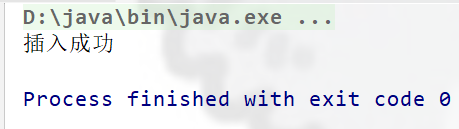
注意:列类型要与预编译对象对应set方法一致,否则会报错
可以看出来PrepareStatement中传入sql语句可以用?占位,这样代码就不用写死,灵活性高。
JDBC查询操作
提前写好Student实体类接受结果
public class Student {
private int s_id;
private String s_name;
private Date s_age;
private String s_sex;
//省略get set方法
@Override
public String toString() {
return "Student{" +
"s_id=" + s_id +
", s_name='" + s_name + '\'' +
", s_age=" + s_age +
", s_sex='" + s_sex + '\'' +
'}';
}
public Student() {
}
} public static void main(String[] args){
try(Connection conn = DriverManager.getConnection("jdbc:mysql://localhost:3306/test")){
//获取预编译对象
try(PreparedStatement pstm =conn.prepareStatement("select * from student")){
//执行查找方法,获取结果集对象
try(ResultSet rs=pstm.executeQuery()){
while (rs.next()) { //next()方法相当于在结果集将指针移动至下一行
//取出对应行的值
int s_id = rs.getInt("s_id");
String s_name = rs.getString("s_name");
Date s_age = rs.getDate("s_age");
String s_sex = rs.getString("s_sex");
System.out.println(new Student(s_id, s_name, s_age, s_sex).toString());
}
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}执行结果:
注意:一定要在获取对应列值之前使用next()方法移动指针,否则会查不到任何值
写到这里,我们发现一个问题,我们一次操作,就需要重新获取一次连接,这样代码冗余度特别大,何不将此部分封装成方法,用的时候直接调用就好了。
封装工具类
package org.ymh.pojo;
import java.sql.*;
import java.util.ArrayList;
import java.util.Collections;
import java.util.List;
public class JDBCUtil {
private static final String URL = "jdbc:mysql://localhost:3306/test";
private static final String USERNAME = "root";
private static final String PASSWORD = "root";
public static Connection getConnection() throws SQLException {
Connection conn = DriverManager.getConnection(URL, USERNAME, PASSWORD);
return conn;
}
}
封装通用的插入方法
public static int insert(String sql, Object... values) {
try (Connection conn = getConnection()) {
try (PreparedStatement pstm = conn.prepareStatement(sql)) {
int count = 1;
for (Object value : values) {
pstm.setObject(count, value);
count++;
}
int rows = pstm.executeUpdate();
return rows;
}
} catch (SQLException e) {
return -1;
}
}由于插入参数不固定,所以这里参数采用可变参数类型。
封装通用查看方法
public static <T> List<T> findBy(String sql, MyInterface<T> myInterface, Object... values) {
try (Connection conn = getConnection()) {
try (PreparedStatement pstm = conn.prepareStatement(sql)) {
int count = 1;
for (Object value : values) {
pstm.setObject(count, value);
count++;
}
List<T> list = new ArrayList<>();
ResultSet rs = pstm.executeQuery();
while (rs.next()) {
T obj = myInterface.mapper(rs);
list.add(obj);
}
return list;
}
} catch (SQLException e) {
return Collections.emptyList();
}
}
MyInterface接口
public interface MyInterface<T> {
public abstract T mapper(ResultSet rs)throws SQLException;
}
收获:模式设计模式,当传入参数类型不明确而且不止一个的时候,可以使用接口做参数,只提供抽象方法, 具体实现交给调用者自己实现,这样代码的扩展性明显提高。当类型不确定的时候最好使用泛型,具体类型后期调用的时候在去指定。
事务
啥都不说直接上代码:
public class TestTransaction {
public static void main(String[] args) throws SQLException {
Connection conn = null;
try {
conn = JDBCUtil.getConnection();
conn.setAutoCommit(false);//由于Mysql默认是自动提交的,这需要开启手动提交
try (PreparedStatement pstm = conn.prepareStatement("insert into big(name) values(?)")) {
pstm.setString(1,"s_name");
pstm.executeUpdate();
conn.commit();//提交事务
} catch (SQLException e) {
e.printStackTrace();
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
conn.rollback();//出现异常,事务回滚
}
}
}
批处理
当数据量非常小的时候,简单的i通过上面的方式向数据库中插入数据效率还是比较高的,当我们的需求从向表中插入几条、几十条,几百条扩大到几万条,几十万甚至百万千万的时候,每插入一条就执行一次executeUpdate()操作,性能明显会降低。那么该怎么办呢?
首先我先通过普通的方式向数据库中插入1万条记录,看一下所需时间:
public static void main(String[] args) {
try(Connection conn =JDBCUtil.getConnection()) {
try(PreparedStatement pstm = conn.prepareStatement("insert into big(name) values(?)")){
long start = System.currentTimeMillis();
for (int i = 0; i <10000 ; i++) {
pstm.setString(1, "张" + i);
pstm.executeUpdate();
}
long end = System.currentTimeMillis();
System.out.println("共耗时"+(end-start)+"毫秒");
}
} catch (SQLException e) {
}
}执行结果:
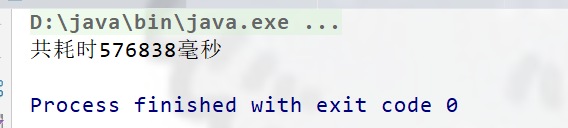
Mysql数据库给我们提供了批处理模式:
开启批处理首先需要在连接URL后面加一个参数,即rewriteBatchedStatements=true
现在的URL是"jdbc:mysql://localhost:3306/test?rewriteBatchedStatements=true"
具体代码如下:
public static void main(String[] args) {
try(Connection conn =JDBCUtil.getConnection()) {
try(PreparedStatement pstm = conn.prepareStatement("insert into big(name) values(?)")){
long start = System.currentTimeMillis();
for (int i = 0; i <10000 ; i++) {
pstm.setString(1,"张"+i);
pstm.addBatch();//添加批量
if(i%1000==0)//减少对java内存的压力
pstm.executeBatch();//批量插入
}
pstm.executeBatch();
long end = System.currentTimeMillis();
System.out.println("共用时"+(end-start)+"毫秒");
}
} catch (SQLException e) {
}
}运行结果![]()
可以很容易从时间上看出来这个性能的提升的幅度是相当之大。
提高查询效率
通过创建索引,可以提高查询效率,我们来做个实验
创建一个big表并向数据库中插入100万条数据
CREATE TABLE `big` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name1` varchar(20) DEFAULT NULL,
`name2` varchar(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=21241 DEFAULT CHARSET=utf8mb4;注意:记得开启批处理
我们给name1列加一个索引,给name2列不加索引,分别用java代码执行两个查询SQL比较一下效率
创建索引SQL语句 :create index idx_name1 on big(name1);
public class TestIndex {
public static void main(String[] args) {
long l1 = testIndex("select * from big where name1=?");
System.out.println("name1为查询条件是查询结果耗时"+l1+"纳秒");
long l2 = testIndex("select * from big where name2=?");
System.out.println("name2为查询条件是查询结果耗时"+l2+"纳秒");
}
public static long testIndex(String sql){
try(Connection conn = JDBCUtil.getConnection()) {
try(PreparedStatement pstm = conn.prepareStatement(sql)){
pstm.setString(1,"张一300");
long start = System.nanoTime();
try(ResultSet rs= pstm.executeQuery()){
while (rs.next()) {
rs.getString("name1");
rs.getString("name2");
}
}
long end = System.nanoTime();
return end-start;
}
} catch (SQLException e) {
e.printStackTrace();
return -1;
}
}
}
执行结果:
name1为查询条件是查询结果耗时3817329纳秒
name2为查询条件是查询结果耗时470540706纳秒
可以看出来加索引和不加索引完全不在一个数量级上。
SQL语句的执行流程
我们将SQL语句发给数据库以后,它是如何执行的呢?

根据上面的执行流程,我们有许多地方可以优化数据库。
数据库的每次连接都是比较耗时的,所以数据库给我们提供了连接池,通过配置连接池的参数我们可以把连接上面耗费的时间降到很低。
常见的连接池有
apache公司的 dpcp
C3P0
alibaba druid 德鲁伊连接池,提供SQL监控功能
这里我选择使用阿里的druid
Druid-池连
首先需要导入依赖jar包
![]()
依次执行以下操作


接下来就可以配置参数然后通过池连获取数据库连接了
我们来给补充我们的JDBCUtil工具类
//1、首先获取全局的dataSource对象
static final DruidDataSource dataSource = new DruidDataSource();
//2、配置数据库连接池参数
static {{
dataSource.setUrl(URL);
dataSource.setUsername(USERNAME);
dataSource.setPassword(PASSWORD);
dataSource.setInitialSize(5); // 初始连接数
dataSource.setMaxActive(10); // 最大连接数
dataSource.setMinIdle(5); // 最小连接数
dataSource.setValidationQuery("select 1"); // 一条简单的sql语句,用来防止数据库自动注销连接
dataSource.setTestWhileIdle(true); // 当空闲时时不时检查一下连接的有效性, 利用ValidationQuery中的sql语句
dataSource.setTimeBetweenEvictionRunsMillis(60*1000); // 默认一分钟执行一次ValidationQuery中的sql语句
}
//3、获取数据库连接, 池连
public static Connection getConnection2() throws SQLException {
return dataSource.getConnection();
}















 385
385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









